LangChain LCEL表达式与Runnable可运行协议
本文探讨了LLM应用开发中组件嵌套调用的优化方法。首先指出多组件invoke嵌套的三大缺陷:可维护性差、调试困难、扩展性受限。随后提出两种解决方案:1)自定义Chain类,通过平级调用序列组件;2)利用LangChain的Runnable协议和LCEL表达式(|运算符),实现更简洁的链式调用。文章详细展示了两种方案的具体实现,并指出Runnable协议底层同样采用顺序执行策略,但提供了更丰富的标准
01. 多组件 invoke 嵌套的缺点
在前面的课时中,我们使用多个组件的 invoke 进行嵌套来创建 LLM 应用,示例代码如下
prompt = ChatPromptTemplate.from_template("{query}")
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
parser = StrOutputParser()
# 获取输出内容
content = parser.invoke(
llm.invoke(
prompt.invoke(
{"query": req.query.data}
)
)
)
这种写法虽然能实现对应的功能,但是存在很多缺陷:
- 嵌套式写法让程序的维护性与可阅读性大大降低,当需要修改某个组件时,变得异常困难。
- 没法得知每一步的具体结果与执行进度,出错时难以排查。
- 嵌套式写法没法集成大量的组件,组件越来越多时,代码会变成“一次性”代码。
前端代码中的嵌套/回调地狱

思考:能否将嵌套的写法改成平级的调用,这样就可以屏蔽嵌套带来的大量缺陷。
02. 手写一个"Chain"优化代码
观察发现,虽然 Prompt、Model、OutputParser 分别有自己独立的调用方式,例如:
- Prompt 组件:format、invoke、to_string、to_messages。
- Model 组件:generate、invoke、batch。
- OutputParser 组件:parse、invoke。
但是有一个共同的调用方法:invoke,并且每一个组件的输出都是下一个组件的输入,是否可以将所有组件组装得到一个列表,然后循环依次调用 invoke 执行每一个组件,然后将当前组件的输出作为下一个组件的输入。
源码实现
from typing import Any
import dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
prompt = ChatPromptTemplate.from_template("{query}")
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
parser = StrOutputParser()
class Chain:
steps: list = []
def __init__(self, steps: list):
self.steps = steps
def invoke(self, input: Any) -> Any:
output: Any = input
for step in self.steps:
output = step.invoke(output)
print(step)
print("执行结果:", output)
print("===============")
return output
chain = Chain([prompt, llm, parser])
print(chain.invoke({"query": "你好,你是?"}))
输出内容:
input_variables=['query'] messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['query'], template='{query}'))]
执行结果: messages=[HumanMessage(content='你好,你是?')]
===============
client=<openai.resources.chat.completions.Completions object at 0x000001C6BF694310> async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x000001C6BF695BD0> model_name='gpt-3.5-turbo-16k' openai_api_key=SecretStr('**********') openai_api_base='https://api.xty.app/v1' openai_proxy=''
执行结果: content='你好!我是 ChatGPT,一个由OpenAI开发的人工智能语言模型。我可以回答各种各样的问题,帮助解决问题,提供信息和创意。有什么我可以帮助你的吗?' response_metadata={'token_usage': {'completion_tokens': 72, 'prompt_tokens': 13, 'total_tokens': 85}, 'model_name': 'gpt-3.5-turbo-16k', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None} id='run-5bf9e183-4b28-4be9-bf65-ce0ad9590785-0'
===============
执行结果: 你好!我是 ChatGPT,一个由OpenAI开发的人工智能语言模型。我可以回答各种各样的问题,帮助解决问题,提供信息和创意。有什么我可以帮助你的吗?
===============
你好!我是 ChatGPT,一个由OpenAI开发的人工智能语言模型。我可以回答各种各样的问题,帮助解决问题,提供信息和创意。有什么我可以帮助你的吗?
