模型加速范式:蒸馏、剪枝、量化(上一个时代)
个人认为不管是Bert时期还是ChatGPT时期,模型加速从底层实现原理上大同小异,但实施Trick实际上是天上地下,毕竟一脉相承,还是值得去研究的,创新大概就是来源于这种一脉相承、系统性的理解,值得深究!!!
关于LLM量化加速的系统性简介:

个人认为不管是Bert时期还是ChatGPT时期,模型加速从底层实现原理上大同小异,但实施Trick实际上是天上地下,毕竟一脉相承,还是值得去研究的,创新大概就是来源于这种一脉相承、系统性的理解,值得深究!!!
深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、系统优化加速、异构计算等方法突破瓶颈,即分别在算法模型、计算图或算子优化以及硬件加速等层面采取必要的手段,模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署。
模型加速,主要有下面几种思路:
➤ Distillation(蒸馏):具体参考蒸馏原理技巧;
➤ Quantization(量化):将高精度模型用低精度来表示,使得模型更小;
➤ Pruning(剪枝):将模型中作用较小部分舍弃,而让模型更小。
➤ 结构优化:
◆ Matrix Decomposition(矩阵分解 ):将MN的矩阵分解为MK + K*N,只要让K<<M 且 K << N,就可以大大降低模型体积
◆ Low-rank Approximation(低秩近似):将权重矩阵变得更稀疏以减少计算和存储代价。
◆ Compact Network design(紧凑网络设计):调整网络结构
蒸馏:Distill
Distilling the Knowledge in a Neural Network
Ref:https://arxiv.org/pdf/1503.02531v1.pdf

蒸馏技术的基础出自2014年Hinton的paper,构建一个多任务的方案,让学生网络拟合教师网络的预测分布,同时教师网络学习逼近真实分布。为保证分布变得平缓,学生网络在推理过程中更有效,增加T参数,让学生网络学习更加充分。举一个例子,假设你是每次都是进行负重登山,虽然过程很辛苦,但是当有一天你取下负重,正常的登山的时候,你就会变得非常轻松,可以比别人登得高登得远。
Hinton 在论文中提出方法很简单,就是让学生模型的预测分布,来拟合老师模型(可以是集成模型)的预测分布。迁移过程是Student在进行training 时,除了学习ground truth 外,还需要学习label的probability(softmax output),但是不是直接学习 softmax output,而是学习soften labels,所谓soften labels 即经过Temperature 平滑后的 probability:
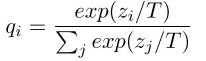
其中:T 为 temperature,z 是 logits。注:
(1)、T参数为了对应蒸馏的温度概念,在论文中叫的是Temperature,也就是蒸馏的温度。T越高对应的分布概率越平缓;
(2)、soft target,soft就是对应的带有T的目标,是要尽量地接近于大网络加入T后的分布概率;
(3)、hard target,hard就是正常网络训练的目标,是要尽量的完成正确的分类;
(4)、两个目标函数也就是对应的上面的soft target和hard target。这个体现在Student Network会有两个loss,分别对应上面两个问题求得的交叉熵,作为小网络训练的loss function;
CrossEntropy(si, ti)
实际使用中,因为各个框架中交叉熵损失函数大多针对 hard-label,也就是一般 one-hot 标签,而针对软标签,只能自己手写未优化交叉熵。或者像大多实现用 KLD(Kullback-Leibler divergence, KL散度) Loss 来等价实现,比如 pytorch 中。
loss =nn.KLDivLoss(F.log_softmax(s_logits/temperature),F.softmax(t_logits/temperature))loss = loss * (temperature)**2
注意:至于之后再乘上 temperature 平方,是为了保持梯度量级的不变。
直接 MSE 简单粗暴的来拟合分布。
获得了拟合老师分布的损失后,还会加上实际标注数据的交叉熵损失,然后在训练过程中控制两者比例,从而使最后结果表现更好。一般刚开始设置拟合损失权重大,而在快结束时则是标注损失权重大一些。
上述过程可表示成:
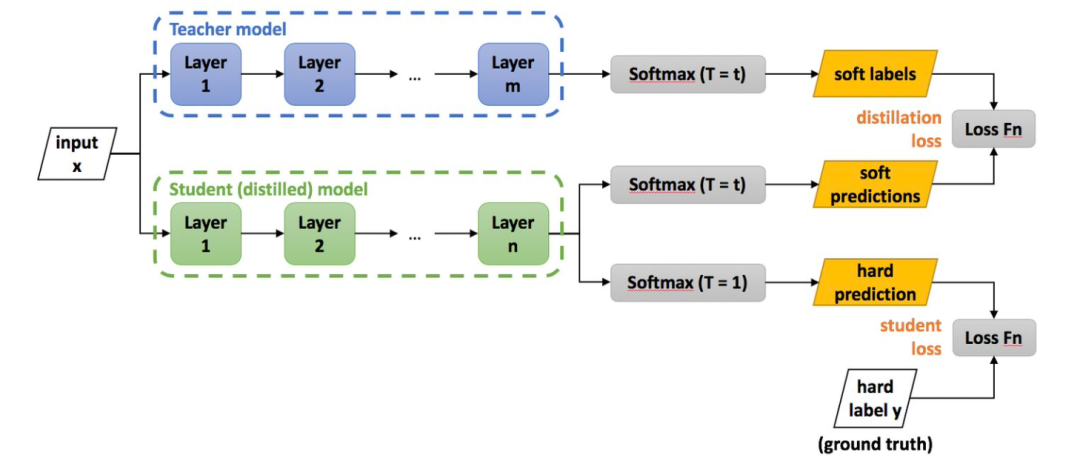
当然除了上述方法,还用了些其他技巧,比如用老师模型参数初始化学生模型,其实蒸馏过程并不需要一定按照 Hinton 最初论文里一样只对最后输出进行拟合,只要能让学生模型从老师模型中学习到东西就行。
剪枝:Pruning
模型剪枝(Model Pruning)是利用自定义的规则或者排序方法等将需要剪枝的层中的神经元的权重置零,对深度神经网络的稠密连接引入稀疏性。
剪枝则只是对原模型进行修剪,保留原模型。
