利用TTS、ASR与LLM赋能视频会议系统
语音识别(ASR)、文本转语音(TTS)与大语言模型(LLM)等 AI 技术的深度融合,正彻底改变会议的 “会前 - 会中 - 会后” 全流程,解决会议记录繁琐、信息传递低效、跨语言沟通障碍等核心痛点。以下代码基于 Python 实现,选用开源工具(如 Whisper for ASR、GPT-3.5-turbo for LLM、pyttsx3 for TTS),演示智能会议的核心流程。: 接收来自
在远程协作成为常态的今天,视频会议系统已从单纯的 “音视频传输工具” 进化为 “智能协作中枢”。语音识别(ASR)、文本转语音(TTS)与大语言模型(LLM)等 AI 技术的深度融合,正彻底改变会议的 “会前 - 会中 - 会后” 全流程,解决会议记录繁琐、信息传递低效、跨语言沟通障碍等核心痛点。本文将系统阐述智能视频会议的技术架构、关键应用场景,并提供核心模块的代码示例,为系统升级提供实践指引。
一、智能视频会议系统的核心价值体验与技术逻辑
1.1 智能视频会议系统的核心价值
传统视频会议的核心是 “连接”,而智能视频会议的核心是 “理解与赋能”。ASR、TTS、LLM 的组合解决了 “语音 - 文本 - 语义 - 语音” 的闭环转化问题,具体价值体现在三方面:
-
效率提升:ASR 自动转写会议内容,LLM 自动生成纪要、提炼重点,减少 80% 的人工记录成本;
-
体验优化:TTS 将文字实时转为自然语音,LLM 提供实时问答、摘要总结,降低参会者信息接收负担;
-
场景拓展:结合 LLM 的跨语言翻译能力,实现多语言实时互译;结合 ASR 的说话人分离,实现个性化记录与追溯。
1.2 智能技术如何重塑视频会议体验
-
自动语音识别 (ASR) - “听得懂”
-
实时字幕/转录: 为听障人士、在嘈杂环境或不便开扬声器的与会者提供支持。
-
多语言实时翻译字幕: 将一种语言的语音实时转译并显示为另一种语言的文字。
-
会议纪要生成: 为后续生成会议摘要和待办事项提供原始文本材料。
-
功能: 将会议中的实时语音流转换为高精度的文本。
-
应用场景:
-
大语言模型 (LLM) - “听得明白”
-
-
智能会议摘要: 自动提炼会议的核心论点、决策和结论。
-
行动项提取: 自动识别并分配会议中提到的任务(To-Do Items)。
-
智能问答: 与会者可以随时提问“我们刚才讨论了什么关于预算的问题?”,LLM能基于上下文立即回答。
-
内容增强: 根据讨论内容,实时推荐相关文档或资料。
-
功能: 理解、总结、推理和生成基于会议文本内容的信息。
