【算法对比】最短路算法(Dijkstra、Dijkstra+heap、Bellman_ford、Spfa、floyed)
文章的目的在于对比Dijkstra、Dijkstra+heap、Bellman_ford、Spfa算法的区别,下面将从,题目区别,算法核心代码&算法核心逻辑,相同变量的含义区别3个维度去对比
目录
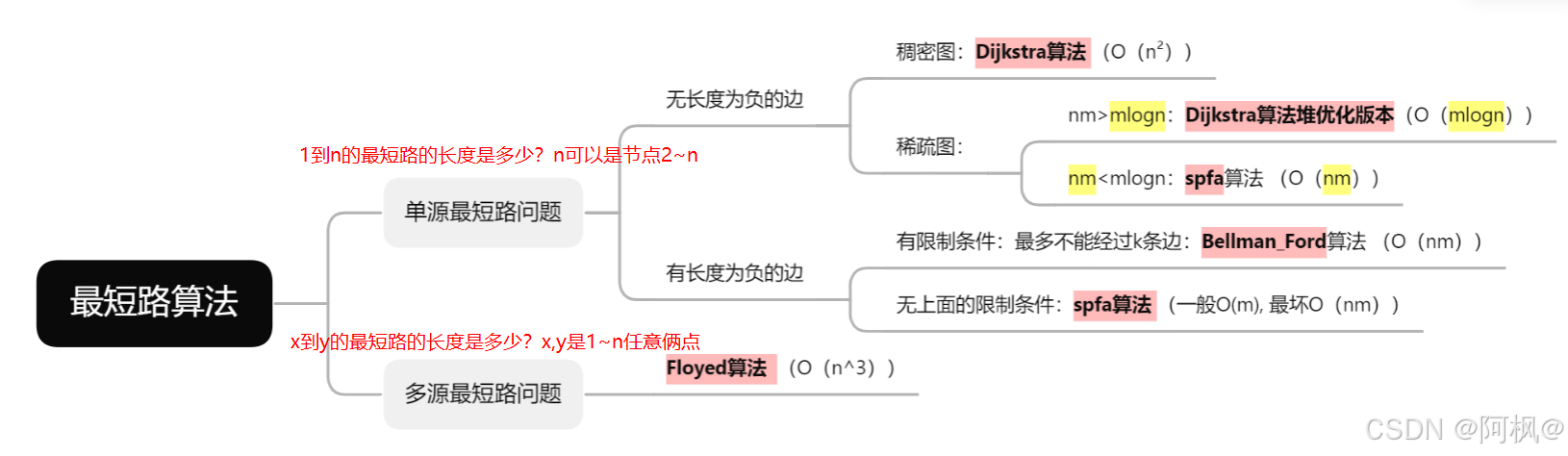
算法分类:
最短路算法,顾名思义,就是让我们求解结点到结点之间的最短路的长度
可以分类为如图情况:
文章目的:
文章的目的在于对比最短路算法的区别,下面将从,题目区别,算法核心代码&算法核心逻辑,相似变量的含义区别3个维度去对比:
一、题目区别
- 单源最短路问题:求图中一个源点(如 1 号点)到其他各点(如 2~n 号点)的最短距离。Dijkstra 算法、SPFA 算法、Bellman_Ford 算法主要用于解决此类问题。其中,Dijkstra 算法要求图中无负权边;SPFA 算法和 Bellman_Ford 算法可处理含负权边的图,且 Bellman_Ford 算法适用于存在边数限制的情况。
- 注意:SPFA算法不可以处理有负环的题目,否则因为它的维护是用队列,会出现不断出队入队的死循环情况; 而由于Bellman_Ford 算法适用于存在边数限制的情况,所以它的代码是直接遍历的方式,而不是队列,所以即使出现负环也不会死循环
- 多源最短路问题:求图中任意两点之间的最短距离。Floyd 算法专门用于解决此类问题,可处理包含负权边但无负权回路的图。
二、算法核心代码+算法核心逻辑
Dijkstra:
void Dijkstra(){
memset(dist,0x3f,sizeof dist); // 初始化所有点到源点距离
dist[1]=0; // 初始化源点到源点距离为0
for(int i = 0;i < n-1;i++){ // 更新n-1个点的dist,所以循环n-1次
int t = -1;
// 找到不属于最短路径集合的点中,距离源点距离最近的点
for (int j = 1;j <= n;j++){
if (!st[j] && (t==-1 || dist[t]>dist[j]))
t = j;
}
st[t] = true; // 标记该点t加入最短路径集合
// 更新所有点到源点距离
for (int j = 1;j <= n;j++){
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
}
if(dist[n]==0x3f3f3f3f) puts("impossible"); // 若n到源点不连通,则无解
else printf("%d",dist[n]);
}算法核心逻辑:就是在找一些距离源点最近的点,加入到最短路径的集合中(结点1会先加入),然后通过这个点再去更新所有的点到源点的最短距离
Q:为什么要找到不属于最短路径集合的点中,距离源点距离最近的点
for (int j = 1;j <= n;j++){
if (!st[j] && (t==-1 || dist[t]>dist[j]))
t = j;
}
A:
1)为什么要找到不属于最短路径集合的点?