关于剪枝,具体做法就是将模型中权重设为0,而根据所操作规模,可分为三个级别:
1. 对权重连接,其实就是权重矩阵中某个位置;
2. 对神经元,相当权重矩阵中某一行或一列;
3. 对整个权重矩阵
- 权重连接剪枝
常用的技巧就是 weight pruning,其中一个简单的做法是直接根据权重大小来剪枝,简单的将接近 0 小于某个阈值的权重连接都设为 0,这里的思想是认为该连接在网络中重要性不大。因此通过该剪枝法来处理后矩阵中会出现很多0, 会涉及模型使用稀疏矩阵加速。
关于稀疏矩阵参考:
-
Generative Modeling with Sparse Transformers
-
Sparse Networks from Scratch: Faster Training without Losing Performance
- 神经元剪枝
人为设置一个标准来对每个神经元进行打分,之后根据这个标准,将分比较低的神经元给去掉,反应在矩阵上的表现就是去掉某一行或某一列。但其直接改变了形状,也会在一定程度上影响并行运算的效率。
- 权重矩阵剪枝
相关BERT论文中验证了 Transformer 中注意力头的冗余性,根据一个打分标准(proxy importance score,模型对该参数的敏感程度)依次去掉不重要的头,同样是一种有效的方法。
非结构化剪枝:是指修剪参数的单个元素,比如全连接层中的单个权重、卷积层中的单个卷积核参数元素或者自定义层中的浮点数(scaling floats)。其重点在于,剪枝权重对象是随机的,没有特定结构,因此被称为非结构化剪枝。
结构化剪枝:如丢弃整行或整列的权重,或者在卷积层中丢弃整个过滤器。
结构化剪枝和非结构化剪枝的主要区别在于剪枝权重的粒度。如下图所示,结构化剪枝的粒度较大,主要是在卷积核的channel和Filter维度进行裁剪,而非结构化剪枝主要是对单个权重进行裁剪。非结构化剪枝能够实现更高的压缩率,同时保持较高的模型性能。然而其稀疏结构对于硬件并不友好,实际加速效果并不明显,而结构化剪枝恰恰相反。
静态剪枝方法:是根据整个训练集训练后的结果,评估权重的重要程度,「永久性」裁剪掉重要程度小的权重参数。
动态剪枝方法:则是「保留」所有的权重参数,根据每次输入的数据不同衡量权重参数的重要程度,将不重要权重参数忽略计算,从而实现动态剪枝。
局部剪枝:对模型内的部分模块的部分参数进行剪枝
全局剪枝:对整个模型进行剪枝
自定义剪枝:可以自定义一个子类,用来实现具体的剪枝逻辑,比如对权重矩阵进行间隔性的剪枝
推荐阅读:
☂. Pruning Filter in Filter.
Abstract: 文章提出了一种 SWP (Stripe-Wise Pruning)的方法,将维度为C * K * K的卷积核分成K * K个 1 * 1 * C的卷积核,以1 * 1 * C为单位对卷积核进行裁剪。其中,引入可学习的参数“Filter skeleton”表示裁剪后卷积核的shape。实验结果表明,SWP剪枝方法比之前Filter剪枝方法更加有效,并且在CIFAR-10和ImageNet数据集上达到SOTA效果。
☂. Pruning neural networks without any data byiteratively conserving synaptic flow.
Abstract: 针对基于梯度的修剪算法在初始化时会出现层塌,整个层的过早修剪使网络不可训练,文章提出一种新的数据不确定算法迭代突触流剪枝(SynFlow),它满足最大临界压缩,并实证证明该算法在12个不同的模型和数据集组合上实现了最先进的剪枝性能。
☂. Greedy Optimization Provably Wins the Lottery: Logarithmic Number of Winning Tickets is Enough.
Abstract: 针对:允许模型性能减少某一程度下,到底能够剪枝掉多少参数的问题,文章提出一种基于剪枝算法的贪心优化方法。
☂. HYDRA: Pruning Adversarially Robust Neural Networks.
Abstract: 在安全要求苛刻和计算资源受限的场景下,深度学习面临缺少对抗攻击的鲁棒性和模型庞大的参数等挑战。文章让模型剪枝考虑对抗训练的因素,以及让对抗训练目标指导哪些参数应该进行裁剪。他们将模型剪枝看成一个经验风险最小化问题,并提出一种叫做HYDRA的方法,使得被压缩网络能够同时达到benign和robust精度的SOTA效果。
Ref: https://zhuanlan.zhihu.com/p/402296513
☂. Logarithmic Pruning is All You Need.
☂. Sanity-Checking Pruning Methods: Random Tickets can Win the Jackpot.
Abstract: 网络层的连接数或者压缩率才是真正影响模型性能的因素。
☂. Scientific Control for Reliable Neural Network Pruning.
Abstract: 提出一种可靠的神经网络剪枝算法。
☂. Neuron-level StructuredPruning using Polarization Regularizer.
