大模型五大场景评估基准全解析:从医疗到Agentic的实战指南
文章研究了大模型在医疗、金融、法律、多模态和agentic五大场景中的评估基准。通过分析24个代表性benchmark,提取了各场景的评估任务和指标架构,包括医疗问答中的准确率与事实性评估,金融领域的信息提取与推理能力测试,法律推理的多维度评估,多模态理解与生成能力测试,以及agentic场景的决策与工具使用能力评估。这些评估体系为大模型在各领域的应用提供了标准化的评测方法。
文章研究了大模型在医疗、金融、法律、多模态和agentic五大场景中的评估基准。通过分析24个代表性benchmark,提取了各场景的评估任务和指标架构,包括医疗问答中的准确率与事实性评估,金融领域的信息提取与推理能力测试,法律推理的多维度评估,多模态理解与生成能力测试,以及agentic场景的决策与工具使用能力评估。这些评估体系为大模型在各领域的应用提供了标准化的评测方法。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
我们深度拆解了医疗、金融、法律、多模态、agentic等五大场景中24个具有代表性的benchmark,提取出了这五个场景中模型的评估任务和评估指标架构。
医疗问答场景中的评估任务和评估指标设计
用7个医疗相关的benchmark来研究在医疗问答场景里的评估任务和评估指标
MedMCQA(印度, 2022)
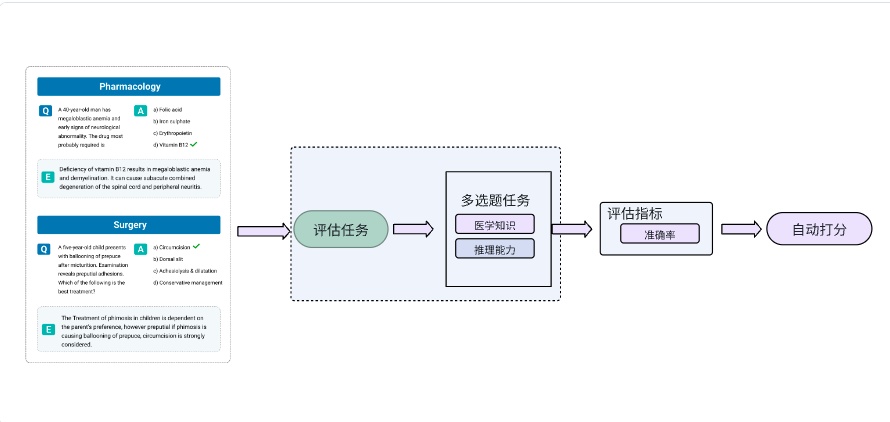
MedMCQA基准,这是一个大规模、多学科、多选题(MCQA)数据集,专门设计用于应对真实世界的医学入学考试问题的综合评测基准。
在MedMCQA这个benchmark里,评估任务为选择题任务,包含单选题和多选题,都是客观任务。评价指标是准确率。
