黑马SpringCloud微服务课程总结(五)
本文是黑马微服务SpringCloud课程的总结,文章总结内容包括:ElasticSearch的进阶操作,例如数据聚合,自动补全,数据同步
参考课程:SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式,系统详解springcloud微服务技术栈课程|黑马程序员Java微服务_哔哩哔哩_bilibili
本文是黑马微服务SpringCloud课程的总结,文章总结内容包括:ElasticSearch的进阶操作,例如数据聚合,自动补全,数据同步
数据聚合
聚合的分类


DSL实现Bucket聚合
aggs定义聚合

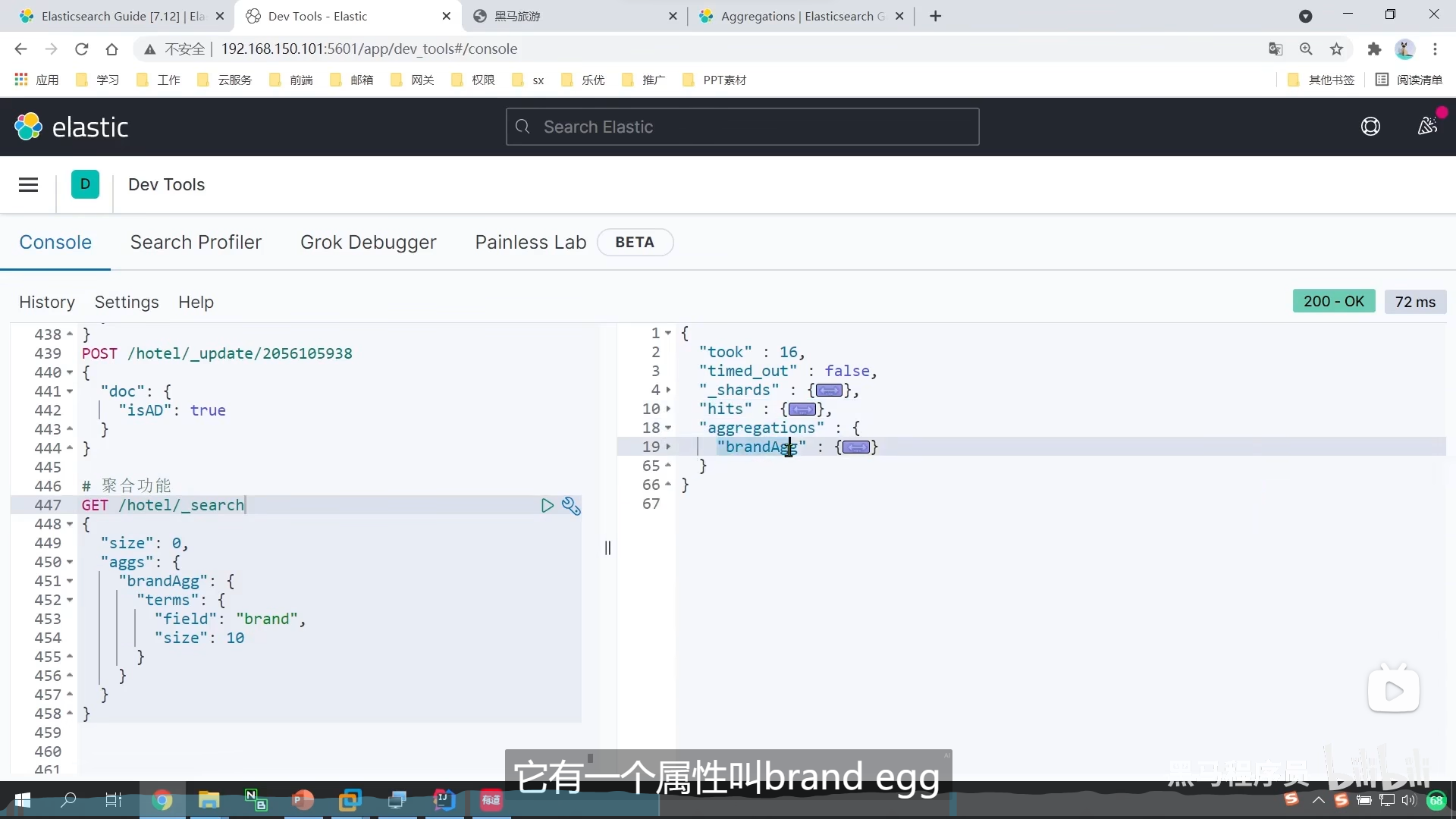
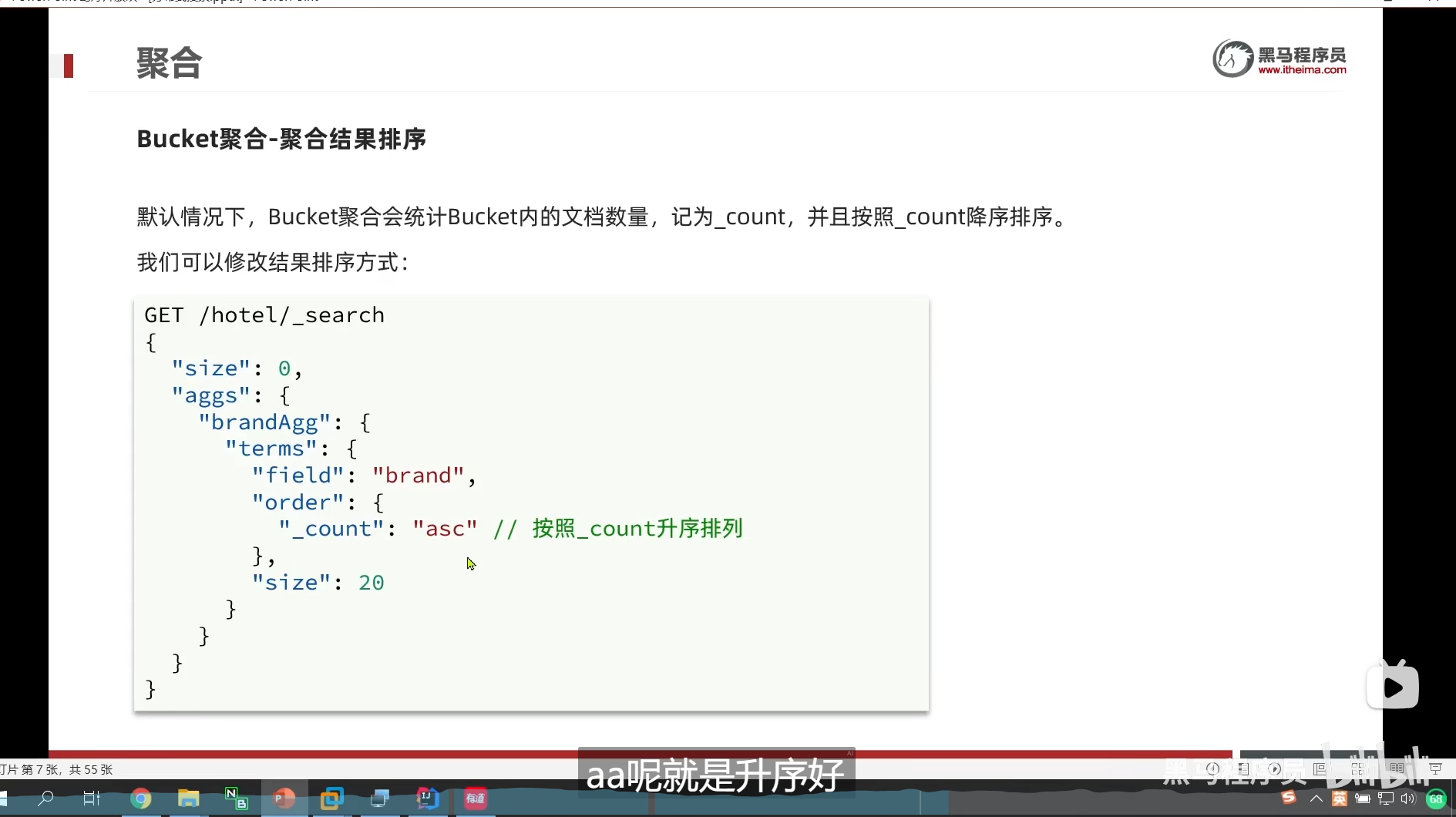
_count
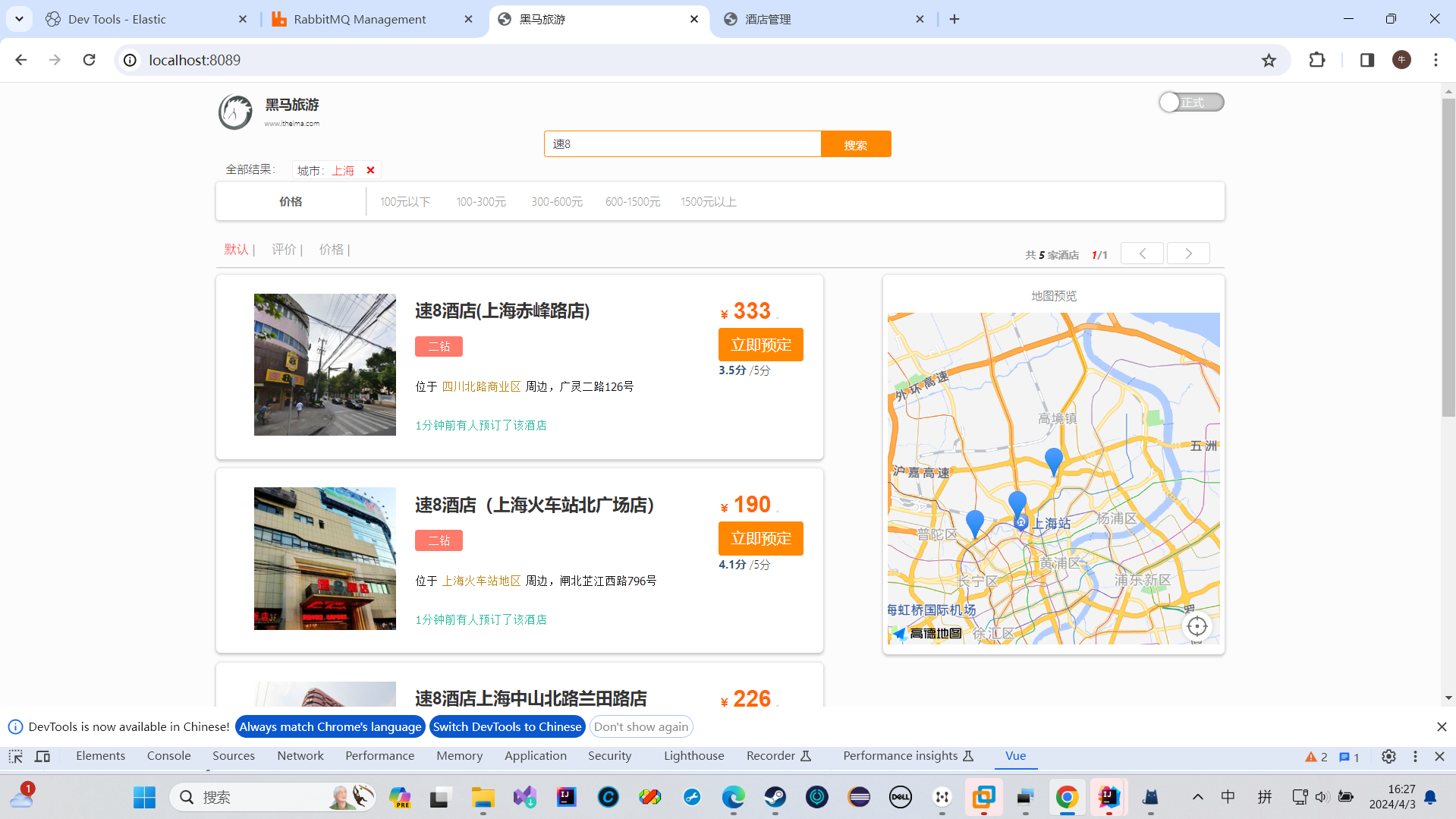
我们文档中某个品牌的数量,然后决定升序还是降序排列
我们是对整个索引库搜索,那么我们消耗的内存是非常大的
那我们能不能限定我们搜索的范围呢
限定范围
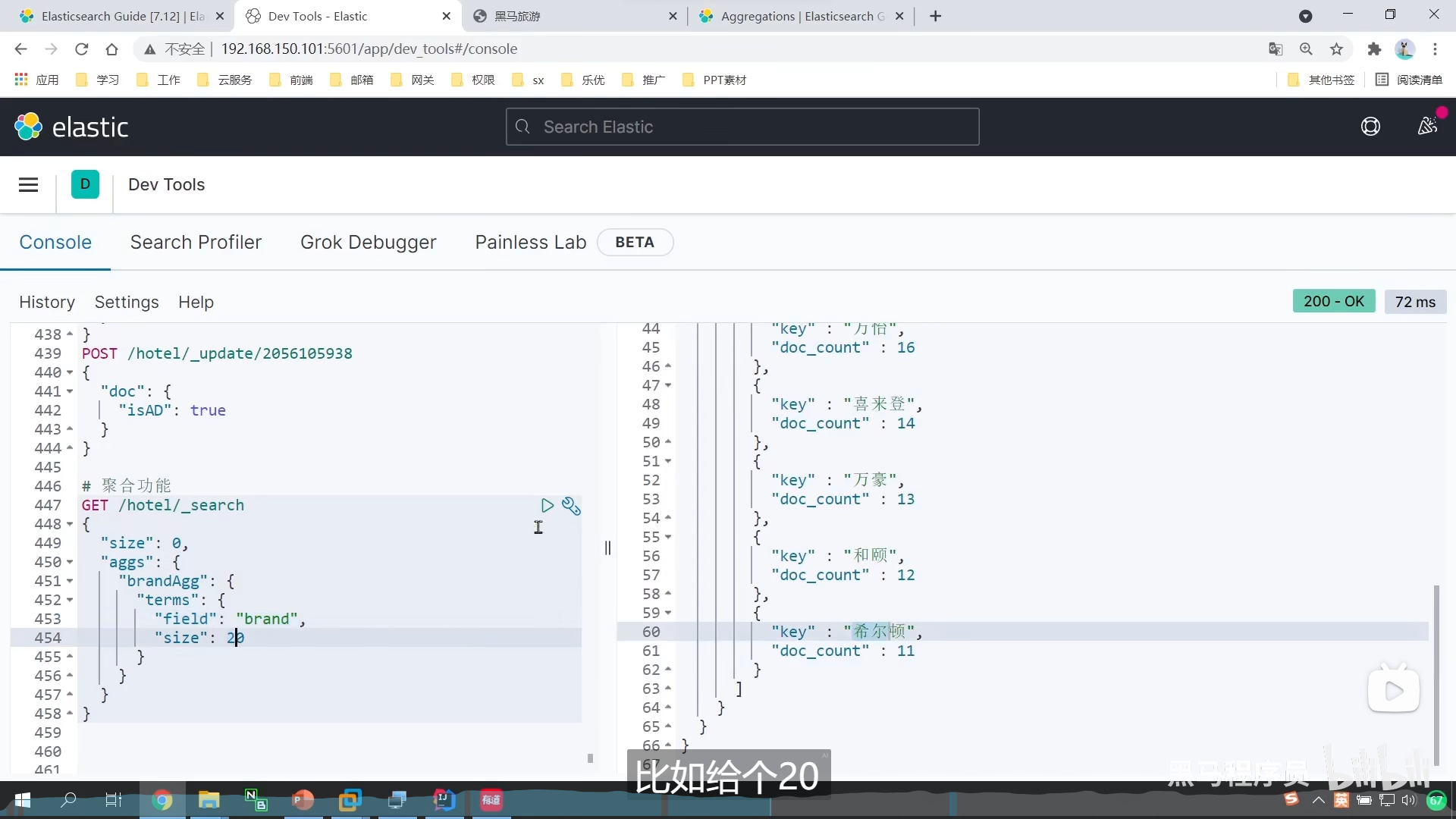
例如我们的给我们的加个price限定范围