因为最短路径集合里面的点,都被用去更新所有的点的dist,即被用去更新所有的点到源点的距离(如下)
// 更新所有点到源点距离
for (int j = 1;j <= n;j++){
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
被拿去用去更新了一次dist,下次就不用它去更新dist了,所以直接标记true,下次若st[j]直接不用它
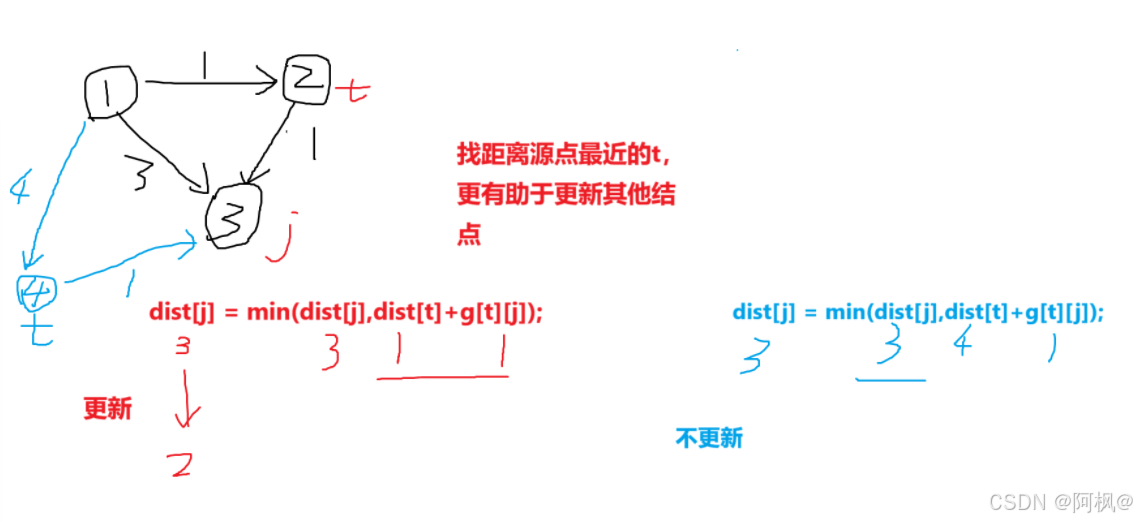
2)为什么要找距离源点距离最近的点?