-
应用场景:
-
-
文本转语音 (TTS) - “会说话”
-
-
语音助手交互: 允许用户通过语音命令控制会议(如“嘿,助手,加入会议”),并由TTS进行语音反馈。
-
无障碍访问: 为有视觉障碍的与会者朗读聊天消息、会议摘要或界面元素。
-
内容播报: 在会议开始时自动播报议程,或在结束时朗读总结。
-
功能: 将文本信息转换为自然、富有表现力的语音。
-
应用场景:
1.3 三者的技术逻辑链
三者技术逻辑链为:ASR 将会议语音转化为结构化文本→LLM 对文本进行语义理解、分析与生成→TTS 将 LLM 输出的文本(如纪要、翻译结果)转化为自然语音,形成 “感知 - 理解 - 生成” 的智能闭环。
二、智能视频会议系统的整体架构设计
智能视频会议系统采用 “分层解耦” 架构,分为基础层、AI 能力层、应用层、交互层四个核心层级,各层通过 API 无缝衔接,支持灵活扩展。
2.1 架构图
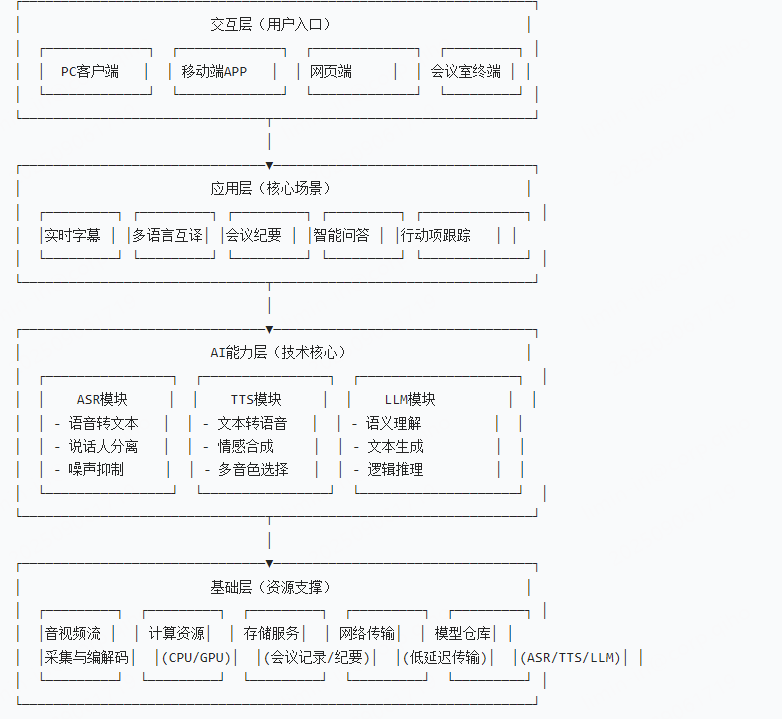
2.2 TTS、ASR和LLM的云端智能视频会议系统的核心组件与数据流程图
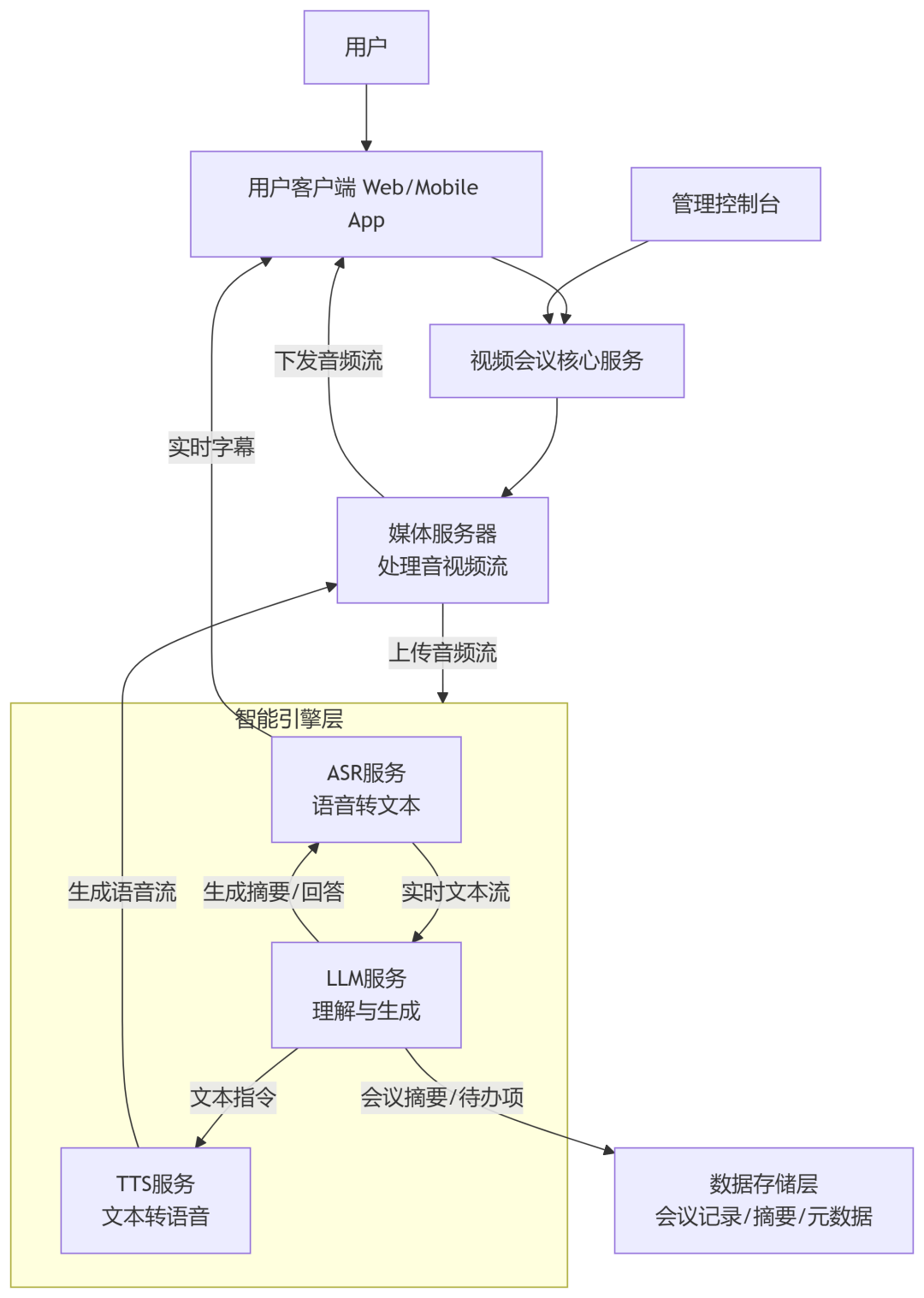
架构说明:
-
用户客户端: 提供会议界面,负责音视频的采集、渲染和最终展示(如字幕、AI语音)。