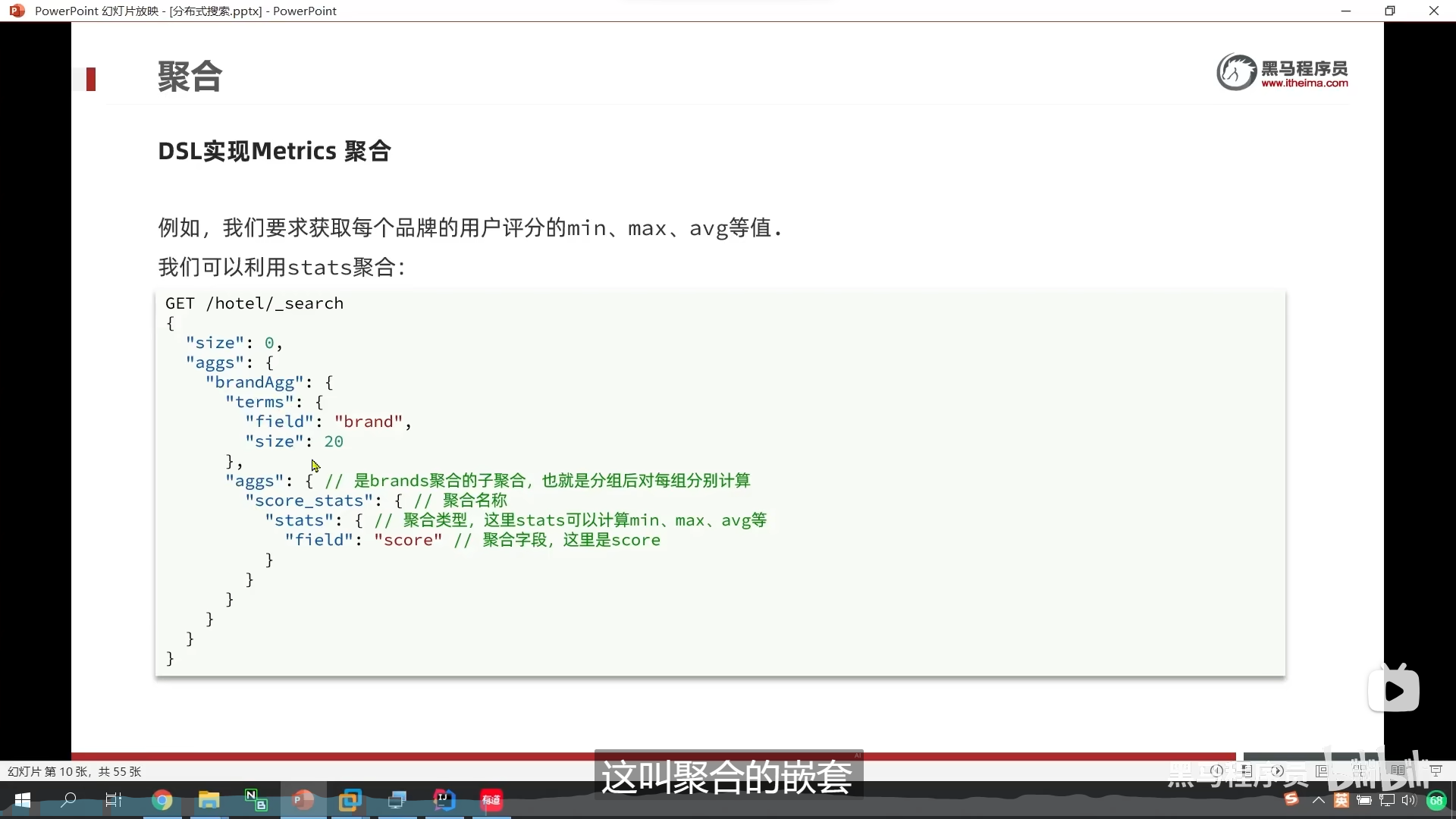
DSL实现metrics聚合
stats聚合
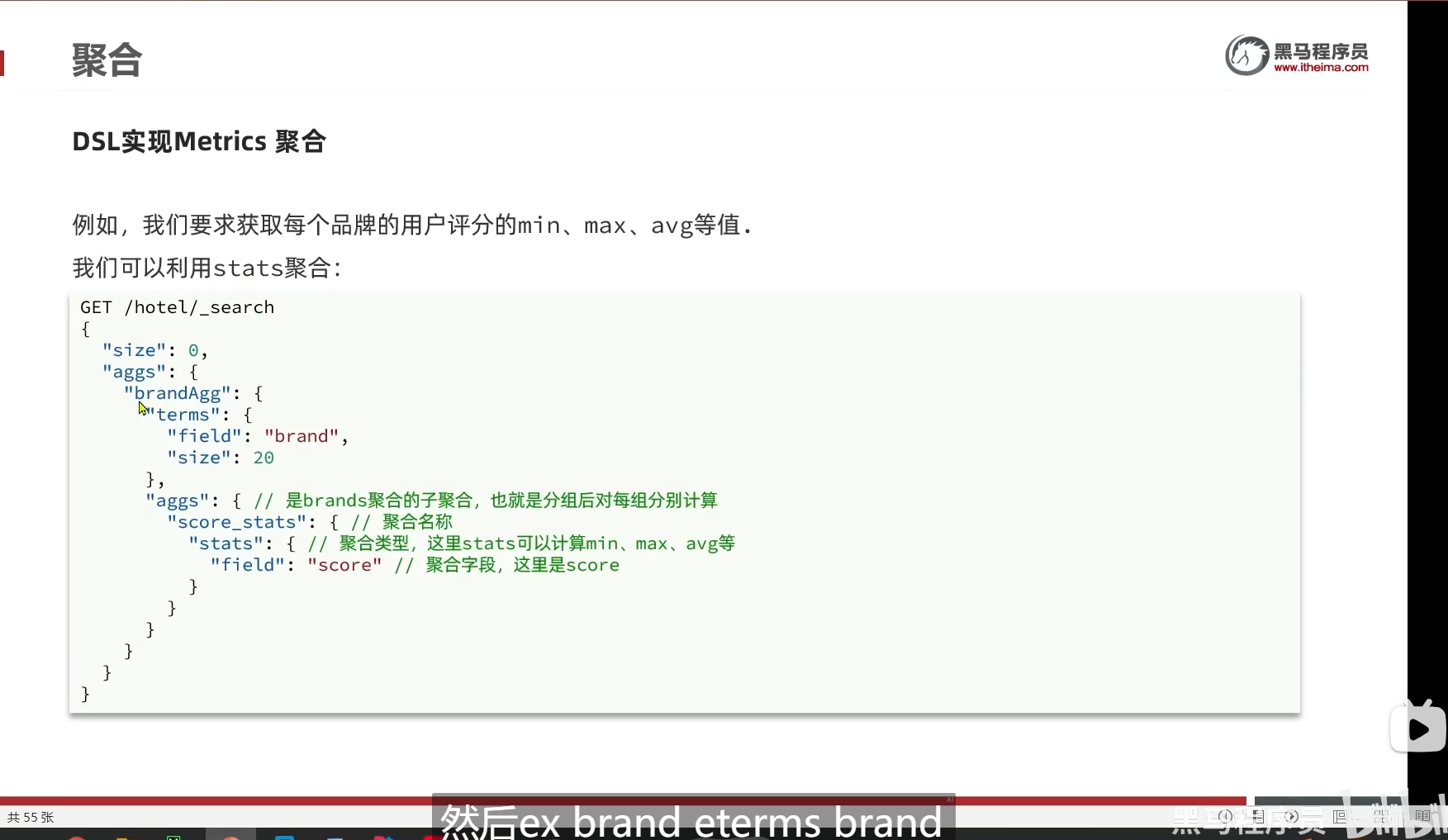
嵌套聚合
我们做了嵌套聚合
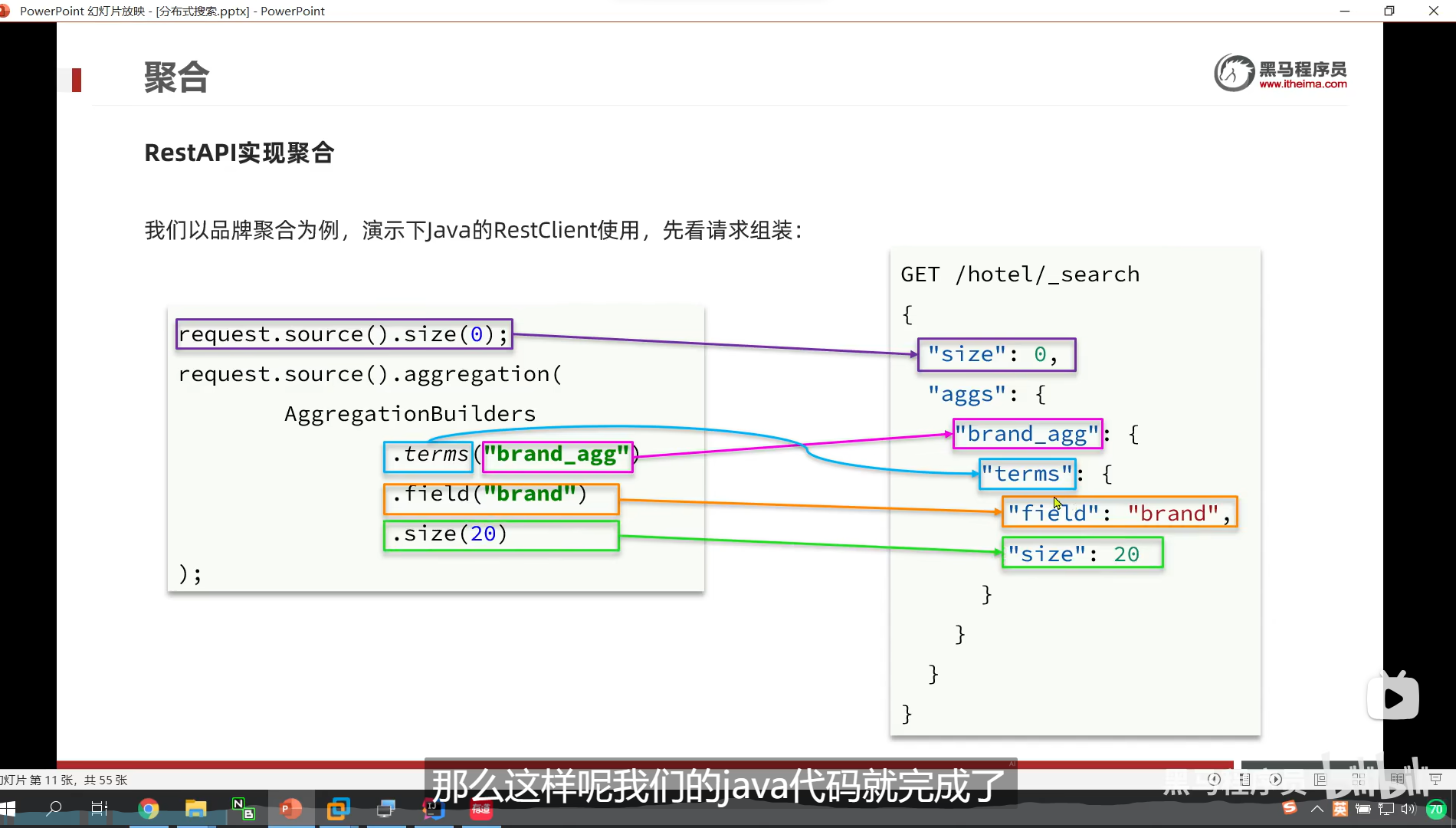
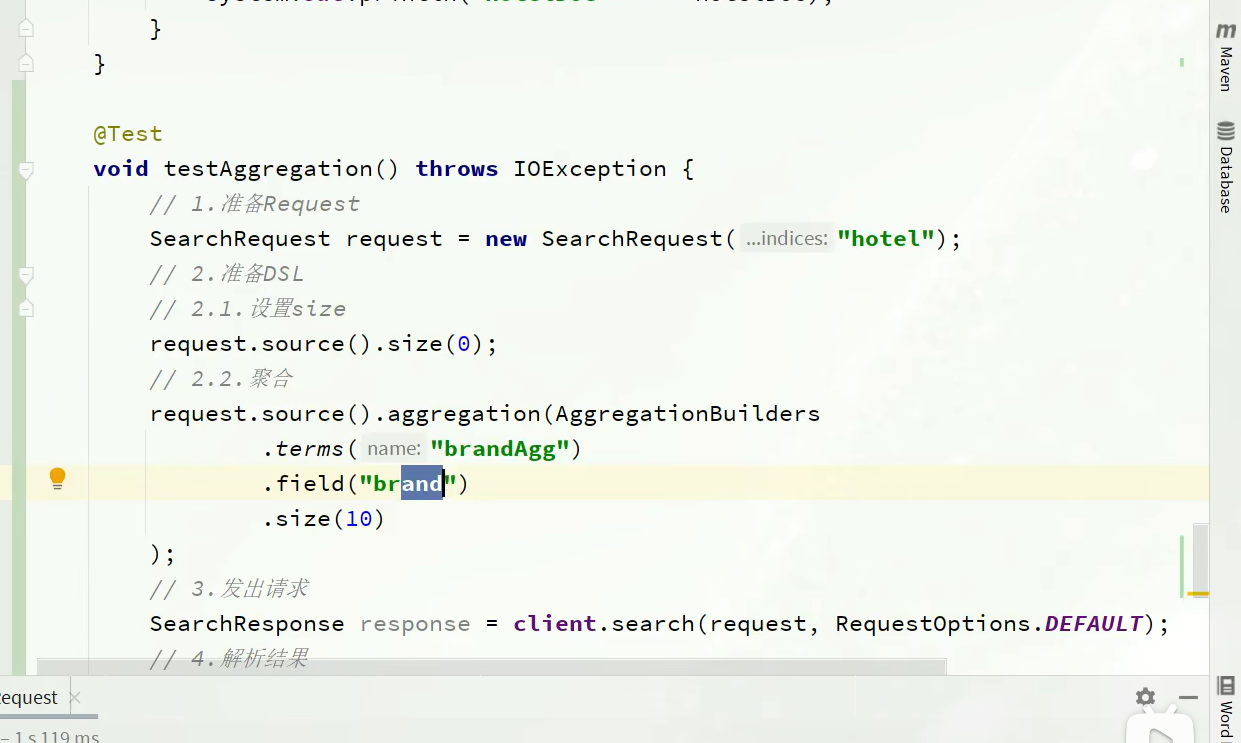
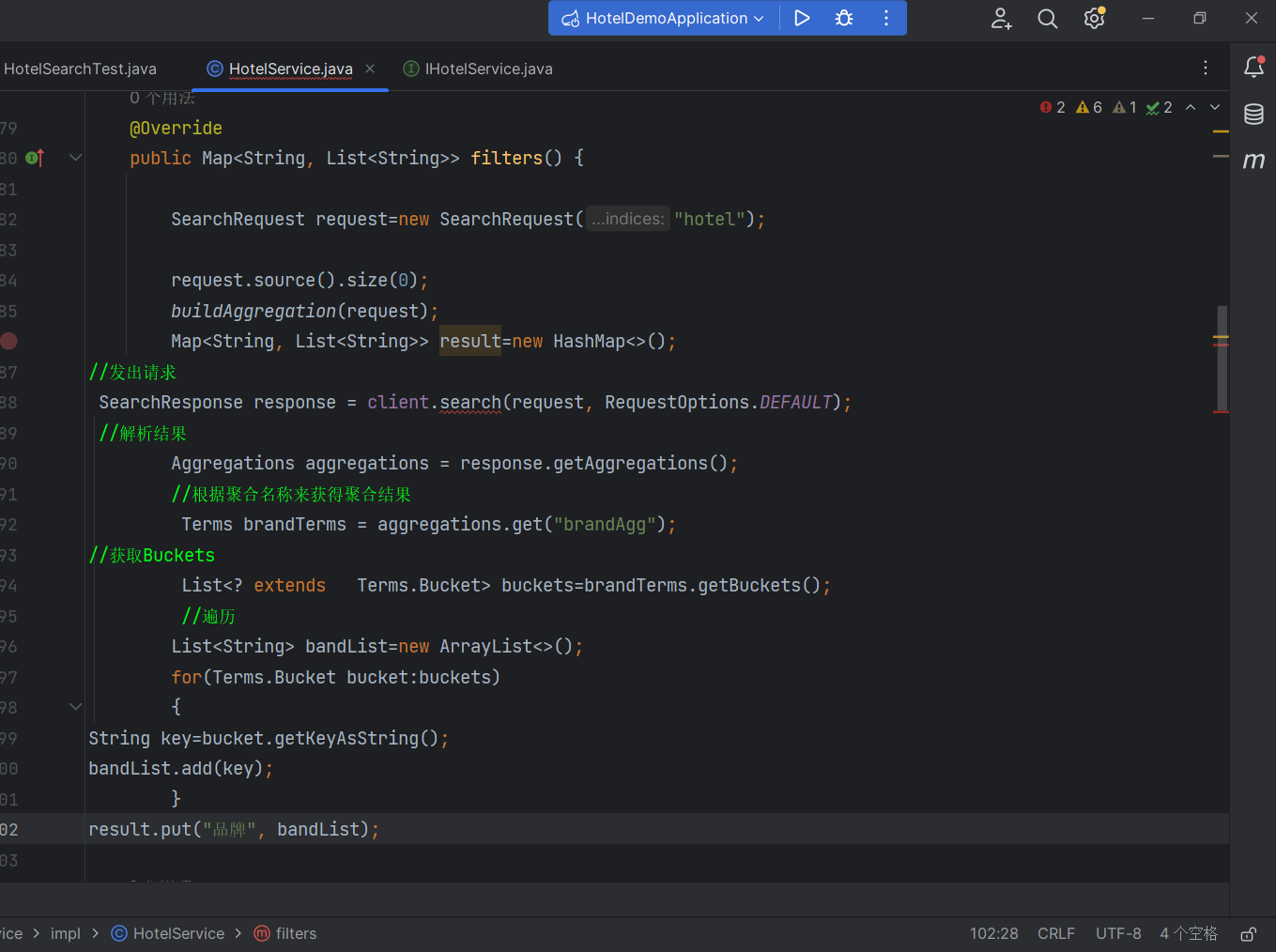
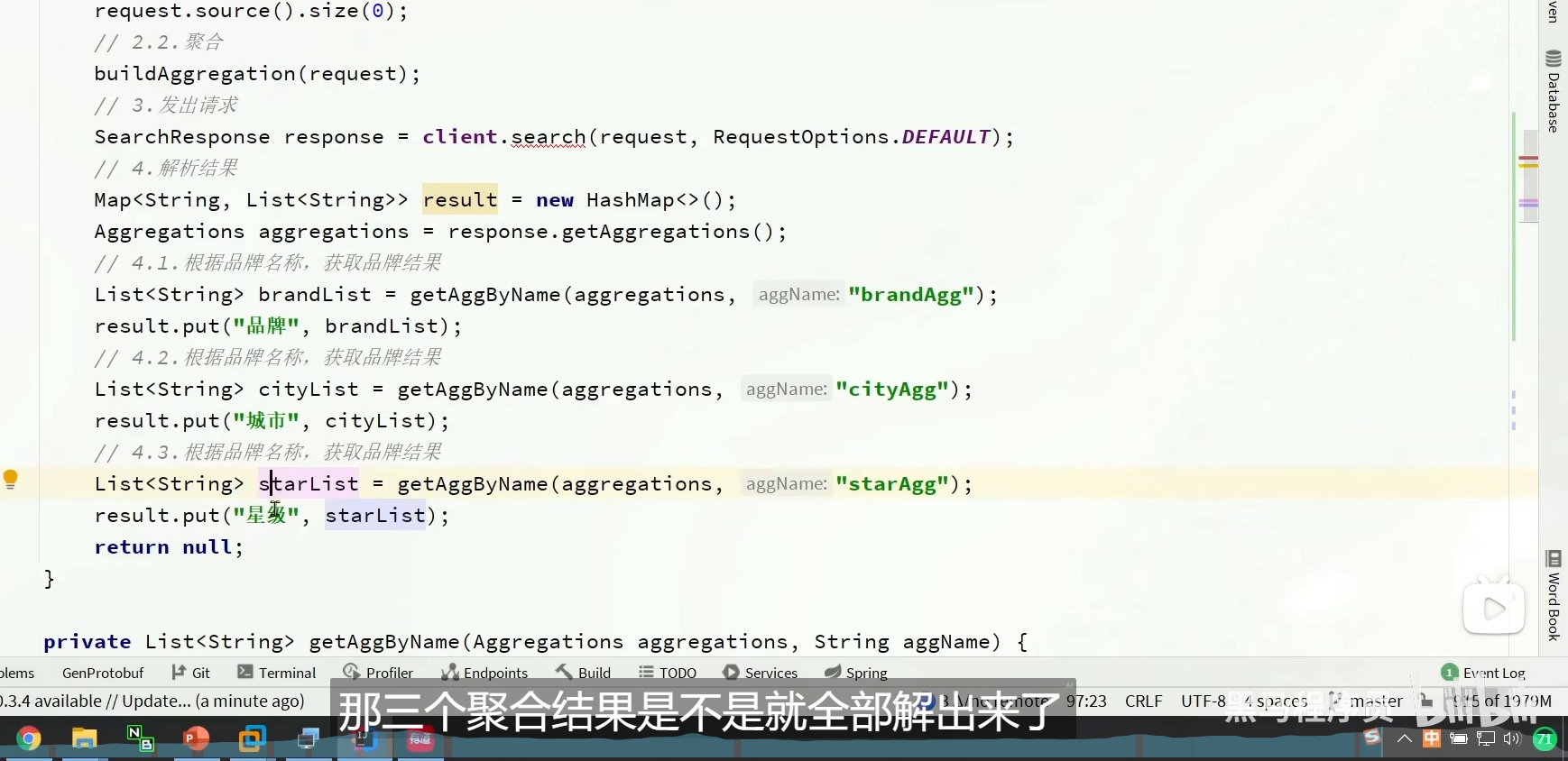
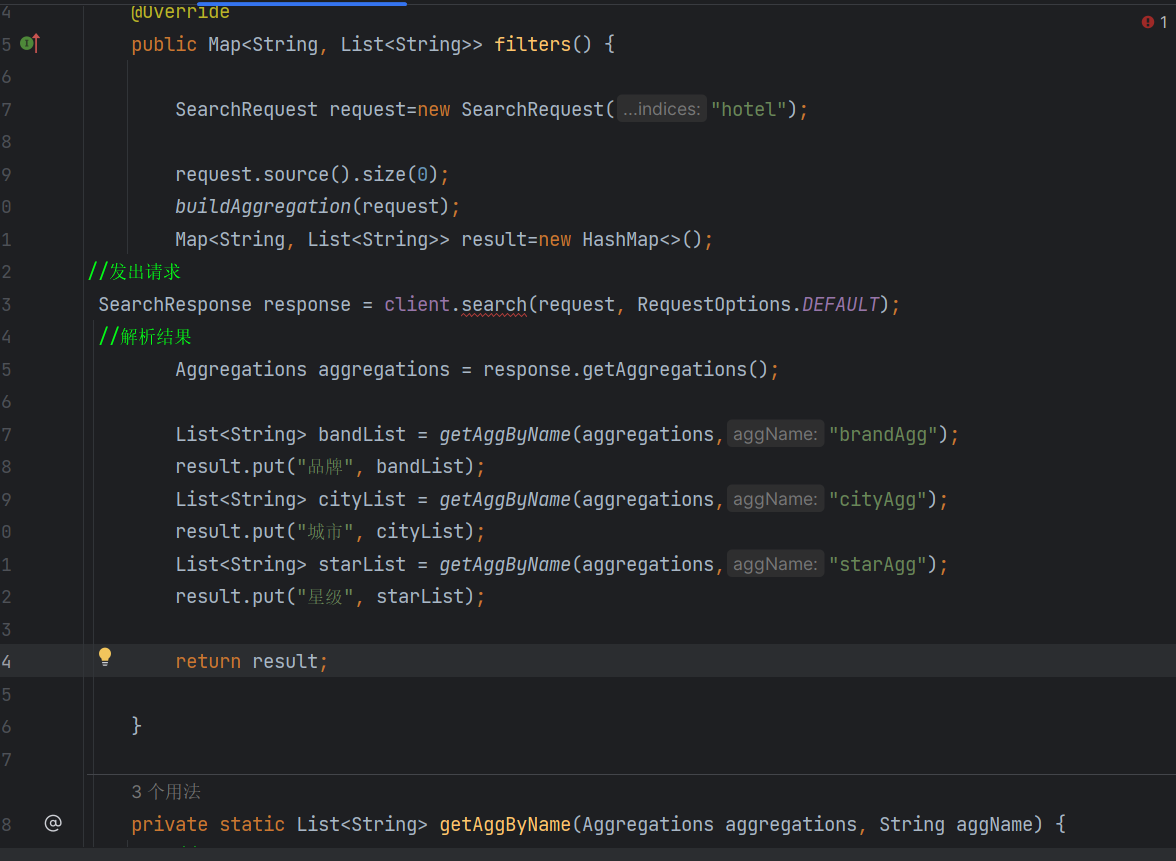
Restclient实现聚合
aggregation
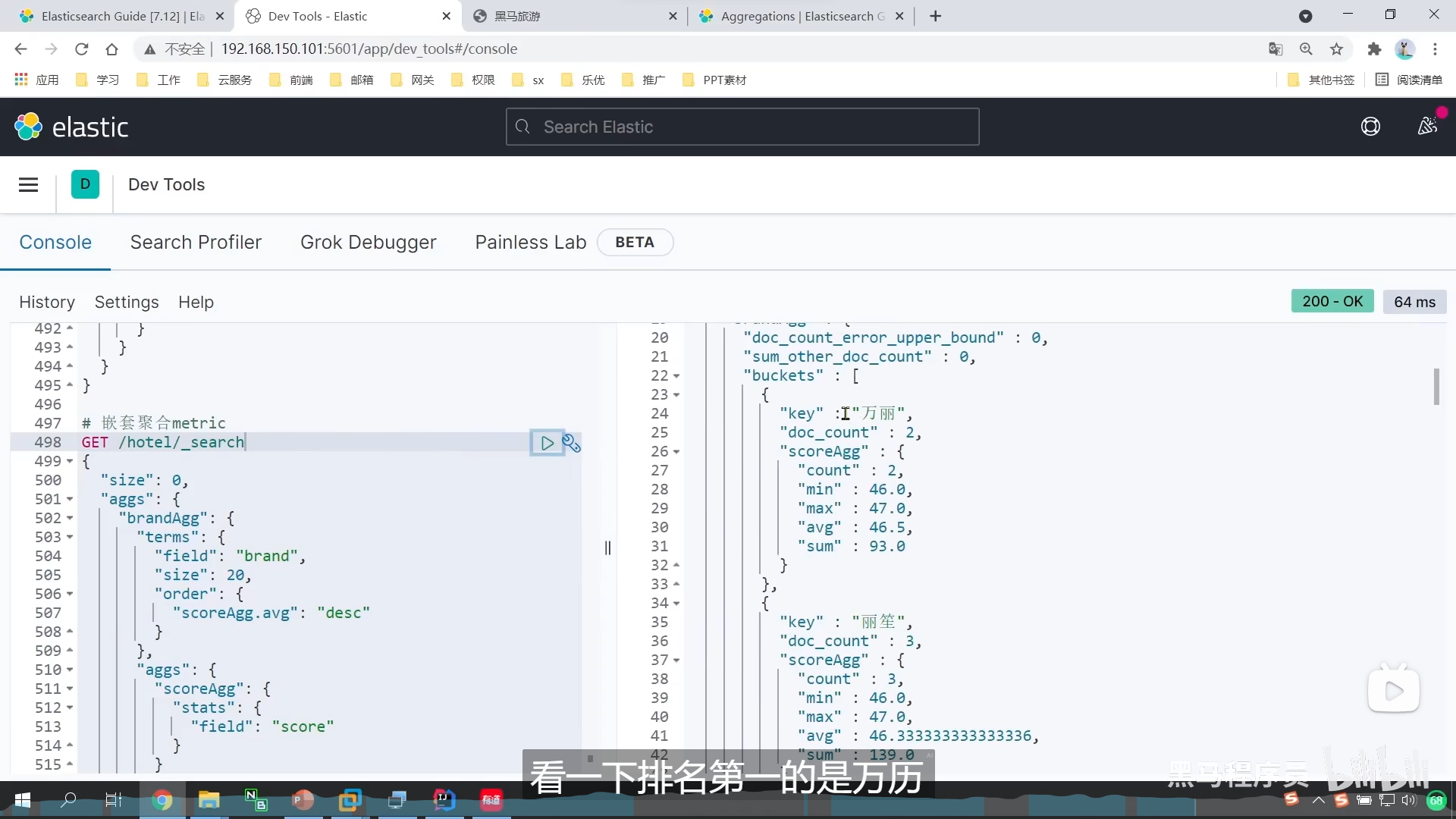
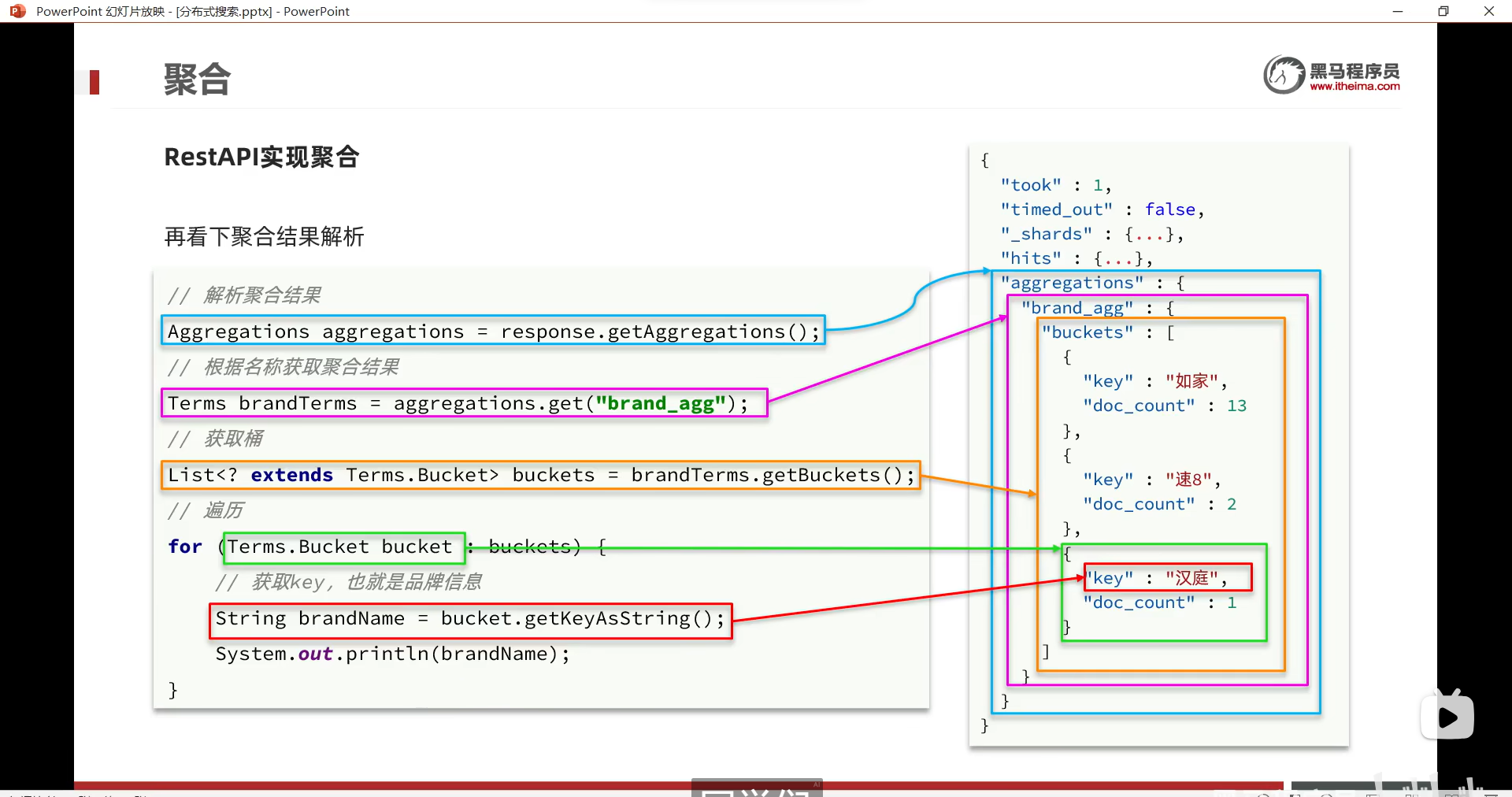
这是我们弄聚合
我们解析聚合
response.getAggregations()
多条件聚合
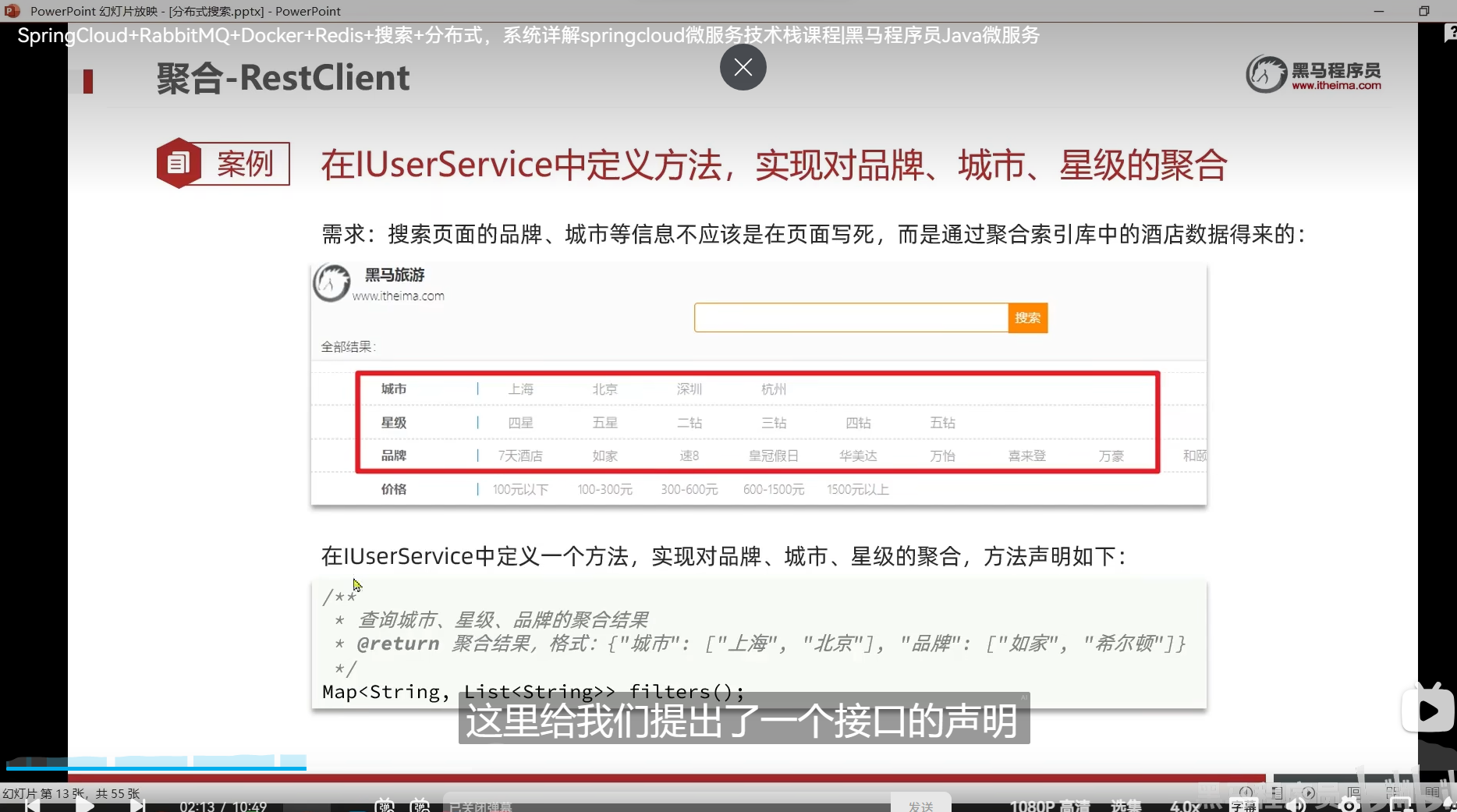
我们不想让我们的过滤条件是写死的,所以我们的标签应该做的是动态变化
点一个标签,其他标签会跟着变化
索引库中包含了什么东西,我们就要展示什么东西
所以我们要根据这个标签字段做聚合,这样子就知道我们的ES索引库里面到底包含了什么东西
在接口中定义方法
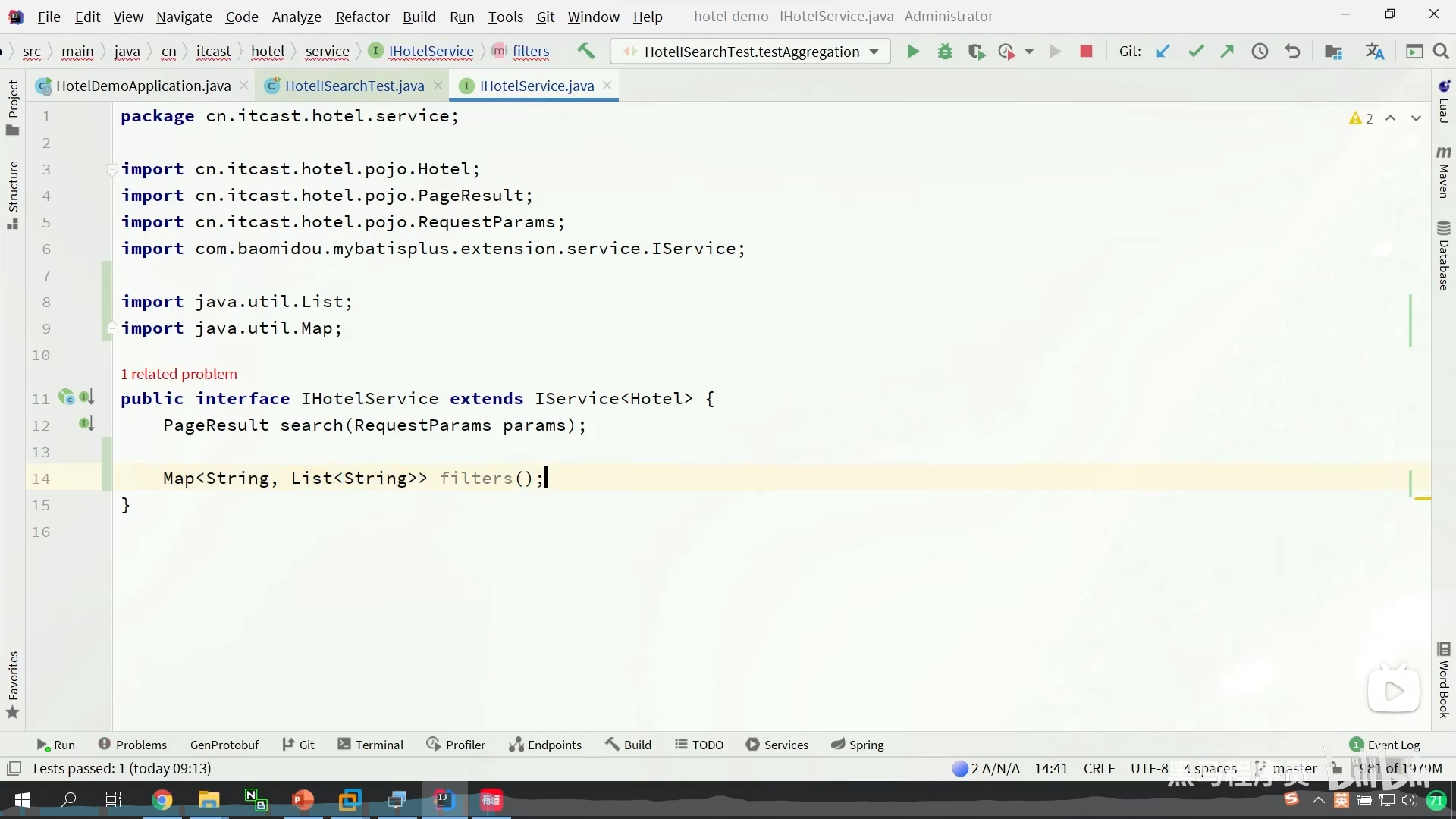
然后我们要对这方法进行封装
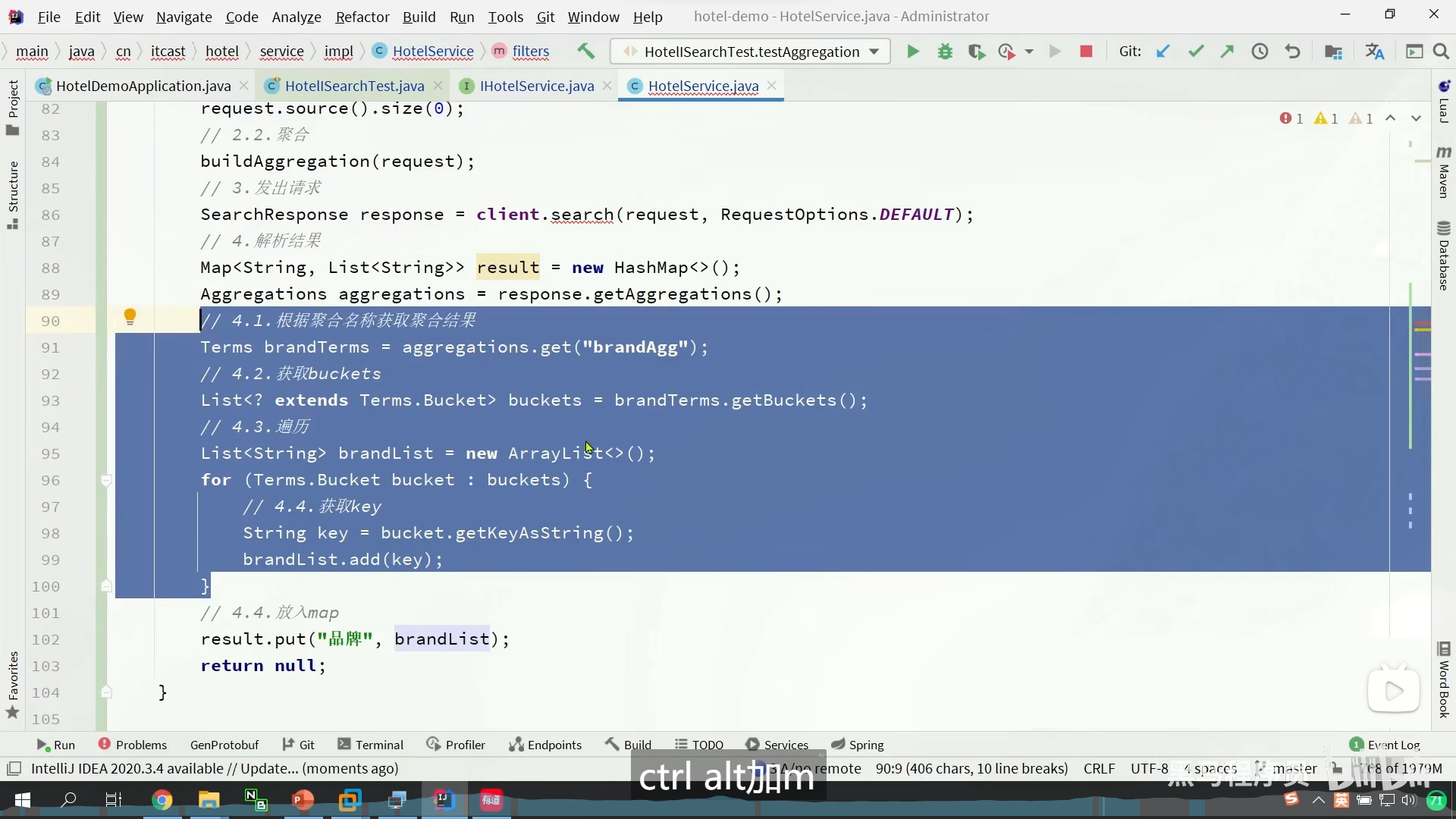
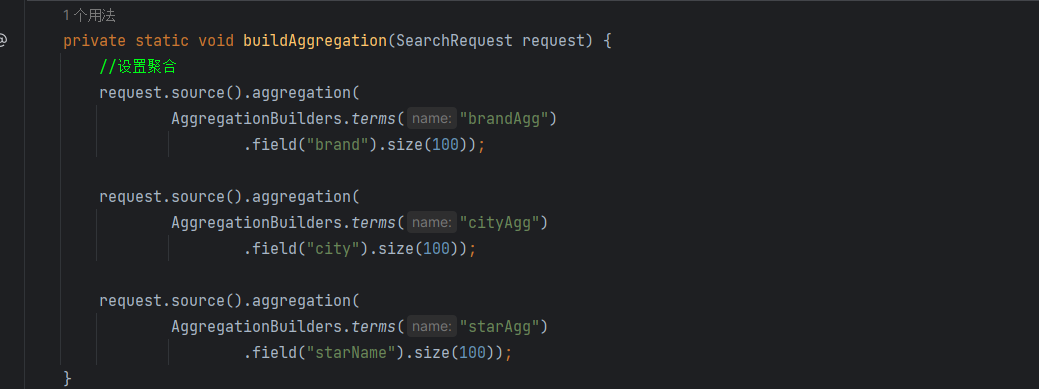
带过滤条件的聚合
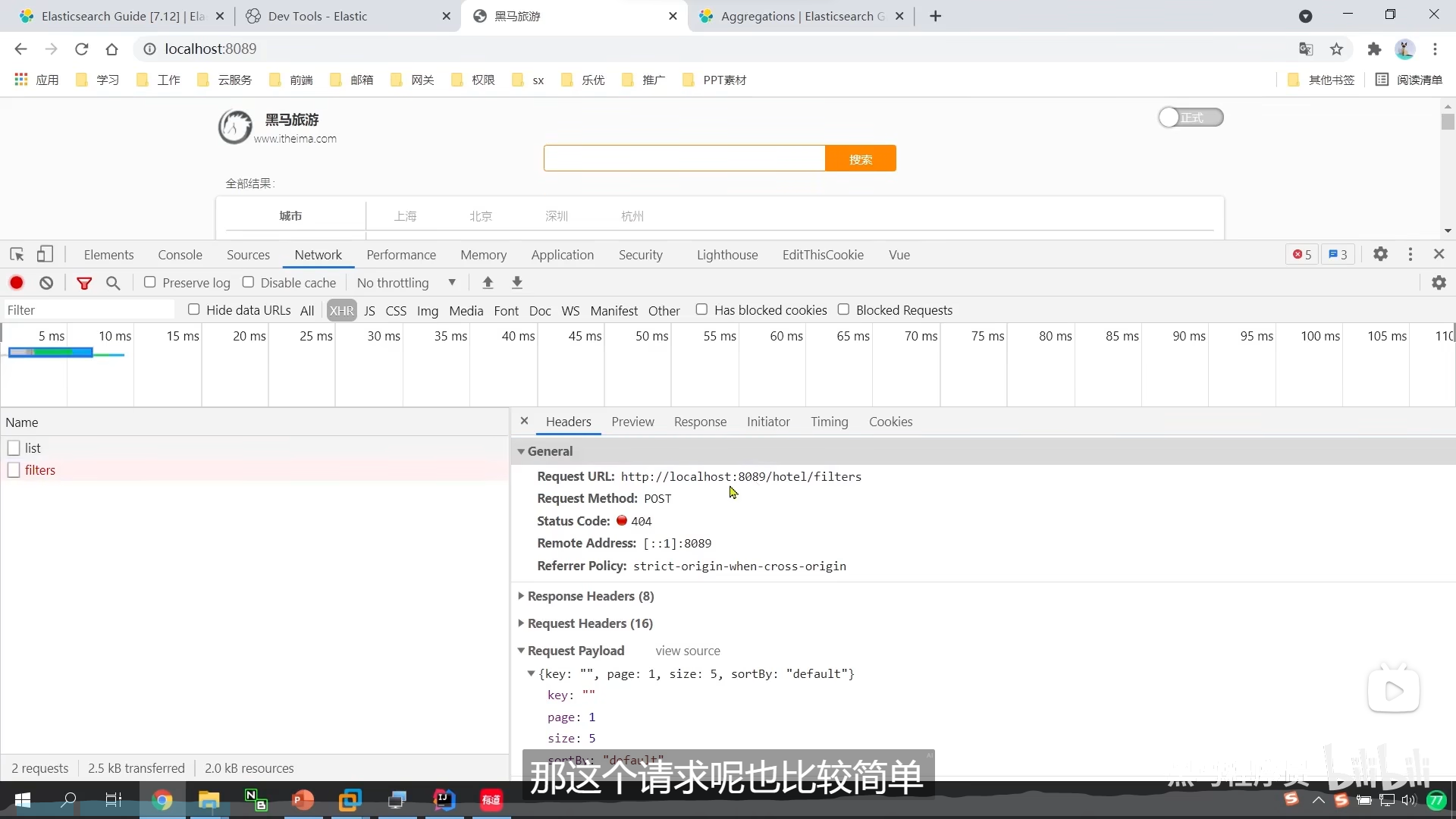
我们的标签项目 是filter
我们的搜索项 是list
我们按一次标签就发起一次filter请求
但是我们的list,也要结合我们的标签发起请求
为什么这两个的参数一摸一样呢
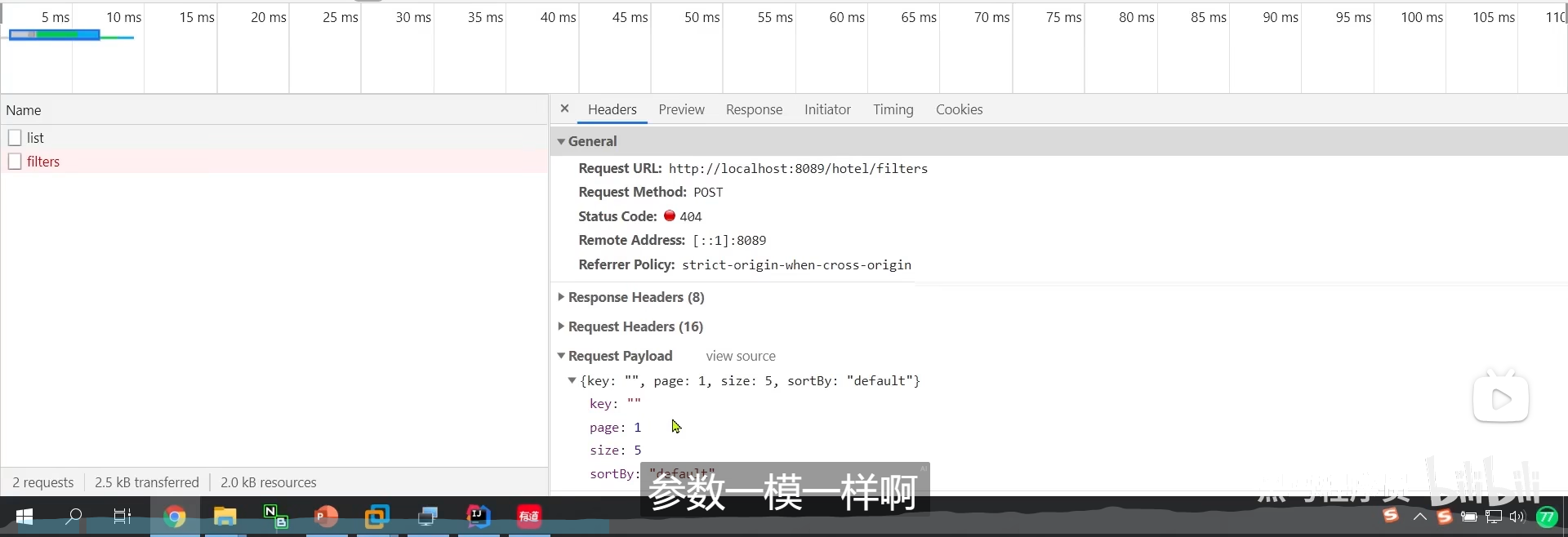
为什么我们在查过滤项目的时候也要条件呢
这是在限定聚合的范围
为什么要限定范围呢?我直接对整个索引库聚合不就好了?
我们搜虹桥
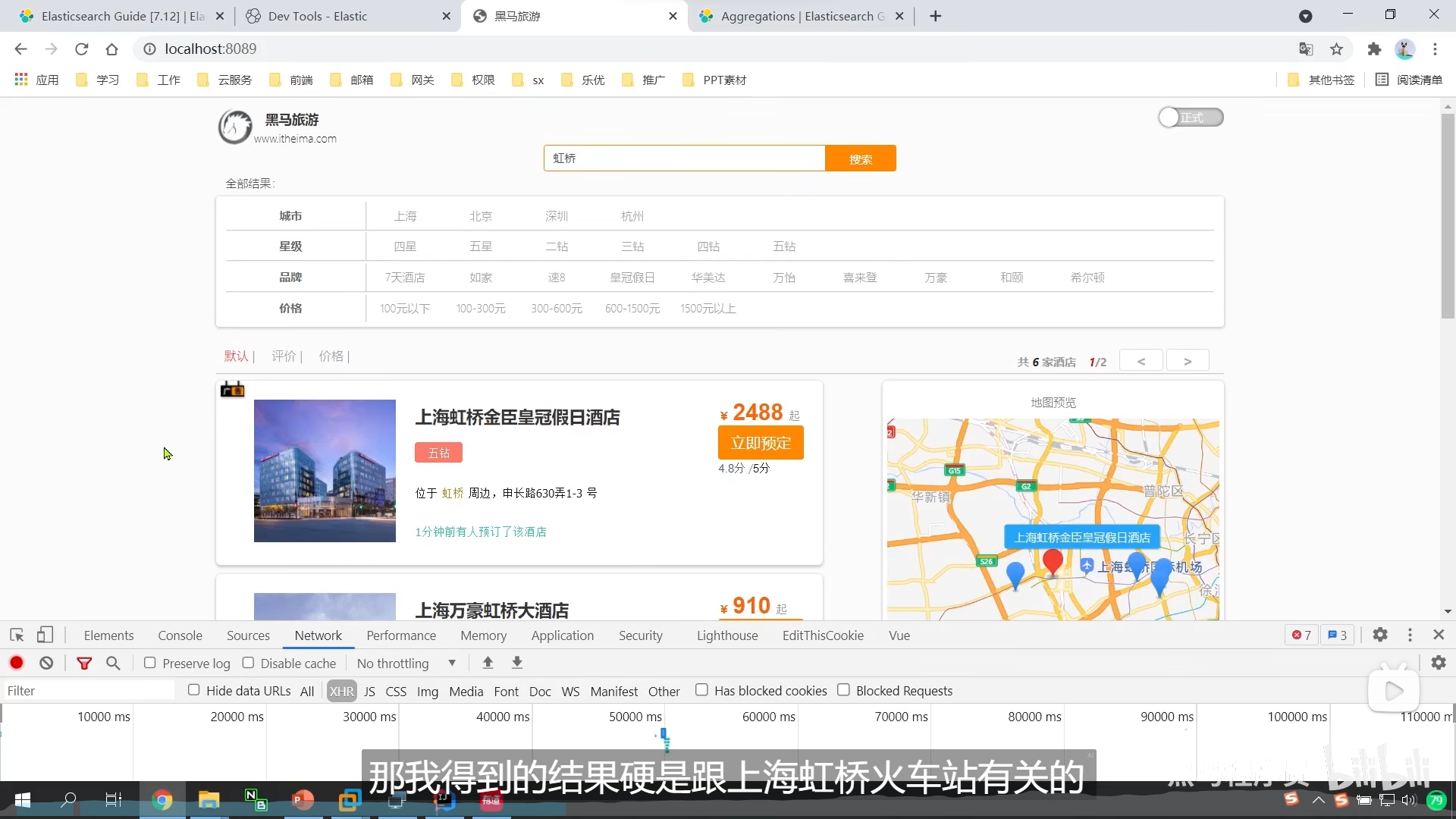
和上海虹桥有关的,对应的就是上海
但是我们却对所有数据进行了聚合,那肯定就包括了所有城市
也就是说,我们搜上海虹桥
那么我们的标签应该只剩下一个城市上海
但是标签它还是那么多
因为它是对整个索引库做聚合的,所以我们的标签是固定的,但是我们不想对整个索引库做聚合
我们要对我们的搜索的结果做 标签的聚合
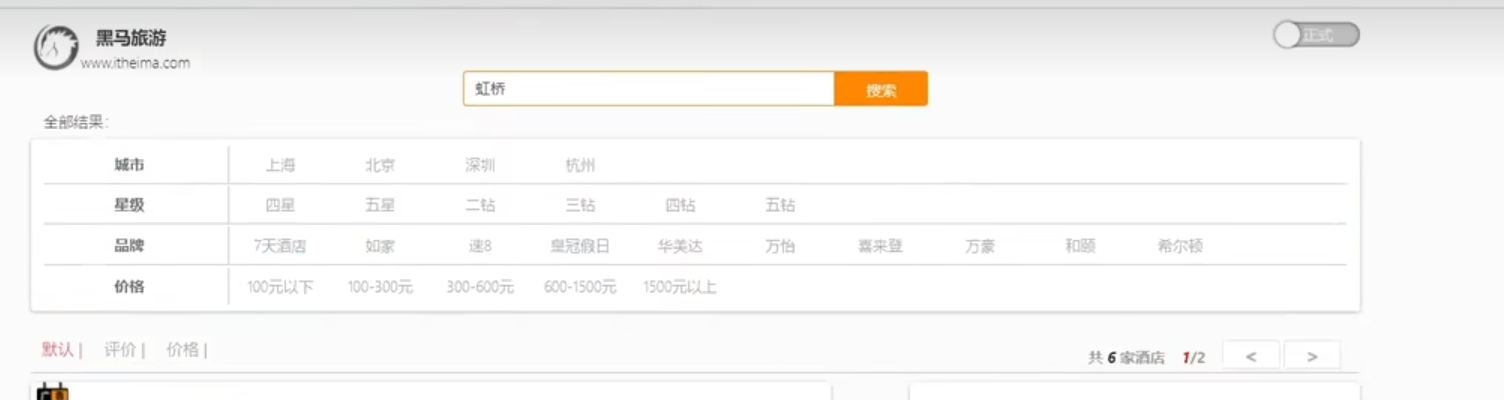
我们查酒店,那么我们的聚合应该是对我们的酒店搜索出来的结果做聚合的。
我们的聚合必须是在搜索条件的基础上完成