在
// 更新所有点到源点距离
for (int j = 1;j <= n;j++){
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
j会从1到n,即这个过程中,不仅t这个点会被更新,其他的点也会被更新dist
在这个过程,取dist最小的t,更有可能更新dist[j],无论它更新的是dist[t]还是其他节点的dist(如图)
堆优化版本的Dijkstra:
void add(int a,int b,int c){
e[idx] = b,ne[idx] = h[a],w[idx] = c;h[a] = idx++;
}
void Dijkstra(){
memset(dist,0x3f,sizeof dist); // 初始化所有点到源点距离
dist[1]=0; // 初始化源点到源点距离为0
priority_queue<PII,vector<PII>,greater<PII>> heap;// PII是pair<int,int>
heap.push({0,1}); // {0,1} 代表结点1到源点距离为0
while(heap.size()){ // 若队列非空
auto t = heap.top(); // 出队
heap.pop();
int distance = t.first,node = t.second;
if(st[node]) continue; // 若出队的node节点已经在最短路径集合中,进入下个循环
st[node] = true;
// 找出队的node节点的连接节点
for (int i = h[node];i!=-1;i=ne[i]){
int j = e[i];
// 更新连接节点到源点的最短距离
if (dist[j]>distance + w[i]) {
dist[j]=distance + w[i];
heap.push({dist[j],j});// 若该j更新了最短距离,则入队
}
}
}
if(dist[n]==0x3f3f3f3f) puts("impossible");
else printf("%d",dist[n]);
}算法核心逻辑:用优先队列维护,节点1先入队(实际入队的是{0,1},这里方便描述写作入队节点1),只要队列非空就出队,若出队的节点已经在最短路径集合中,就出队下一个结点。否则就标记出队的节点加入最短路径集合,随即去更新该节点的连接节点到源点的最短距离
PS:注意在主函数写上memset(h,-1,sizeof -1);
Q:为什么要将更新了到源点最短距离的节点j入队heap.push({dist[j],j})
A:入队之后,小跟堆会排序,然后每次出队都会拿到距离源点最短距离的节点,用它去更新其他连接节点的dist,更容易更新
如:将{4,2},{3,2}先后入队后
小跟堆中现在就有{3,2},{4,2};
出队时,会直接拿到{3,2}
注意:优先队列会优先对pair的first排序,所以pair数据中距离要放前面
总结:所以Dijkstra和Dijkstra_heap本质都是先处理1节点,再不断找离1最近的节点,用它去不断更新其他点到源点的距离
Bellman_Ford:
const int N = 510, M = 10010;
int n, m, k;
int dist[N], backup[N];
struct Edge {
int a, b, w;
} edges[M];
void Bellman_Ford() {
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < k; i++) { // 最多经过k条边,所以进行k次松弛操作,所以循环k次
memcpy(backup, dist, sizeof dist); // 备份上一轮的距离数组,保证最多经过k条边
for (int j = 0; j < m; j++) { // 遍历所有边(本质是遍历edges结构体数组)
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
dist[b] = min(dist[b], backup[a] + w); // 更新边的终点到源点的距离
}
}
if (dist[n] > 0x3f3f3f3f / 2) puts("impossible"); // 判断是否可达,由于有负环,所以第三题[n]可能被更新成0x3f3f3f3f / 2~0x3f3f3f3f的数
else printf("%d", dist[n]);
}算法核心逻辑:通过对图中所有边进行k次松弛操作(“放松” 对v到源点距离的估计,使其更接近真实的最短距离),每次松弛操作都遍历所有的边,进行dist的更新
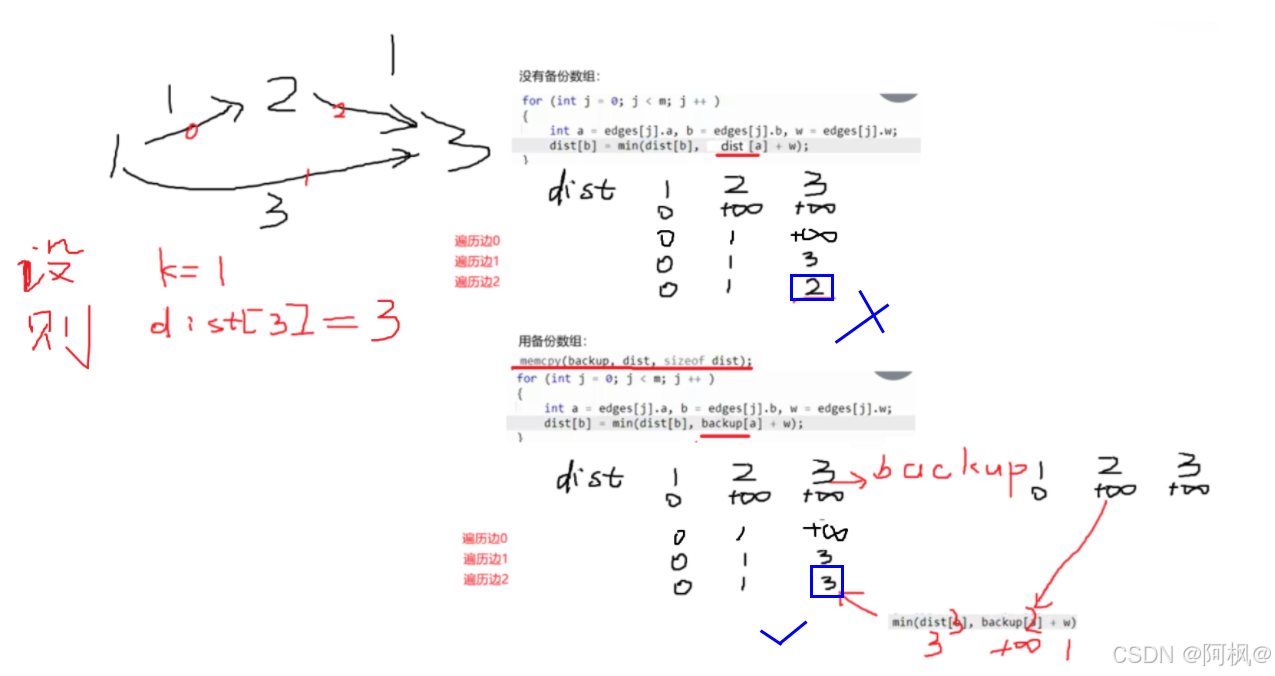
Q1:为什么每次松弛操作前要备份距离数组memcpy(backup, dist, sizeof dist); ?