MultiMedQA (Google, 2023)
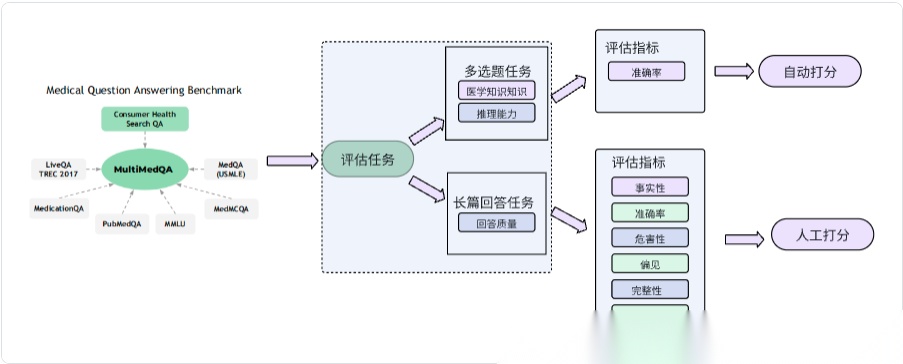
MultiMedQA 基准,这是一个结合了六个现有开放问题回答数据集(涵盖专业医疗考试、研究和消费者查询)以及一个新数据集 HealthSearchQA(在线搜索的医疗问题)的综合评测基准。
在MultiMedQA这个benchmark里,评估任务为多选题任务和长篇回答任务,一个客观一个主观。选择题有参考答案,长篇回答问题无gold standard/Ground thruth,因此由人类人工打分。
对于客观多选题任务,评估指标是准确率。对于主观的长篇回答任务,评估指标为事实性,准确率,危害性,偏见,完整性,有用性
CMExam(清华,阿里等 2023)
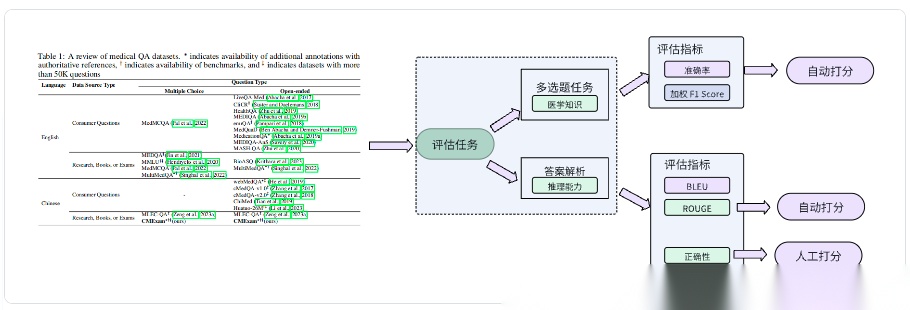
CMExam是一个从中国国家医学执照考试(CNMLE)中收集的大型中文医学考试数据集,包含 60,000 多个多选题,用于标准化和客观评估大型语言模型(LLMs)在医学领域的表现。
CMExam的评估任务设计为答案预测任务(多选题)和答案解析任务(开放式推理),其中答案解析任务85.24%有参考解析(gold standard/Ground thruth**)**)
MedExQA(英国, 2024)
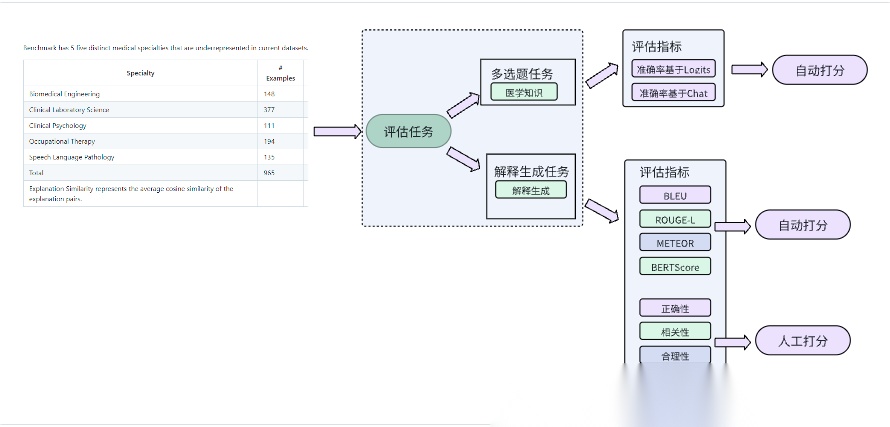
主要用于评估大语言模型(LLMs)在生成医疗解释方面的能力。它聚焦于医学解释生成质量而不仅仅是选择题的答题准确率.
在这个benchmark里,评估任务为多选题以及对正确选项的解释生成。选择题为客观题,解释生成也有gold standard/Ground thruth。