我们要做的是,给我们的标签的聚合,做过滤项,限定我们的范围

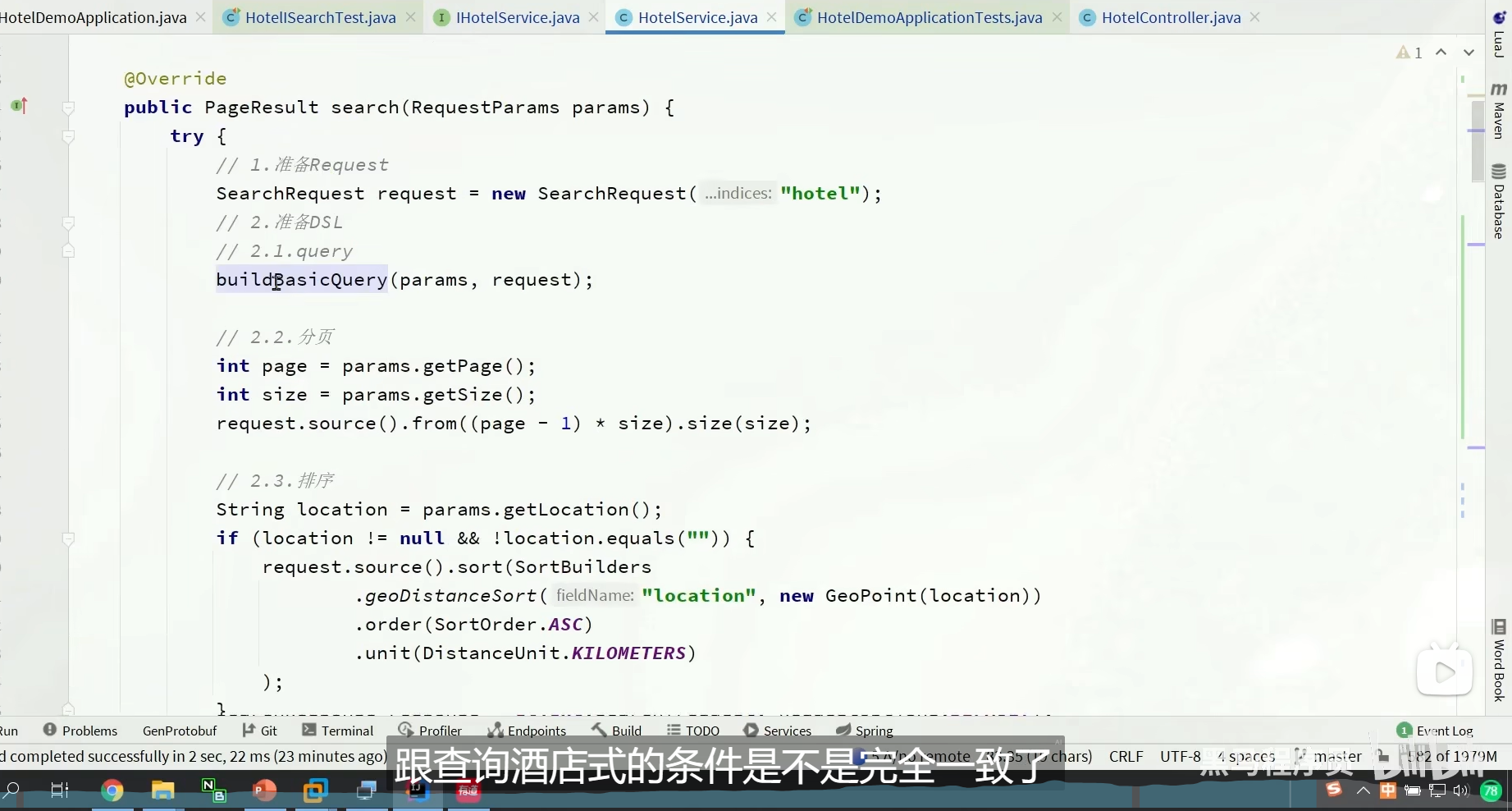
把之前的copy过去
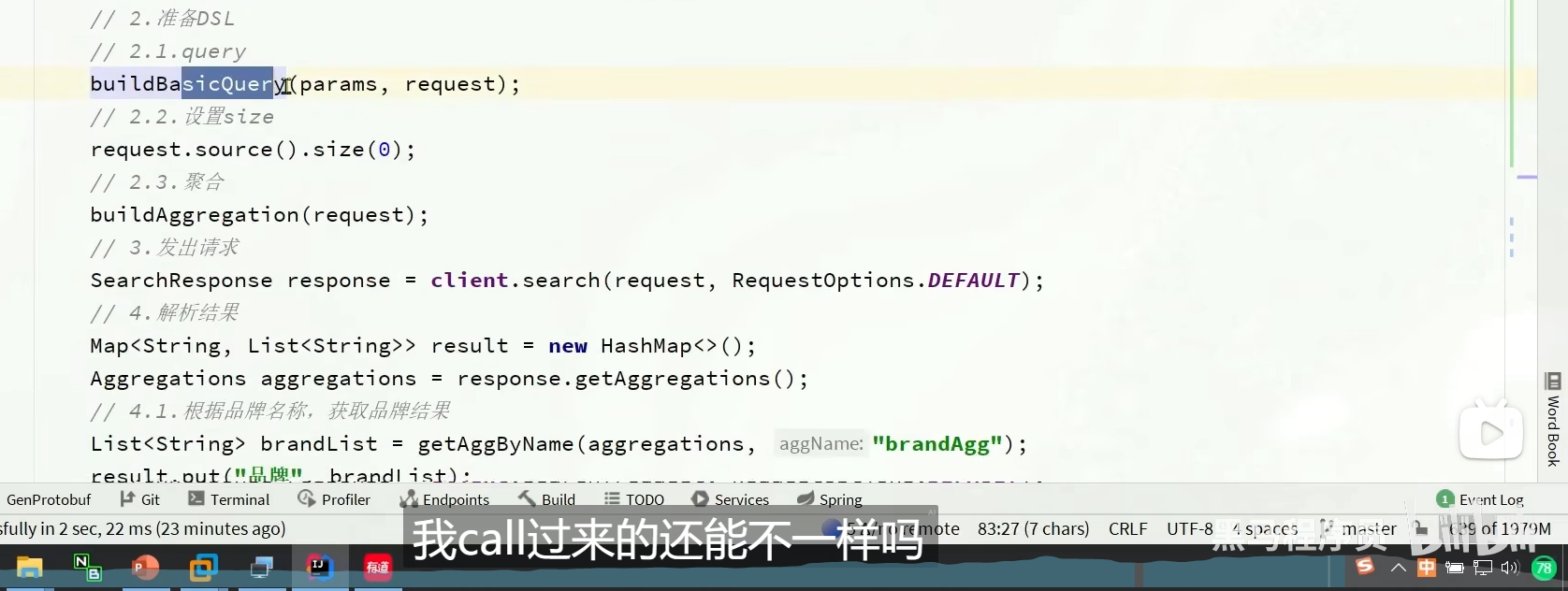
、
动态过滤项
我们虹桥只有上海,那我们搜索虹桥的时候,我们的城市选项直接没了
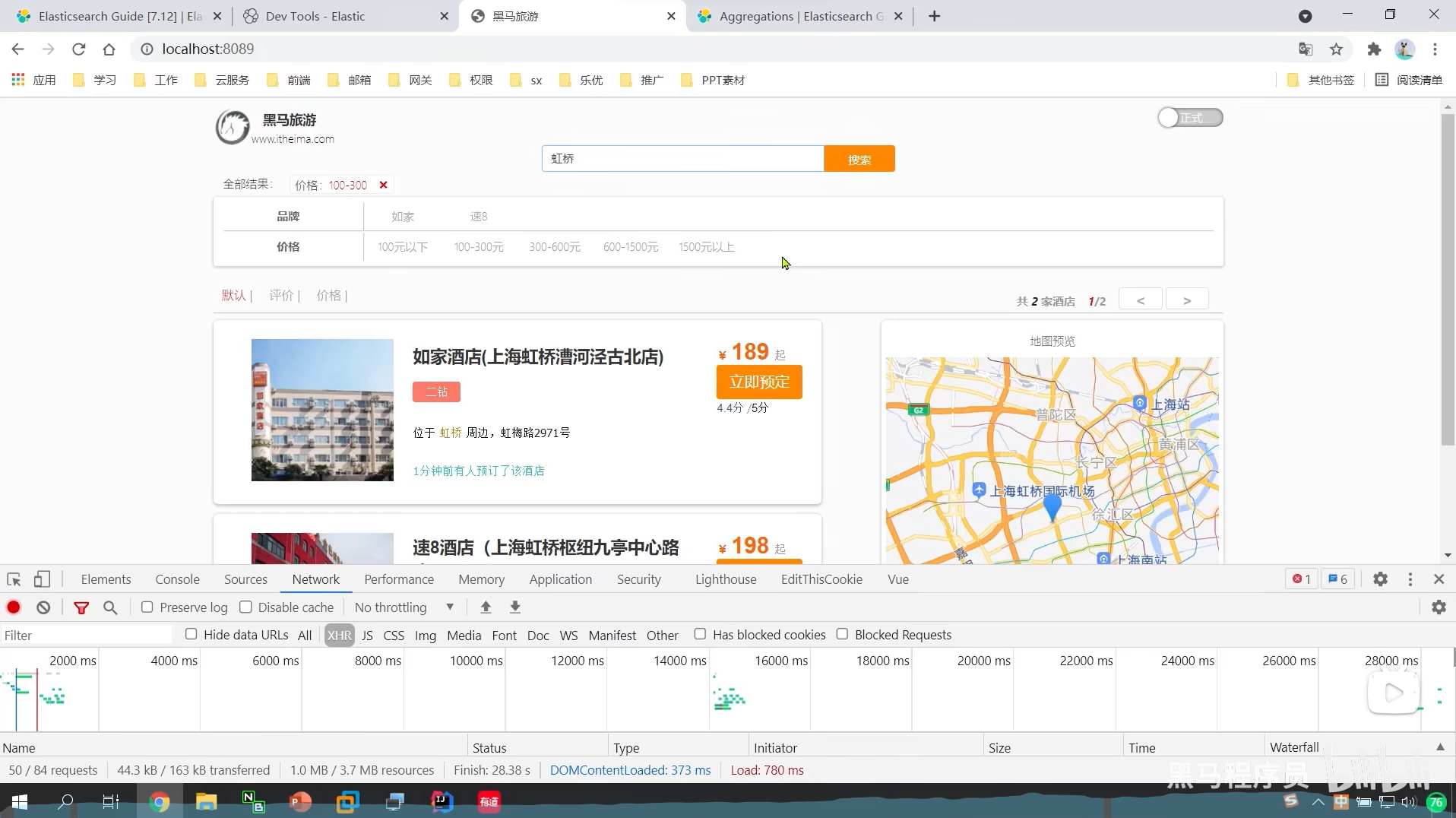
这就是我们的动态过滤项
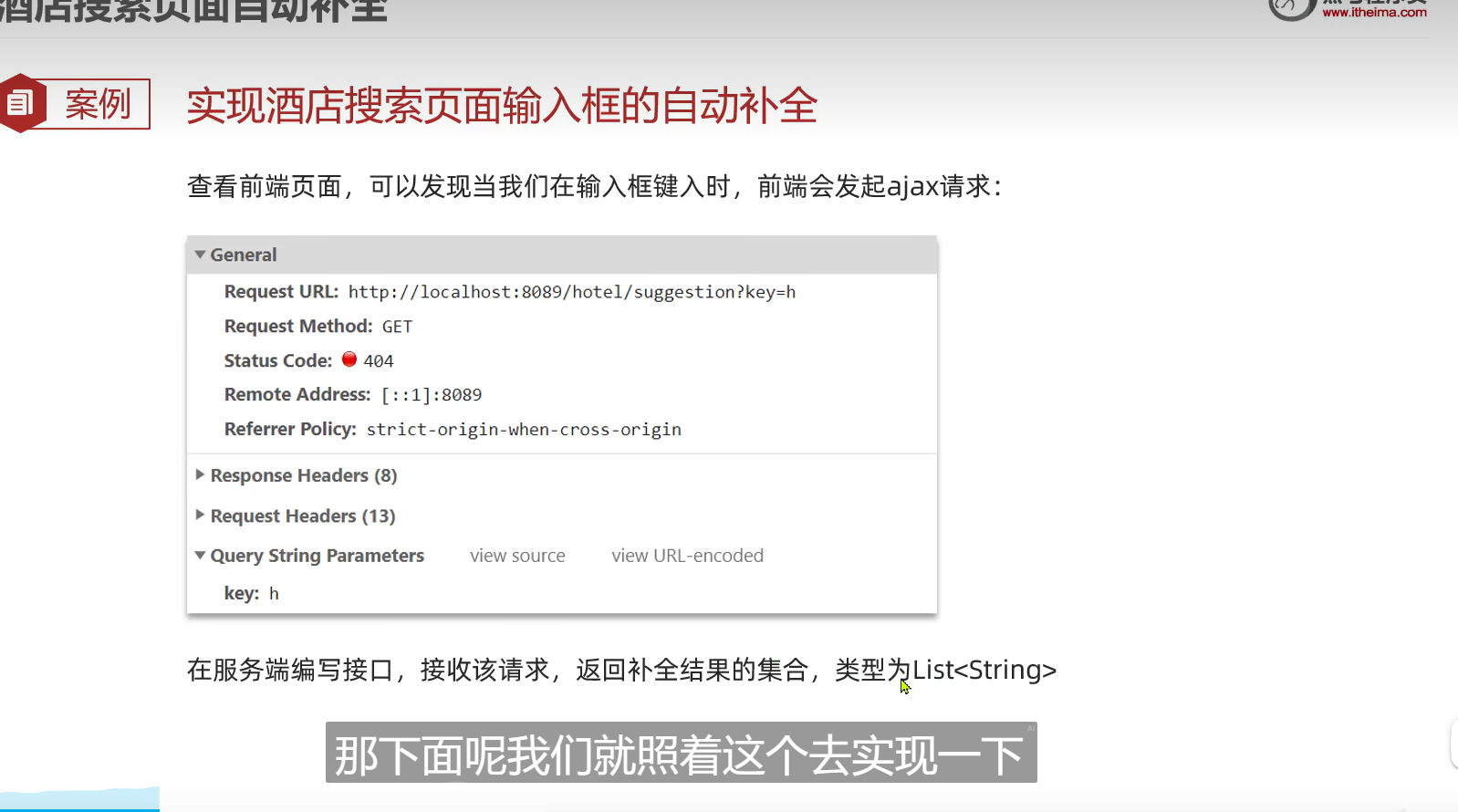
自动补全
安装拼音分词器
这样就说明我们的拼音分词器安装成功了
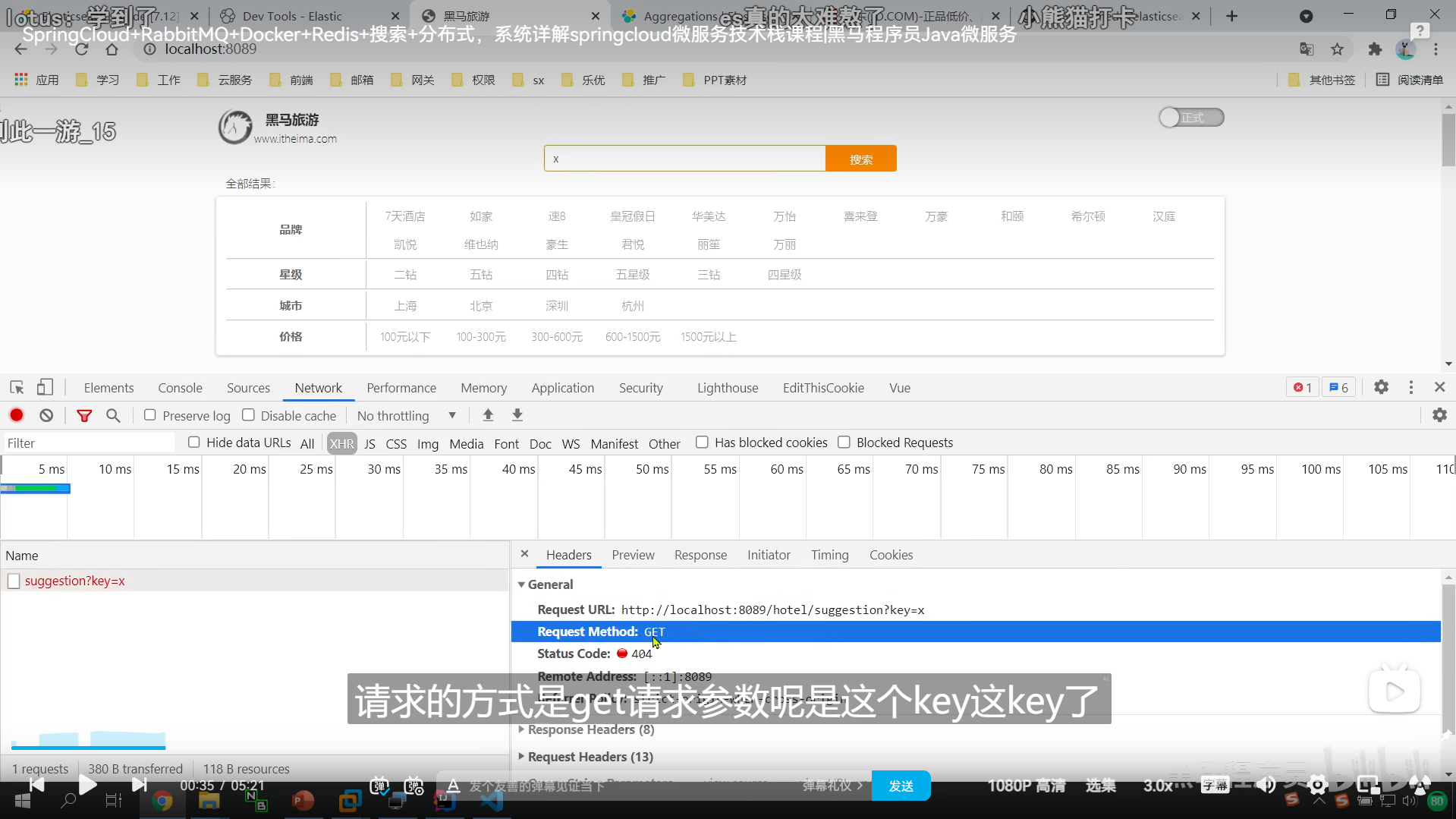
发送不了post请求我们可以发送get请求,因为会有报错,所以我们根据ai来修改就行了
自定义分词器(解决搜索时,狮子和柿子都转成拼音shizi从而搜索错误的问题)
拼音分词器不会分词

这个是全拼首字母
而且里面没有汉字只剩下拼音,大多情况下我们都是中文搜索占多数,拼音只是锦上添花的一个东西
所以我们要自定义分词器
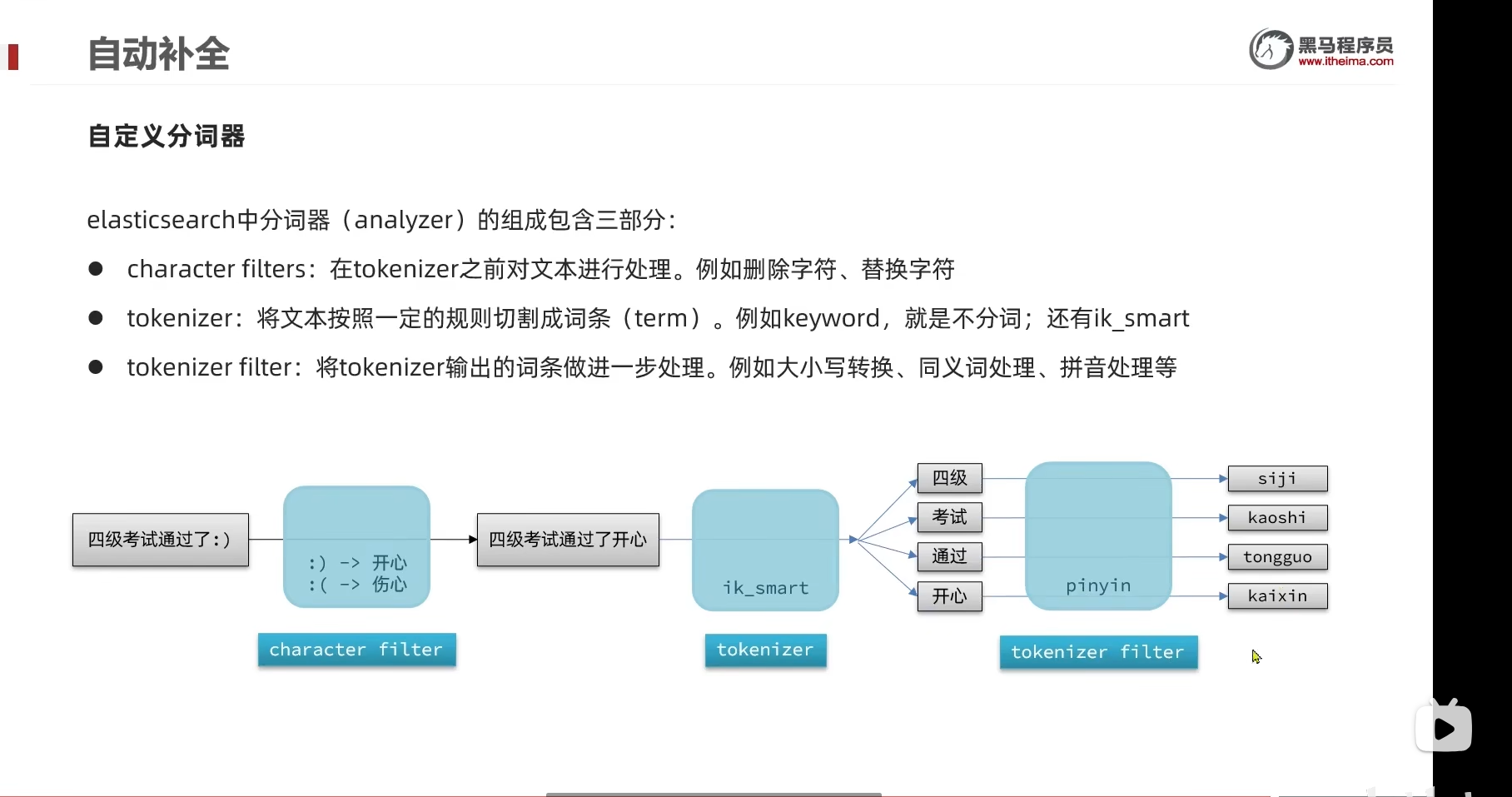
分词器由这三部分组成
首先先对文本进行处理(删除和替换)
然后分词
然后对词条做进一步处理
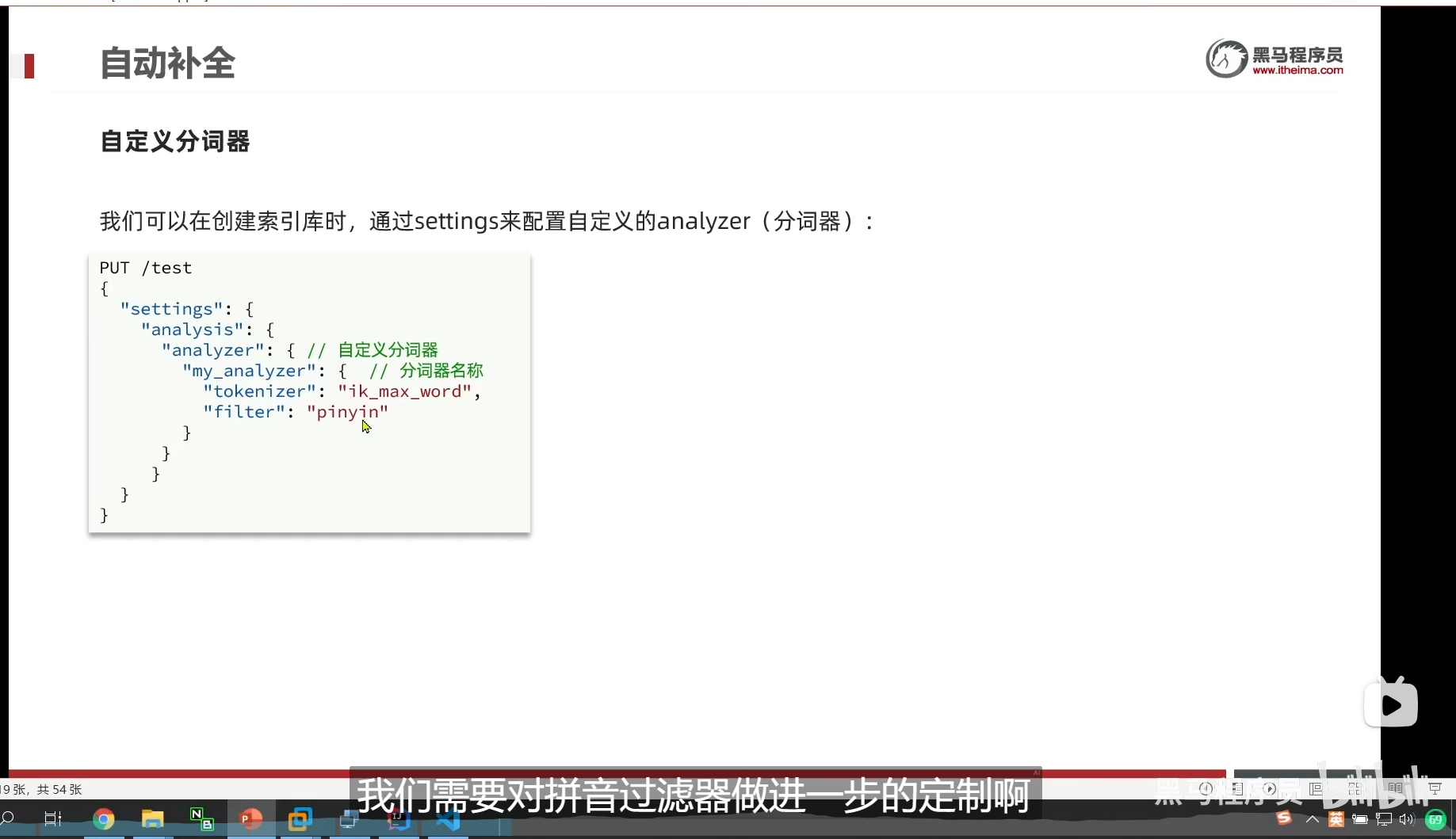
我们先分好词
然后再交给我们的filter 拼音去处理
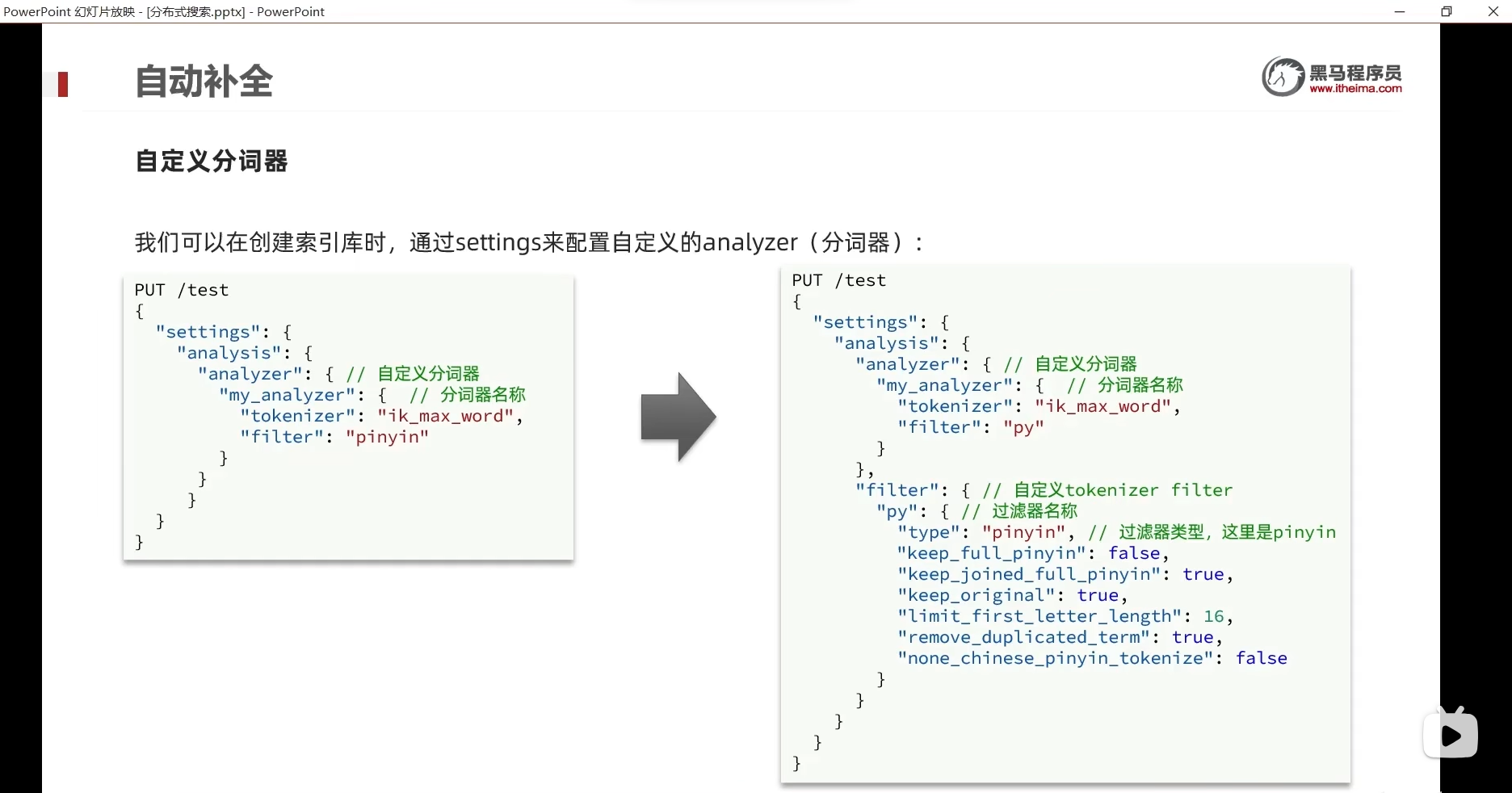
我们一开始那样也是不对的
拼音分词器转成词语的时候
是一个字一个字的转成拼音
还会把中文给去掉删除
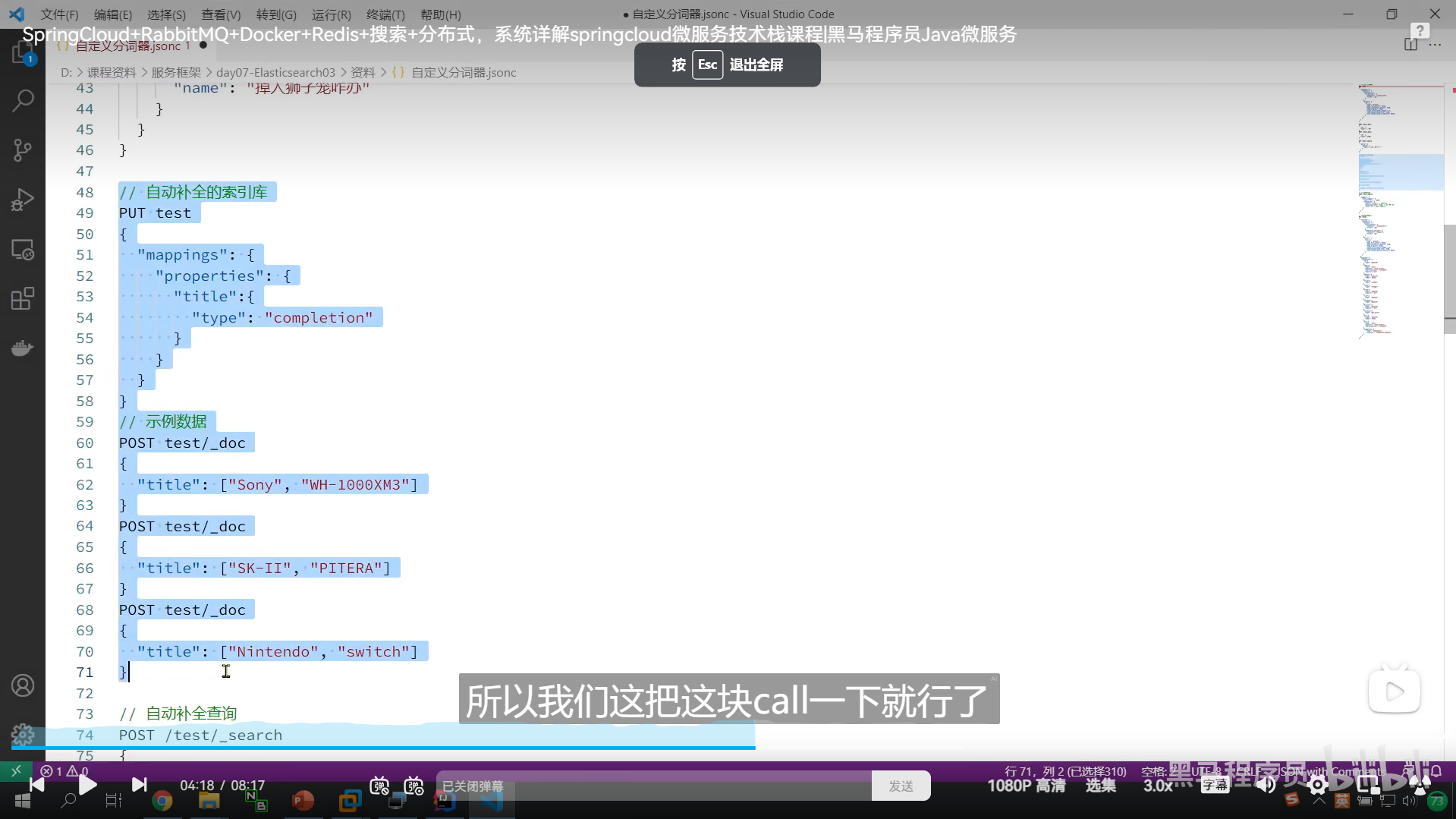
拼音分词器官网上给了很多参数,这些参数可以实现到控制的效果
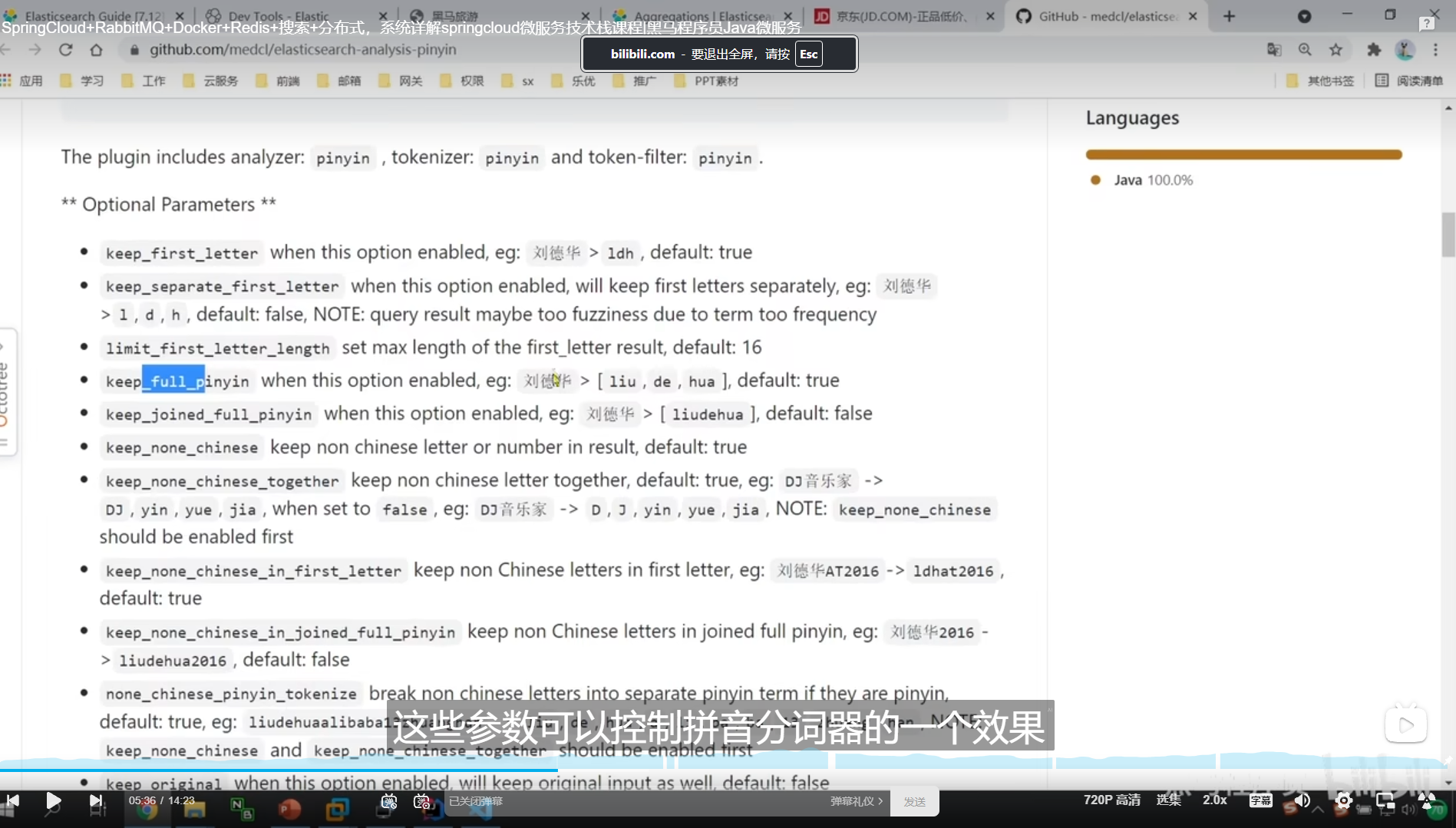
所以我们自己弄了个filter py
里面配置了我们想要的参数
例如保留我们的中文
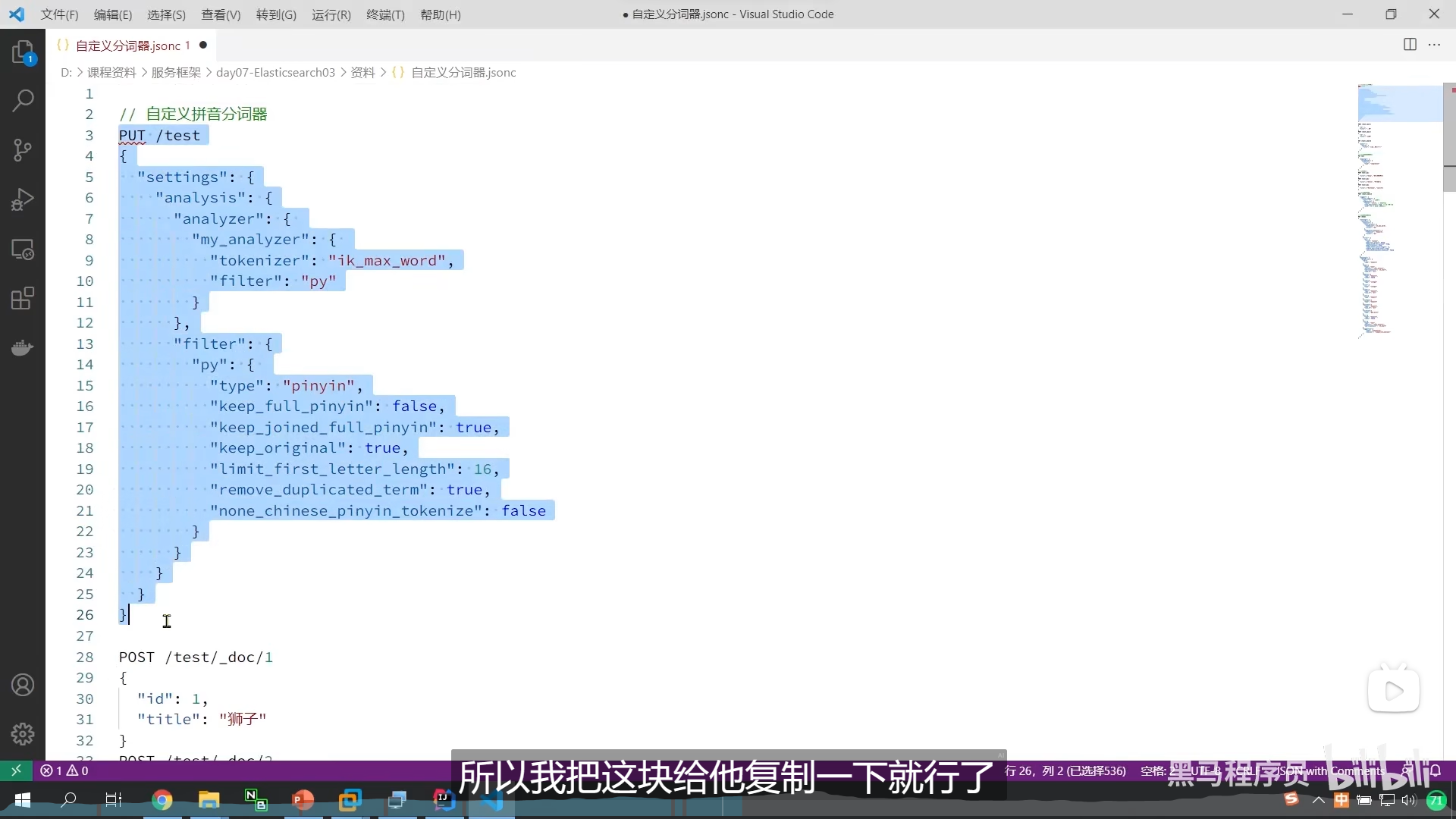
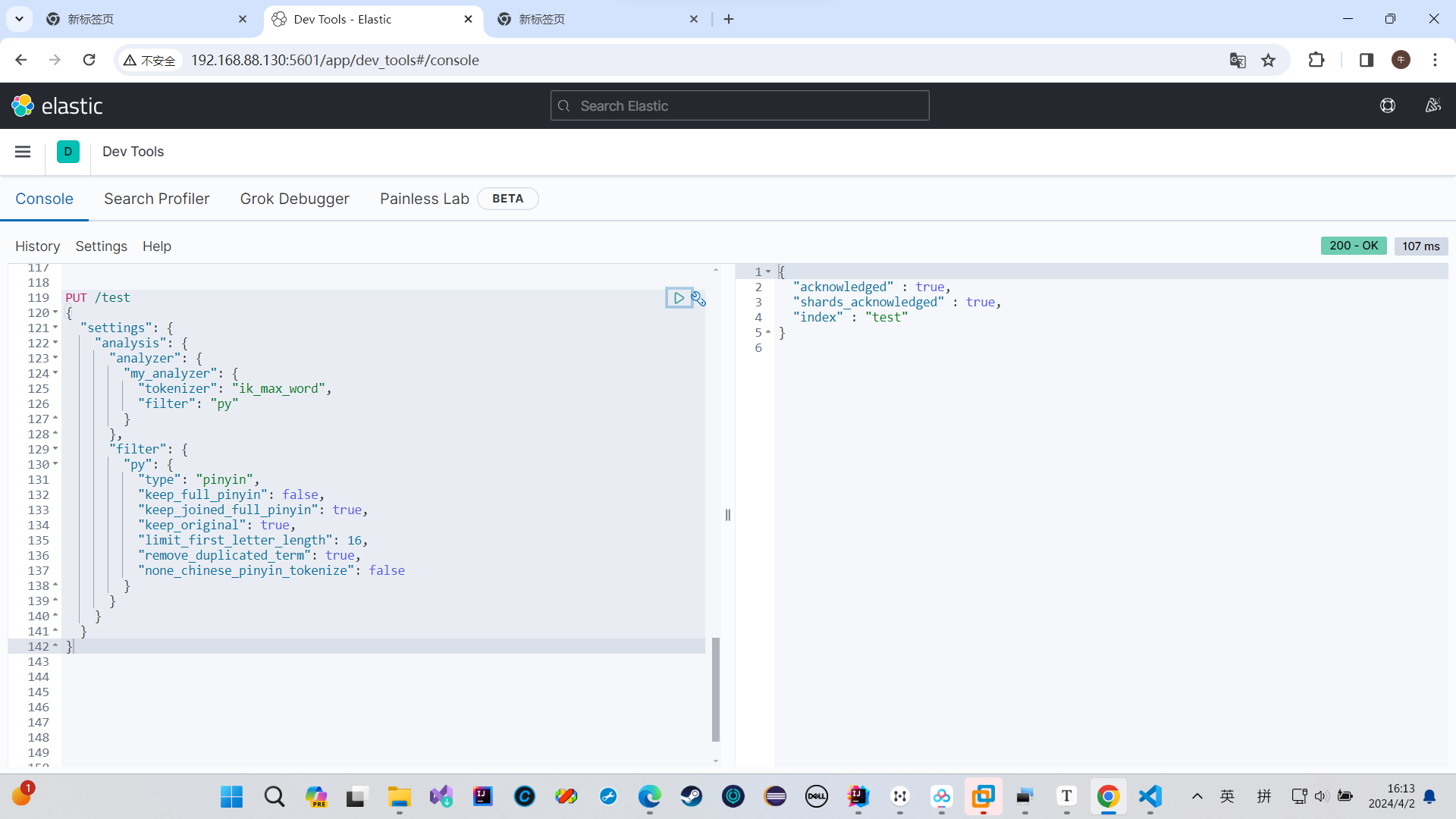
我们弄个mapping映射,这样我们这个字段就可以用我们的自定义分词器去分词了
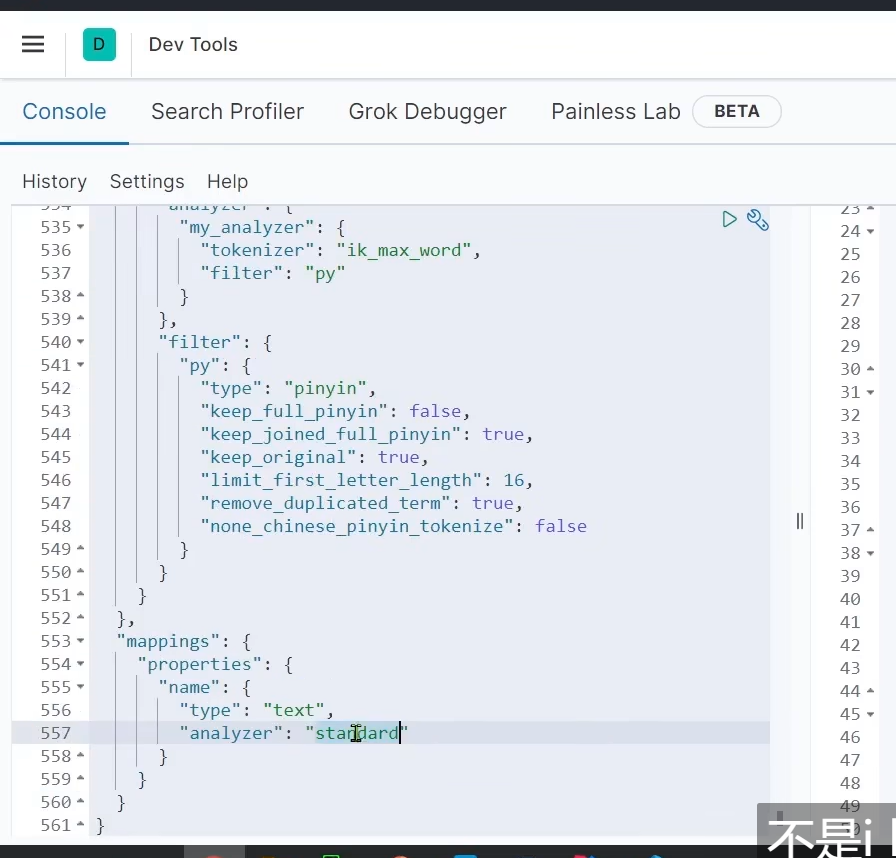
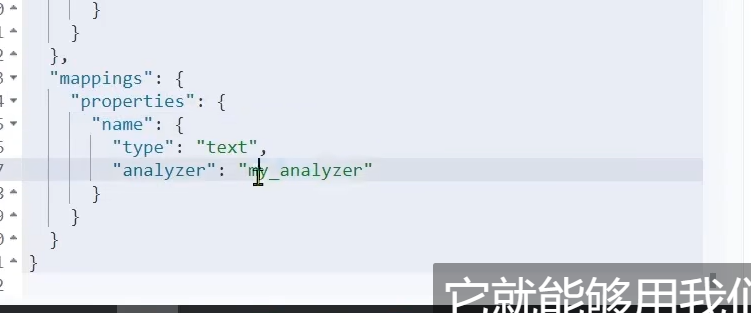
这样子我们分词的时候
我们的拼音和我们的中文都做了分词
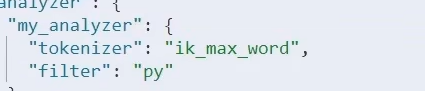