-
视频会议核心服务: 处理信令、用户管理、房间管理和会话控制。
-
媒体服务器: 负责音频流的编解码、混音、降噪以及分发。它是连接客户端和智能引擎的桥梁。
-
智能引擎层(核心):
-
ASR服务: 接收媒体服务器转发的音频流,进行实时语音识别,并将文本结果发送给LLM服务和客户端(用于字幕)。
-
LLM服务: 接收来自ASR的实时文本流,维护会议上下文,处理用户查询(如问答),并生成摘要、提取行动项。它是系统的“大脑”。
-
TTS服务: 接收LLM或系统发出的文本指令(如问答答案、语音通知),将其转换为自然语音流,发回媒体服务器。
-
-
数据存储层: 持久化存储会议录音、转录文本、最终摘要和元数据,供用户会后查阅。
-
三、核心模块的代码示例
以下代码基于 Python 实现,选用开源工具(如 Whisper for ASR、GPT-3.5-turbo for LLM、pyttsx3 for TTS),演示智能会议的核心流程。
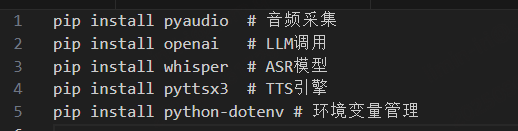
3.1 环境准备
首先安装依赖包:
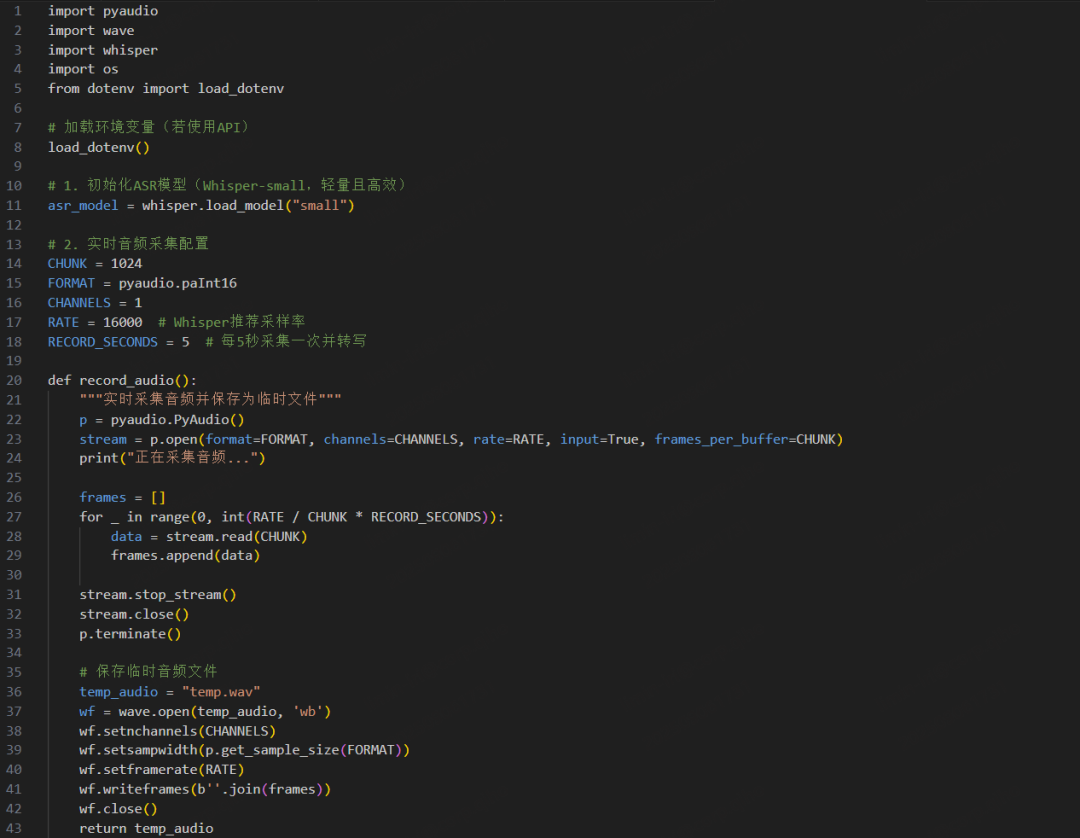