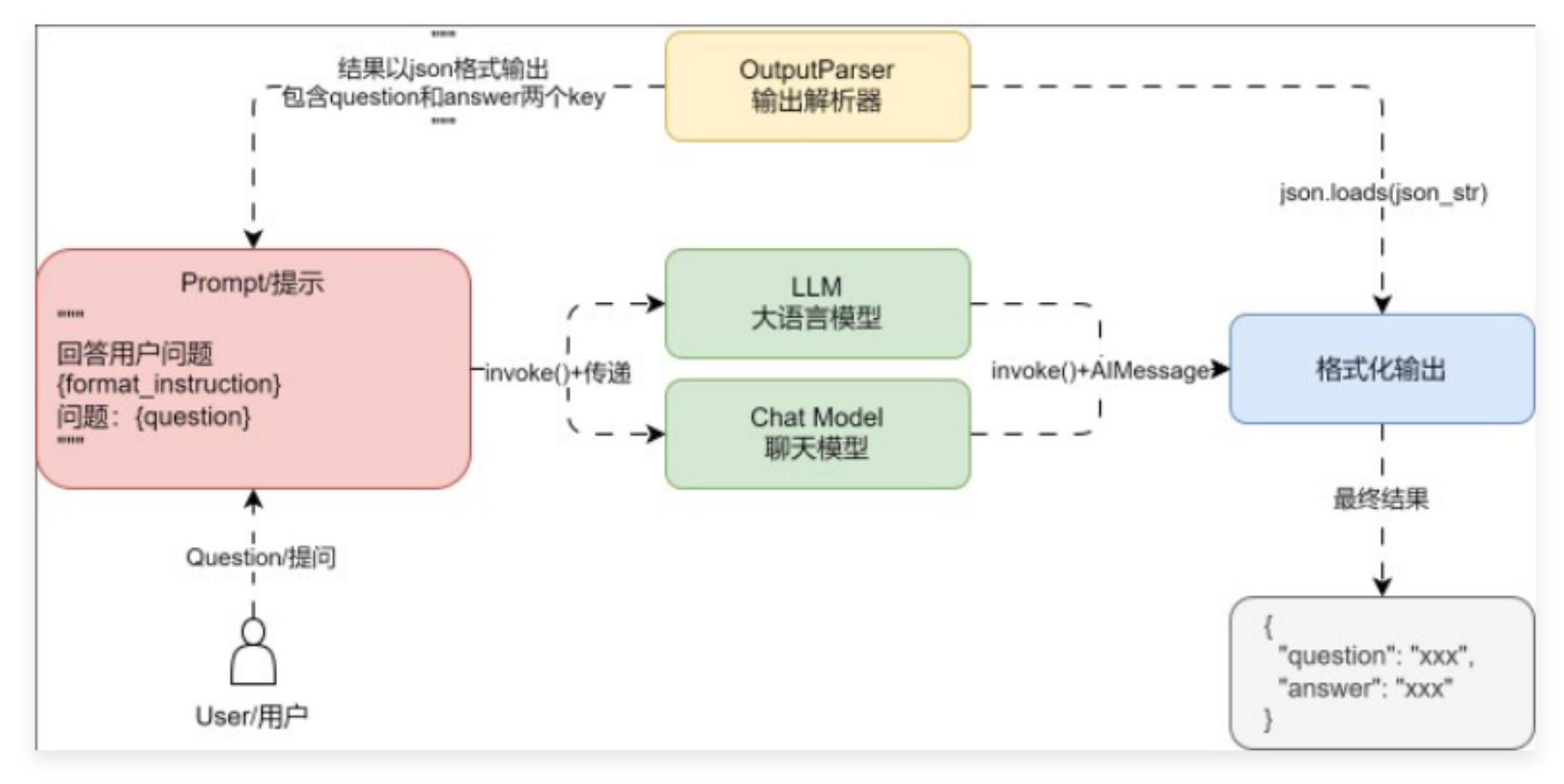
通过自定义"Chain"的方式虽然简化了过程,也支持观察,不过功能过于简陋,在 LangChain 中既然 Prompt、Model、OutputParser 均支持 invoke 方法,底层是否统一了某种规范?并支持以更简单的方式进行调用?
03. Runnable 简介与 LCEL 表达式
为了尽可能简化创建自定义链,LangChain 官方实现了一个 Runnable 协议,这个协议适用于 LangChain 中的绝大部分组件,并实现了大量的标准接口,涵盖:
- stream:将组件的响应块流式返回,如果组件不支持流式则会直接输出。
- invoke:调用组件并得到对应的结果。
- batch:批量调用组件并得到对应的结果。
- astream:stream 的异步版本。
- ainvoke:invoke 的异步版本。
- abatch:batch 的异步版本。
- astream_log:除了流式返回最终响应块之外,还会流式返回中间步骤。
除此之外,在 Runnable 中还重写了 __or__ 和 __ror__ 方法,这是 Python 中 | 运算符的计算逻辑,所有的 Runnable 组件,均可以通过 | 或者 pipe() 的方式将多个组件拼接起来形成一条链

from typing import Any
import dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
prompt = ChatPromptTemplate.from_template("{query}")
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
parser = StrOutputParser()
chain = prompt | llm | parser
# 等价于以下写法
composed_chain_with_pipe = (
RunnableParallel({"query": RunnablePassthrough()})
.pipe(prompt)
.pipe(llm)
.pipe(parser)
)
print(chain.invoke({"query": "你好,你是?"}))
Runnable 底层的运行逻辑本质上也是将每一个组件添加到列表中,然后按照顺序执行并返回最终结果,核心源码
def invoke(self, input: Input, config: Optional[RunnableConfig] = None) -> Output:
from langchain_core.beta.runnables.context import config_with_context
# setup callbacks and context
config = config_with_context(ensure_config(config), self.steps)
callback_manager = get_callback_manager_for_config(config)
# start the root run
run_manager = callback_manager.on_chain_start(
dumpd(self),
input,
name=config.get("run_name") or self.get_name(),
run_id=config.pop("run_id", None),
)
# 调用所有步骤并逐个执行得到对应的输出,然后作为下一个的输入
try:
for i, step in enumerate(self.steps):
input = step.invoke(
input,
# mark each step as a child run
patch_config(
config, callbacks=run_manager.get_child(f"seq:step:{i+1}")
),
)
# finish the root run
except BaseException as e:
run_manager.on_chain_error(e)
raise
else:
run_manager.on_chain_end(input)
return cast(Output, input)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)