type:“pinyin”
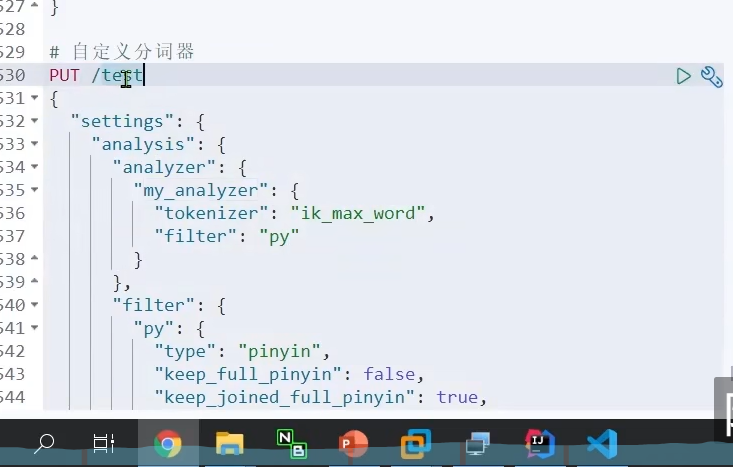
这个settting设置是针对当前索引库的
所以我们在这用不了

除非我们告诉它我们要的是test这个库
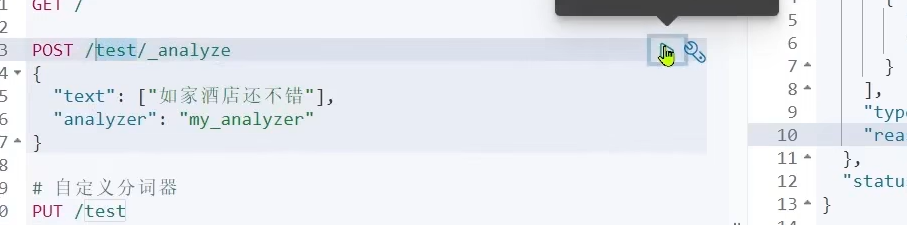
然后我们测试一下
我们还可以拿我们的文档内容做测试
因为我们之前mapping映射的是name字段,所以我们要用name字段
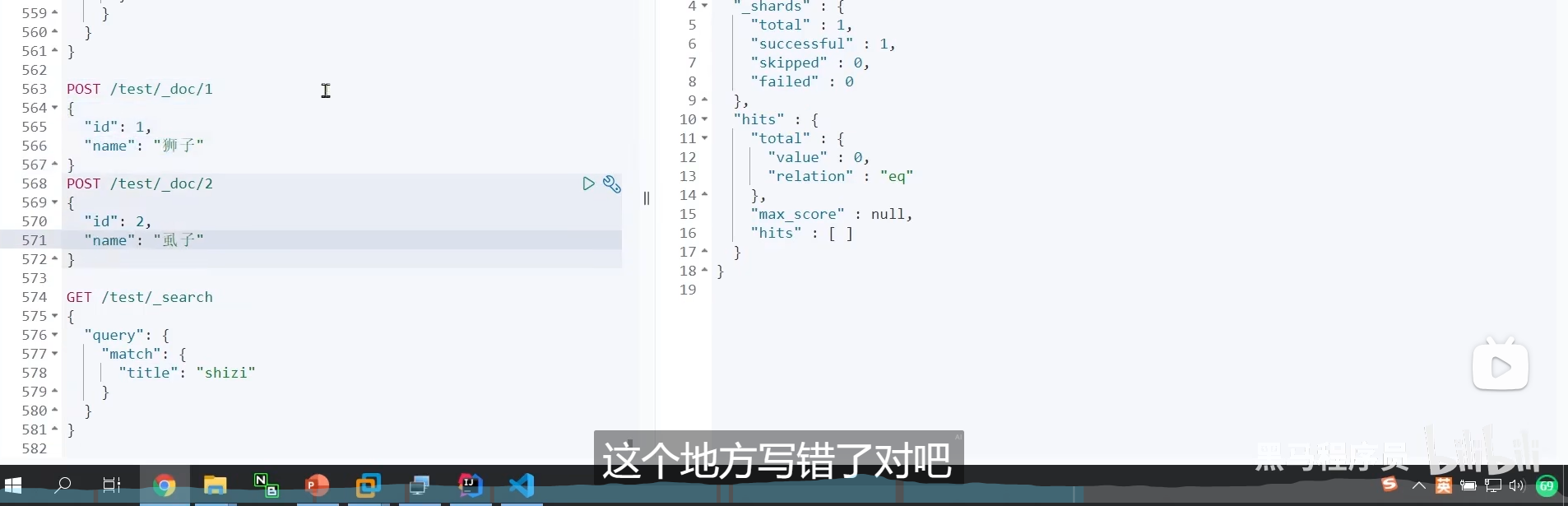
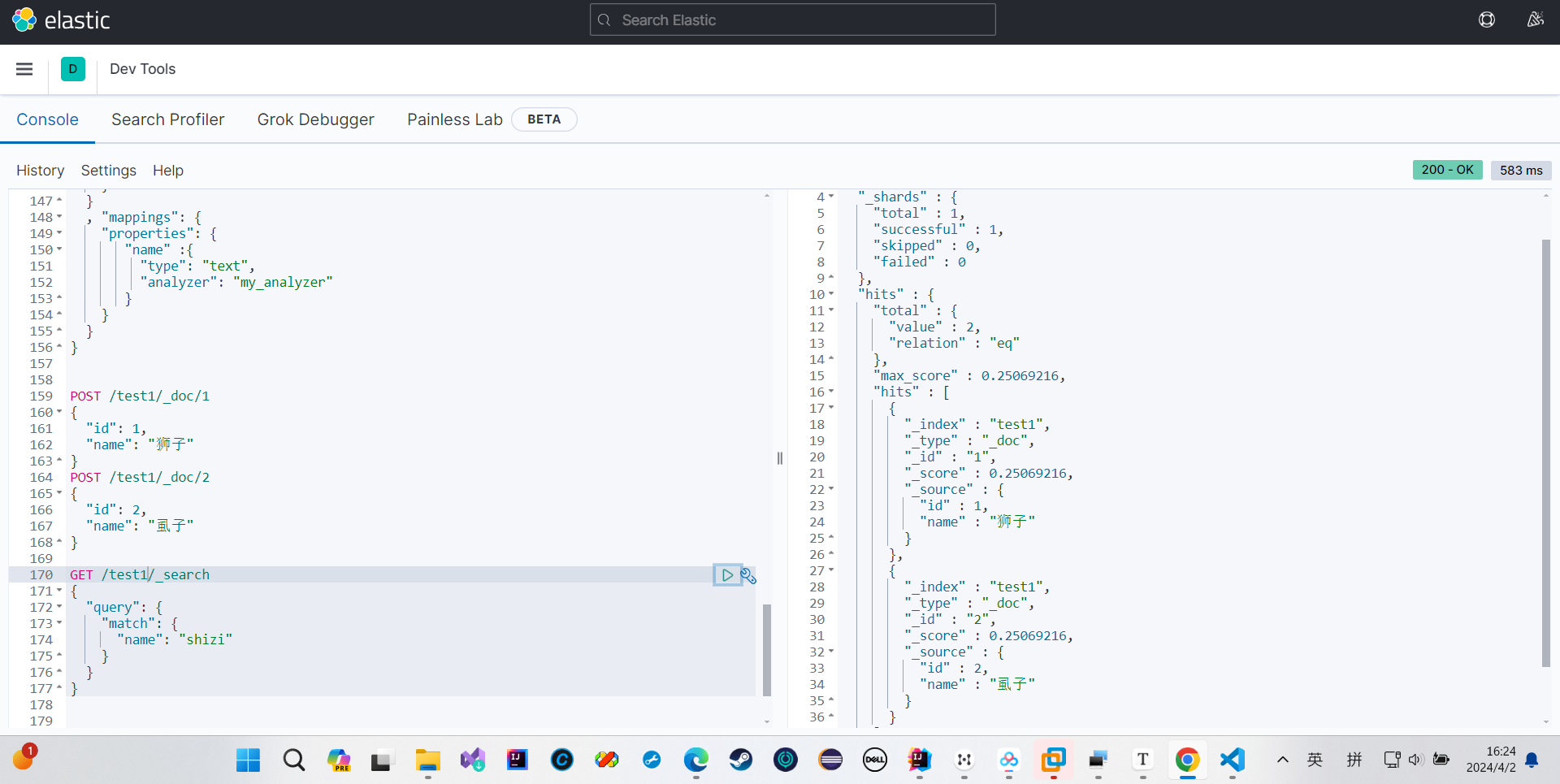
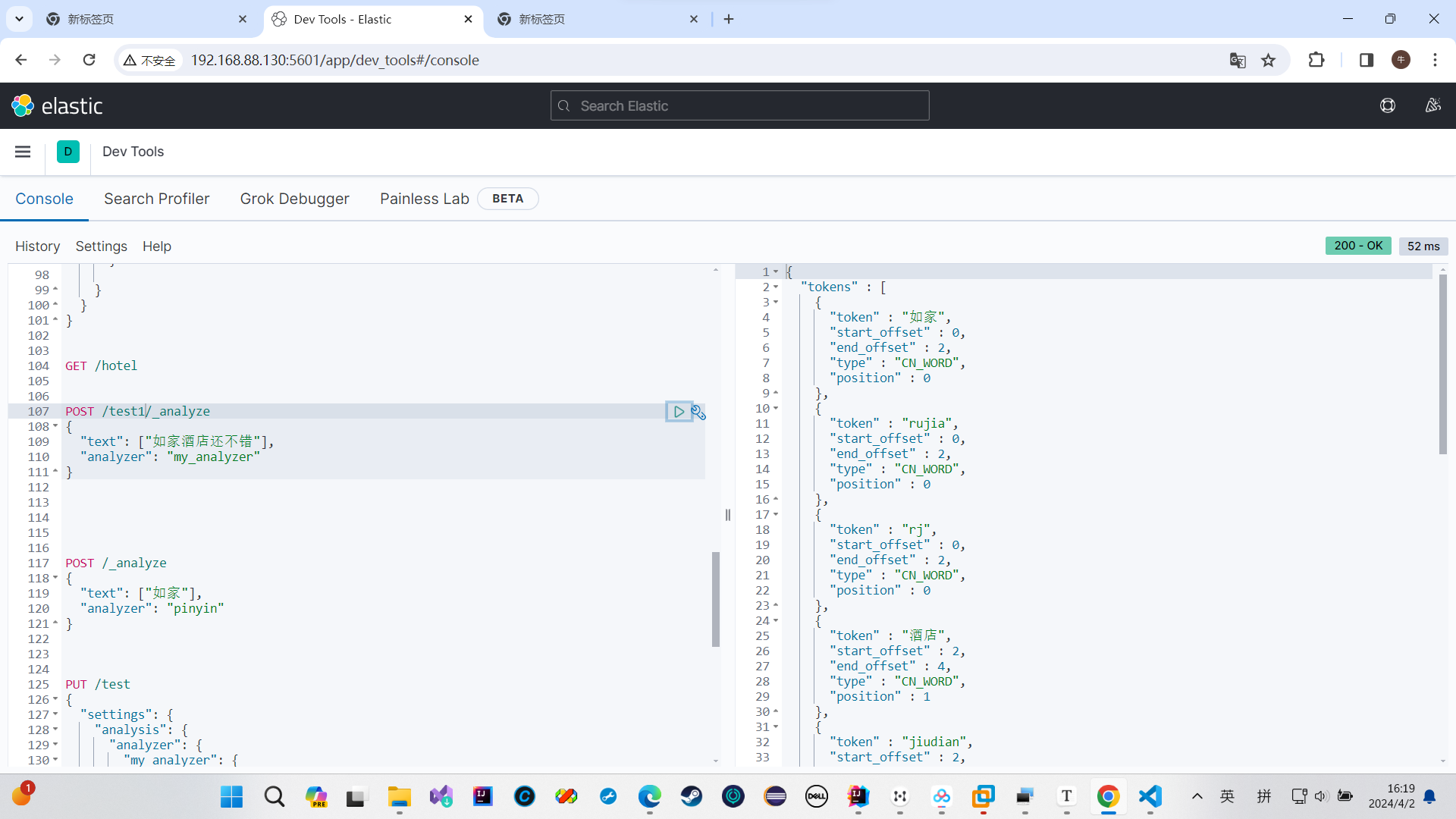
我们这样子搜索也搜到了,说明有问题
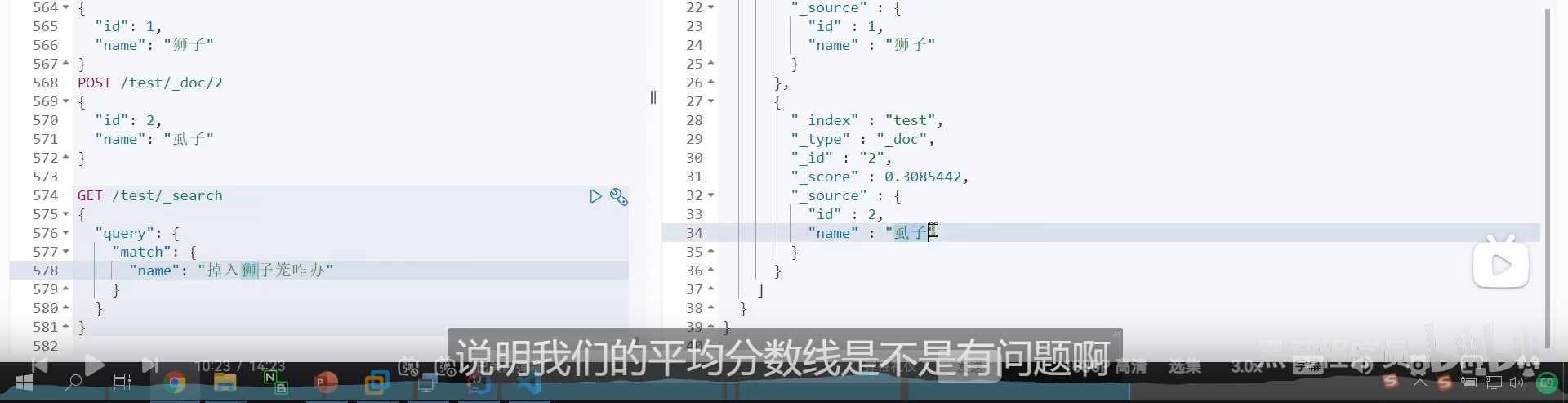
创建索引时应该用拼音分词器,但是我们搜索的时候不应该用
拼音分词器适合在创建索引的时候使用,但不适合在搜索的时候使用
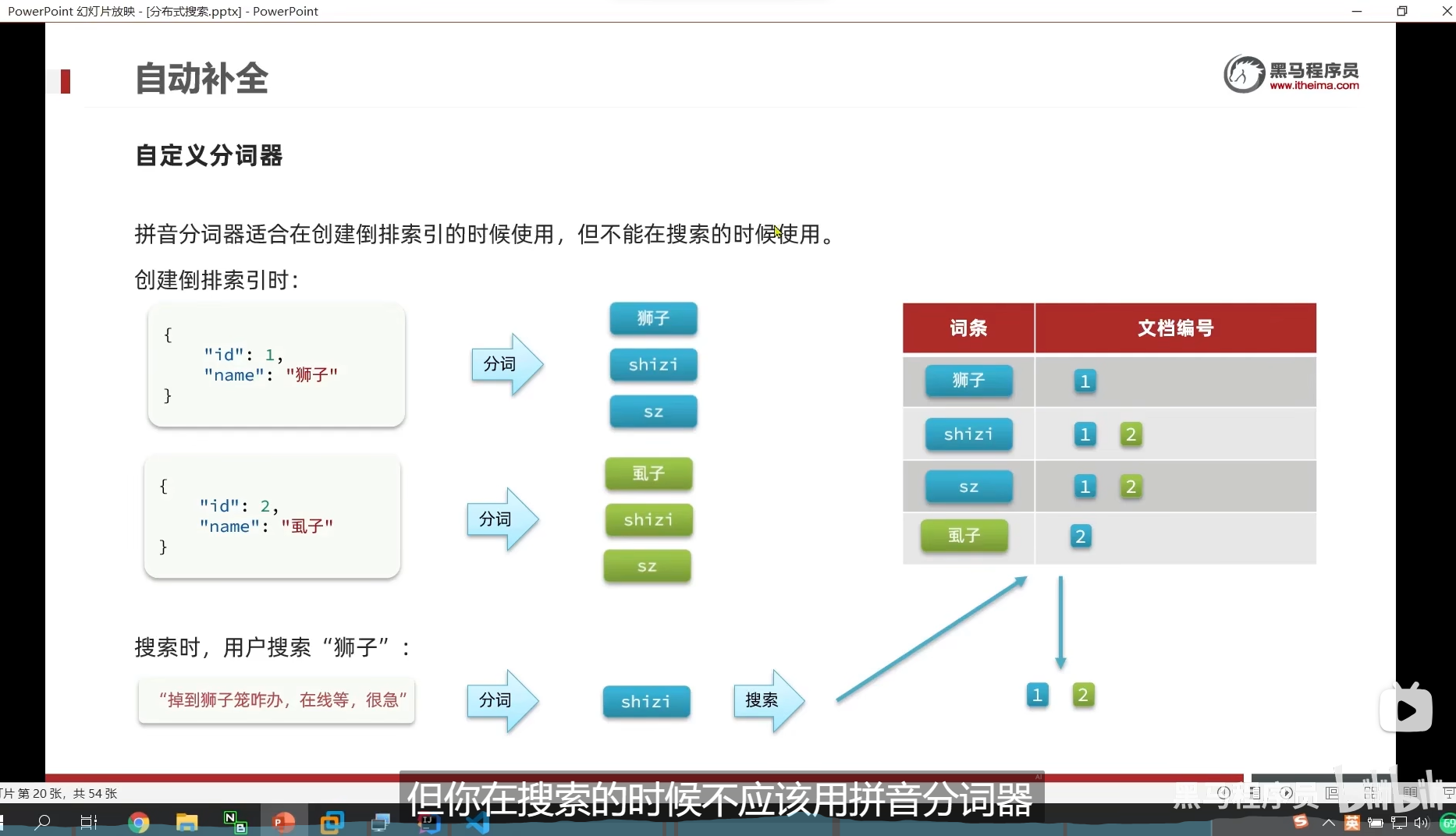
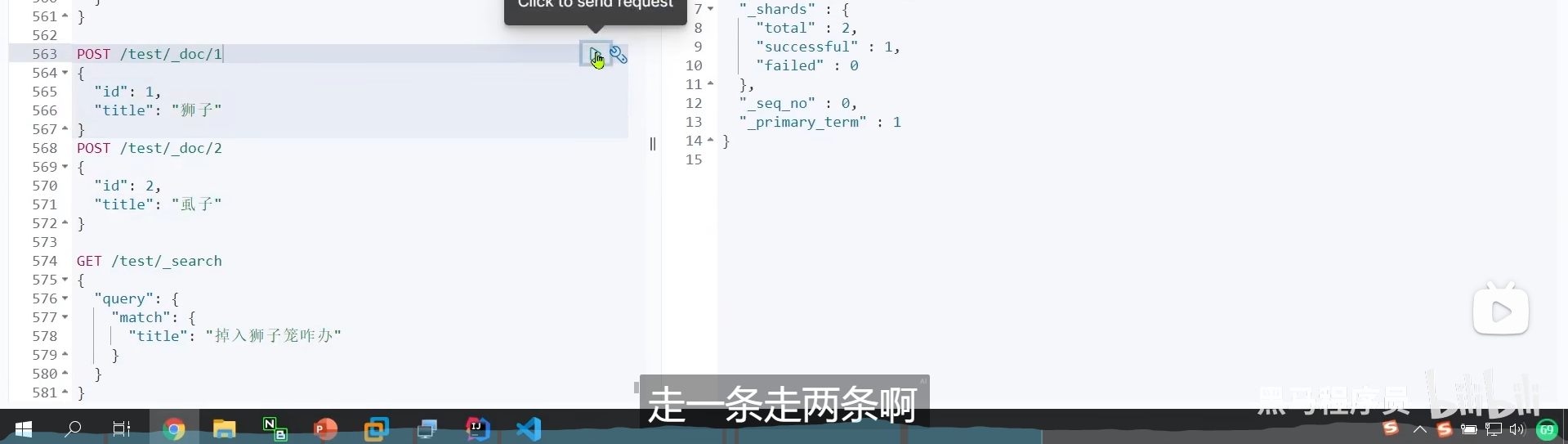
例如我们的狮子和虱子 拼音是一样的
如果我们用拼音分词器搜索 狮子 shizi
那么我们连虱子也会搜索出来,这样子是不对的
我们想要让拼音搜索时,,两个都搜索到
但是中文搜索时,只能搜索到对应的
用户输入中文我们拿中文搜索,拼音我们就拿拼音搜索
创建的时候,和搜索的时候,我们应该用的是不同的分词器
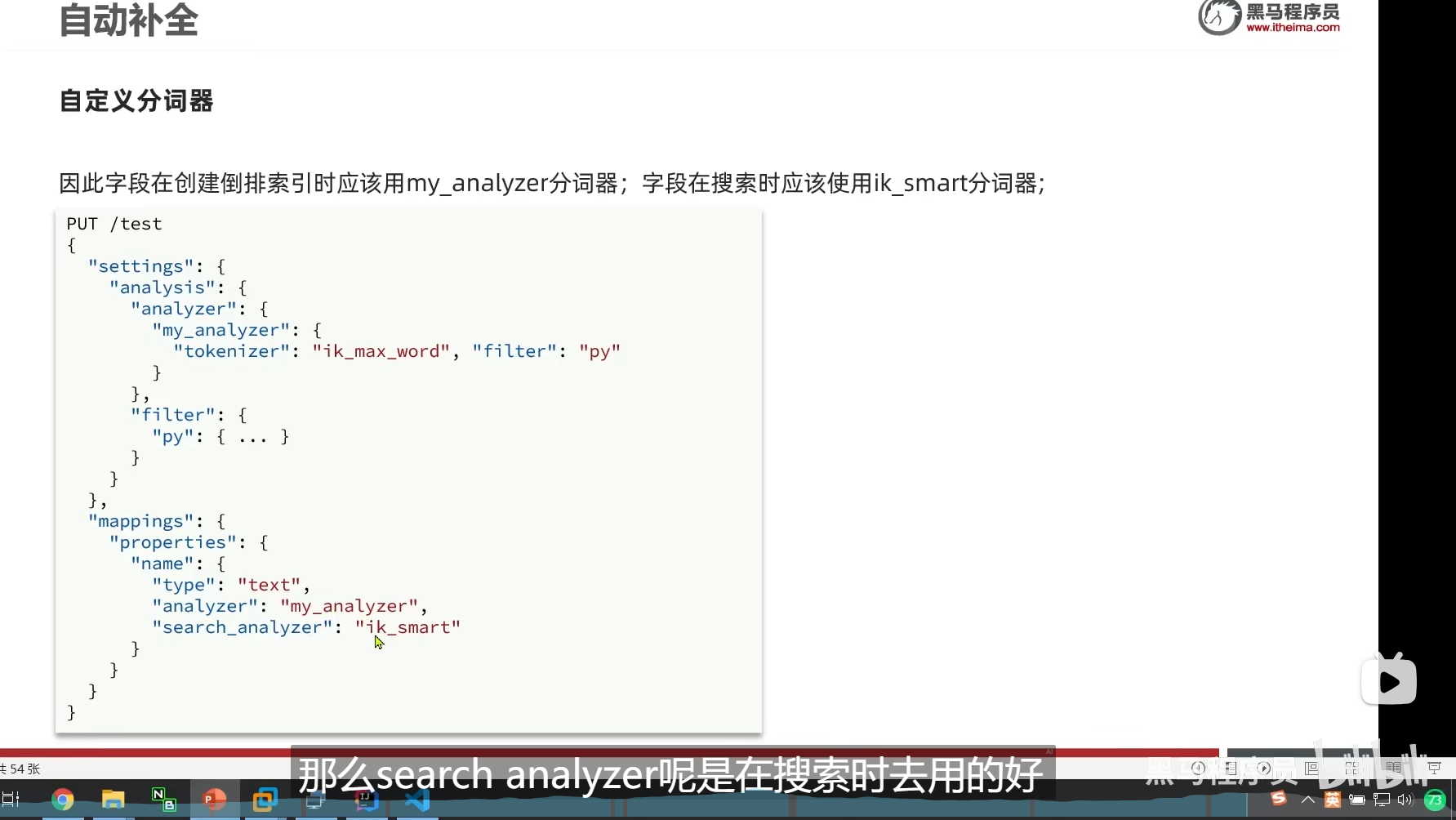
analyzer是创建索引的时候用的
我们在mapping隐射的时候指定两个,一个是analyzer创建索引的时候用的分词器
一个是search_analyzer 也就是我们搜索的时候用的分词器