MedBench(复旦等, 2024)
MedBench是一个针对中国医学领域的大型基准,包含从真实医学考试和医疗报告中收集的 40,041 个问题,涵盖多种医学分支,旨在为医学大型语言模型(LLMs)提供统一的评估标准。
MedBench的评估任务设计为 医学多选题(MCQ)和真实临床病例问答。选择题为客观题,真实临床病例问答为主观题, 有gold standard/Ground thruth
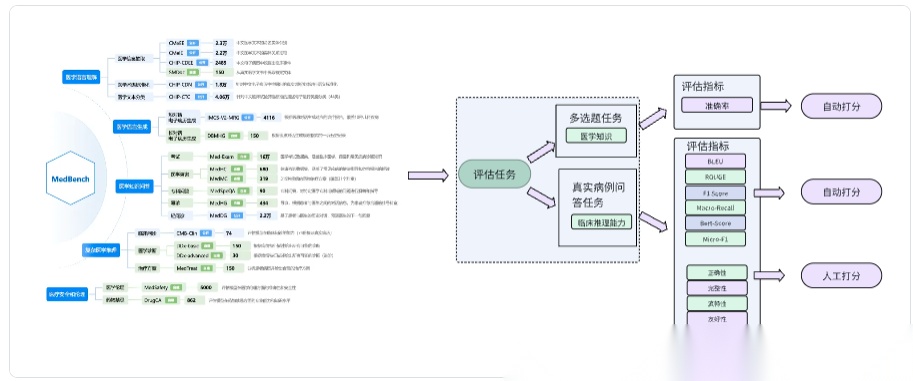
CliMedBench(腾讯等,2024)
CliMedBench是一个包含 33,735 个问题的综合性中文医学基准,涵盖 14 个专家指导的核心临床场景,从 7 个关键维度评估 LLMs 的医学能力,模拟真实医疗实践,测试模型在医学知识、推理能力和临床适用性方面的综合能力。
CliMedBench的评估任务为根据14个不同的临床场景设计了3种类型的任务,分别为多选临床问答任务,排序任务和开放式生成任务
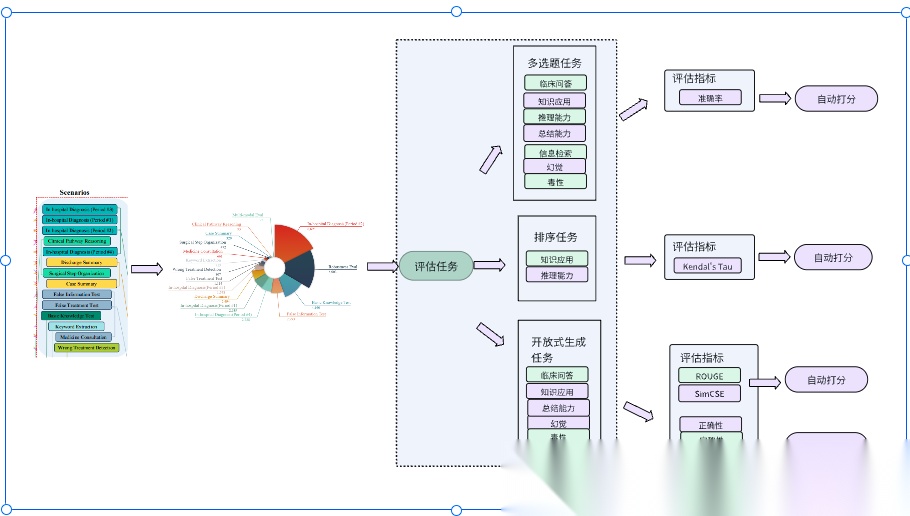
MedAgentsBench(耶鲁,斯坦福等, 2025)
MEDAGENTSBENCH是一个专注于复杂医学问题(需多步临床推理、诊断制定和治疗规划)的基准,包含 862 道 HARD 子集问题,从七个医学数据集抽取,解决了现有基准的简单问题占比高、采样不一致和缺乏成本分析的局限。
MedAgentsBench的评估任务为多选题任务和问答任务(答案符合simpleQA规则,简短明确),主要的评价指标为Pass@1 准确率,其他的辅助指标为成本,推理时间等。
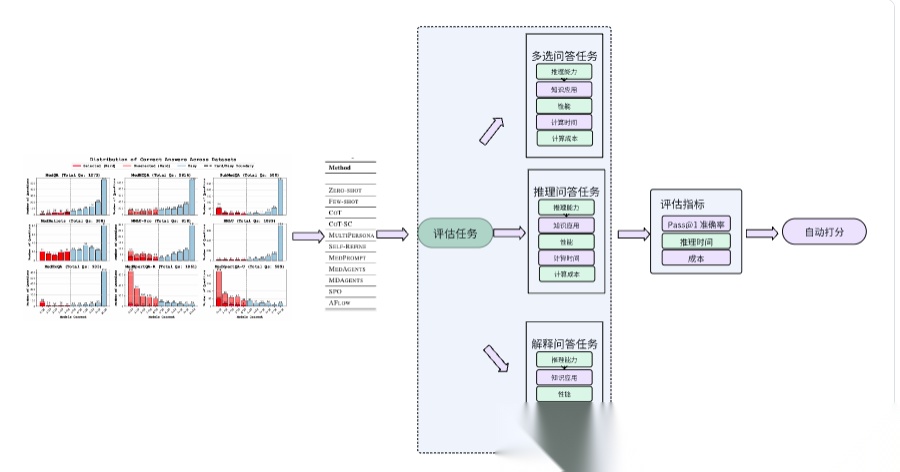
金融问答场景中的评估任务和评估指标设计
