企业场景下大模型AI应用具体案例(二)——征服AI幻觉!Dify+RAGFlow打造企业级精准决策引擎
通过与RAGFlow的API深度集成,系统可在处理非结构化数据的同时,实现语义层面的精准匹配,充分发挥“数据+语义”双轮驱动的优势,为企业提供更高质量的智能检索服务。给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!截至目前大模型已经超过200个
在AI日益深入企业核心业务的今天,数据驱动的智能决策已成为竞争的关键。然而,“幻觉”问题如同一颗定时炸弹,看似完美的回答背后——它可能虚构事实、误引数据、混淆逻辑,最终导致错误判断,甚至影响企业的战略方向和市场声誉。面对这一挑战,如何构建一个既智能又可靠的AI系统,成为企业数字化转型中的重中之重。
As AI increasingly permeates core business operations, data-driven intelligent decision-making has become a critical competitive differentiator. However, the "hallucination" issue looms like a time bomb—behind seemingly flawless responses, AI may fabricate facts, misinterpret data, or confuse logic, ultimately leading to erroneous judgments that impact strategic direction and market reputation. Confronted with this challenge, building an intelligent yet reliable AI system has emerged as a top priority in corporate digital transformation.

AI幻觉的本质:智能背后的“认知陷阱”
The Essence of AI Hallucination: The "Cognitive Trap" Behind Intelligence
所谓“AI幻觉”,指的是生成式AI在缺乏准确依据的情况下,输出看似合理但实则错误的内容。这种现象源于大模型训练时对海量文本的统计归纳能力,而非真正的理解与验证机制。当AI面对未知或模糊问题时,往往通过“猜测”来填补空白,从而产生误导性信息。对于医疗诊断、金融分析、法律咨询等高风险领域而言,哪怕是一个小错误也可能带来严重后果。
"AI hallucination" refers to generative AI producing plausible but factually incorrect content when lacking accurate grounding. This phenomenon stems from large language models’ statistical induction capabilities over massive text corpora during training, rather than genuine comprehension and verification mechanisms. When faced with ambiguous or unfamiliar queries, AI often "guesses" to fill knowledge gaps, generating misleading information. In high-stakes domains like medical diagnosis, financial analysis, and legal consulting, even minor errors can trigger severe consequences.
破解幻觉难题:Dify 与 RAGFlow 的强强联合
Solving the Hallucination Challenge: The Powerful Integration of Dify and RAGFlow
要真正解决AI幻觉问题,不能仅依赖于模型本身,而需要从知识来源、推理路径、结果验证三个层面进行重构。正是在这样的背景下,Dify 与 RAGFlow 联合打造了一套面向企业的精准决策引擎 ,从根本上提升AI系统的准确性与可信度。
Truly addressing AI hallucination requires restructuring not just the model itself, but also three critical layers: knowledge sourcing, reasoning paths, and result validation. Against this backdrop, Dify and RAGFlow jointly deliver an enterprise-oriented precision decision engine, fundamentally enhancing the accuracy and trustworthiness of AI systems.

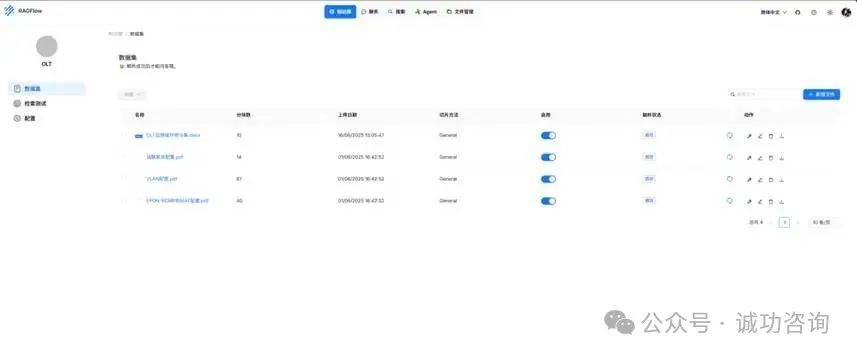
RAGFlow具备强大的文档解析能力,能够高效处理PDF、扫描件、表格等多种复杂格式内容。其智能布局识别技术可自动提取结构化数据,有效弥补Dify在原生文档解析方面的不足,大幅提升信息提取的完整性与准确性。
RAGFlow boasts robust document parsing capabilities, efficiently processing complex formats like PDFs, scanned files, and tables. Its intelligent layout recognition technology automatically extracts structured data, effectively compensating for Dify’s native document parsing limitations and significantly improving information extraction completeness and accuracy.
通过多路召回机制与重排序优化策略,RAGFlow显著提升了检索结果的相关性与准确率。实测数据显示,针对扫描版PDF表格内容,其解析完整度提升超过40%,极大增强了AI系统在处理非结构化数据时的可靠性。
Through multi-path recall mechanisms and re-ranking optimization strategies, RAGFlow dramatically enhances retrieval relevance and precision. Real-world tests show a >40% improvement in parsing completeness for scanned PDF tables, substantially boosting AI reliability in handling unstructured data.
Dify支持向量检索、全文检索以及推荐使用的混合检索模式。通过与RAGFlow的API深度集成,系统可在处理非结构化数据的同时,实现语义层面的精准匹配,充分发挥“数据+语义”双轮驱动的优势,为企业提供更高质量的智能检索服务。
Dify supports vector search, full-text search, and hybrid retrieval (recommended). Deep API integration with RAGFlow enables semantic-level precision matching while processing unstructured data, leveraging dual-driven advantages of "Data + Semantics" to deliver higher-quality intelligent search services for enterprises.
精准决策引擎的核心价值
Core Value of the Precision Decision Engine
✅去幻觉:基于真实数据源的生成机制
Hallucination Reduction: Generation grounded in authentic data sources
利用RAGFlow强大的文档解析与检索能力,AI的回答不再凭空想象,而是依托企业内部的知识库、政策文件、历史数据等真实内容,显著降低幻觉发生率。
Leveraging RAGFlow’s powerful parsing and retrieval, AI responses are anchored in real enterprise knowledge bases—policy documents, historical data, etc.—significantly reducing hallucination rates.
✅可追溯:每一次回答都有据可依
Traceability: Every answer comes with verifiable sources
系统自动记录生成过程中的引用来源,用户可以轻松回溯答案出处,满足合规审计与责任追踪需求。
The system automatically logs citations during generation, enabling users to trace answer origins and meeting compliance, auditing, and accountability requirements.
✅高适配:灵活应对多样业务场景
High Adaptability: Flexibility across diverse business scenarios
借助NewINT平台,企业可根据不同部门、岗位、流程快速构建专属AI助手,如财务分析员、法律顾问、客服机器人等。
Using the NewINT platform, enterprises can rapidly deploy role-specific AI assistants (e.g., financial analysts, legal advisors, customer service bots) tailored to departments, roles, or workflows.
✅易部署:私有化架构保障数据安全
Easy Deployment: Private architecture ensures data security
支持本地化部署与混合云架构,确保敏感信息不出域,全面满足金融、政务、医疗等行业对数据隐私的高标准要求。
Supports on-premise and hybrid cloud deployment, ensuring sensitive information never leaves designated domains while meeting stringent data privacy standards in finance, government, healthcare, and other regulated sectors.
如何学习AI大模型 ?
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
(👆👆👆安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
(👆👆👆安全链接,放心点击)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)