GPU服务器市场十问十答
3、国产CPU+国产AI芯片,个人认为CPU本身和AI芯片都是理论上兼容的,但是在国内通常会进行“组合”销售,比如HW的KP+ST,HG的CPU+DCU等,这是一个厂商同时具有CPU和AI芯片的情况的,但是的AI芯片品牌众多,很多AI芯片公司通常选择一到几家服务器厂商进行适配(基于Intel或者AMD的GPU机型),国产AI芯片厂商主动适配国产CPU平台的不多(除非客户指定,因为国产AI芯片本身出
前言,最近不少朋友找我咨询或者私信讨论,其中和GPU服务器产品相关的占大多数,智算产业发展带动了GPU服务器市场的繁荣,我把大家经常讨论的GPU服务器相关问题(或话题)简单做了梳理,筛选了其中我认为比较有代表性的十条通过十问十答的形式给大家做个分享,包括了GPU服务器的产品形态(品类)、品牌情况、应用场景、整机价格(主要机型)、市场规模、客户群体(Top行业)、整机功率、机柜部署(现状)、国产平台(发展情况)和液冷落地(现状)共10项,提前声明个人观点,水平有限仅供参考!

一、什么是GPU服务器,具体有哪些产品类型
“GPU服务器”顾名思义是为了支持更多GPU数量、适配更多GPU卡类型、满足各类GPU算力场景的服务器“产品”,核心参数就是“能装”多少张GPU卡,我们常见的有4U4卡、4U8卡、4U16卡、4U20卡、6U10卡等,我之前写过2篇公众号文章如下,详细介绍了GPU服务器支持的“卡数”由什么因素决定,大家若想进一步了解,可以点击下面链接查阅。
从GPU产品类型来说,市场主流出货机型有搭配HGX模组的高端训练机型(如H100 NVLink整机)、也有搭配RTX4090出货的4U8卡机型,每个厂商对GPU服务器的布局也有所差异,下图是我们公司(超云)结合AI大模型的规模以及训练&推理需求进行的GPU服务器产品形态分类,仅供大家参考,需要说明的是下图仅列举了部分型号,还有6U8卡(支持8卡四宽GPU)机型、4U16卡&20卡(支持单卡推理)机型、国产CPU平台的机型以及液冷+GPU的机型等并未列出。

二、GPU服务器的品牌情况
最近找我问GPU服务器品牌情况的朋友挺多,H系列整机和PCIe的八卡机对应的品牌也有区别,我们按照这两个主流机型进行展开。
1、H系列整机品牌:国外品牌最出名肯定是超微了,其次还有HP、Dell等,中国(台湾地区)品牌有技嘉、华硕等,中国大陆有浪潮、H3C、联想、宁畅、超聚变、超云等(OEM)品牌,经常听到的还有华勤(ODM为主),当然英伟达自己也推出自有品牌的DGX H100等,市场上见到的并不多。