Abstract: 在network slimming的工作中,利用L1正则化技术让BN层的scale系数趋近于0,然后裁剪“不重要”的channel。然而,这篇文章认为这种做法存在一定问题。L1正则化技术会让所有的scale系数都趋近于0,更理想的做法应该是只减小“不重要”channel的scale系数,保持其他系数的仍处于较大状态。文章提出了polarization正则化技术,使scale系数两极化。
☂. Directional Pruning of Deep Neural Networks.
Abstract: 利用SGD进行网络优化时,容易使网络损失函数陷入“平坦的山谷”,导致网络优化困难。然而,这一特性可以被当作方向剪枝的理论基础。当网络参数处于“平坦的山谷”中,其梯度趋近于0和二阶梯度存在不少0值。对于这类型参数进行裁剪,其对于training loss的影响微乎其微。文提出一种新颖的方向剪枝方法 (gRDA),其不需要retraining和设置先验稀疏度。同时为了减少计算量,其使用tuned l1 proximal gradient算法实现方向剪枝。
☂. Storage Efficient and Dynamic Flexible Runtime Channel Pruning via Deep Reinforcement Learning.
Abstract: 文章利用深度强化学习技术,搜索最优的剪枝方案(即剪多少权重和剪哪些权重),实现自动化剪枝。不同于传统的static pruning,该文章主要依据采用dynamic pruning,根据输入数据的不同,对不同的权重进行剪枝。
☂. Movement Pruning: Adaptive Sparsity by Fine-Tuning.
Abstract: 文章提出了新的剪枝算法movement pruning,针对BERT等预训练模型进行剪枝。相比关注权重的L1范数,movement pruning剪枝方法更关注训练过程中逐渐远离“0”值的权重。
剪枝实现
pytorch要求为1.4.0以上版本,torch.nn.utils.prune中已经支持:
- RandomUnstructured
- L1Unstructured
- RandomStructured
- LnStructured
- CustomFromMask
论文:transformers.zip: Compressing Transformers with Pruning and Quantization
Code:
https://github.com/robeld/ERNIE
https://github.com/pytorch/pytorch/blob/main/torch/nn/utils/prune.py
推荐阅读:
https://www.cnblogs.com/yanshw/p/16592678.html
https://blog.csdn.net/qunsorber/article/details/128605174
https://blog.csdn.net/xue_csdn/article/details/105220985
量化:Quantization
量化的实际应用中,涉及各种不同的分类:比如说真量化(Real Quantization)与伪量化( Pseudo Quantization),训练后量化(Post Training Quantization)与训练中量化(During Training Quantization),最近 pytorch 1.3 文档中还有,动态量化(Dynamic Quantization)与静态量化(Static Quantization)。
真量化,即将模型中参数表示用低精度来表示。比较常用的方法就是直接通过:Q(x, scale, zero_point) = round(x/scale + zero_point)。来将高精度(比如说32位)矩阵转换成低精度(比如说8位),之后矩阵运算使用低精度,而结果则用 scale 和 zero_point 这两个参数来还原高精度结果。还可以更进一步,不光矩阵运算,整个模型中的运算都用低精度(比如激活函数)。
伪量化,实际的运算过程和一般情况下相同,其增加的操作就是将模型用低精度表示存储,然后实际运算中查表近似还原的操作。
量化中运用很广泛的一个算法 k-means quantization。具体做法是,先拿到模型完整表示的矩阵权重 W,之后用 k-means 算法将里面参数聚成 N 个簇。然后将 W 根据聚成的簇,转化成 1 到 N 的整数,每个分别指向各个簇中心点。这样就能将 32 位降到只有 log(N)位,大大减小了存储空间。而使用时只需要按照对应的 N 查表还原就行。因为实际运算用的还是完整精度,因此也被称为伪量化。
训练后量化与训练中量化:
训练后量化,其实大概就类似上面说的 k-means quantization 过程。
训练中量化,一般会用一个算法 quantization-aware training。大概过程是:①、量化权重;②、通过这个量化的网络计算损失;③、对没量化权重计算梯度;④、然后更新未量化权重
训练结束后,量化权重用量化后的模型直接进行预测,类似于混合精度训练。
论文:Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
code:
*Tensorflo**w:*https://www.tensorflow.org/lite/performance/post_training_quantization
*Pytorch:*https://pytorch.org/docs/master/quantization.html
经典Paper推荐
论文:
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
Paper: https://arxiv.org/abs/1903.12136
Github: https://github.com/km1994/nlp_paper_study
作者延续Hinton 的思路在BERT 上做实验,首先用BERT-12 做Teacher,然后用一个单层Bi-LSTM 做Student,loss 上除了ground truth 外,也选择了使用teacher 的logits,包括Temperature 平滑后的soften labels 的CrossEntropy和 logits 之间的MSE,最后实验****验
证MSE效果优于CE。

从头开始训练Student,所以只用任务相关数据会严重样本不足,作者提出了三种NLP的任务无关的data augment策略:
\1. mask:随机mask一部分token作为新样本,让teacher去生成对应logits ;
\2. 根据POS标签去替换,得到 ”What do pigs eat?" -> " How do pigs ear?"