A1:见图
Q2: 为什么要循环k次?
A2:因为要保证最多不超过k条边,所以需要循环k次。
那为什么循环k次后可以保证最多不超过k条边?画个图就知道了,如:当k=2的时候,第一次循环会得到上面的图的情况,第二次循环的时候,dist[3]就会因为dist[2]=1,所以backup[2]=1,所以在 dist[b] = min(dist[b], backup[a] + w)被更新成2
Q3:为什么要遍历结构体数组,而不是用队列出队,再遍历所有的连接节点?
A3:因为后者并不能保证每次松弛每条边的时候,能够遍历到所有的边,而松弛操作的要求是需要遍历所有的边,否则无法达成目标
spfa:
const int N = 100010,M=200010;
int n, m;
int h[N], e[M], ne[M], w[M], idx; // 注意这个初始化的N,M。h下标是节点,一共有N个节点,存的是下一条边的编号。e ne w存的是下一条边的起点,终点,权值,一共有M条边
int dist[N];
bool st[N];
void add(int a, int b, int c) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
void Spfa() {
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
st[1] = true; // 标记点1已经在队列中
queue<int> q;
q.push(1);
while (q.size()) {
int t = q.front();
q.pop();
st[t] = false; // 若没有这一步,st[t]=true的话下面if (!st[j])不会执行
for (int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
if (dist[j] > dist[t] + w[i]) {
dist[j] = dist[t] + w[i];
if (!st[j]) { // 若j不在队列中
q.push(j);
st[j] = true; // 标记j在队列中
}
}
}
}
if (dist[n] == 0x3f3f3f3f) puts("impossible");
else printf("%d", dist[n]);
}算法核心逻辑: 入队节点1,标记节点1已经在队列中,若队列非空,出队,标记出队节点不在队列中,遍历所有出队节点的连接节点,更新dist,若连接节点不在队列中,入队,标记在队列中