search_analyzer是我们搜索的时候用的
我们把test库删掉,然后重新弄一个test库

ok,我们搜索没问题了
DSL实现自动补全查询
我们尽量分成一个一个词条反到我们的数组中
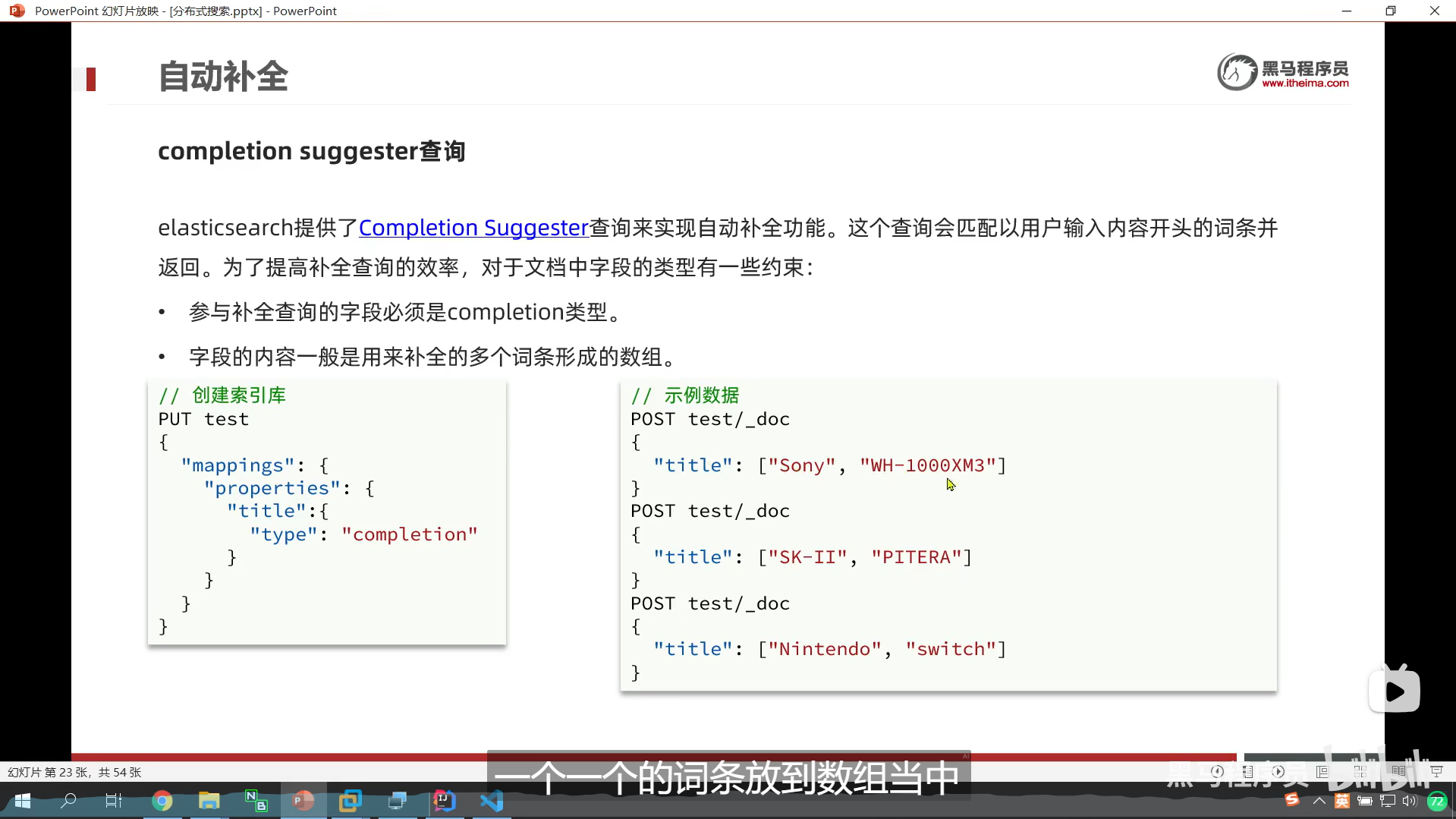
suggest
自动补全
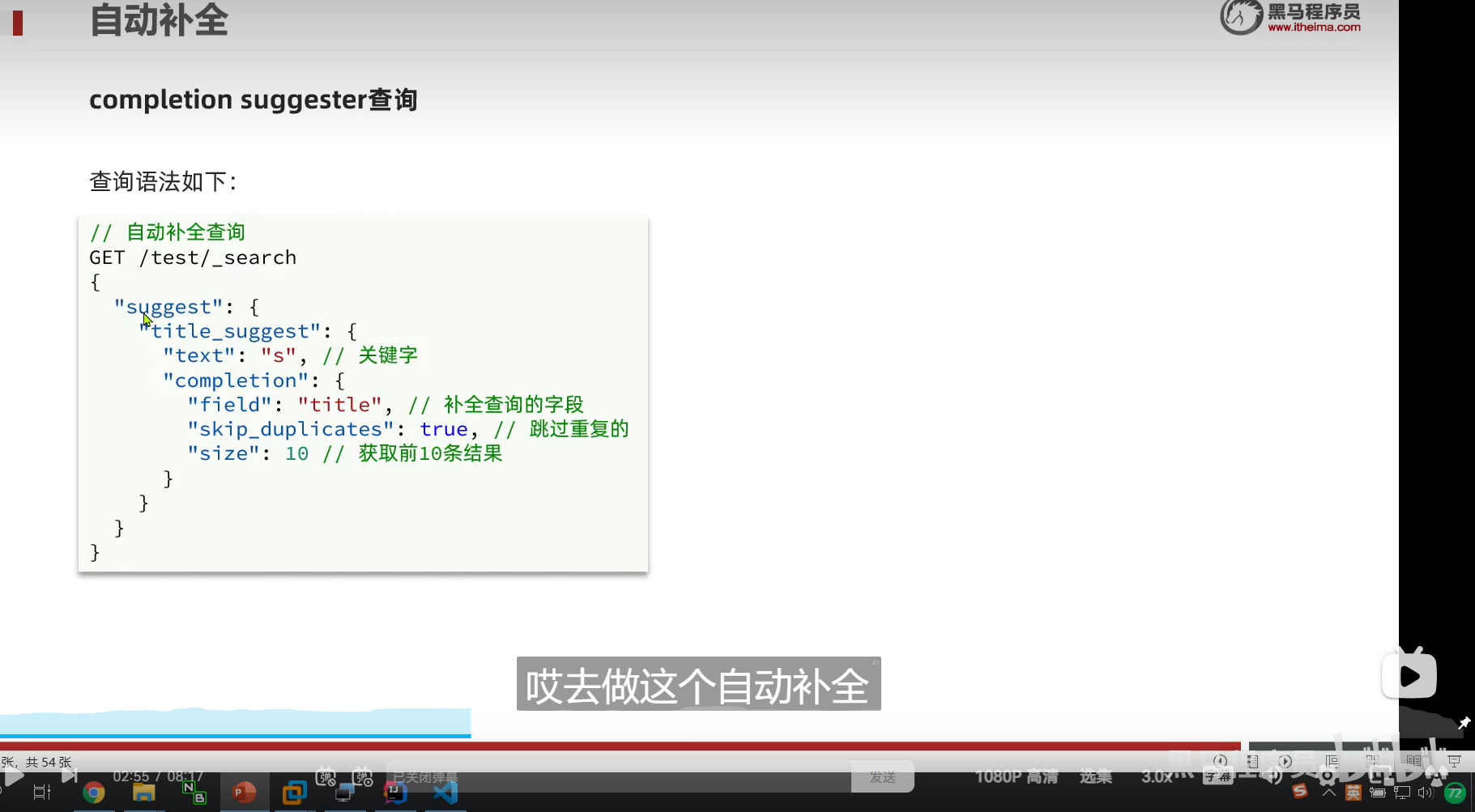
这个是我们的查询的名称
![]()
- completion,代表我们的自动补全的类型

我们这个分词器是 不分词,直接转拼音

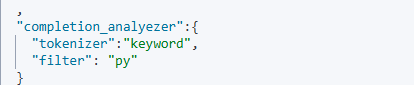
我们对title这个字段,的s做自动补全
这个option,就是我们的自动补全的结果
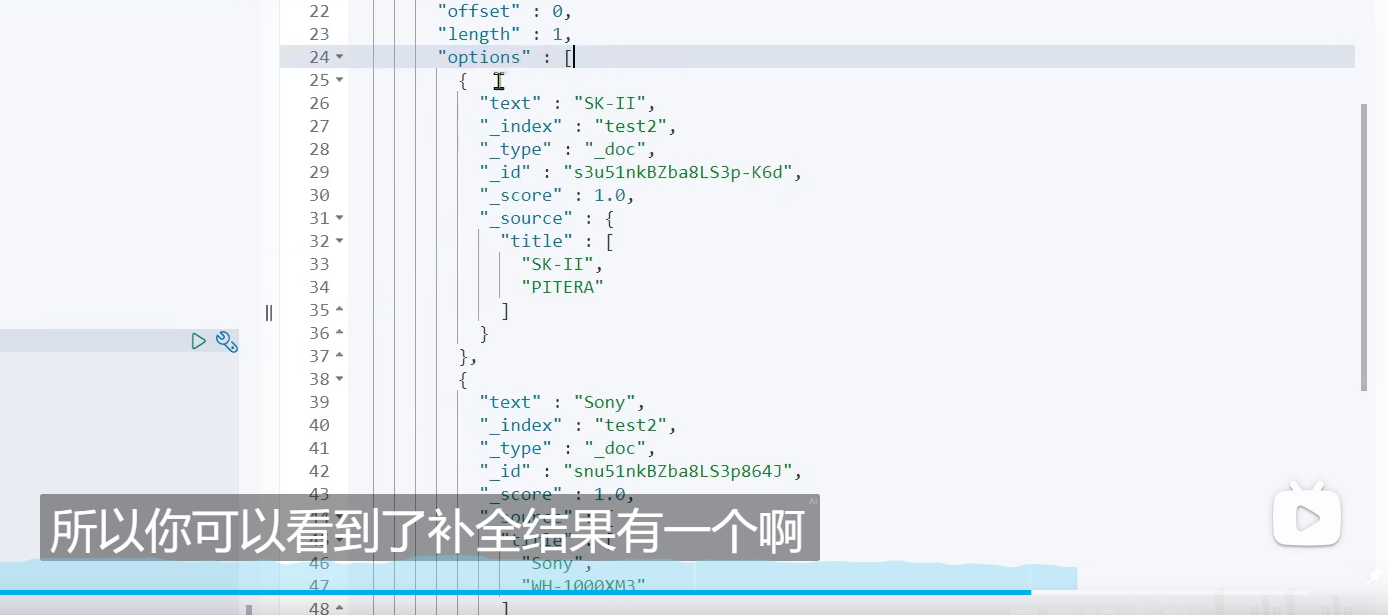
自动补全对字段的要求

修改酒店索引库数据结构
我们首先要给我们的索引库添加多一个commpletion类型的suggestion字段


为实体类添加多一个字段

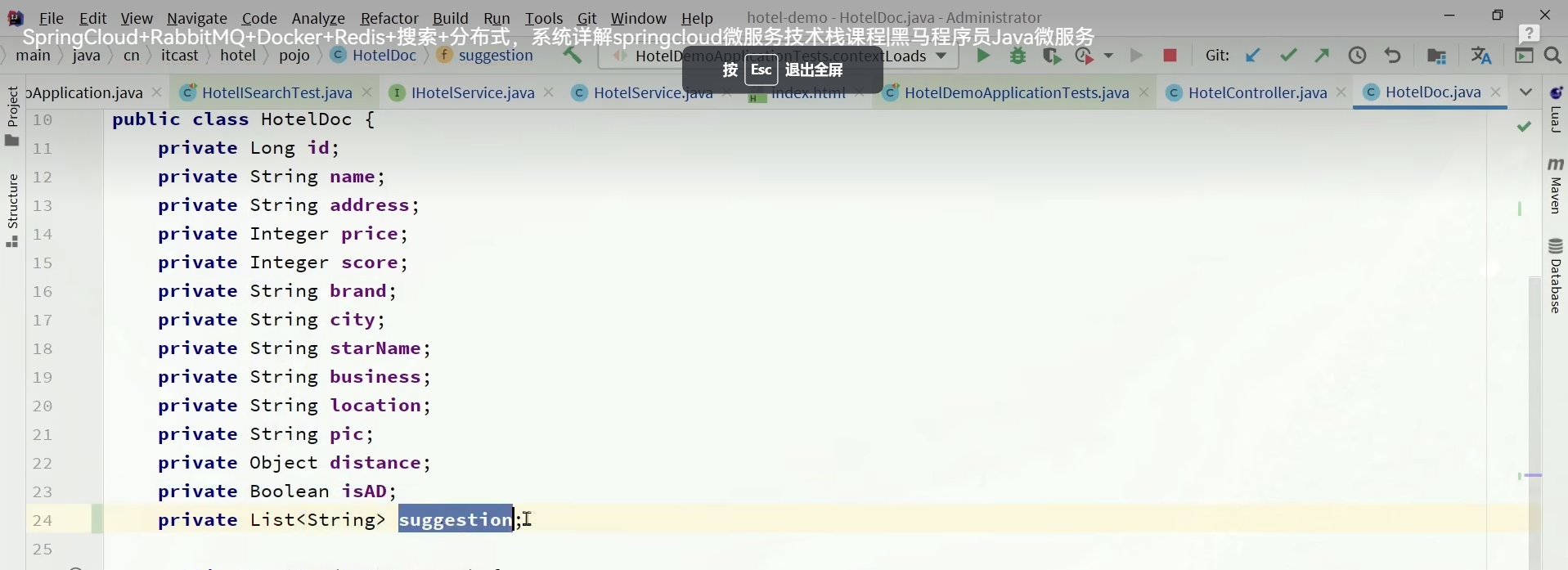
其实suggestion这个字段,是要把我们的现有的信息放进去

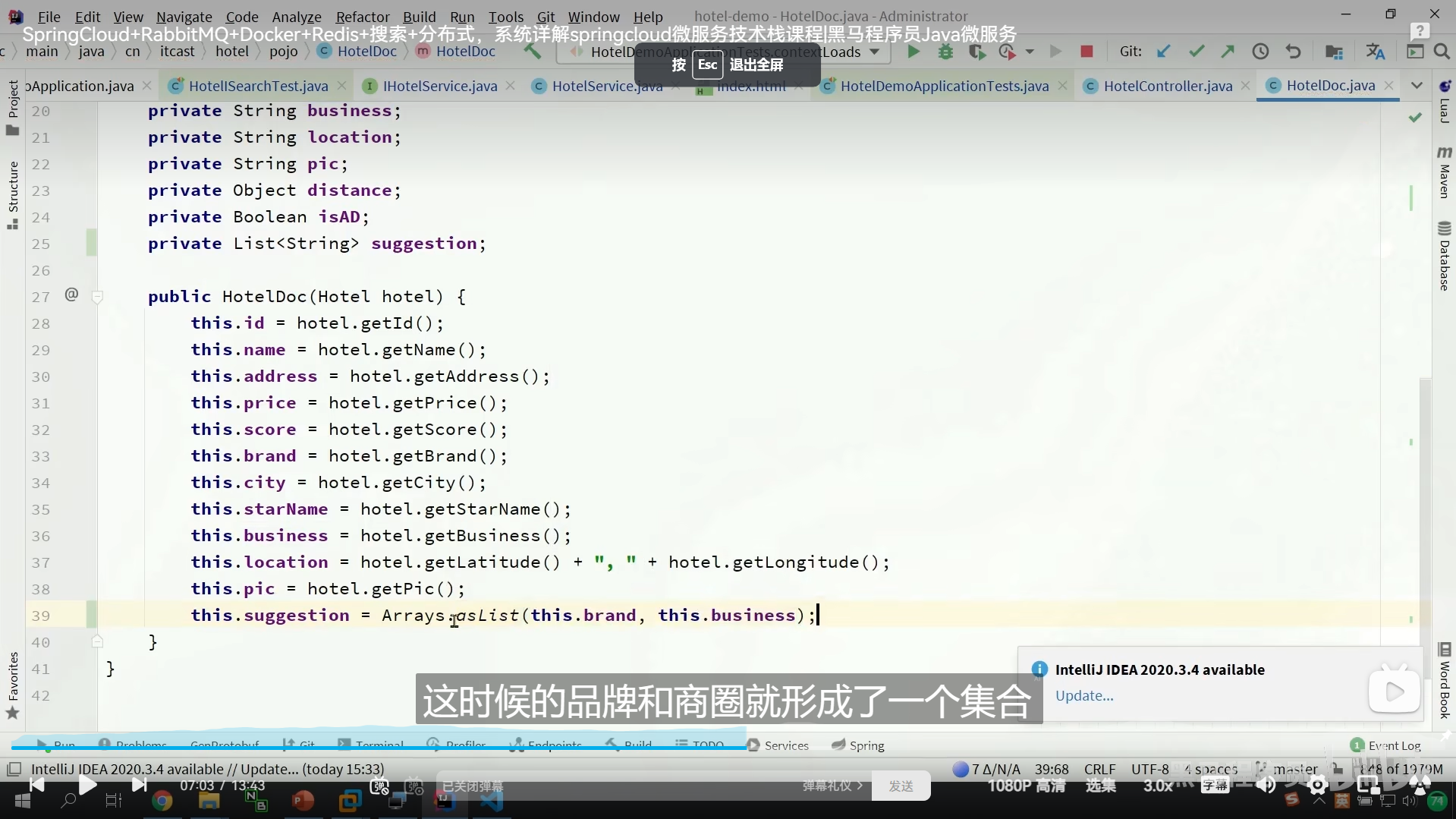
重新导入我们的数据
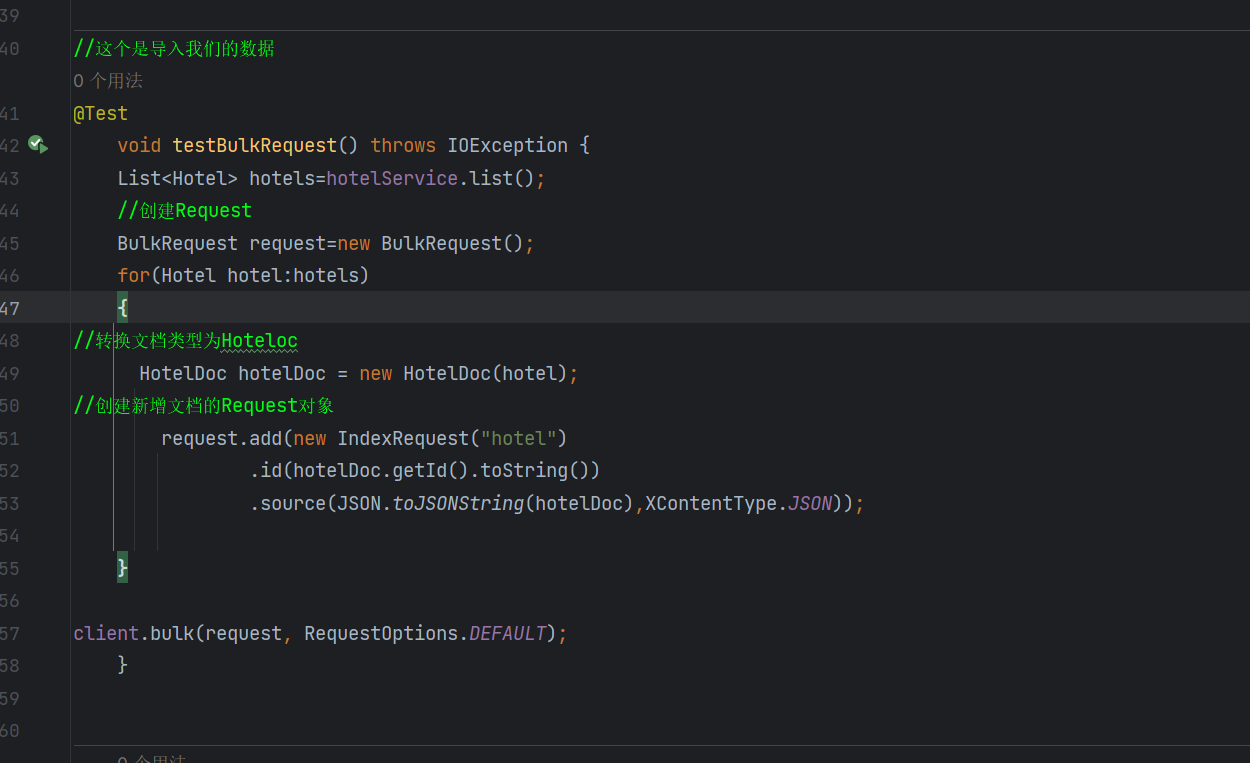
绿了我们的数据导入成功了
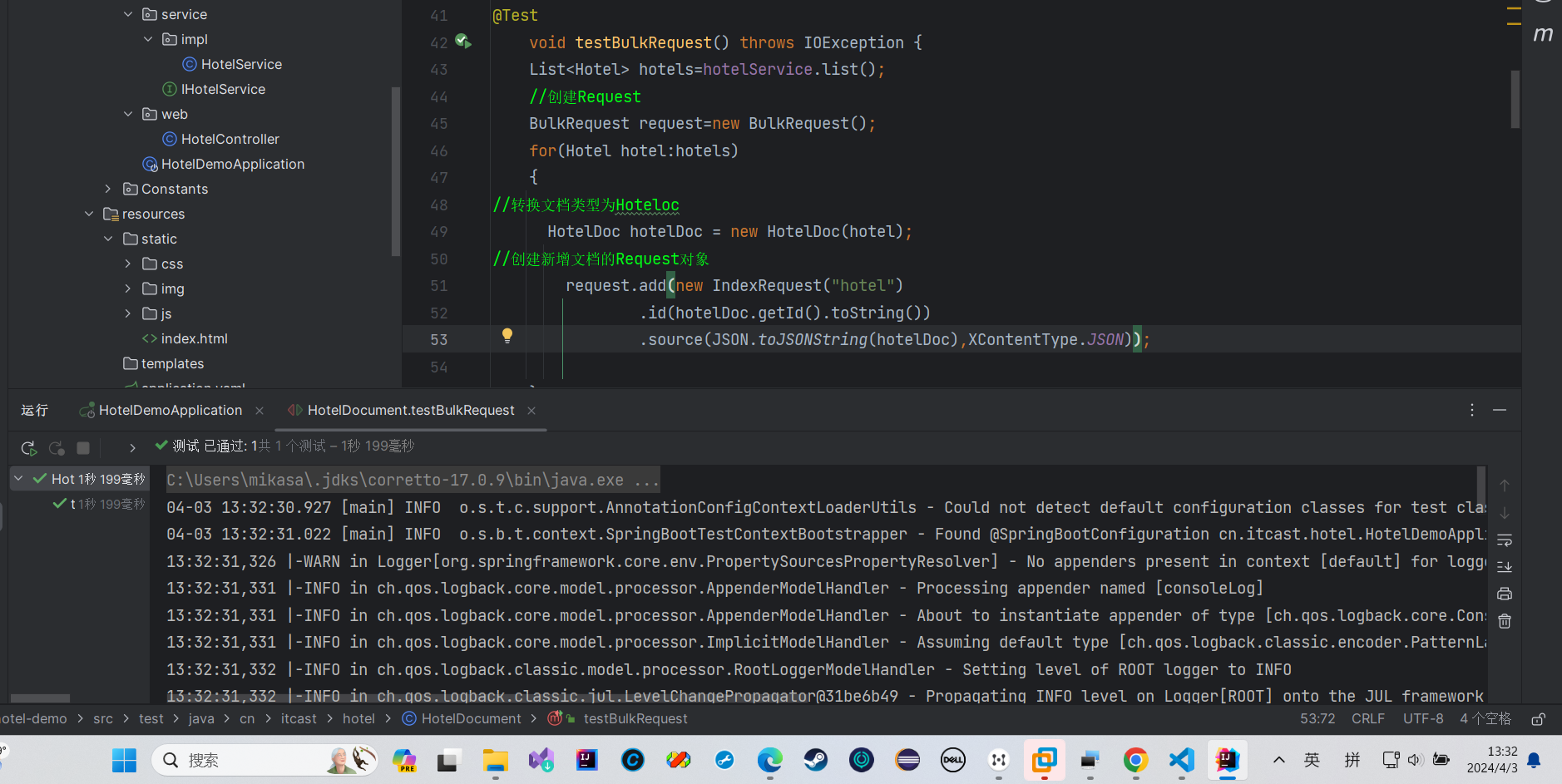
我们来做一个常规的搜索
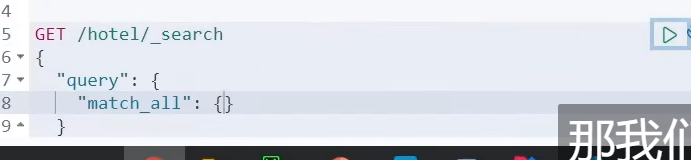
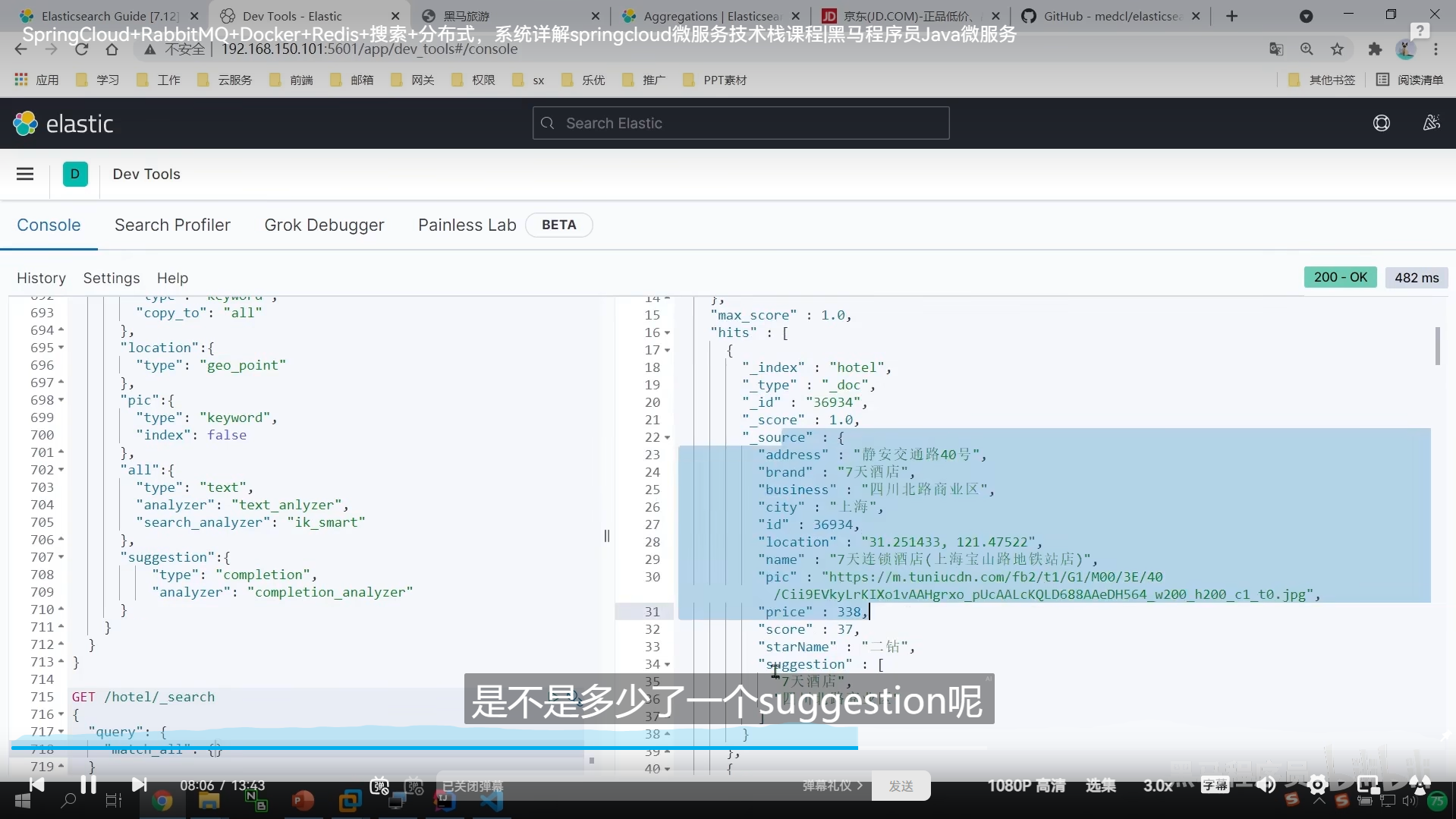
我们要重新弄实体类,弄个List,把我们的tilte,brand放到这个list里面
当作我们的自动补全字段
这个的话,就只能根据 江来提示了,而不能根据 5来提示了
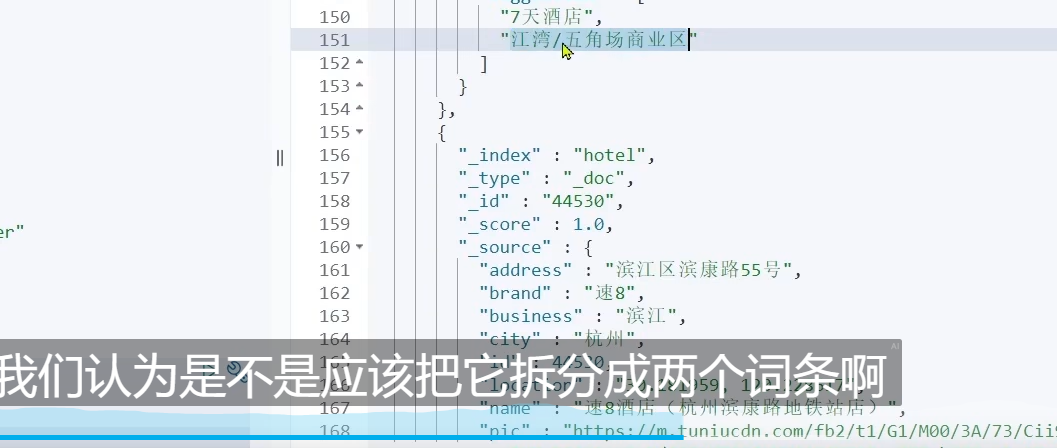
所以我们pojo类的时候,就要把他们切割
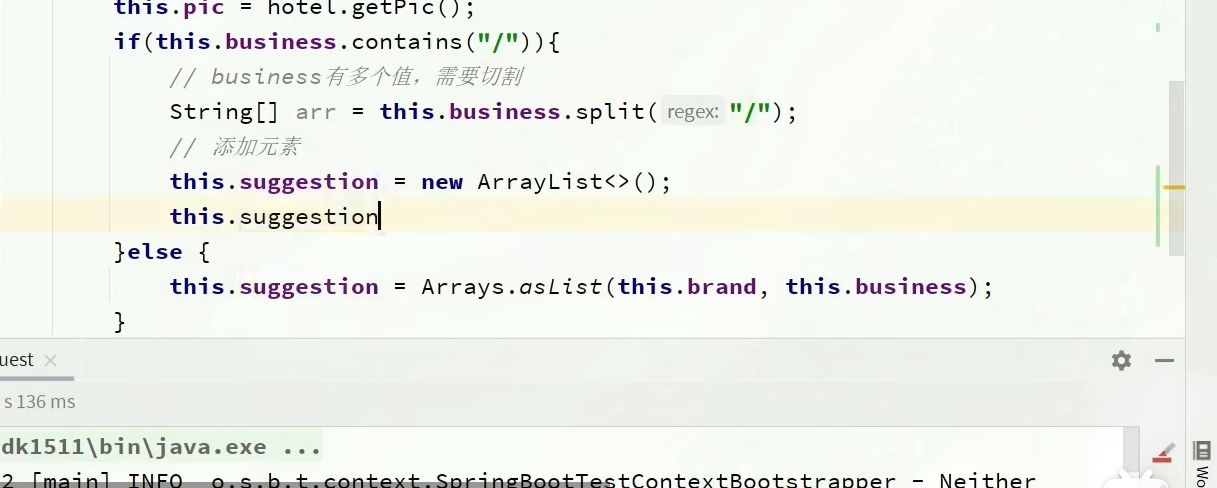
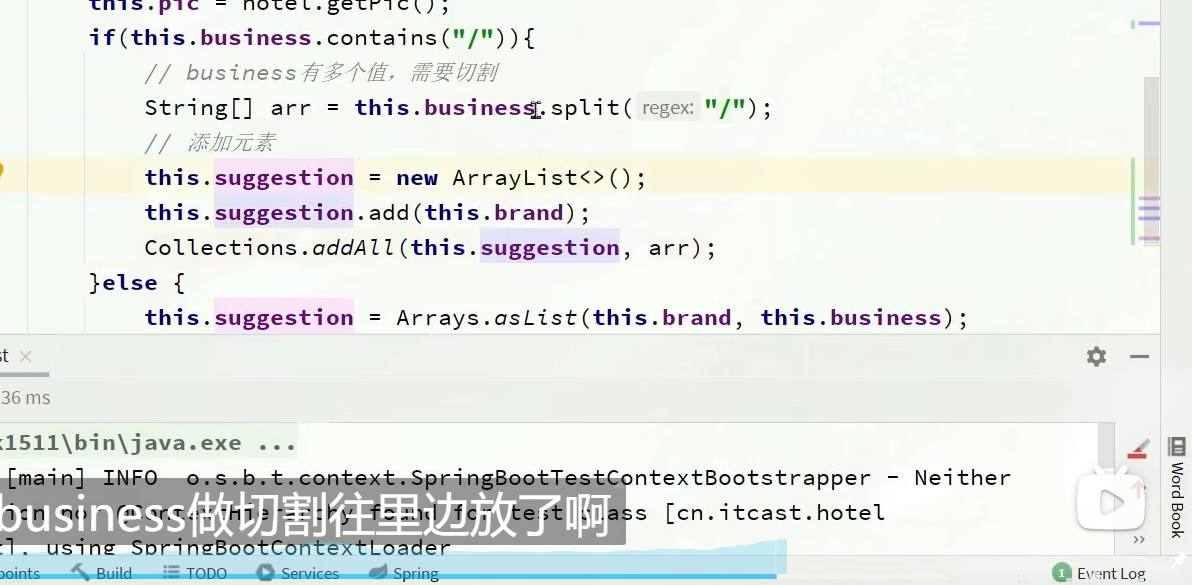
ok,我们重新运行一下,切割成3个了