\3. n-gram采样:随机选取n-gram,n取[1-5],丢弃其余部分,以一定的概率,用n-gram来取代原始的句子。n的取值范围是[1,5]。这个操作相当于dropout,是升级版的Masking
论文:
EMNLP2019.TinyBERT: Distilling BERT for Natural Language Understanding
Paper: https://www.aclweb.org/anthology/2020.findings-emnlp.372.pdf
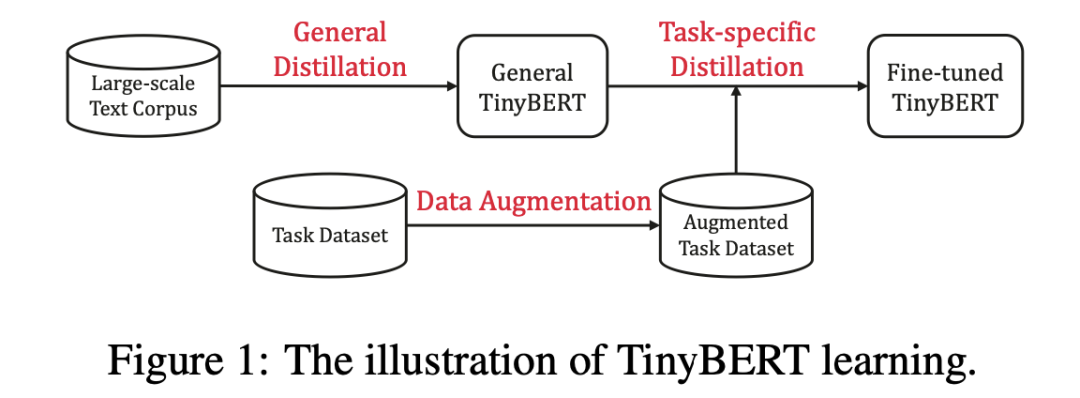
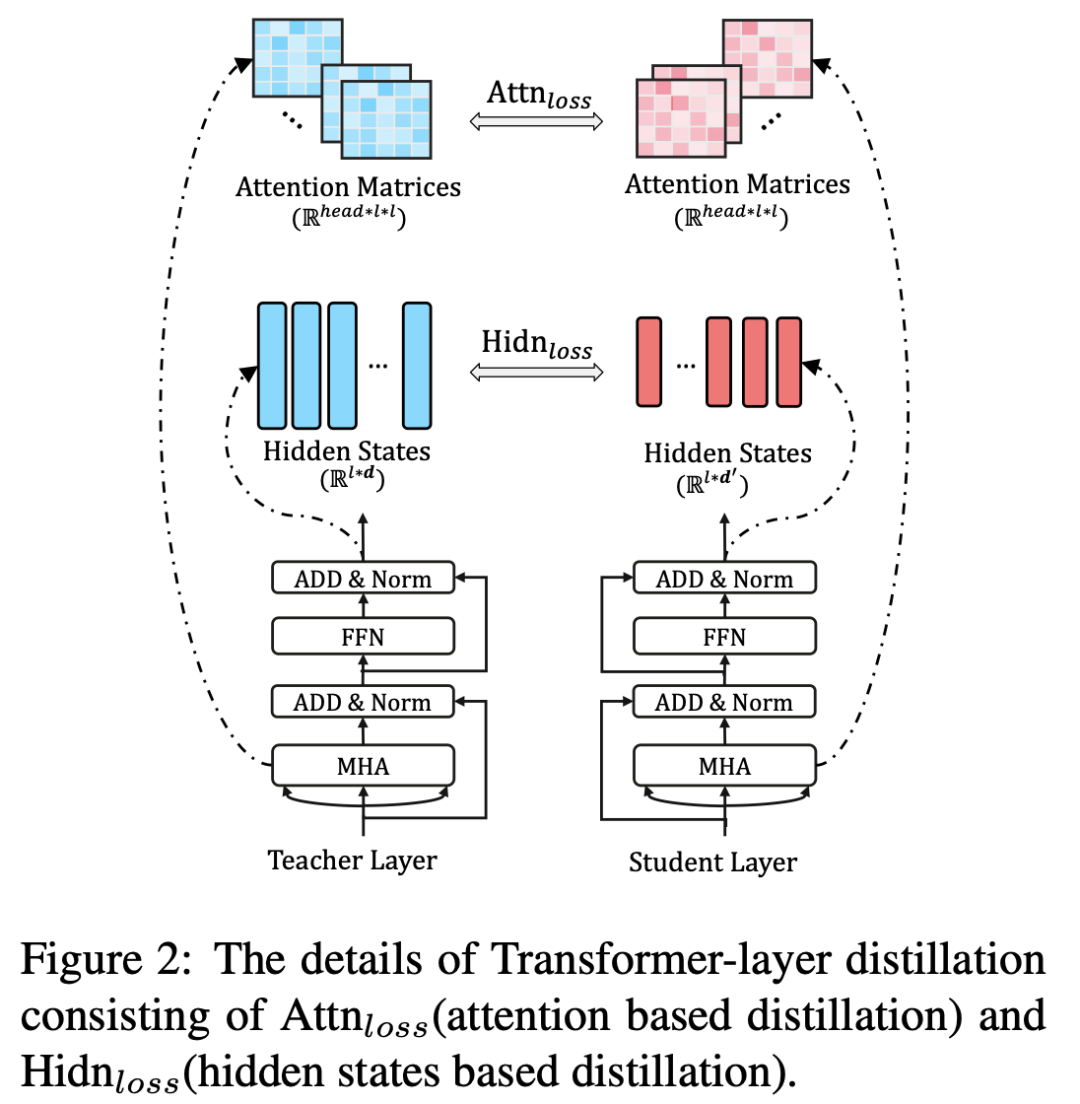
Paper技术点:
\1. Student选择一个更窄更浅的transformer;
\2. 将KD也分为两个阶段:pre-train 和 fine-tuning,并且在两个阶段上都进行KD;
\3. 使用了更多的loss:Embedding之间的MSE,Attention Matrix中的logits之间的MSE,Hidden state之间的MSE以及最后的分类层的CE;
\4. 为了提高下游任务fine-tuning后的性能,使用了近义词替换的策略进行数据增强。
优点:
\1. 6层transformer基本达到了bert-12的性能,并且hidden size更小,实际是比bert-6更小的;
\2. 因为有pre-train KD,所以可以拿来当bert 一样直接在下游fine-tuning。
缺点:
\1. 由于hidden size的不同,所以为了进行MSE,需要用一个参数矩阵W 来调节,这个参数只在训练时使用,训练完后丢弃,这个矩阵没有任何约束,觉得不优雅;
\2. 其次,student model的每一层都需要去学习teacher model的对应的block的输出,如何对不同的层如何设计更好的权重也是一个费力的事;
\3. 虽然student的结构也是transformer,但是由于hidden size 不同,没法使用teacher的预训练结果,但是我觉得这里其实可以用降维的方式用teacher的预训练结果,可能不需要pretraining的阶段了也说不定。
论文:
ACL2020.MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Paper: https://www.aclweb.org/anthology/2020.acl-main.195.pdf
作者同样采用一个transformer 作为基本结构,但作者认为深度很重要,宽度较小对模型损坏较小,所以整体架构是保持模型深度不变,通过一个矩阵来改变feature size,即bottleneck,再通过在block的前后插入两个bottleneck,来scale feature size。