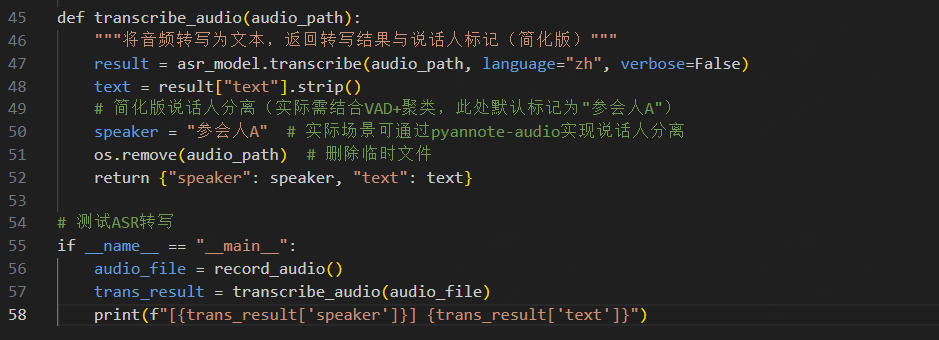
3.2 模块 1:ASR 语音转写(含实时采集)
使用 OpenAI 的 Whisper 模型实现语音转写,支持实时采集与说话人分离(简化版)
3.3 模块 2:LLM 会议纪要生成
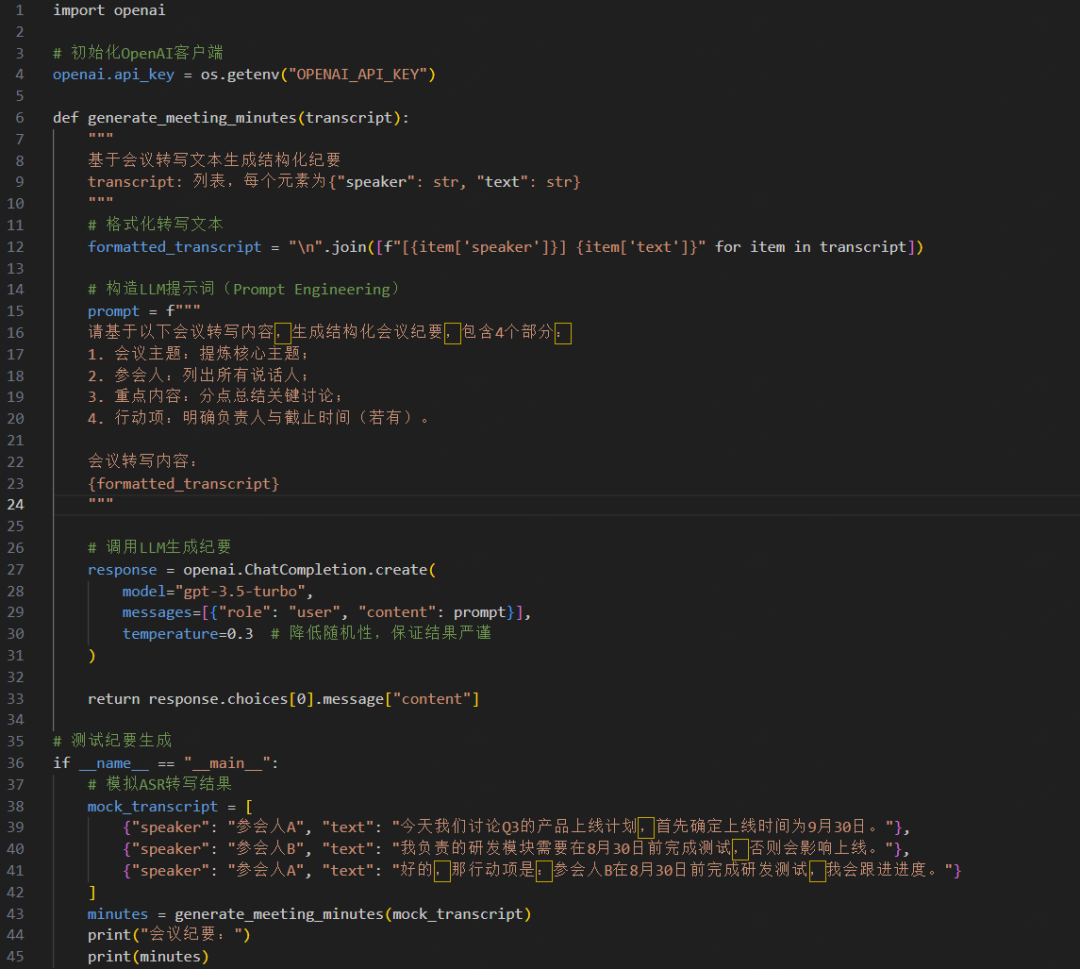
调用 GPT-3.5-turbo 模型,基于 ASR 转写的全文生成结构化会议纪要。
3.4 模块 3:TTS 语音合成(纪要朗读)
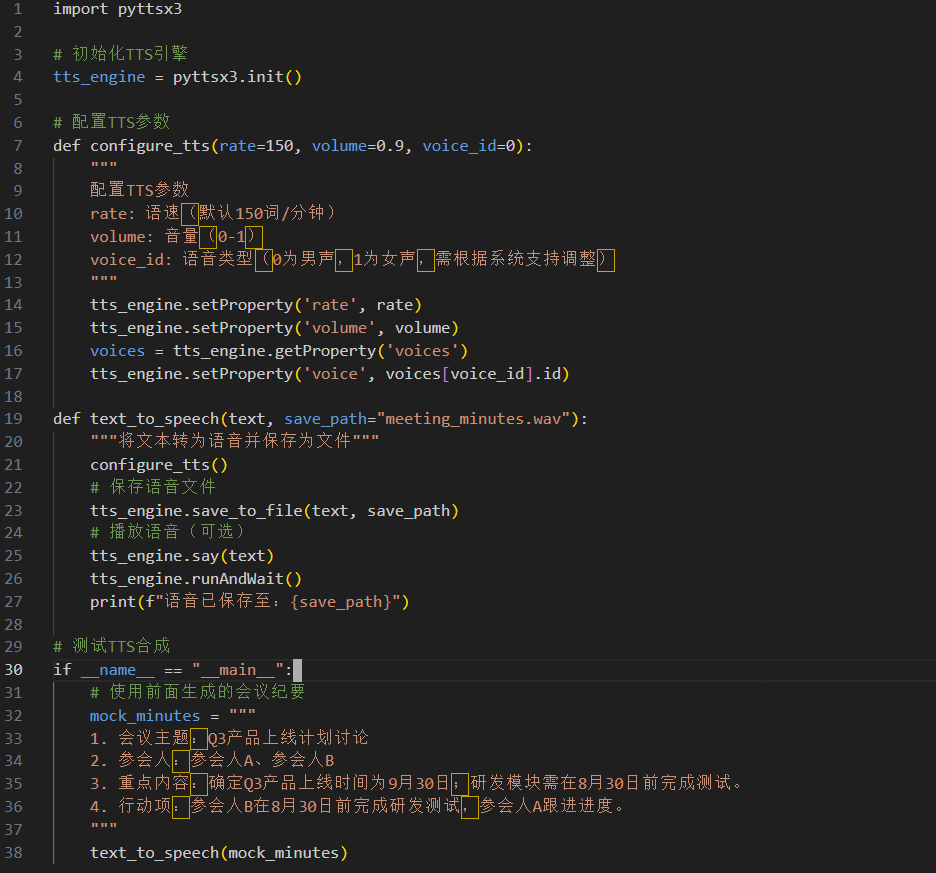
使用 pyttsx3 将 LLM 生成的纪要转为语音,支持本地离线合成。
3.5 完整流程串联
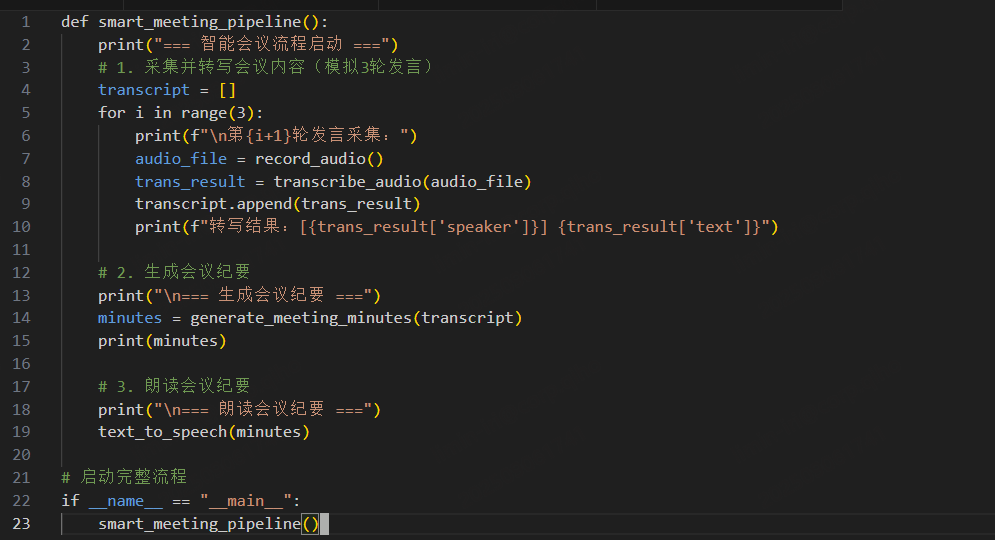
将 ASR、LLM、TTS 串联,实现 “实时采集→转写→纪要→朗读” 的闭环:
四、系统落地的关键挑战与解决方案
将 AI 技术融入视频会议并非一蹴而就,需解决以下核心挑战:
4.1 低延迟要求
挑战:实时字幕、翻译需保证延迟 < 2 秒,否则影响参会体验。
解决方案:-
采用 “流式 ASR”(如 Whisper 的 streaming 模式),边采集边转写,而非整段处理;
-
优化 LLM 调用:使用轻量化模型(如 Llama 2-7B)部署本地 GPU,替代远程 API,减少网络延迟。
4.2 说话人分离准确性
挑战:多人同时发言时,ASR 难以区分说话人。
解决方案:-
结合 “语音活动检测(VAD)”(如 webrtcvad),识别说话人切换时机;
-
引入专门的说话人分离模型(如 pyannote-audio),基于语音特征聚类区分不同参会人。
4.3 多场景适配
挑战:会议室、居家等不同场景的噪声(如键盘声、回声)影响 ASR accuracy。
解决方案:-
前端音频预处理:使用噪声抑制算法(如 noisereduce)降低背景噪声;
-
后端模型适配:在 ASR 模型训练中加入多场景噪声数据,提升鲁棒性。
五、结论
通过将TTS、ASR和LLM无缝集成到视频会议系统中,我们可以将会议从被动的信息接收转变为主动的、可操作的协作体验。这不仅能显著提升生产力和无障碍访问性,更是迈向“AI原生”协作生态系统的关键一步。随着这些AI技术的不断成熟和成本的降低,智能会议将成为所有协作工具的标配。
智汇云视频会议地址:https://zyun.360.cn/product/vcs
-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)