用7个金融相关的benchmark来研究在金融问答场景里的评估任务和评估指标
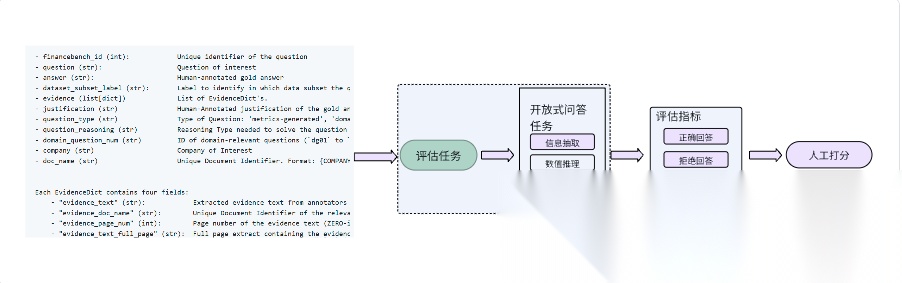
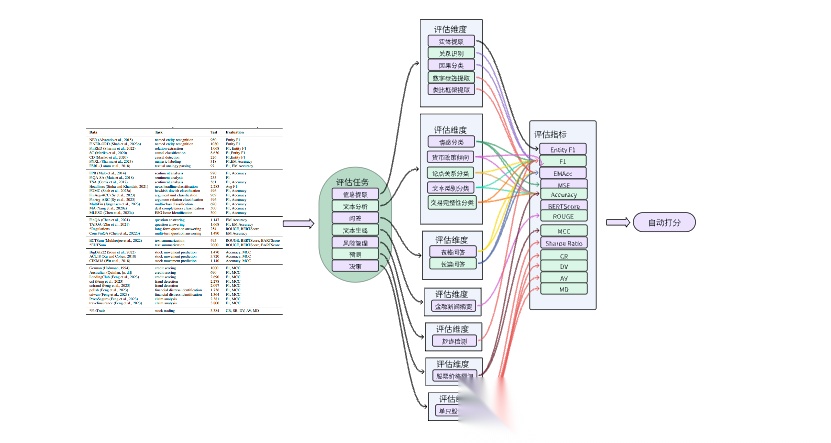
FinanceBench (Patronus AI公司,2023)
FinanceBench是首个专为开放式金融问答(Financial QA)而设计的评测基准。数据集包含 10 231 条“问题-答案-证据”三元组,覆盖 40 家美国上市公司、361 份公开财报(10-K、10-Q、8-K 及财报电话会纪要),问题贴近实际金融分析流程且设定为“最低可接受表现”门槛。其中用于评估的样本150个。
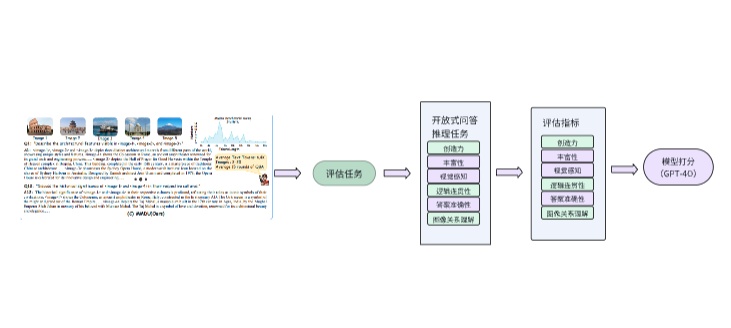
在FinanceBench这个benchmark里,评估任务为开放式问答,包括信息提取,逻辑推理,数值推理等维度;评估指标为Correct Answer(正确回答),Incorrect Answer(错误回答),Failure to Answer(拒绝回答),均为主观评价指标。
FinBen(FinAI研究团队、武汉大学等, 2024)(备注,选这个benchmark用来做数据集构造分析)
FinBen是首个全面的开源金融领域大型语言模型(LLMs)评估基准,包含 36 个数据集,覆盖 24 个金融任务,涉及七个关键维度:信息提取(IE)、文本分析(TA)、问答(QA)、文本生成(TG)、风险管理(RM)、预测(FO)和决策(DM)。FinBen 的创新包括更广泛的任务和数据集覆盖、首次评估股票交易、引入代理(Agent)和检索增强生成(RAG)评估策略,以及三个新的开源数据集(用于文本摘要、问答和股票交易)。