由于MobileBERT太窄太深,所以不好训练,作者提出新的方式,通过一个同深但是更宽的同架构的模型来训练 作为teacher,然后用MobileBERT迁移。
loss 设计上主要包括三部分:feature map之间的MSE,Attention logits之间的KL,以及pre-training MLM + pre-training-NSP + pre-training-KD
训练策略上,有三种方式:
\1. 将KD作为附加预训练的附加任务,即一起训练;
\2. 分层训练,每次训练一层,同时冻结之前的层;
\3. 分开训练,首先训练迁移,然后单独进行pre-training。
此外,为了提高推理速度,将gelu 替换为更快的 relu ,LayerNormalization 替换为 更简单的NoNorm,也做了量化的实验。
优点:
\1. 首先mobileBERT容量更小,推理更快,与任务无关,可以当bert来直接在下游fine-tuning,而之前的KD大多数时候需要与任务绑定并使用数据增强,才能达到不错的性能;
\2. 论文实验非常详实,包括如何选择inter-block size, intra-block size, 不同训练策略如何影响等;
\3. 训练策略上,除了之前的一起训练完,实验了两种新的训练方式,而最终的一层一层的训练与skip connection 有异曲同工的作用:每层都学一小部分内容,从而降低学习的难度;
\4. 替换了gelu 和 LayerNormalization,进一步提速。
缺点:
\1. 要训练一个IBBERT作为teacher,而这个模型容量与BERT-Large差不多,增加了训练难度.
论文:
EMNLP2019.Patient Knowledge Distillation for BERT Model Compression
Paper: https://arxiv.org/abs/1908.09355
针对 Transformer 的蒸馏,首先是 BERT-PKD (Patient Knowledge Distillation) 模型,它最主要是在之前提到两个损失之上,再加上一个loss, LPT。
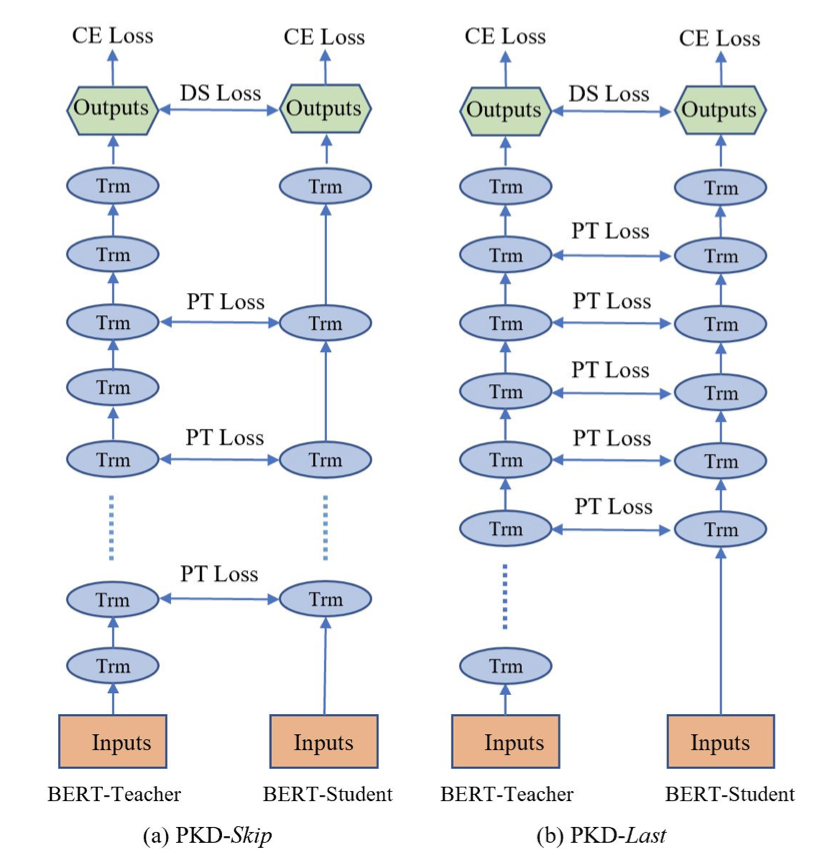
而这个 loss 是由老师和学生模型中间层的 [CLS] 符的隐状态算得,计算过程是先归一化,然后直接 MSE 求损失。之所以取 [CLS] 位置,是因为其在 BERT 分类任务中的重要性。
至于学生模型中间层如何与老师模型中间层对应,论文中发现最佳策略是直接按倍数取老师模型对应层就行,比如1对2,2对4这样.