我们的补全字段是completion类型,并且存在List类型的suggestion字段中
所以我们查询的field字段,是suggestion字段

匹配我们的字段
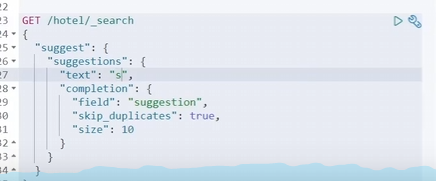
匹配到的字段
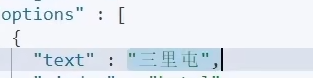
我们搜索时,用s匹配
然后匹配到的文本内容里面,有我们的suggestion【】这个我们的补全List类
我们补全的时候是从这个List类的suggestion里面查找
所以我们的补全内容是针对我们的List类的suggestion字段的
并且是基于我们 搜索栏匹配的前提下补全的
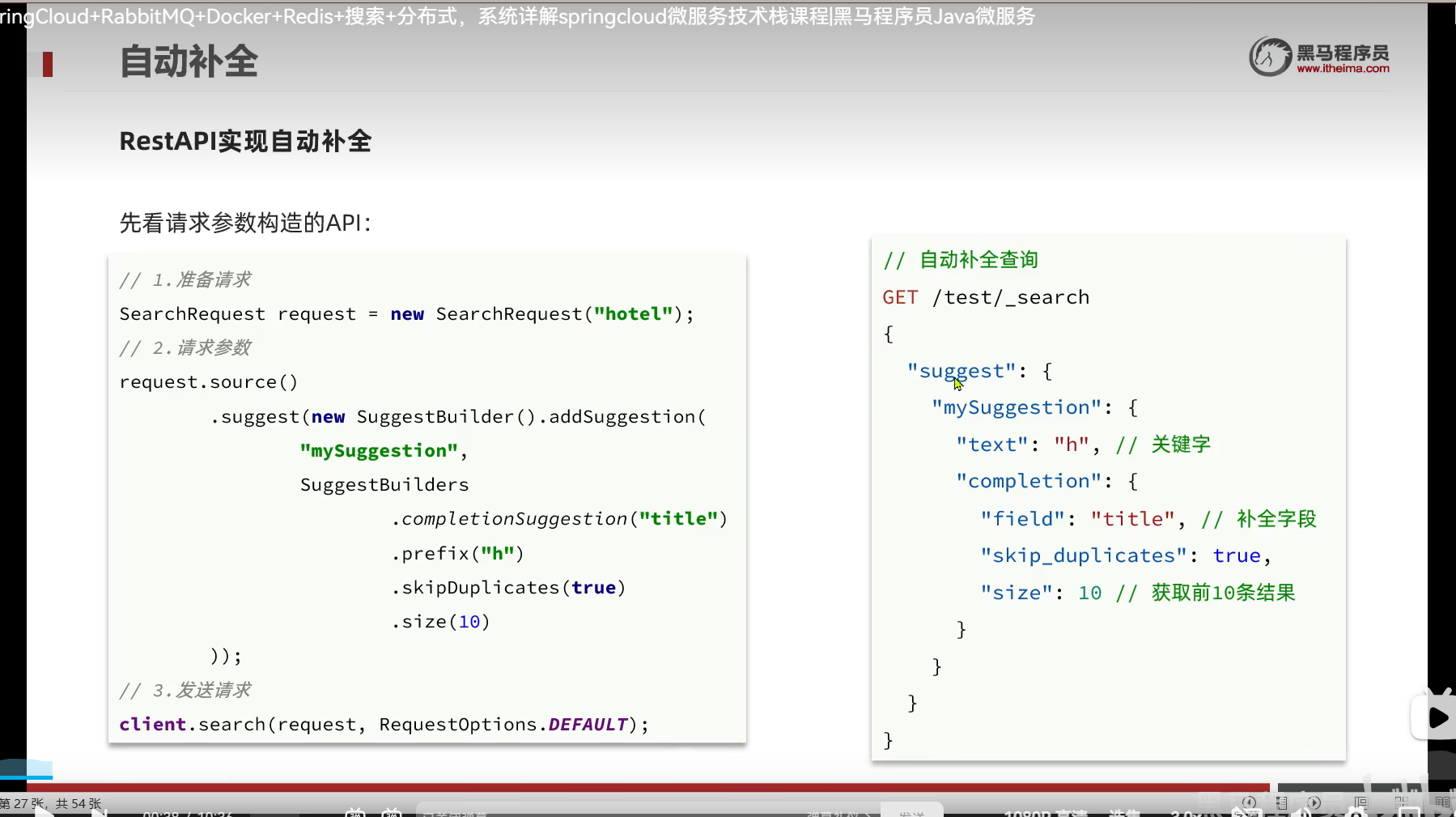
RestAPI实现自动补全查询
为啥gz能匹配到Suggestion里面的广州呢?还记得我们的分词吗?我们最后是弄成拼音存储了
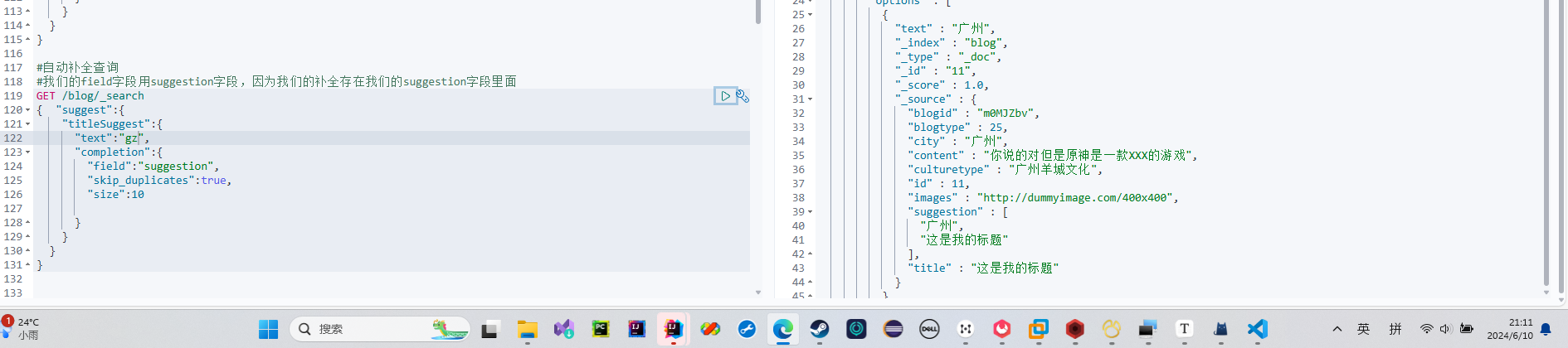
其实我这个没问题 我一开始在想我有那么多个广州怎么查不出来
但我忘记了,我之前设置查询的时候是设置了跳过重复的
所以我们 广州 这个字段只会出现一次
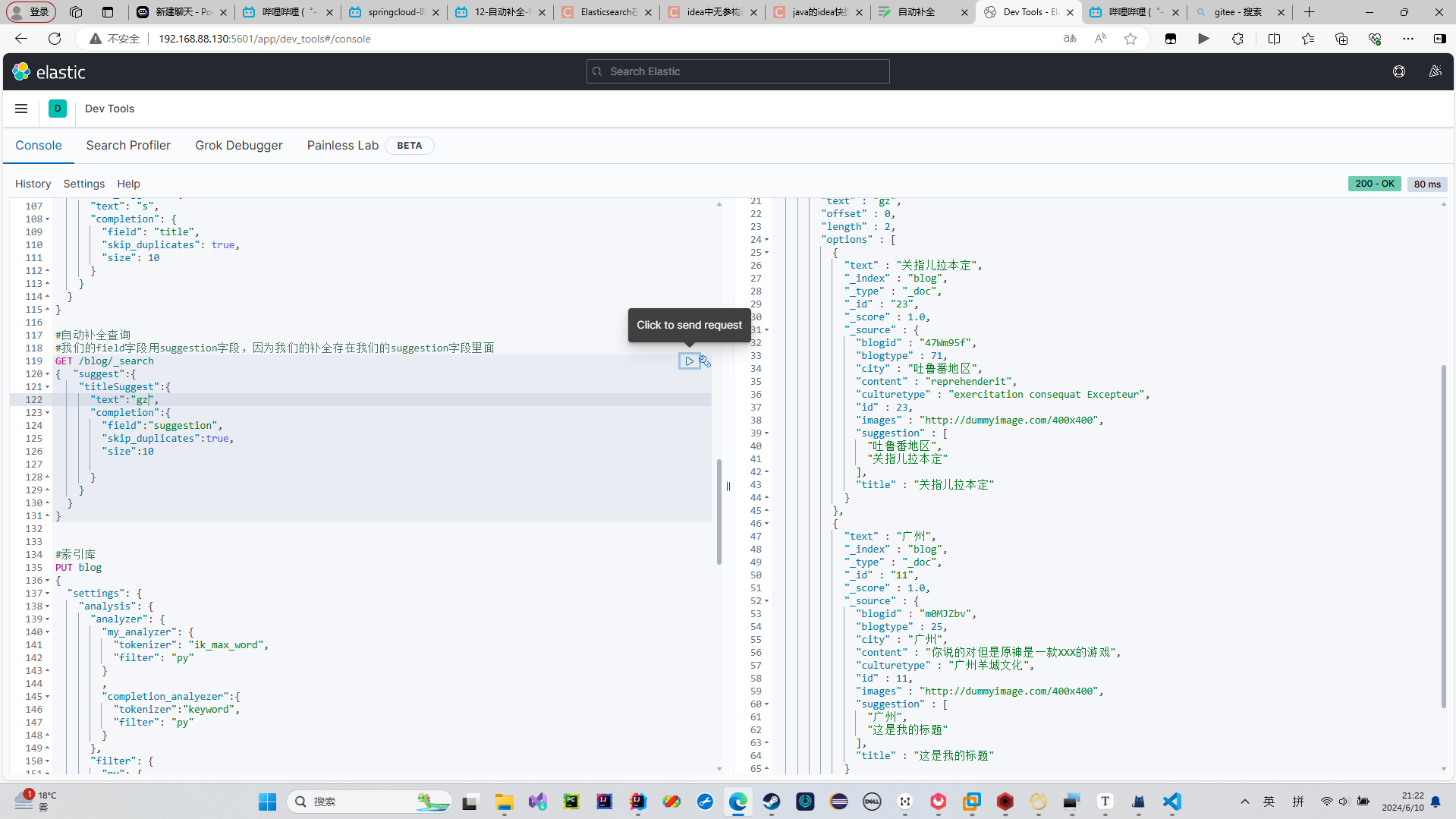
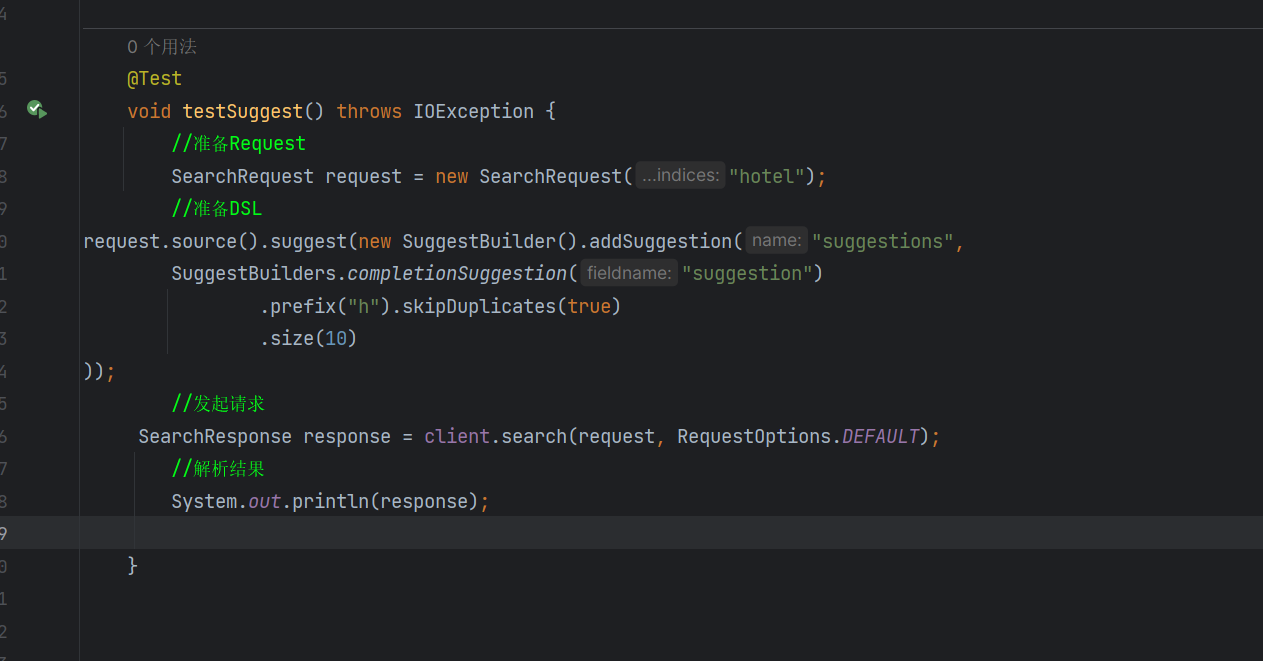
发起请求
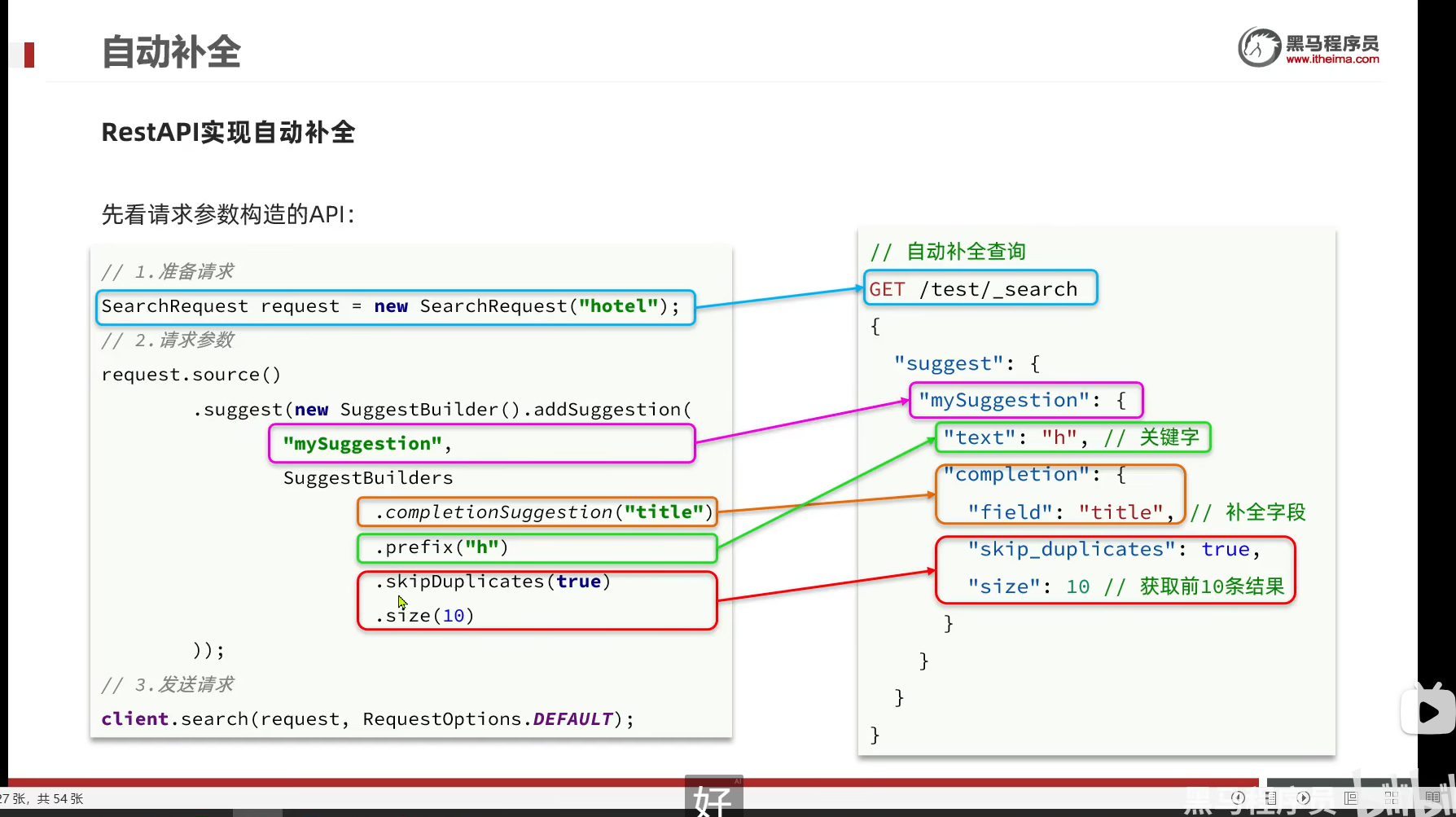
结果解析
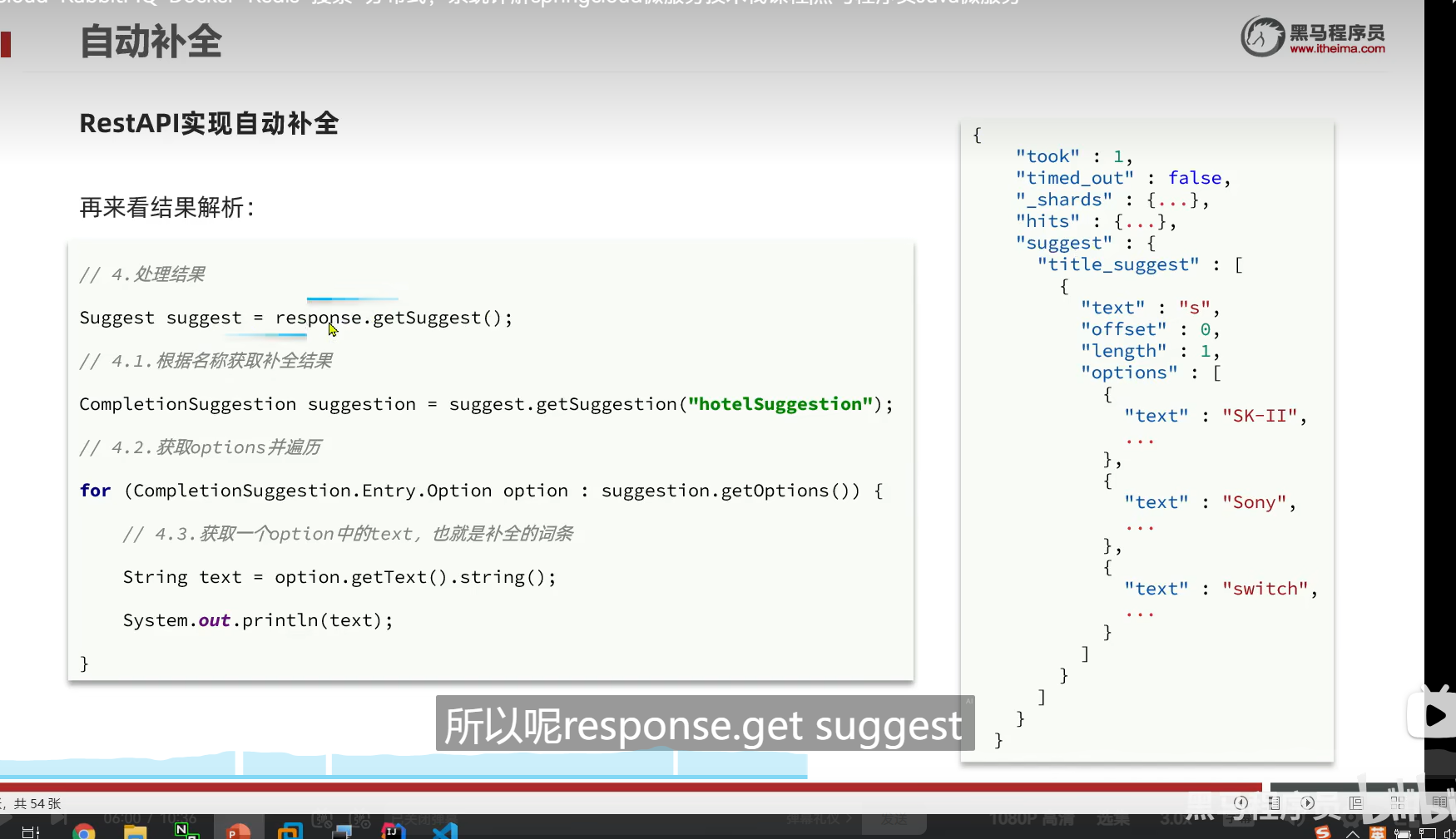
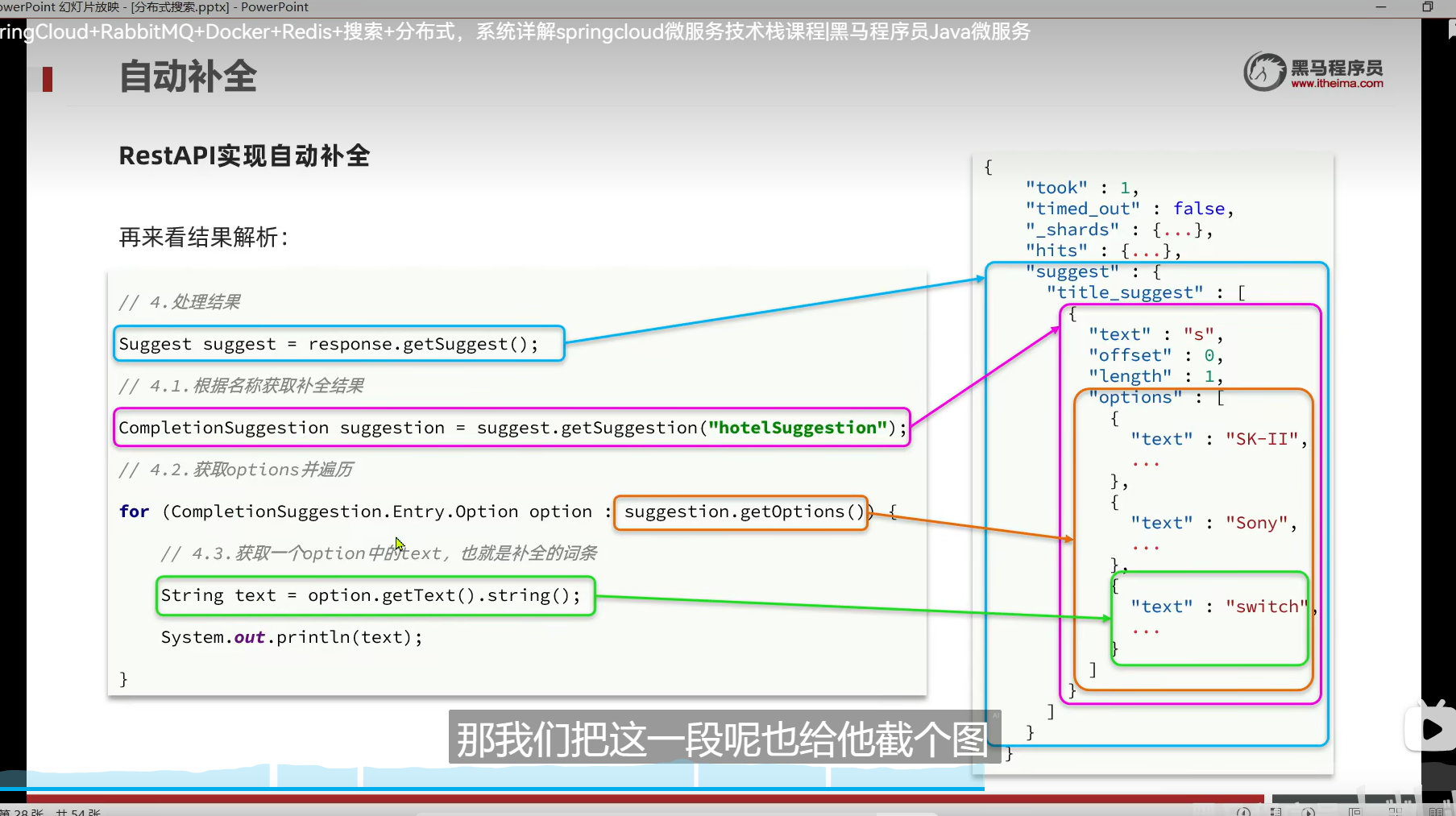
其实这么长的类型,就只是CompletionSuggestion类型
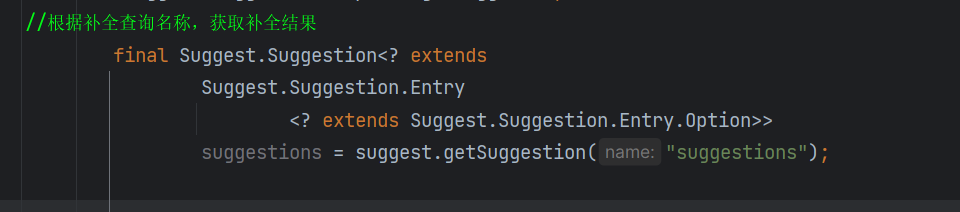

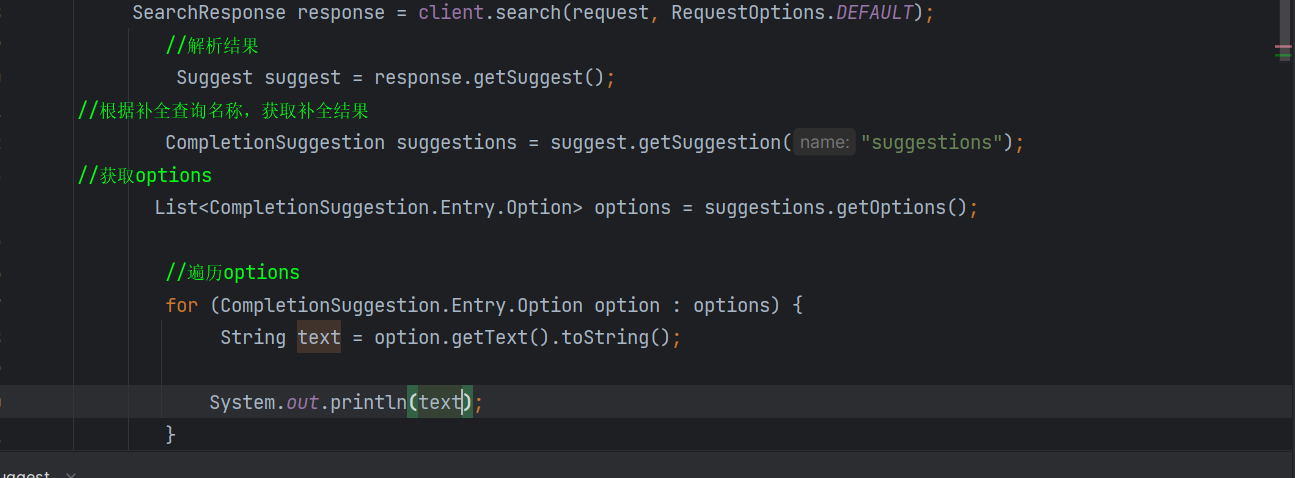
运行一下
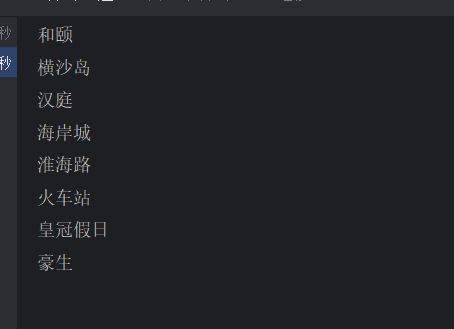
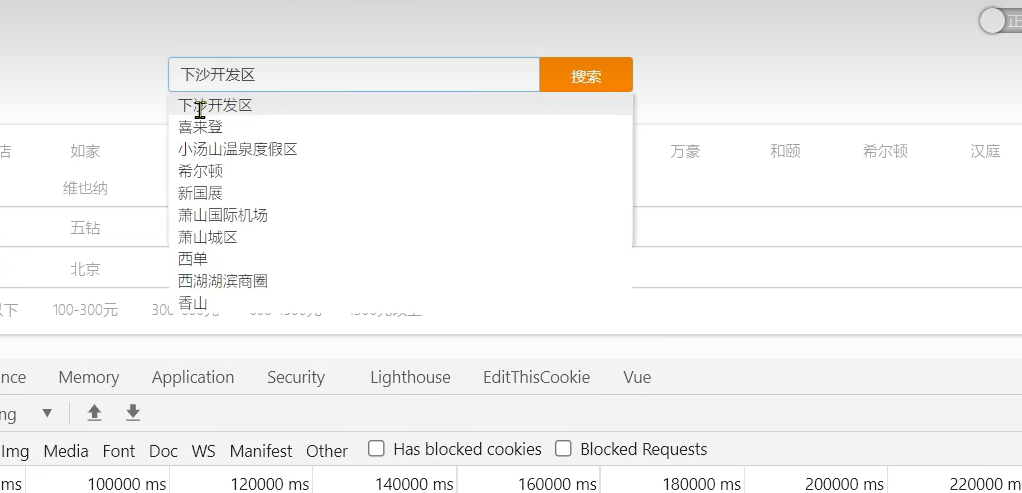
实现搜索框自动补全
然后我们在我们的Controller里面写我们的方法
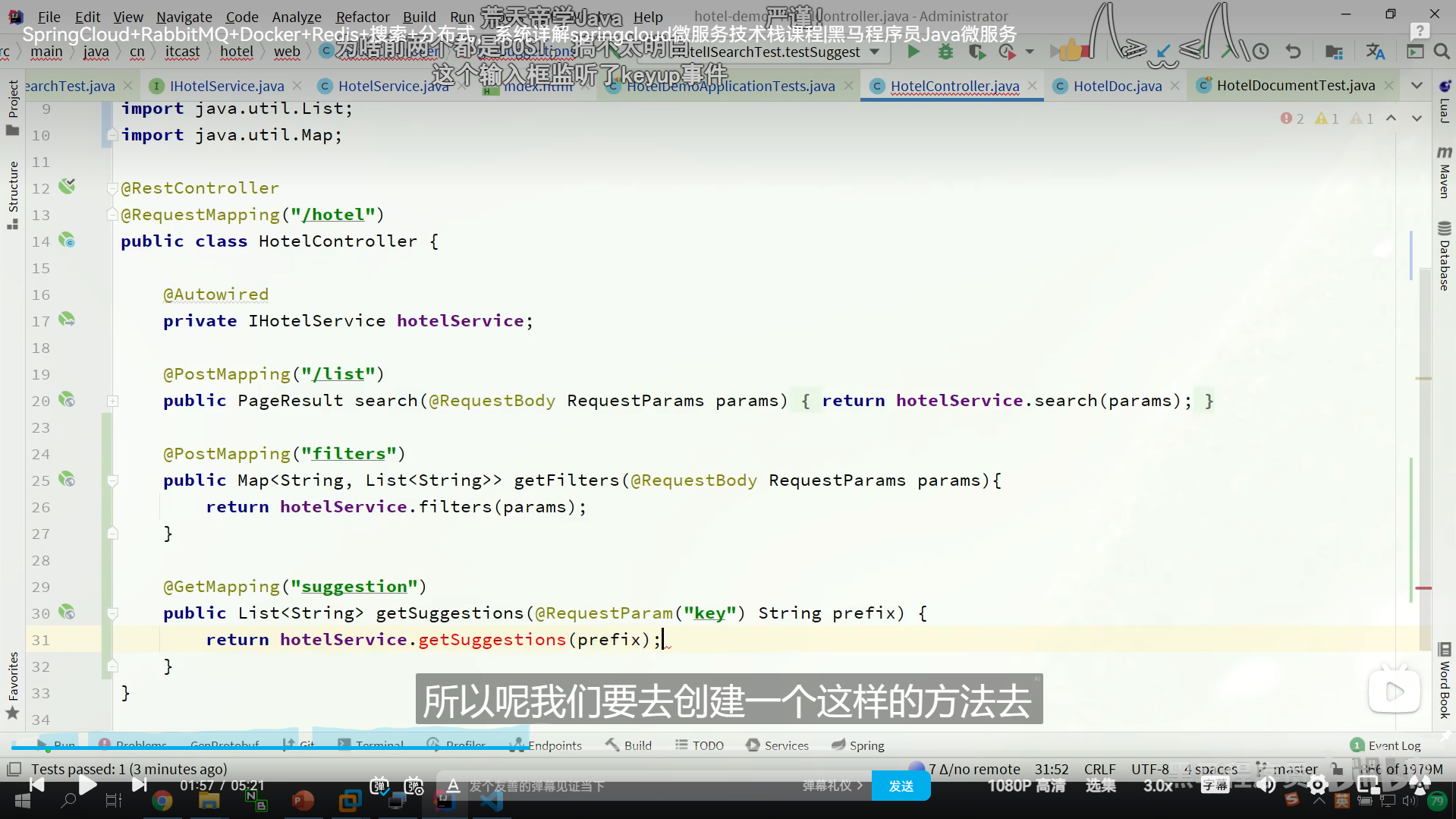
我们把之前测试类的代码放到业务层,修改一下
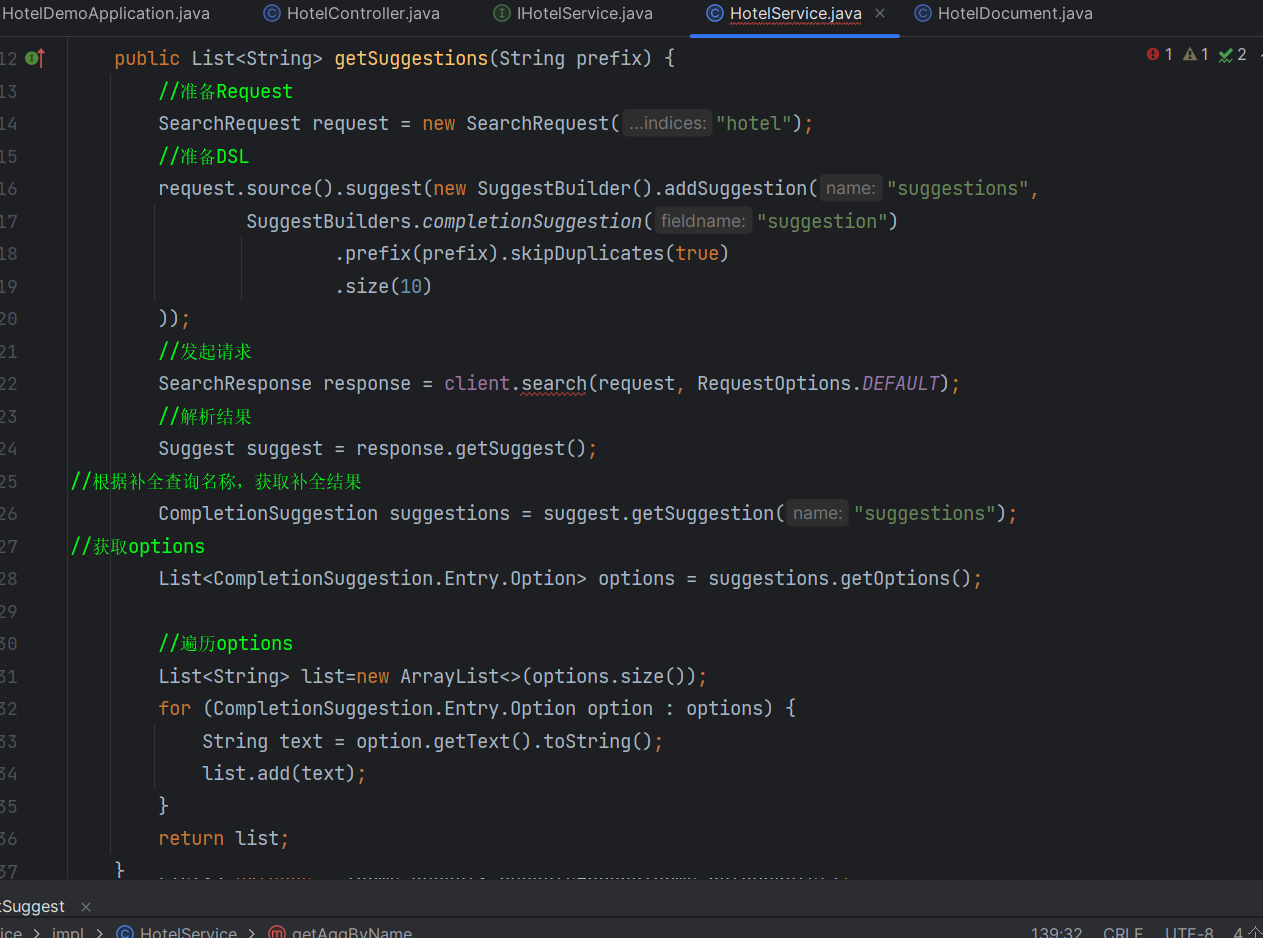
我们弄这种自动补全字段的时候
我们要用SuggestionBuilder
里面来放一些我们的条件
例如 skipDuplicates(true)跳过重复的
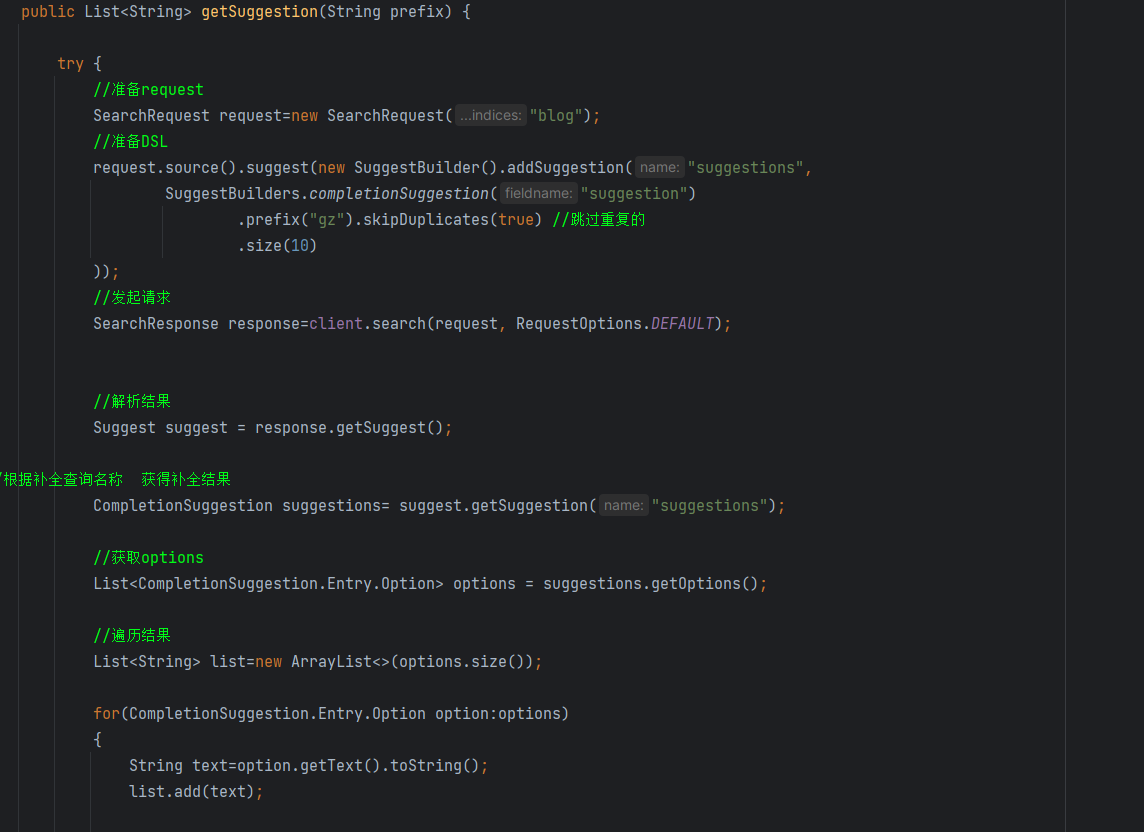
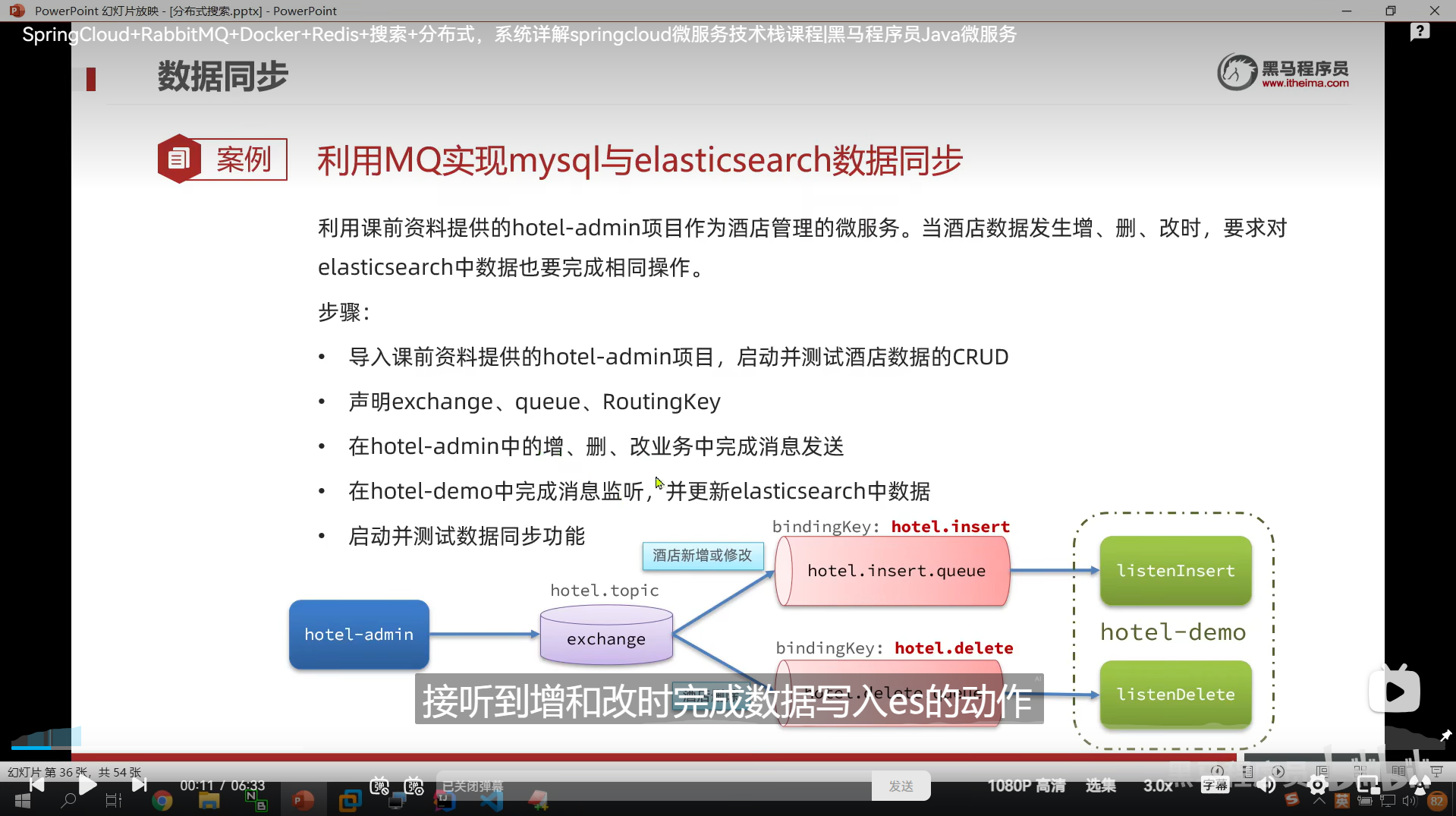
数据同步
同步方案分析
我们要如何保证mysql数据变化的时候,es的数据也变化