在FinBen这个benchmark里,评估维度先行,不同的评估维度里设计不同的评估任务。
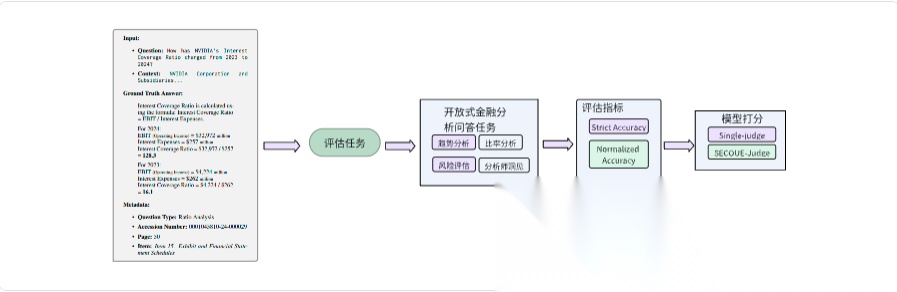
SECQUE (Microsoft Industry AI,2025)
SECQUE是一个专门用于评估大语言模型(LLMs)在金融分析任务中实际能力的基准测试。该基准包含 565 个由金融专家编写的问题,通过真实财务报告(如 10-K 和 10-Q)构建上下文,强调长文本理解和复杂推理能力。
SECQUE的评估任务分为四类,模拟金融分析师的实际工作场景:风险问题(Risk Questions),比率问题(Ratio Questions),比较问题(Comparison Questions),分析师见解(Analyst Insights),另外,SECQUE还设计了对齐任务,用来评估模型打分和人类评分的一致性。
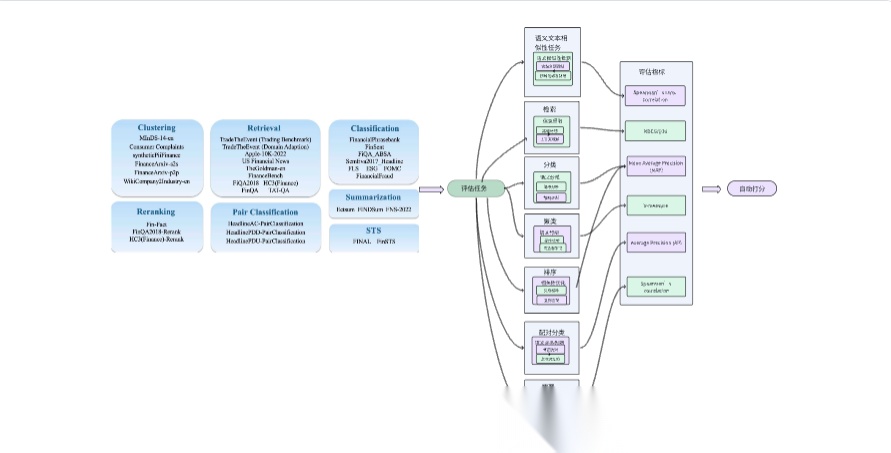
FinMTEB (香港科技大学 (HKUST),2025)
FinMTEB是专为金融领域设计的嵌入模型评估基准,包含64个中英文金融领域数据集。这些数据集涉及金融新闻、年报、ESG报告、监管文件和财报电话会议记录等多种文本类型,旨在评估嵌入模型在金融领域的表现。
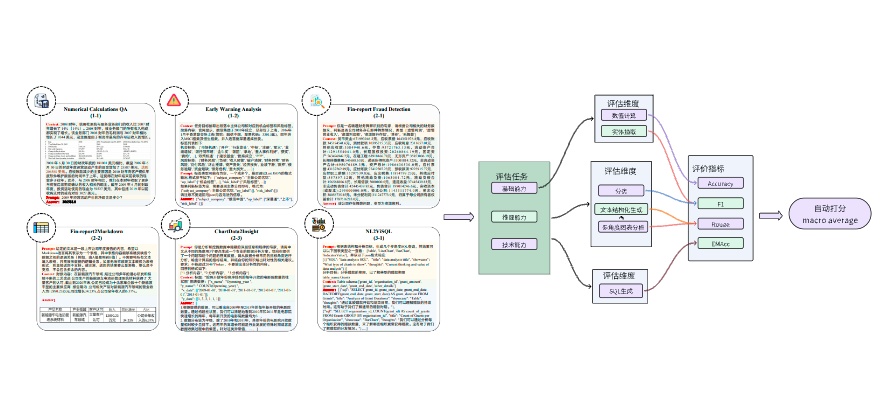
FinDABench (华东师范大学等,2025)
FinDABench 是首个专为评估大语言模型(LLMs)在金融数据分析能力方面设计的综合基准,包含6个子任务,覆盖三个维度:基础能力(Foundational Ability)、推理能力(Reasoning Ability)和技术能力(Technical Skill)。