剪枝的主要原因是提升推理速度,另外是希望去掉在个别case上过拟合的权重,提升模型泛化能力。
我认为剪枝的研究点主要在以下两方面:
1. 剪掉什么?
**weight pruning(WP):**指将矩阵中的某个权重连接置为0,处理完后通过稀疏矩阵进行运算,或者将某一行或一列置为0(神经元),仍用矩阵进行运算。
structured pruning(SP):SP则是对一组权重进行剪枝,比如去掉Attention heads、Attention mechanism、FFN层或者整个Transformer层。
2. 什么时候剪?
预训练、训练/精调、测试三个阶段
方案一:预测时剪掉Attention Heads
在一篇NIPS2019[3]中,作者等人主要研究了注意力头对结果的影响,评估的任务主要是encoder-decoder的NMT和BERT的MNLI。在预测阶段mask掉head进行研究后可以发现,在翻译任务中,只有8(/96)个头会对预测结果有显著影响,大多数头在预测时都是多余的。
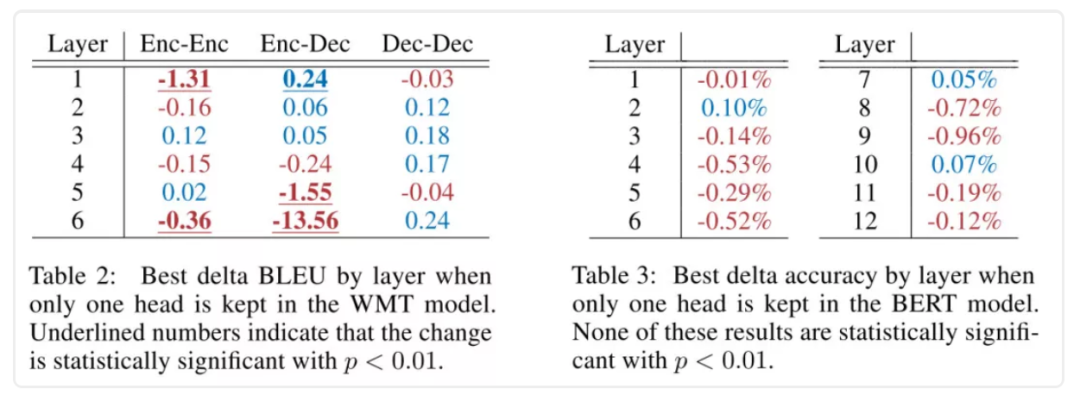
上图中,作者只保留了当前层中最好的一个head。可以看出BERT中大部分层在只有一个head的情况下,对结果的影响都不大。因此通过去掉head来压缩模型是可行的,虽然head在底层是并行计算的,在速度上可能提升不大,作者也提供了测试结果:在剪掉50%的BERT head情况下,是有一定比例的速度提升的。不过作者同时也证明了剪掉50%的head会有效果下降:
大概降了1-2个点的感觉。所以比起我们既想压缩模型,又想提升效果的目标还有一些距离。
方案二:训练时加入Dropout,预测时剪掉Layer
文章提出了类似Dropout的LayerDrop,在训练时随机mask掉一组权重,让模型适应这种“缺胳膊少腿”的情况,变得更加robust,然后在预测时直接去掉部分结构进行预测。评估的任务也非常多样,有NMT、摘要、语言模型和NLU。
剪枝之后的效果要好于蒸馏和同等量级的模型
另外,只将LayerDrop应用在训练过程中还有提升效果的奇效,而且能提升一定的训练速度:
看到LayerDrop这篇文章时觉得已经找到了心中最佳,后续有时间会撸一下代码,其他看了下但没有细读的论文有:
- [5] 按权重大小进行weight pruning
- [6] 类似方案二,在SQUAD2.0上进行实验
- [7] 提出了一种RPP的weight pruning方法
文章提出了 PruningNet 的概念,自动为剪枝后的模型生成权重,从而绕过了费时的 retrain 步骤,剪枝和 NAS 结合的方法**。**并且能够和进化算法等搜索方法结合,通过搜索编码 network 的 coding vector,自动地根据所给约束搜索剪枝后的网络结构。和 AutoML 技术相比,这种方法并不是从头搜索,而是从已有的大模型出发,从而缩小了搜索空间,节省了搜索算力和时间。
Motivation
模型剪枝是一种能够减少模型大小和计算量的方法。模型剪枝一般可以分为三个步骤:
- 训练一个参数量较多的大网络
- 将不重要的权重参数剪掉