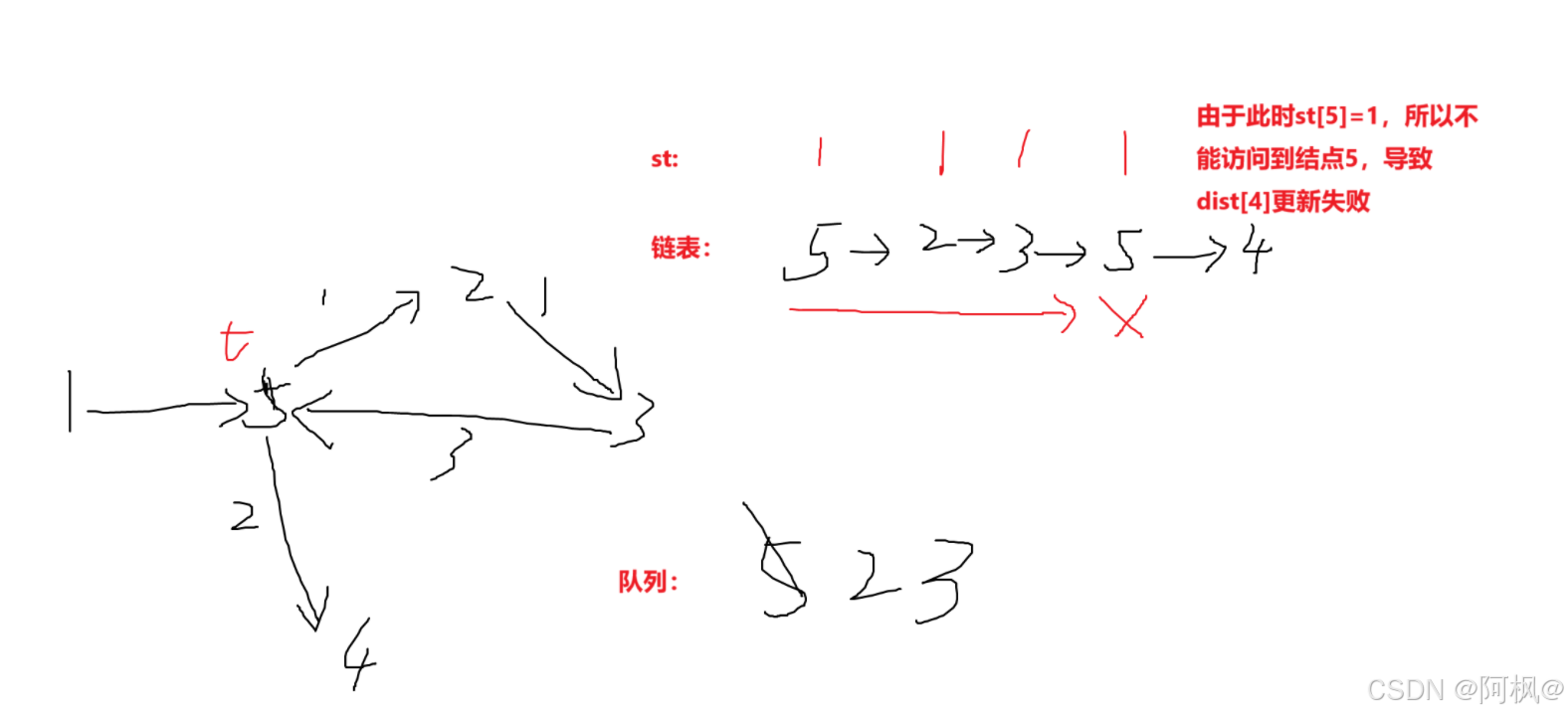
Q1: 为什么要有st[t] = false;
A1: 若没有这一步,st[t]=true的话下面if (!st[j])不会执行
如图:
Q2: 为什么用队列,而不用结构体数组edges?
A2:
因为不需要限制只能经过k条边,所有不需要遍历所有边再去更新了,所以可以只遍历相连接的边,减少遍历的边数,从而提高时间复杂度
Q3:为什么要判断if (!st[j]) 后才将节点j入队q.push(j); ?
A3:st[j]用于标记节点j是否在队列中。如果一个节点已经在队列中,说明它已经在等待被处理以更新其他节点的dist,再次将其加入队列会造成重复处理,浪费时间和资源。
spfa判断是否有负环:
const int N = 2010,M =10010;
int n,m,x,y,z,e[M],ne[M],w[M],h[N],idx,cnt[N],dist[N];
bool st[N];
void add(int a,int b,int c){
e[idx] = b,ne[idx] = h[a],w[idx] = c,h[a] = idx++;
}
bool spfa(){
queue<int> q;
for (int i = 1;i <= n;i++){
q.push(i);
st[i] = true;
}
while(q.size()){
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t];i!=-1;i=ne[i]){
int j = e[i];
if(dist[j]>dist[t]+w[i]){
dist[j]=dist[t]+w[i];
cnt[j] = cnt[t]+1;
if(cnt[j]>=n) return true;
if(!st[j]){
q.push(j);
st[j] = true;
}
}
}
}
return false;
}算法核心逻辑:入队1-n,标记已在队列中。若队列非空,出队,标记已不在队列,遍历出队节点的所有连接节点,更新dist,和cnt(该节点到源点的最短路径边数),若cnt>=n,则有负环,返回true。若该节点不存在队列中,入队并标记已在队列。若无返回true,则无负环,则不会无限出队入队进入无限循环,则循环会结束,结束后返回false。
Q: 为什么选择spfa以及怎么修改spfa使得能够判断有无负环?