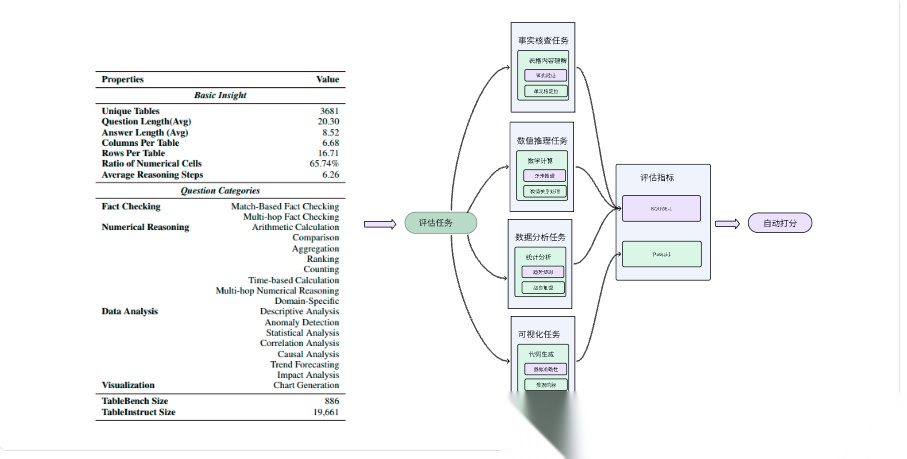
TableBench(The Fin AI、武汉大学等,2025)
TableBench是一种全面且复杂的表格问答基准,包含886个样本,覆盖4大类(事实核查、数值推理、数据分析、可视化)和18个子类别,旨在评估大型语言模型(LLM)在处理现实世界表格数据时的推理能力。
法律问答场景中的评估体系的构建
用3个法律相关的benchmark来研究在法律问答场景里的评估任务和评估指标
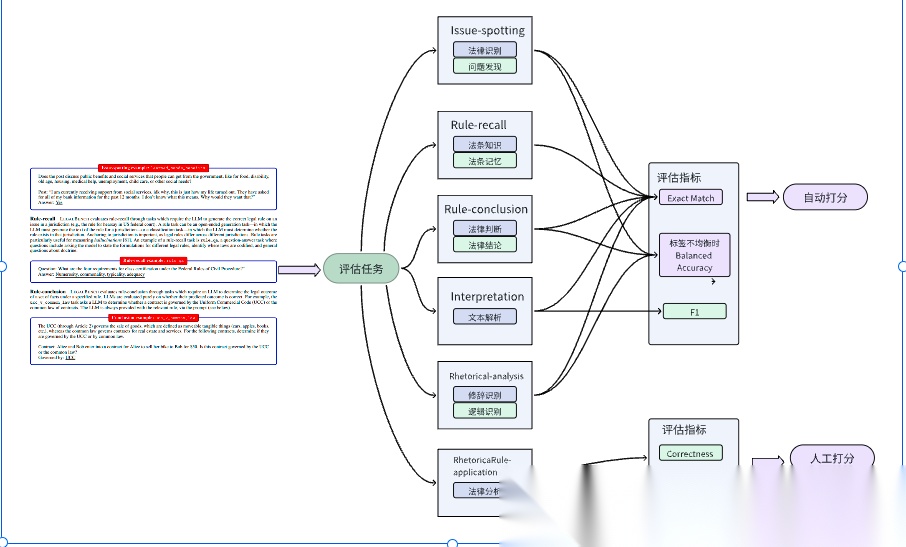
LegalBench (Stanford University等,2023)
LegalBench 是一个由法律与计算机科学领域专家协作构建的法律推理评测基准,涉及 6 类法律推理类型(如 issue-spotting、rule-recall、rule-application 等),涵盖了 162 项子任务,展示了 LLM 在法律推理方面的性能异质性,不同模型和不同推理任务的表现差异显著。
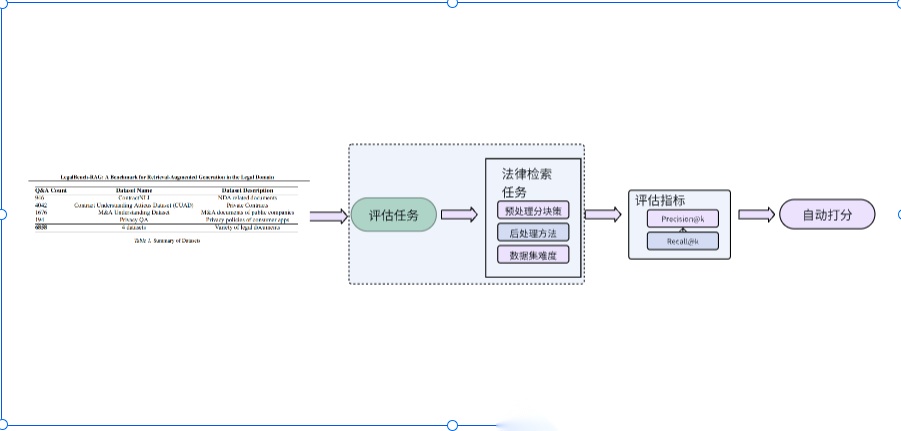
LegalBench-RAG (Nicholas Pipitone等,2024)
LegalBench-RAG是首个专门为评估法律领域中检索增强生成(Retrieval-Augmented Generation, RAG)系统中检索步骤的基准数据集。LegalBench-RAG 旨在解决现有基准(如 LegalBench)无法评估 RAG 系统检索能力的不足,强调从法律文档中精准提取高度相关的短文本片段,而非返回整个文档或大段不精确的内容。
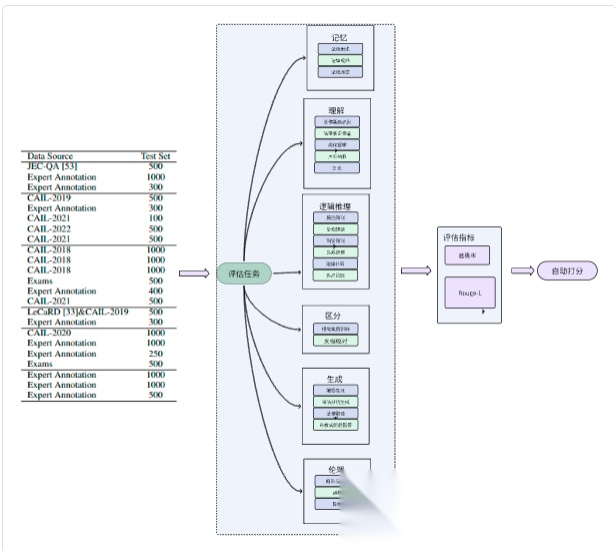