- 剪枝后的小网络做 fine tune
其中第二步是模型剪枝中的关键,困扰模型剪枝落地的一个问题就是剪枝比例的确定。
传统的剪枝方法常常需要人工 layer by layer 地去确定每层的剪枝比例,然后进行 fine tune,用起来很耗时,而且很不方便。不过最近的 Rethinking the Value of Network Pruning 指出,剪枝后的权重并不重要,对于 channel pruning 来说,更重要的是找到剪枝后的网络结构,具体来说就是每层留下的 channel 数量。
受这个发现启发,文章提出可以用一个 PruningNet,对于给定的剪枝网络,自动生成 weight,无需进行 retrain,然后评测剪枝网络在验证集上的性能,从而选出最优的网络结构。
具体来说,PruningNet 的输入是剪枝后的网络结构,必须首先对网络结构进行编码,转换为 coding vector。这里可以直接用剪枝后网络每层的 channel 数来编码。在搜索剪枝网络的时候,我们可以尝试各种 coding vector,用 PruningNet 生成剪枝后的网络权重。网络结构和权重都有了,就可以去评测网络的性能。进而用进化算法搜索最优的 coding vector,也就是最优的剪枝结构。在用进化算法搜索的时候,可以使用自定义的目标函数,包括将网络的 accuracy,latency,FLOPS 等考虑进来。
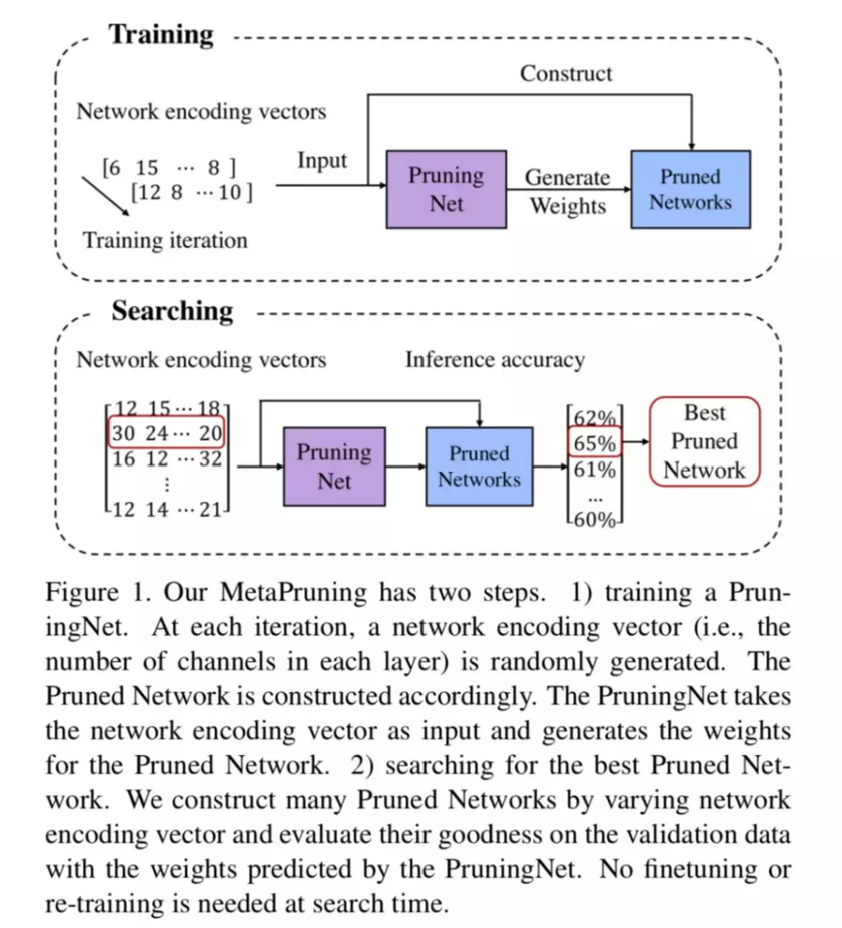
PruningNet
从上一小节已经可以知道,PruningNet 是整个算法的关键。那么怎么才能找到这样一个“神奇网络”呢?
先做一下符号约定,使用 ci 表示剪枝之后第 i 层的 channel 数量, l 为网络的层数, W 表示剪枝后网络的权重。那么 PruningNet 的输入输出如下所示:

- 训练
先结合下图看一下 forward 部分。PruningNet 是由 l 个 PruningBlock 组成的,每个 PruningBlock 是一个两层的 MLP。
首先看图 b,编码着网络结构信息的 coding vector 输入到当前 block 后,输出经过 Reshape,成了一个 Weight Matrix。注意哦,这里的 WeightMatrix 是固定大小的(也就是未剪枝的原始 Weight shape 大小),和剪枝网络结构无关。
再看图 a,因为要对网络进行剪枝,所以 WeightMatrix 要进行 Crop。对应到图 b,可以看到,Crop 是在两个维度上进行的。首先,由于上一层也进行了剪枝,所以 input channel 数变少了;其次,由于当前层进行了剪枝,所以 output channel 数变少了。这样经过 Crop,就生成了剪枝后的网络 weight。我们再输入一个 mini batch 的训练图片,就可以得到剪枝后的网络的 loss。
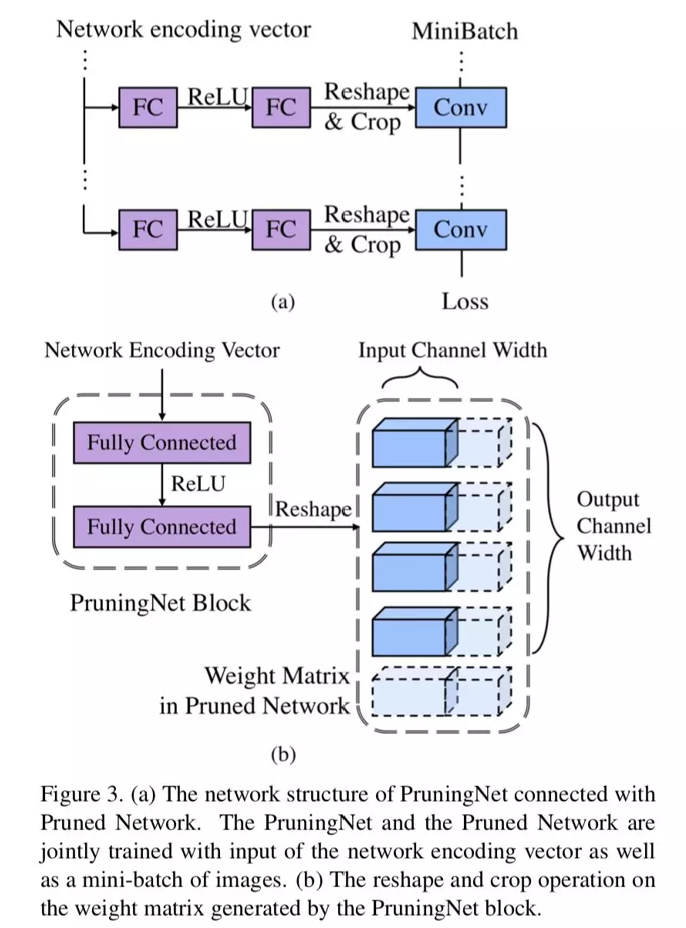