但是我们是微服务项目啊
单体服务可以实现同步调用
但是我们这个服务是微服务,所以我们不用同步调用
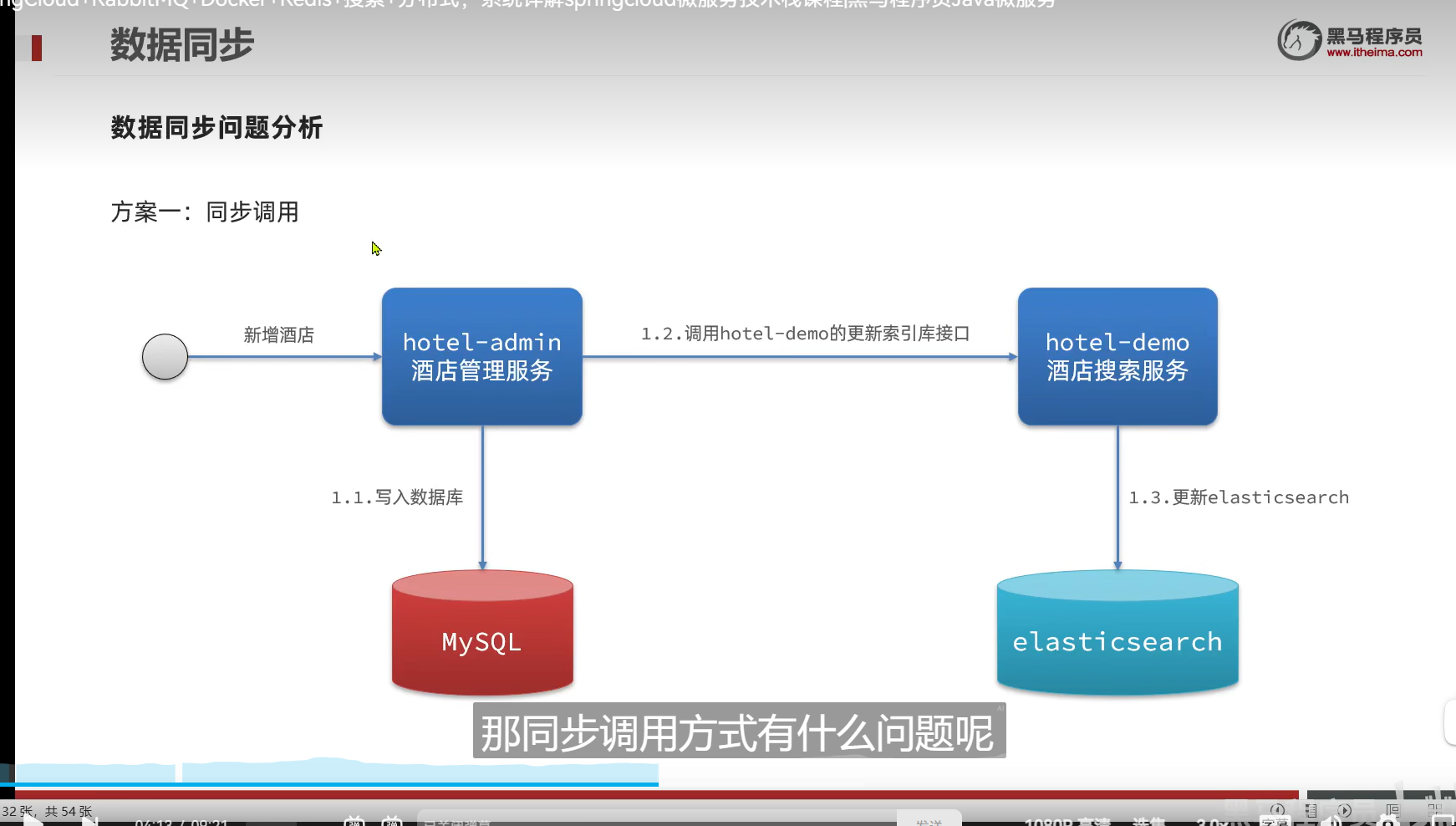
用MQ实现异步通知
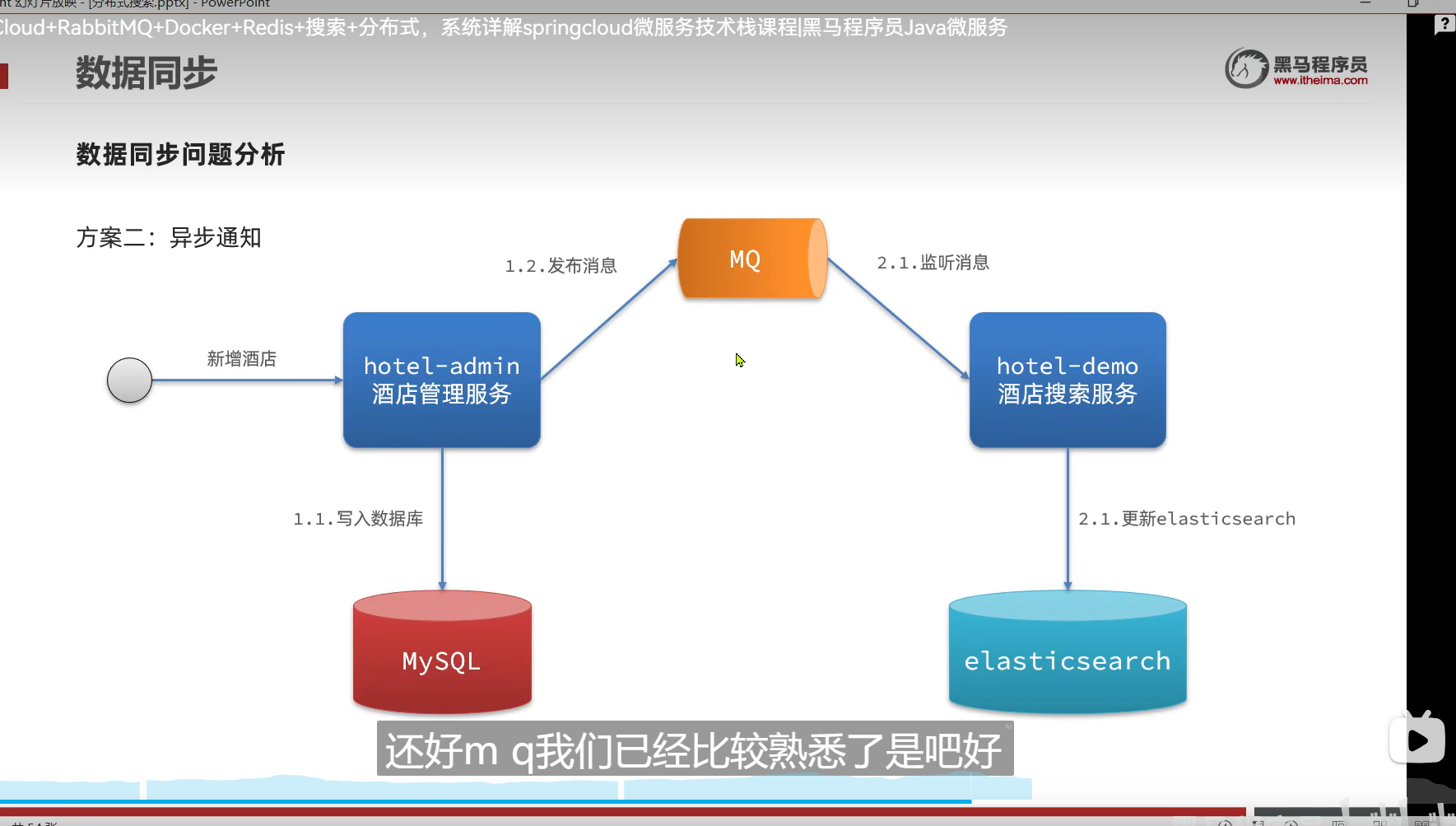
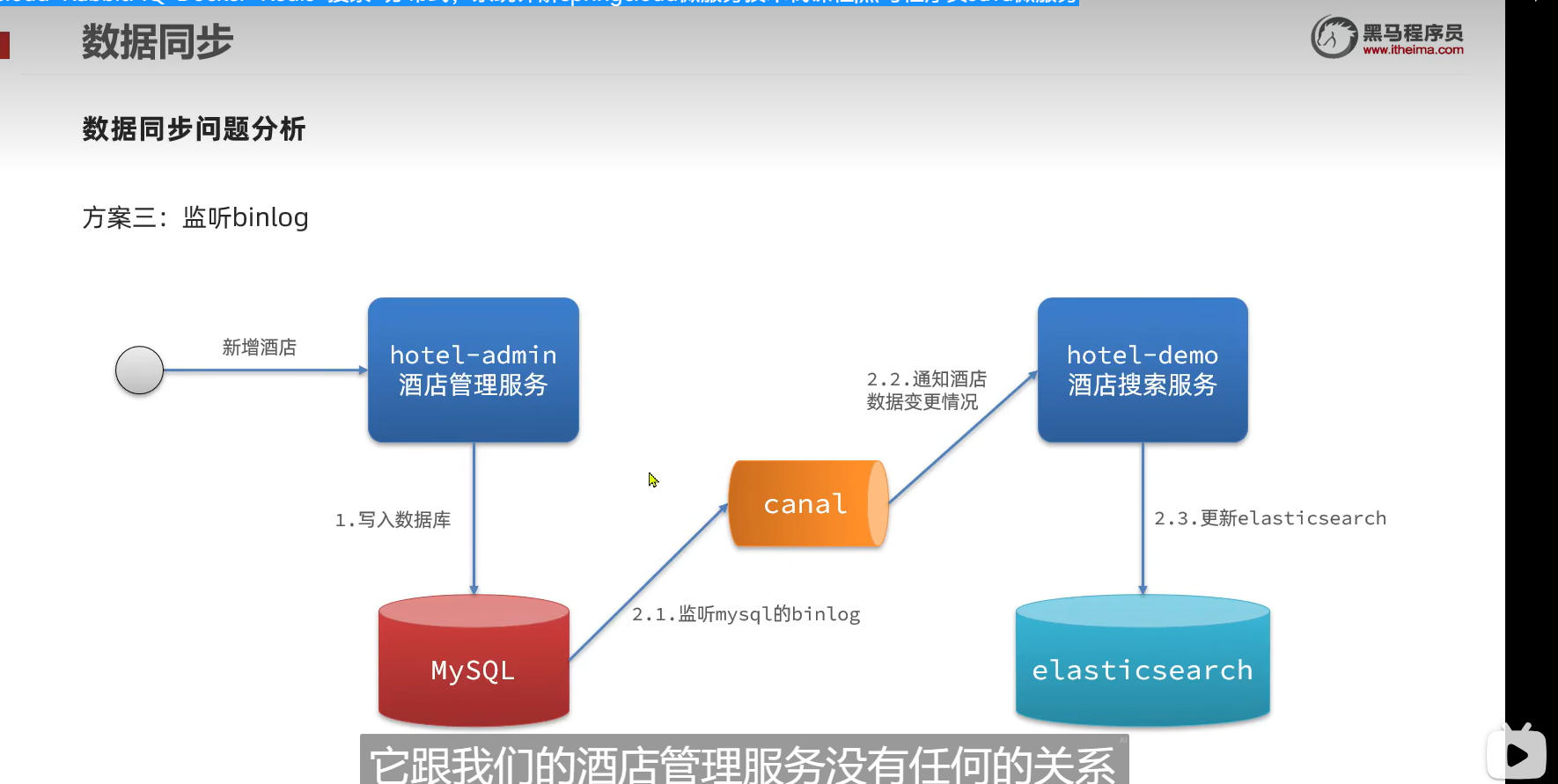
binlog

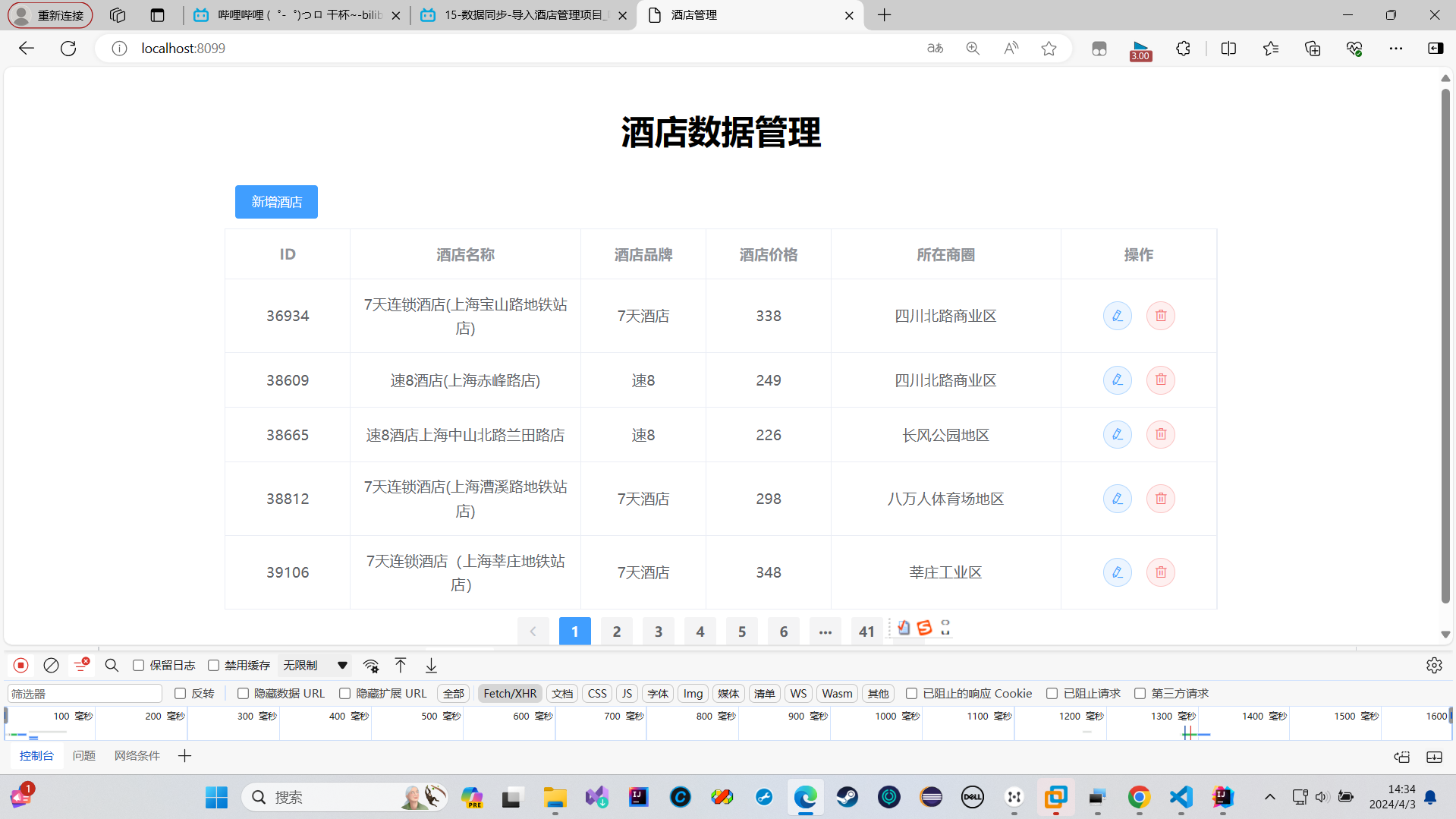
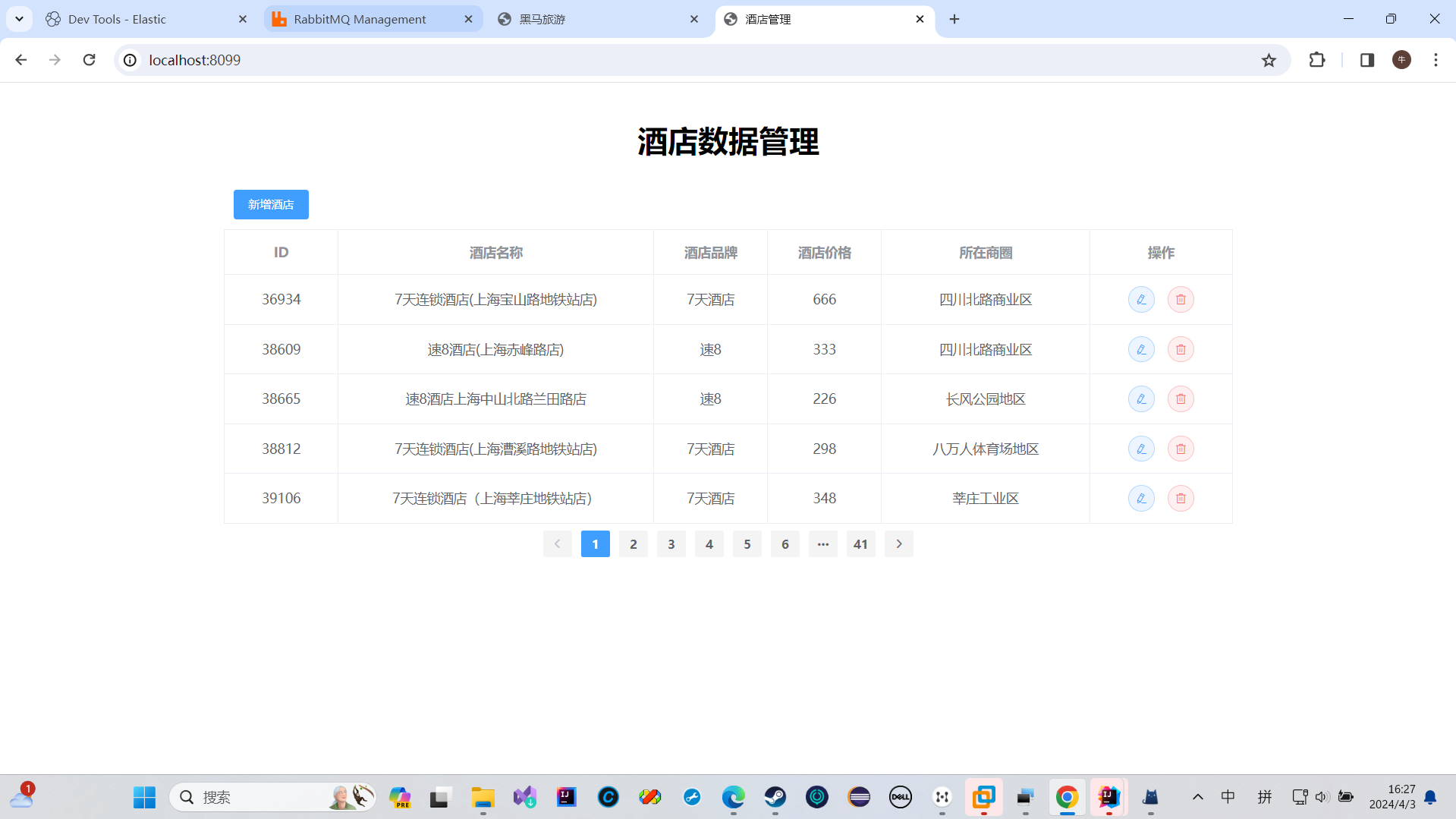
导入酒店管理项目

测试了一下,发现修改功能没有问题
声明队列和交换机
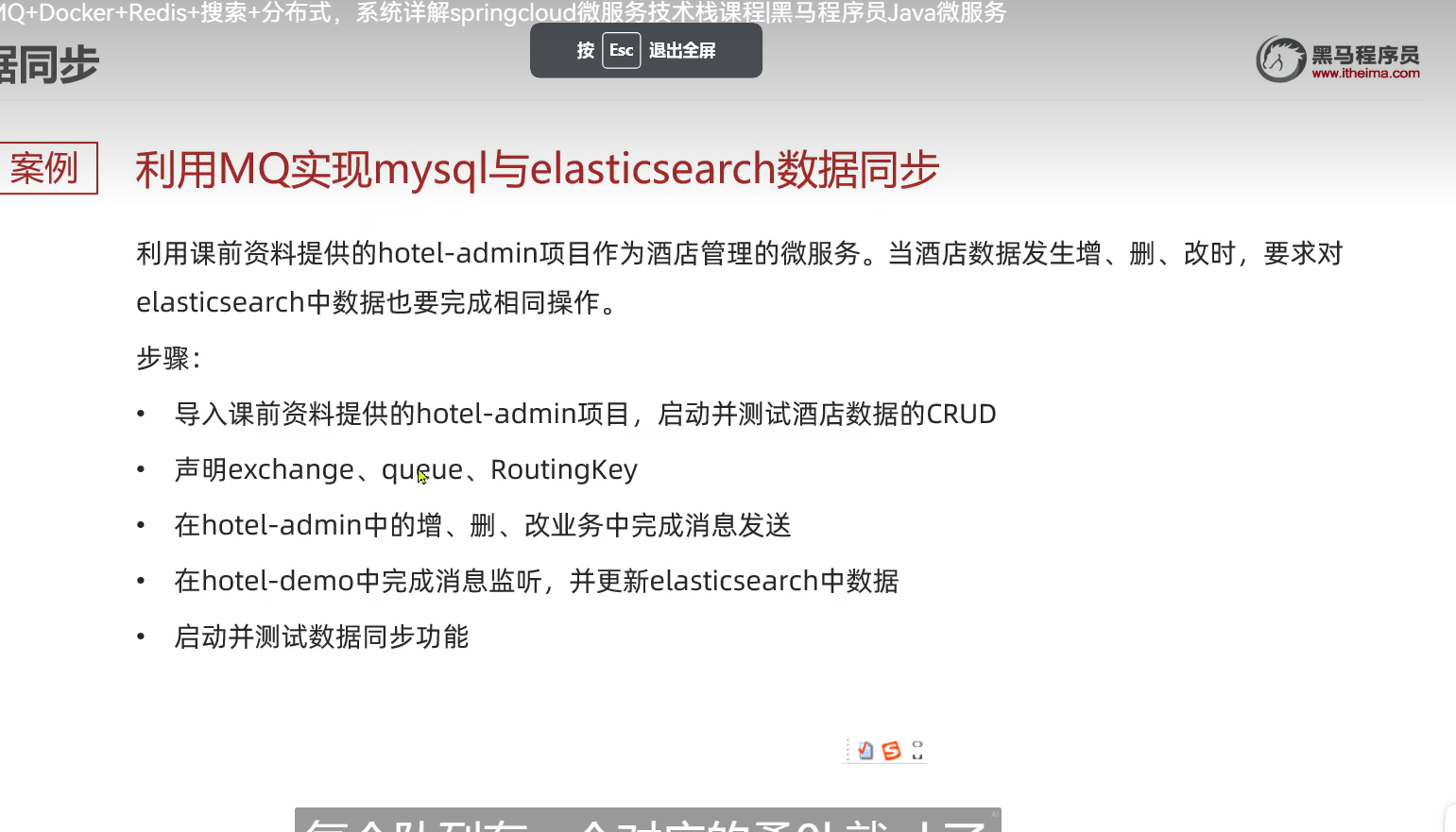
es里面,id不存在的话在修改时会自动添加
所以我们可以把es的新增和修改业务写在一起
分成两类消息
一类是新增和修改
一类是删除
然后我们要配置一下,我们的AMQP的地址,即连接的rabbitMQ
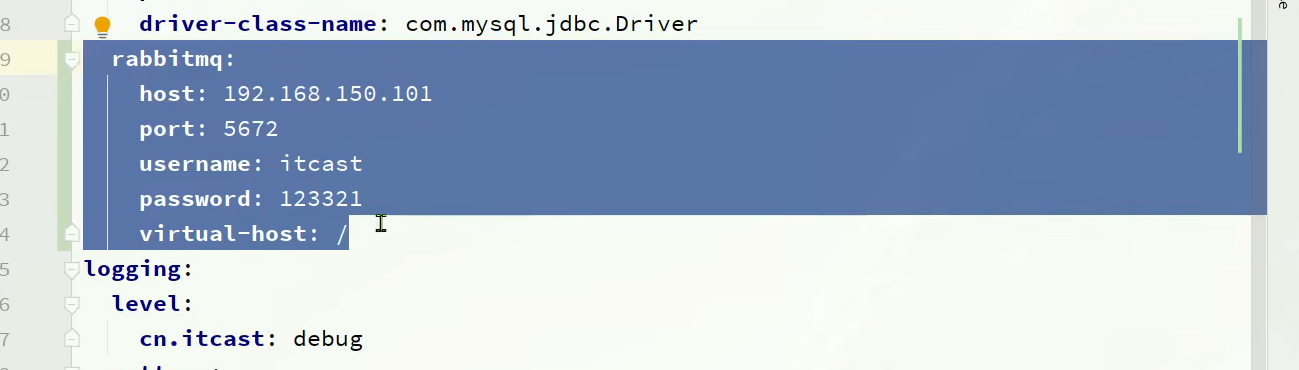