LexEval (清华大学,2024)
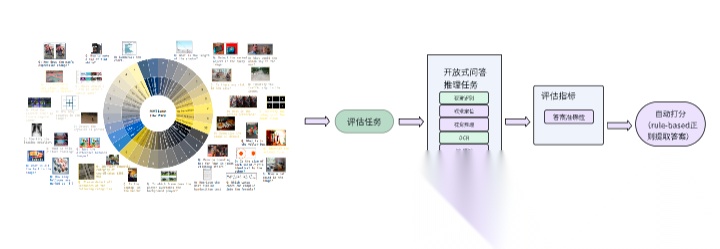
LexEval 是目前最大的中文法律基准数据集,LexEval 提出了一套面向 中文法律场景 的综合评测基准,按“法律认知能力六层级”——记忆、理解、逻辑推理、判别、生成、伦理——组织 23 个任务、14 150 道题。数据来自公开数据集、司法考试真题及 18 位法律专家新标注,统一格式后可零/少样本直接评估 LLM。
多模态场景中的评估任务和评估指标设计
用4个benchmark来研究大模型在多模态场景里的评估任务和评估指标
MMMU(俄亥俄州立大学等,2024)
MMMU,一个大规模多学科多模态理解与推理基准数据集,旨在评估多模态模型在大学水平专家任务中的表现。
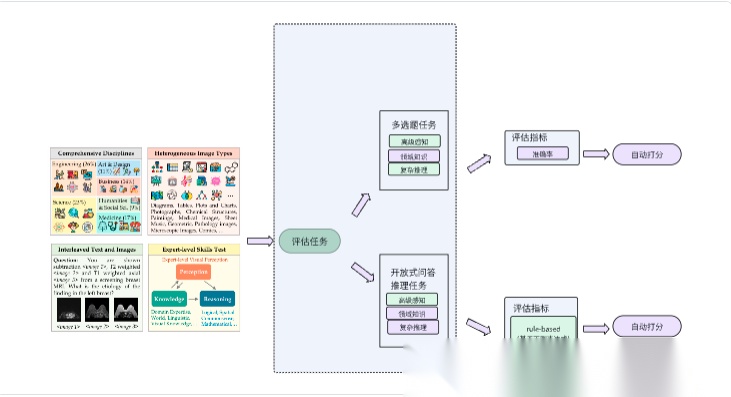
MMDU (上海人工智能实验室,2024)
MMDU,一个多轮多图像对话理解基准数据集,旨在评估和提升大型视觉-语言模型(LVLMs)在复杂多模态对话场景中的能力。
MMT-Bench(上海人工智能实验室,2024,垂直行业大模型评估)
MMT-Bench 是第一个全面评估 LVLMs 在多任务 AGI 中的多模态理解能力的基准,涵盖广泛的任务类型和图像类型。
M³CoT(浙江大学计算机学院,2024)
M³CoT是一个新的基准,用于评估Vision Large Language Models(VLLMs)在多领域、多步骤、多模态Chain-of-Thought(CoT)推理中的表现。它解决了现有基准测试的局限性,如缺乏视觉推理和单步骤推理。
MME-Unify (中国科学院自动化研究所,2025)
MME-Unify (MME-U)是第一个用于评估统一多模态大语言模型 (U-MLLMs) 的基准测试,涵盖理解、生成和混合模态任务。