在 backward 部分,我们不更新剪枝后网络的权重,而是更新 PruningNet 的权重。由于上面的操作都是可微分的,所以直接用链式法则传过去就行。如果你使用 PyTorch 等支持自动微分的框架,这是很容易的。
下图所示是训练过程的整个 PruningNet(左侧)和剪枝后网络(右侧,即 PrunedNet)。训练过程中的 coding vector 在状态空间里随机采样,随机选取每层的 channel 数量。
PS:和原始论文相比,下图和上图顺序是颠倒的。这里从底向上介绍了 PruningNet 的训练,而论文则是自顶向下。
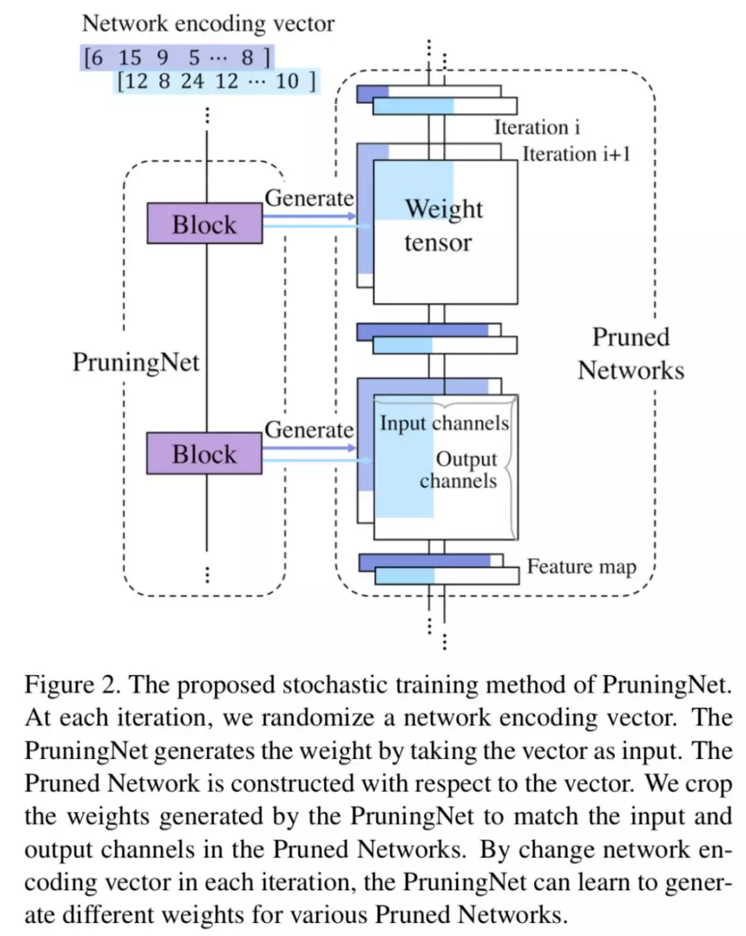
- 搜索
训练好 PruningNet 后,就可以用它来进行搜索了!我们只需要输入某个 coding vector,PruningNet 就会为我们生成对应每层的 WeightMatrix。别忘了 coding vector 是编码的网络结构,现在又有了 weight,我们就可以在验证集上测试网络的性能了。进而,可以使用进化算法等优化方法去搜索最优的 coding vector。当我们得到了最优结构的剪枝网络后,再 from scratch 地训练它。
进化算法这里不再赘述,很多优化的书中包括网上都有资料。这里把整个算法流程贴出来:

实验
作者在 ImageNet 上用 MobileNet 和 ResNet 进行了实验。训练 PruningNet 用了 1/4 的原模型的 epochs。数据增强使用常见的标准流程,输入 image 大小为 224×224。
将原始 ImageNet 的训练集做分割,每个类别选 50 张组成 sub-validation(共计 50000),其余作为 sub-training。在训练时,我们使用 sub-training 训练 PruningNet。在搜索时,使用 sub-validation 评估剪枝网络的性能。不过,还要注意,在搜索时,使用 20000 张 sub-training 中的图片重新计算 BatchNorm layer 中的 running mean 和 running variance。
shortcut 剪枝
在进行模型剪枝时,一个比较难处理的问题是 ResNet 中的 shortcut 结构。因为最后有一个 element-wise 的相加操作,必须保证两路 feature map 是严格 shape 相同的,所以不能随意剪枝,否则会造成 channel 不匹配。下面对几种论文中用到的网络结构分别讨论。
MobileNet-v1
MobileNet-v1 是没有 shortcut 结构的。我们为每个 conv layer 都配上相应的 PruningBlock——一个两层的 MLP。PruningNet 的输入 coding vector 中的元素是剪枝后每层的 channel 数量。而输入第 i 个 PruningBlock 的是一个 2D vector,由归一化的第 i-1 层和第 i 层的剪枝比例构成。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献188条内容
已为社区贡献188条内容

所有评论(0)