我们定义常量
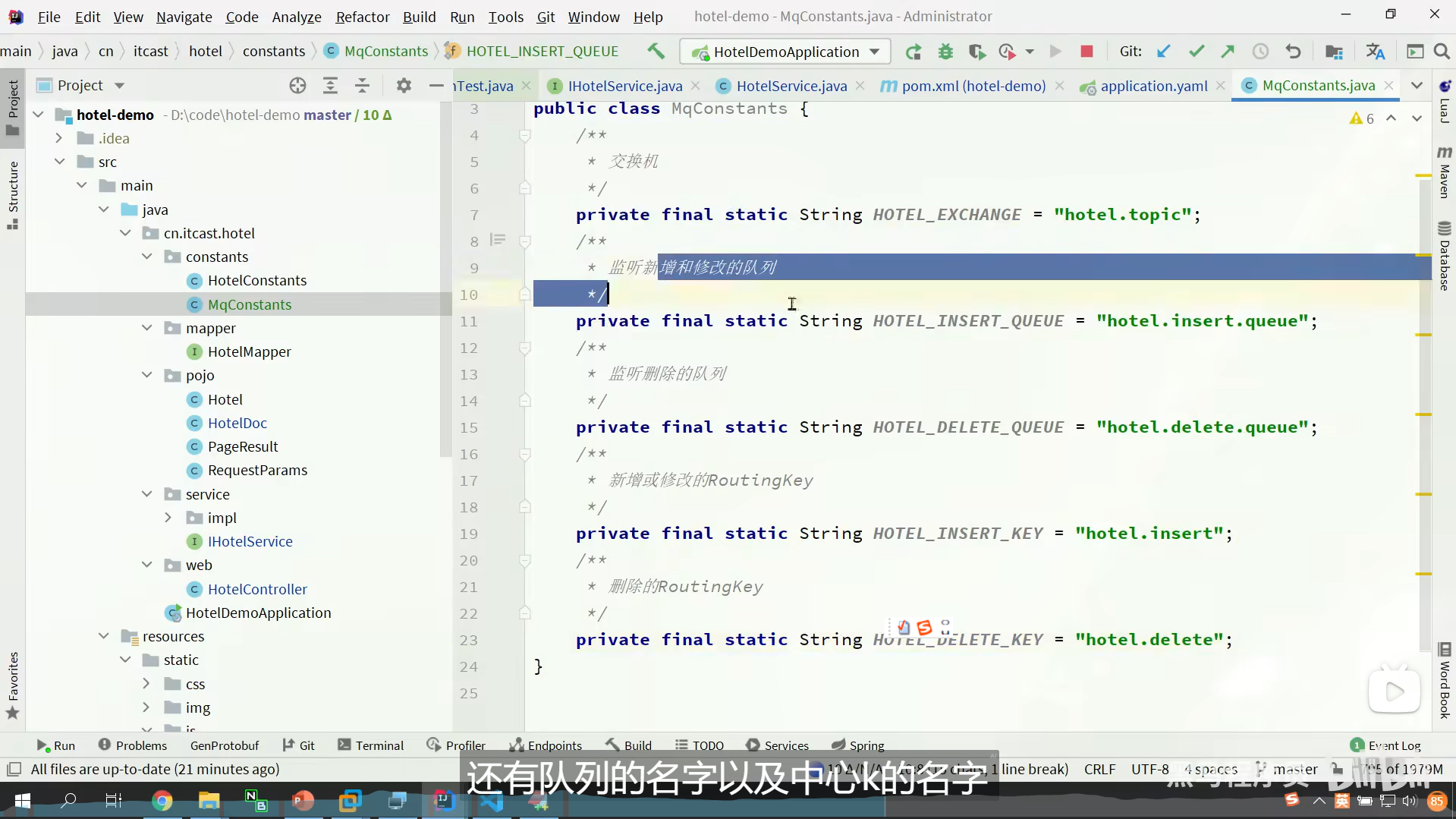
定义方式有两种
一种是基于注解
一种是基于bean
这里用基于bean的方式来演示
我们这样子就实现了一个交换机的定义了
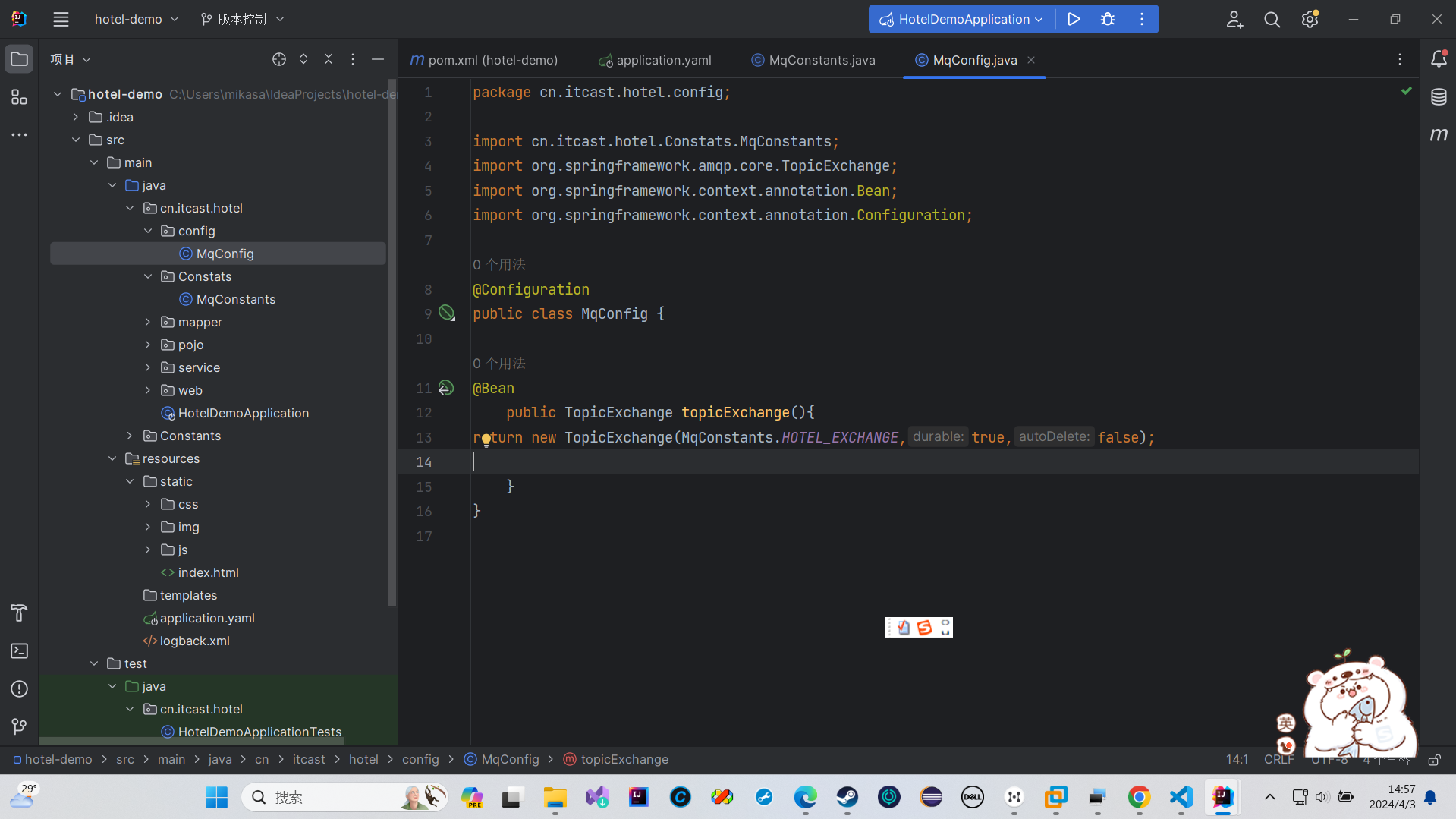
然后我们来定义两个队列
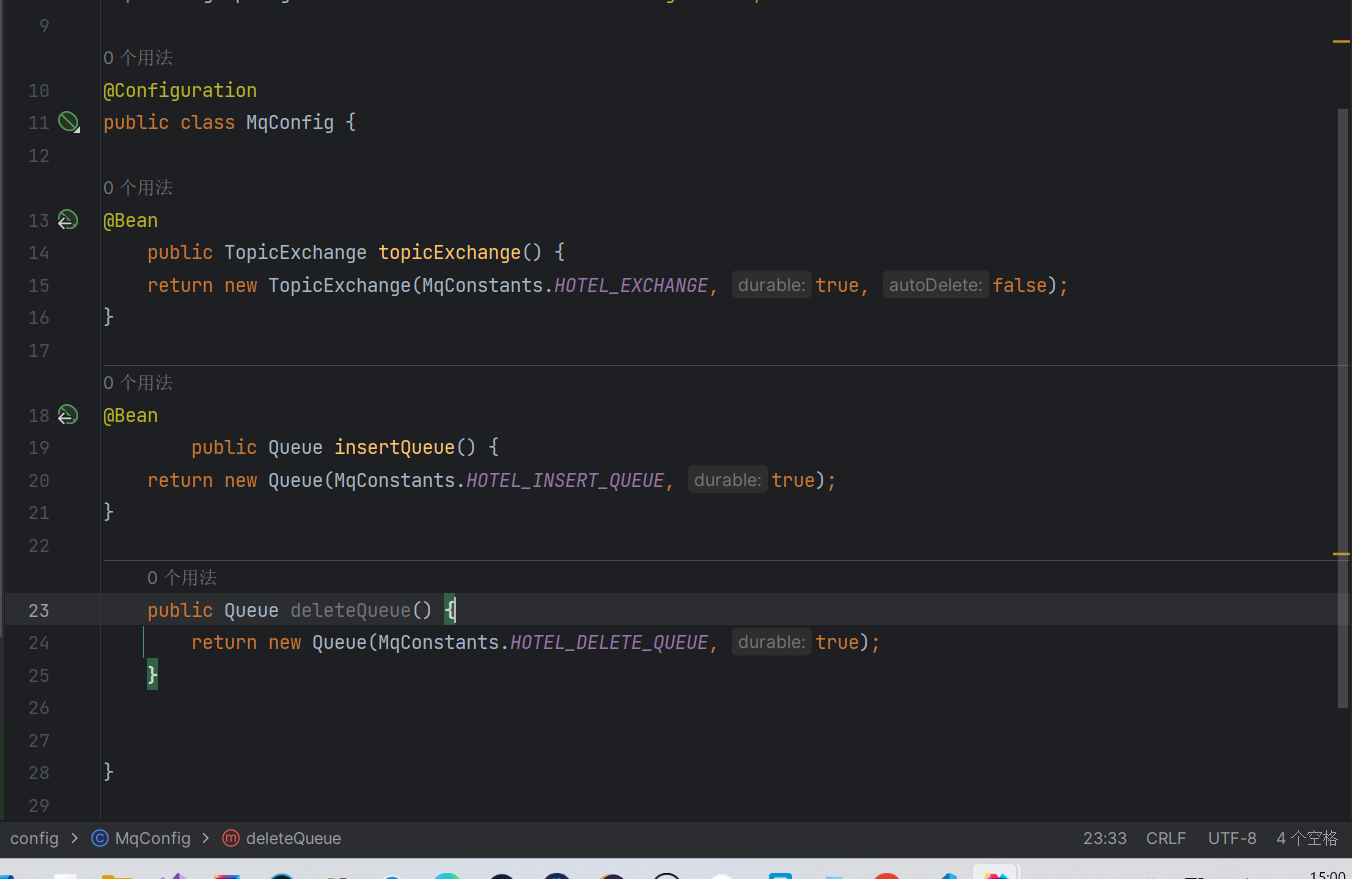
然后我们绑定我们的队列和交换机

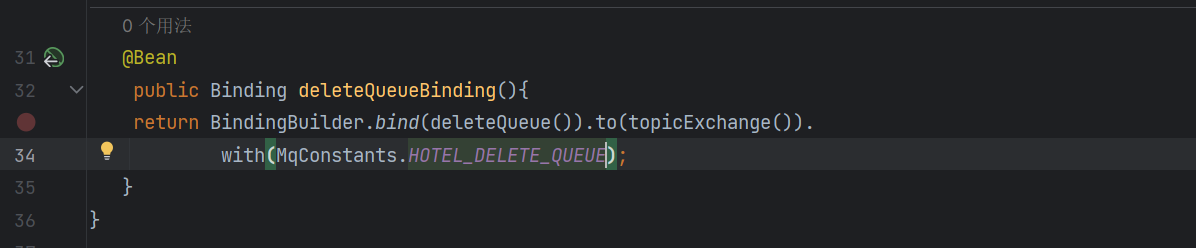
发送MQ消息
我们在我们的业务层注入我们的rabbitTemplate
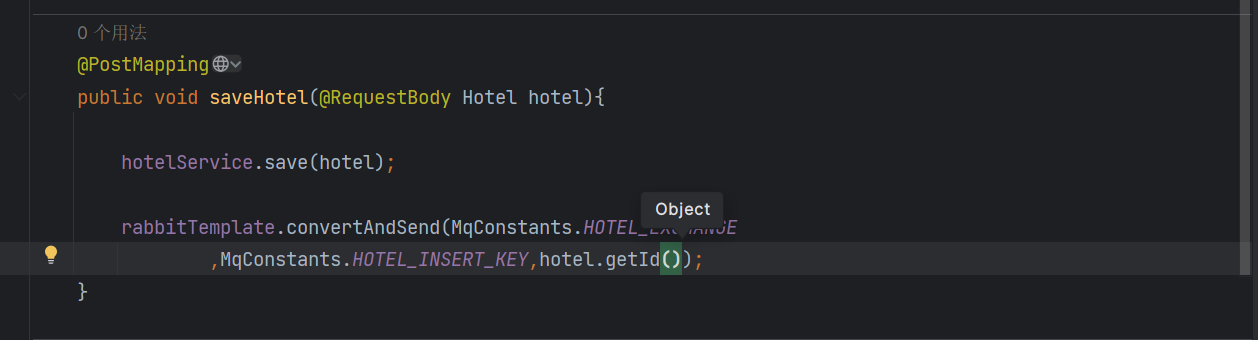
我们新增的时候,要发送消息给我们的交换机
我们没必要把所有都发过去,我们只要把ID发过去就行了,它可以根据ID来查询
监听MQ消息
Component注解
加了Component注解后
我们就能用RabbitListener来标记消费者了
mq监听到后执行者两个方法
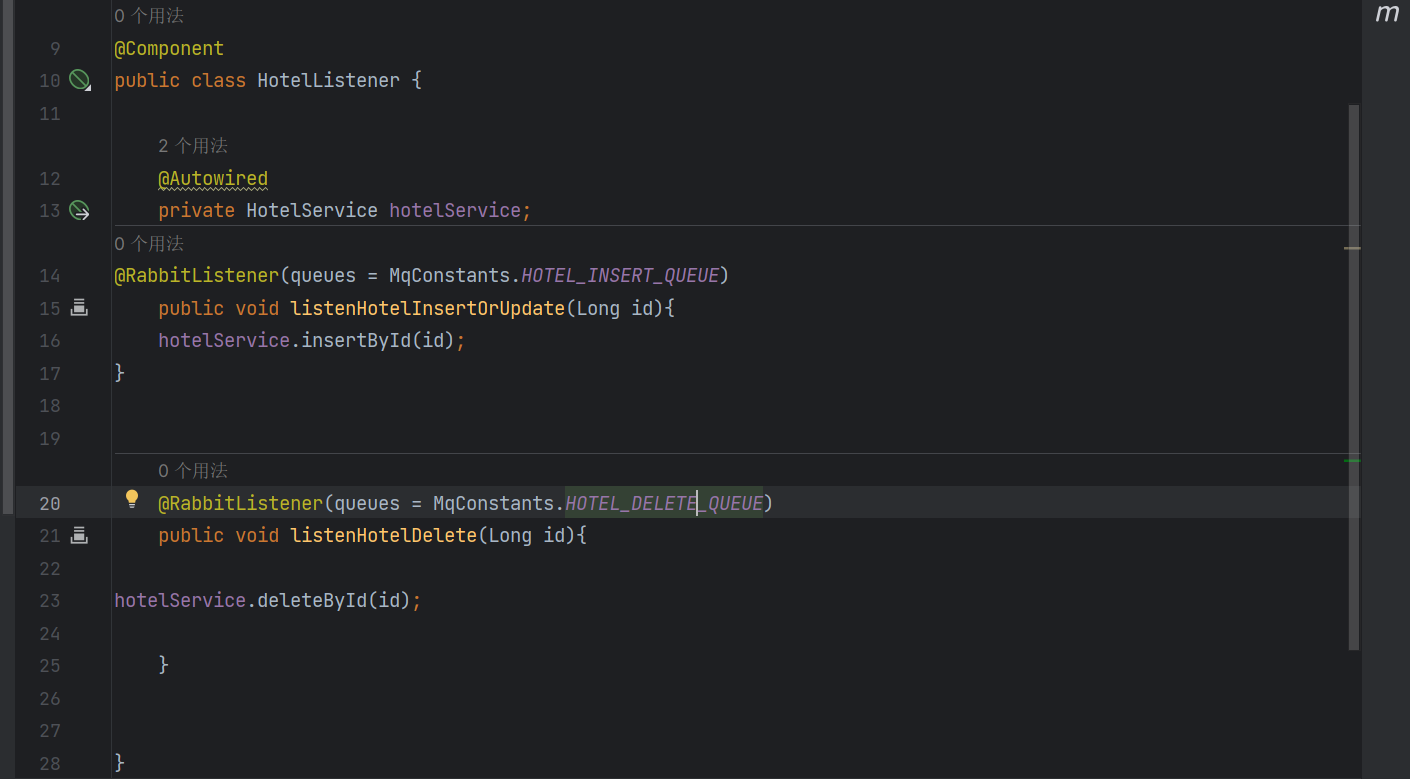
deleteById
insertById
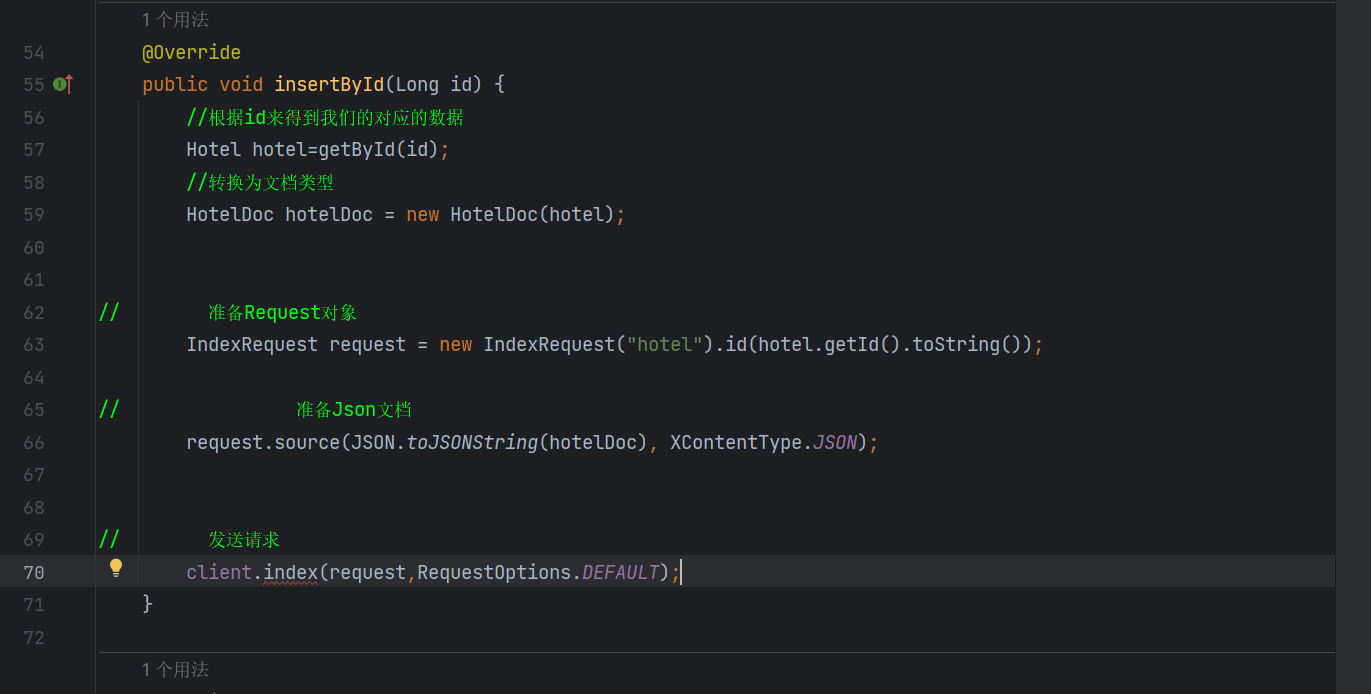
然后我们在接口里面实现我们的方法
然后再service里面写方法的具体
然后把我们的之前TEST里面写的东西拿过来
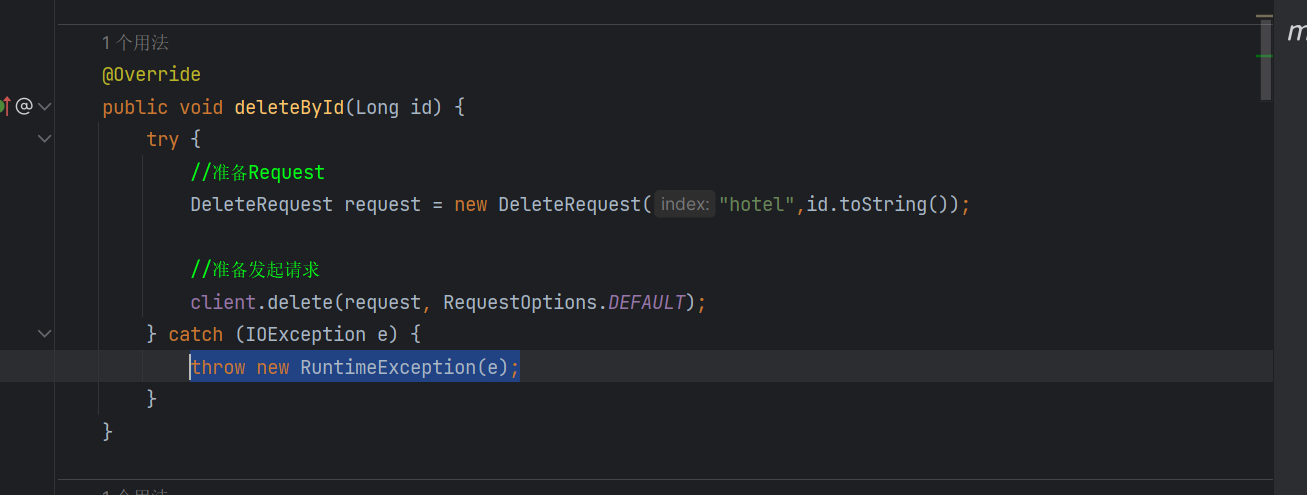
这是我们之前的删除的代码

测试同步功能
我们发现我们创建的两个队列在里面了
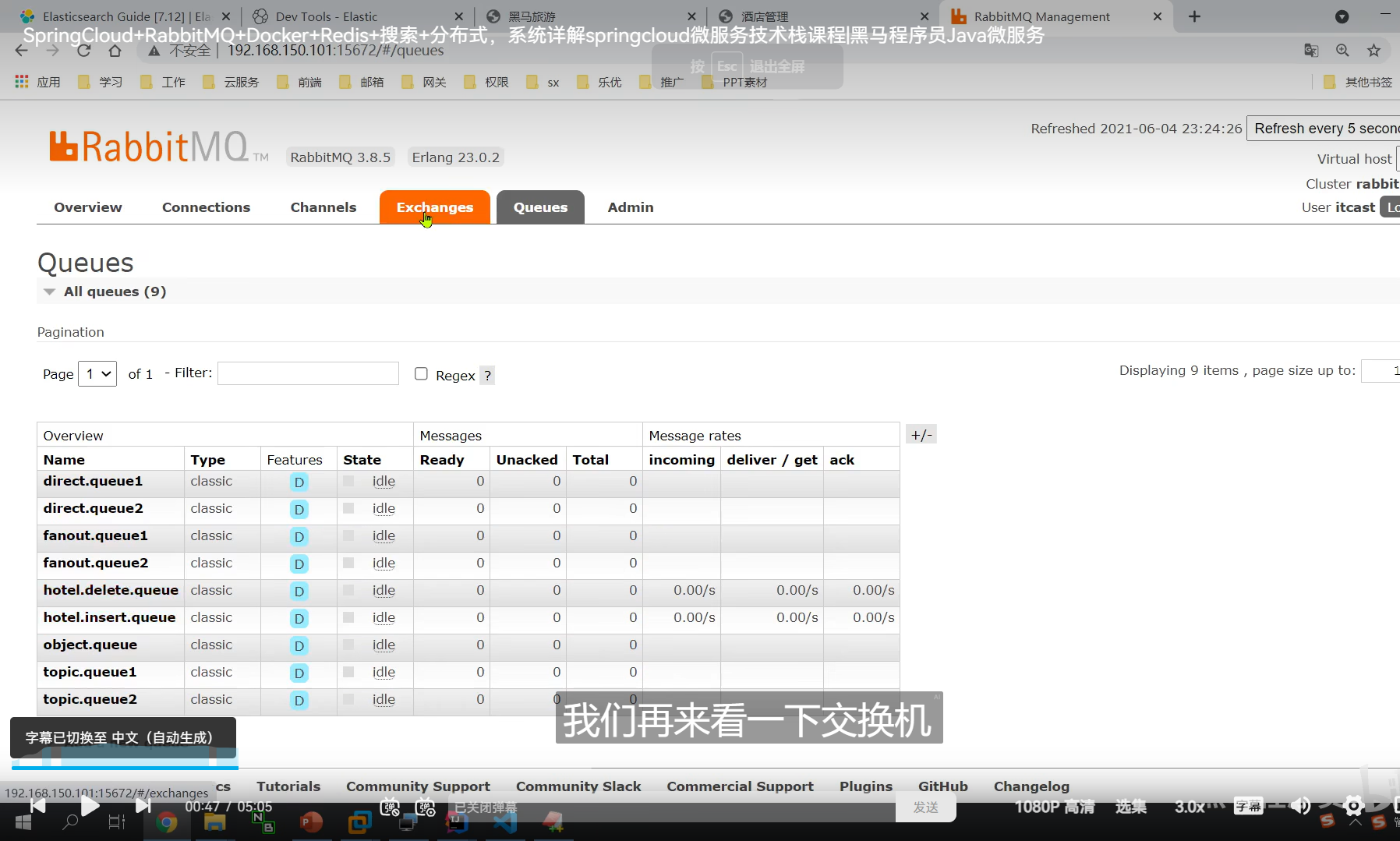
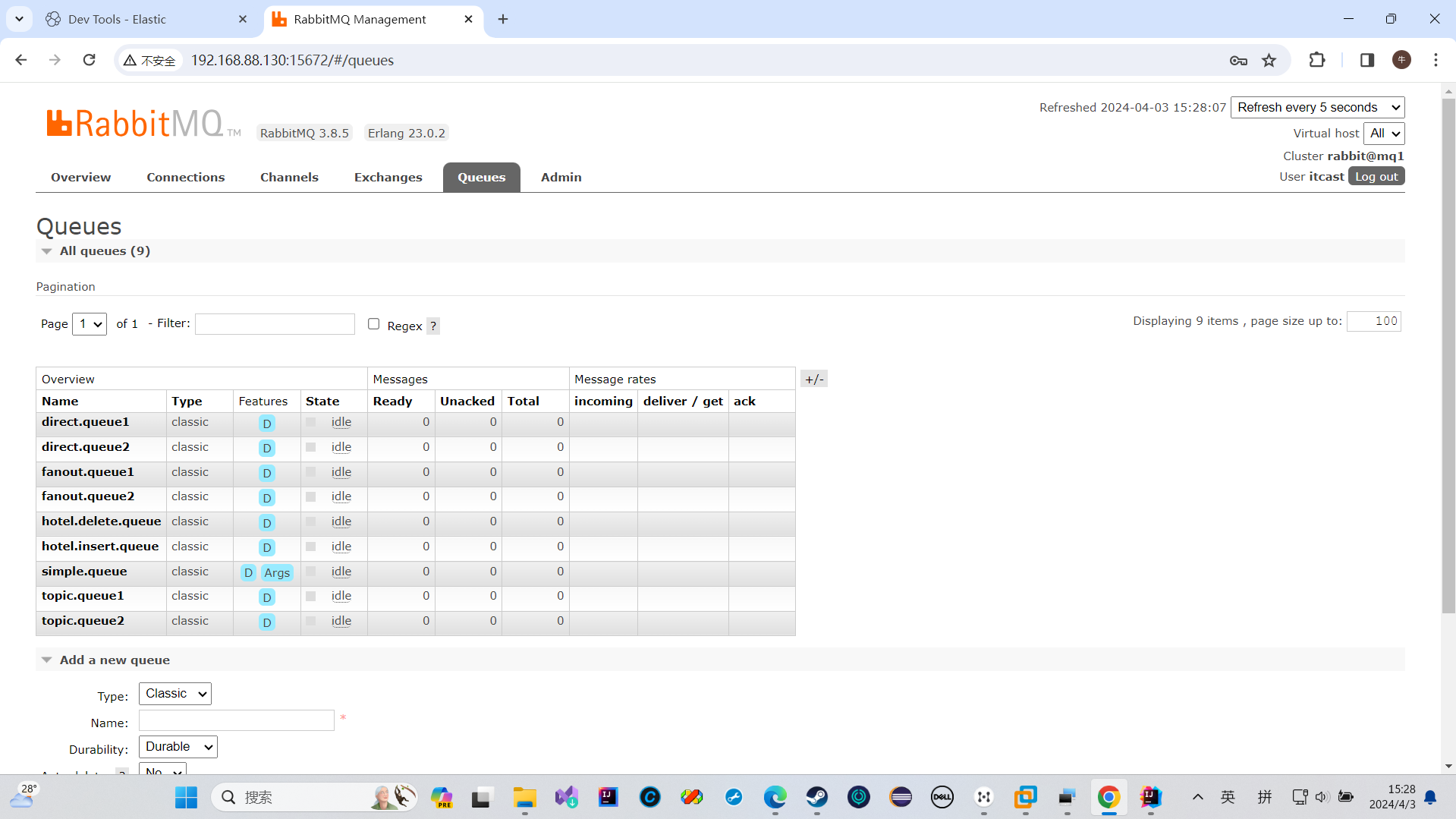
绑定也成功了
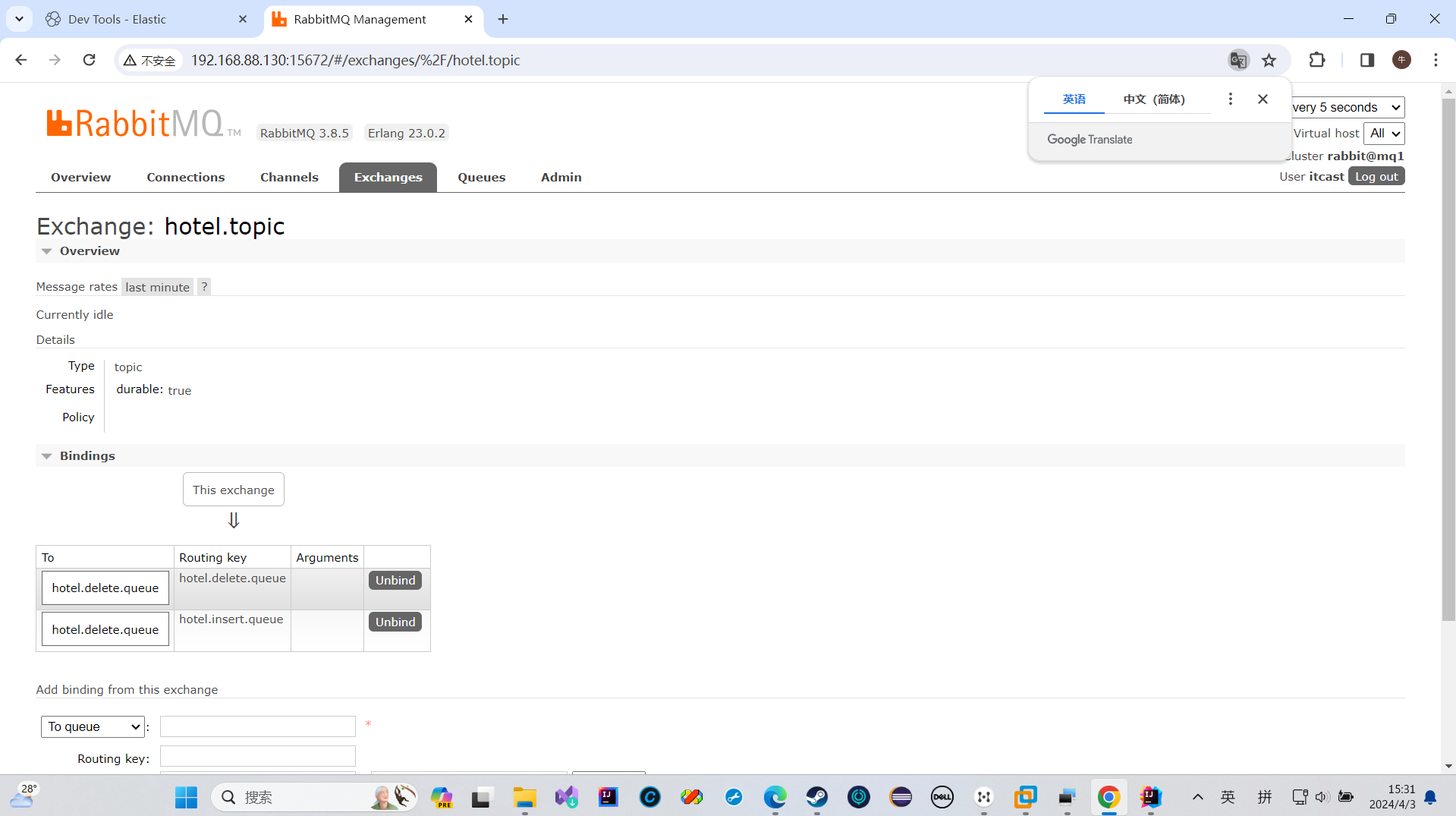
我发现我之前执行不了
是因为把insertqueue绑定错了
我把新增修改的那个虚拟机绑定到删除那里去了,所以我之前操作失败
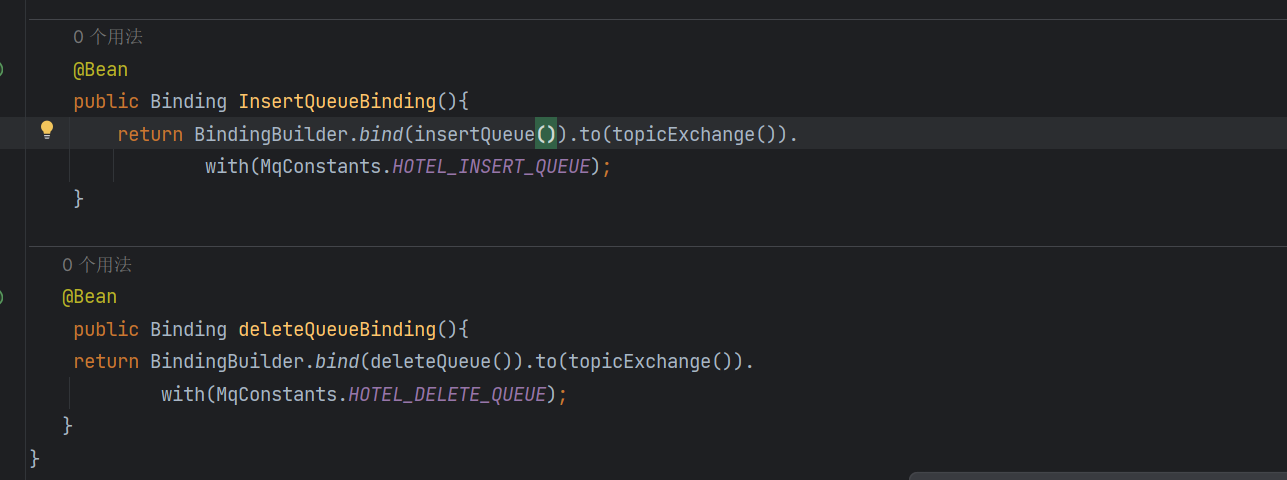
还有我的routingkey也绑定错误了
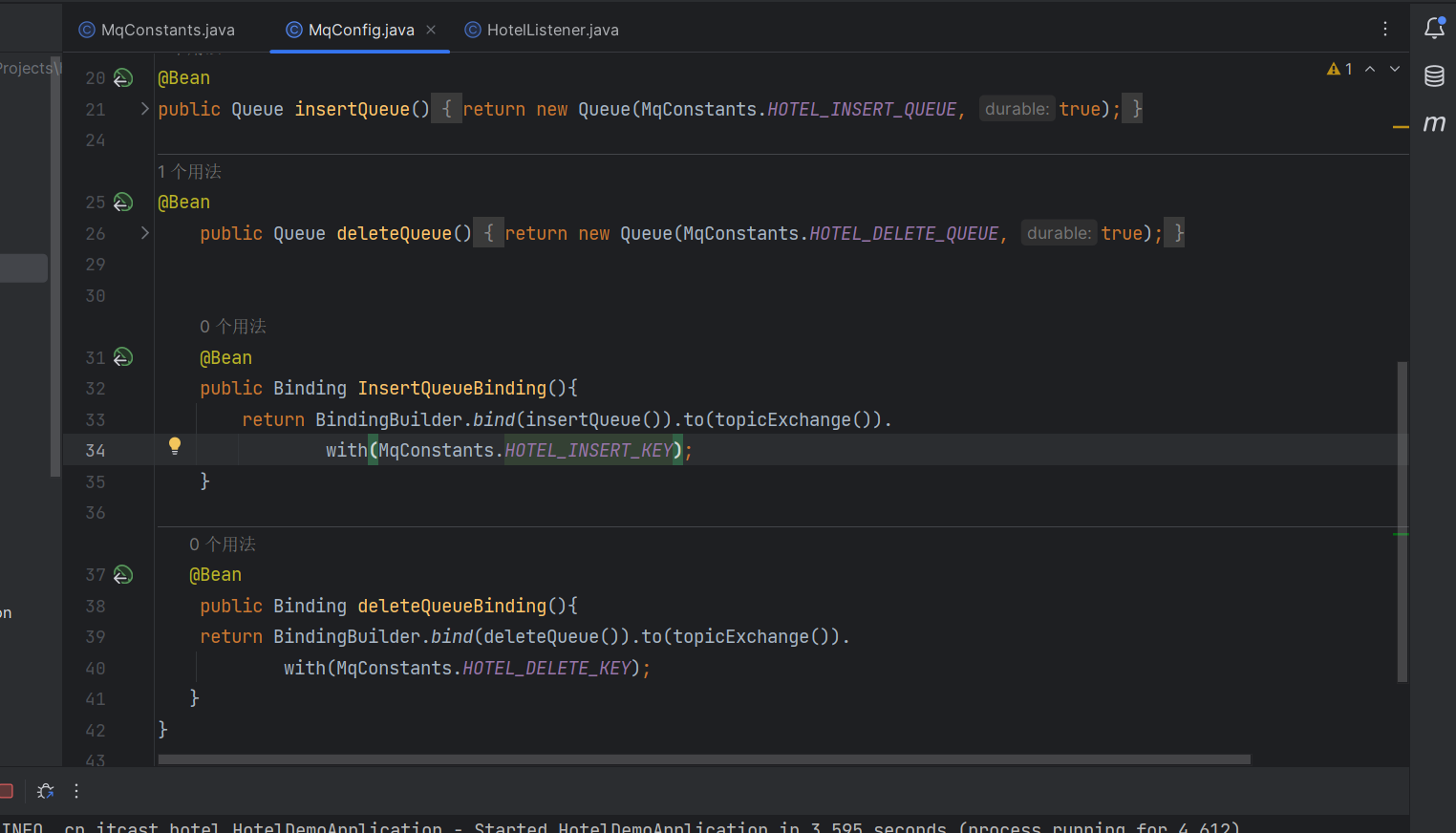
我绑定的key之前写的是QUEUE
OK
这次我的MQ交换机发送没问题了
成功执行了
两个项目的结合

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)