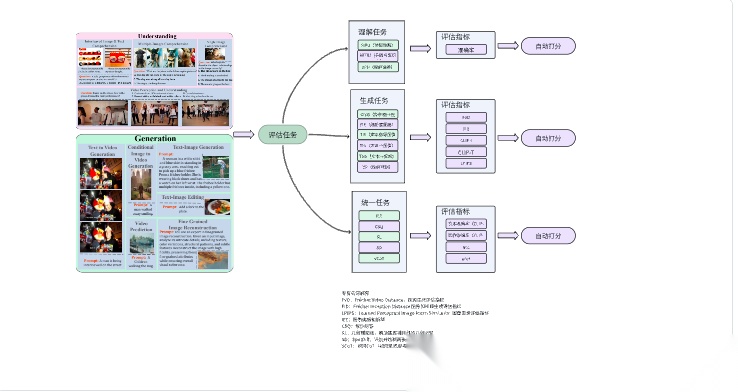
Agentic场景中的评估任务和评估指标设计
用3个benchmark来研究大模型在agentic场景里的评估任务和评估指标
AgentBench(清华大学,2023)
AgentBench 是一套包含 8 种不同交互环境(代码、游戏、网页)与 27 个主流 LLM(API 与开源)的综合评测基准,通过多轮、开放式生成任务来考察模型的推理能力、决策能力和指令****跟随能力。
AgentBench评估过程中没有用到React,Auto-Agent,Langchain等现成Agent框架,而是自定义了基于API&Docker Server–Client 的agent评估框架
GTA(上海交大,2024)
GTA (General Tool Agents) 基准测试,旨在解决现有大型语言模型 (LLM) 工具使用能力评估与真实世界场景之间存在的差距。

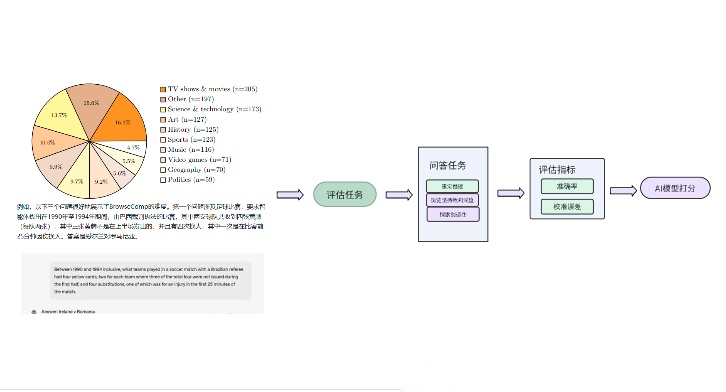
BrowseComp(OpenAI,2025)
BrowseComp是一个简单但具有挑战性的基准测试,用于评估AI代理的网络浏览能力。
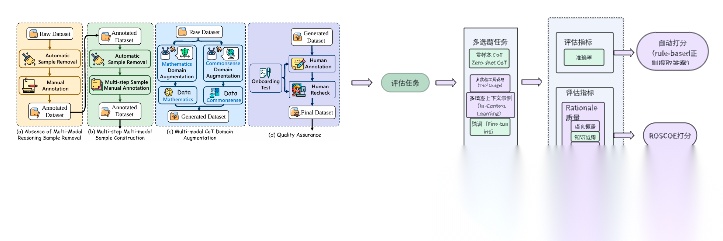
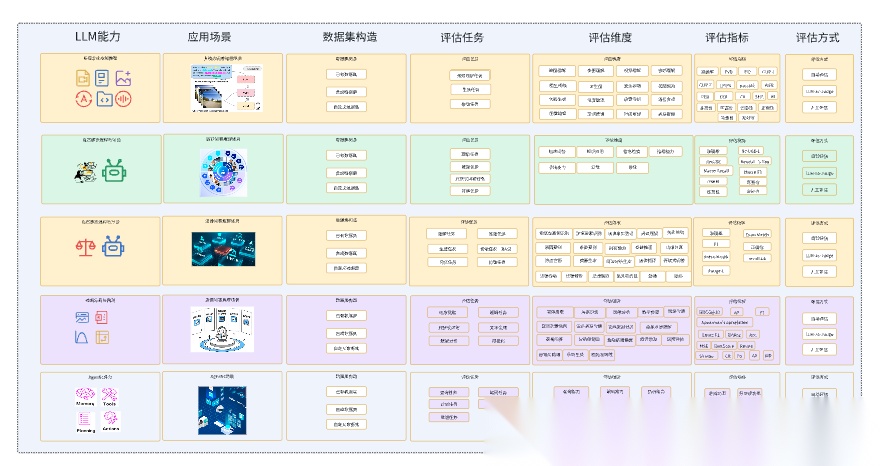
将上面五种场景中的评估指标和评估任务做个总结,可得下面的架构图
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 35
35 0
0- 0



 已为社区贡献235条内容
已为社区贡献235条内容

所有评论(0)