A:为什么是spfa?首先有负环,必有负边,只有spfa可以处理负边且没有限制最多只能经过k条边的情况。
spfa的基础上修改就能判断是否有负环。
首先,spfa算法是在有负边的图去求单源最短路,若多维护一个每个结点j的最短路径的边数cnt[j],当cnt>=n时必有环,且一定是负环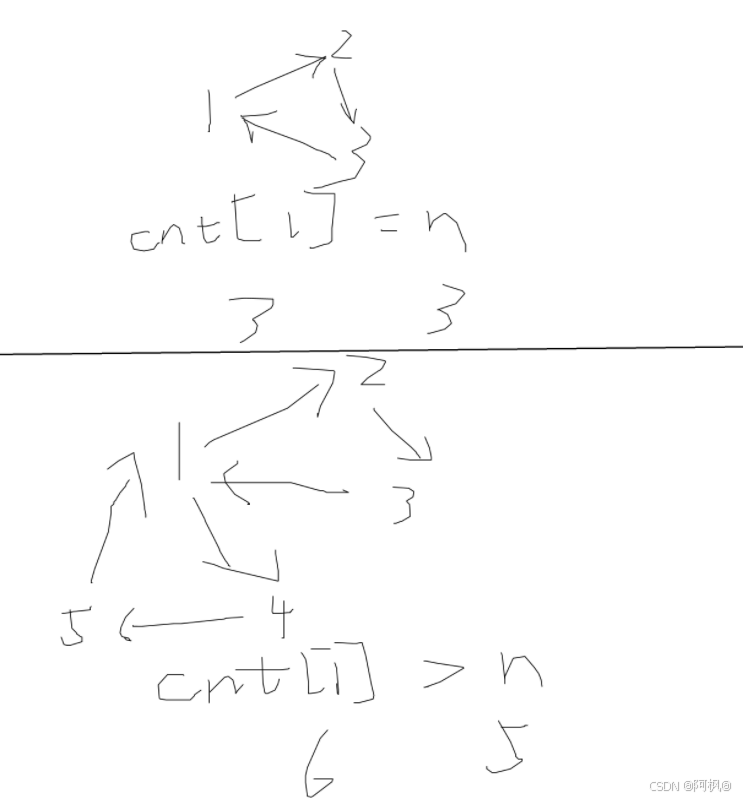
由于只入队1不一定能走到负环,所以我们入队1-n,确保考虑到所有情况
floyed
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 210;
int n,m,k,x,y,z,d[N][N],INF = 0x3f3f3f3f;
void floyed(){
for (int k = 1;k <=n;k++) // 以节点k作为中间点,每个点都要作为中间点一次,故循环k次
for (int i = 1;i <= n;i++)
for (int j = 1;j <= n;j++)
d[i][j] = min(d[i][j],d[i][k]+d[k][j]); // 若点i通过k到j的距离比点i到j近,则更新d
}
int main(){
scanf("%d%d%d",&n,&m,&k);
for (int i = 1;i <= n;i++){
for (int j = 1;j <= n;j++){
if (i==j) d[i][j]=0;
else d[i][j] = INF;
}
}
while(m--){
scanf("%d%d%d",&x,&y,&z);
d[x][y] = min(d[x][y],z);
}
floyed();
while(k--){
scanf("%d%d",&x,&y);
if(d[x][y]>INF/2) puts("impossible");
else printf("%d\n",d[x][y]);
}
}算法核心逻辑:维护一个二维数组d[i][j](表示i到j的距离),除了对角线初始化为0外,其他初始化0x3f3f3f3f。每个结点分别作为中间点一次,遍历d,若点i通过k到j的距离比点i到j近,则更新d
三、相似变量的含义区别
| 算法 | st[] |
| Dijkstra | 是否加入最短路径集合(即是否拿去更新了dist) |
| 堆优化的Dijkstra | 是否加入最短路径集合(即是否拿去更新了dist) |
| Bellman_Ford | 无 |
| Spfa |
是否存在队列中(即是否准备拿去更新dist) |
其他算法:dfs中的st,表示是否搜过该点,常用于剪枝。
| 算法 | dist/d |
|
单源最短路算法(Dijkstra、 Dijkstra+heap、Bellman_ford、Spfa) |
dist:表示节点到源点的最短路距离 |
| 多源最短路算法(Floyed) | d[i][j]:表示i到j的距离 |
如果觉得内容有帮助,可以点赞收藏
如果有纰漏或疑问,欢迎留言

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 56
56 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)