2、PCIe机型的品牌:相比与H系列门槛比较低,产品形态也更多,品牌多到眼花缭乱,除了我们能叫得上名字的国内外大厂,新晋品牌靠着GPU市场火爆也营收不少(我思考再三,还是决定用公司首字母代替吧),除了上面提到的H系列整机品牌外,上了IDC 2024H的GPU服务器榜单的有AQ、KQ、BD、ZX、STHL等、还有很多在区域卖的也不错的比如深圳的ST、上海的PS等,还有太多品牌了,欢迎大家评论区补充。
三、GPU服务器的应用场景有哪些
既然GPU服务器卖的这么火爆,除了AI大模型的训练和推理会用到外,还能做什么呢?这也是一个朋友找我咨询的,下图是我个人整理的5个方面,智算中心采购大量的GPU服务器,除了可用于AI相关的场景外,还有HPC高性能计算、图形渲染、视频编解码和云游戏等。
英伟达GPU的特殊应用场景:显卡挖矿,这个领域比较敏感,我说多了不好(很多中大型的智算中心算力租赁明令禁止“挖矿”的行为,一旦发现就会采取限制措施,但很多小的所谓的“智算中心”与其4090机器闲置,不如“创造短期内”的价值,尤其是那些希望“短期回本”的大家懂的),据悉在曾经的一段时间内,英伟达业务不景气时是靠着众多“矿工&矿场”让英伟达坚持了下来。
四、GPU服务器的整机价格如何
GPU整机价格的波动是市场供需关系的直观“体现”,目前4090八卡机的单价大概在22-25w的范围,H100的整机价格大概在220-240w的范围,当然很多朋友会说你这个价格不准,其实影响价格的因素很多,我之前专门写过两篇公众号文章,从个人角度分析了H100和4090机型价格差距比较大的原因,大家如果想进一步了解,欢迎点击下面链接查看。
五、GPU服务器的市场规模情况如何
大家都看到了,GPU服务器需求的爆发给原本“已入冬”的服务器市场带来了新的增长点,毫不夸张的说某些“掌握核心科技”的国内服务器大厂,今年能够完成业绩目标一半以上的功劳要归于GPU机型业绩增长。
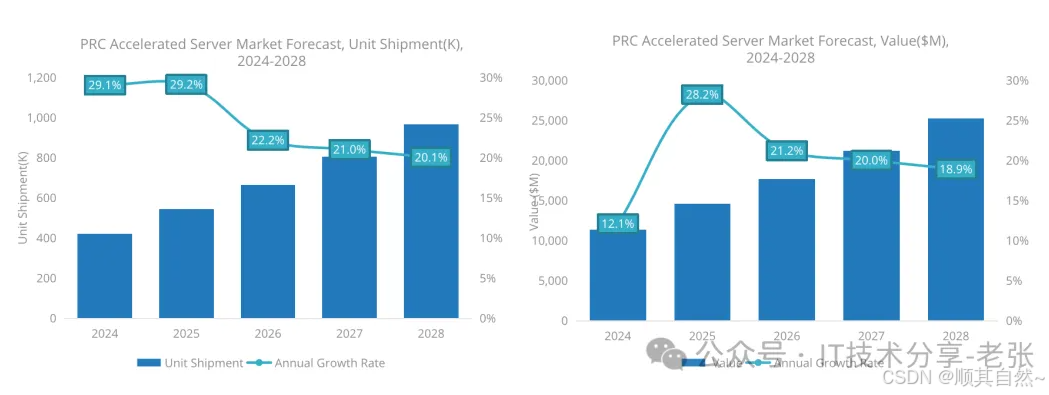
根据IDC上半年国内加速服务器市场报告内容,24年我国GPU类服务器市场规模出货量预计超40w台,市场规模预计超过100亿美元。预测和实际肯定是有出入的,仅供大家参考(下图源自IDC 2024H1报告的市场预测)。
六、GPU服务器的Top客户群体是哪些?
这个问题可以从两个维度来分析,一是智算中心建设维度的采购主体有哪些,二是从全行业的角度分析GPU服务器的重点行业是哪些。
1、按智算中心建设数量Top3的为地方政府、电信运营商和互联网&CSP,算力规模Top3的为互联网&CSP、电信运营商和地方政府。
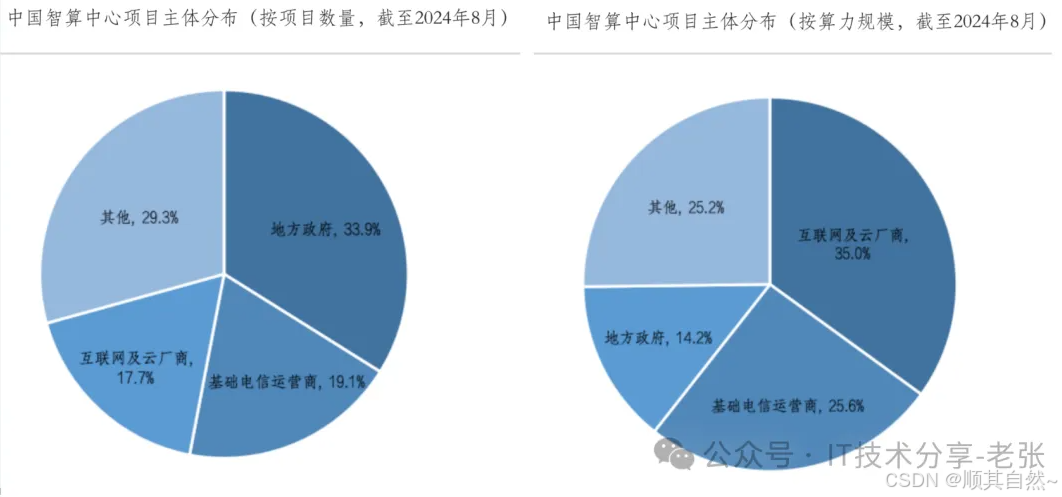
注:以上信息来自中国通信工业协会数据中心委员会发布的《中国智算中心产业发展白皮书(2024年)》
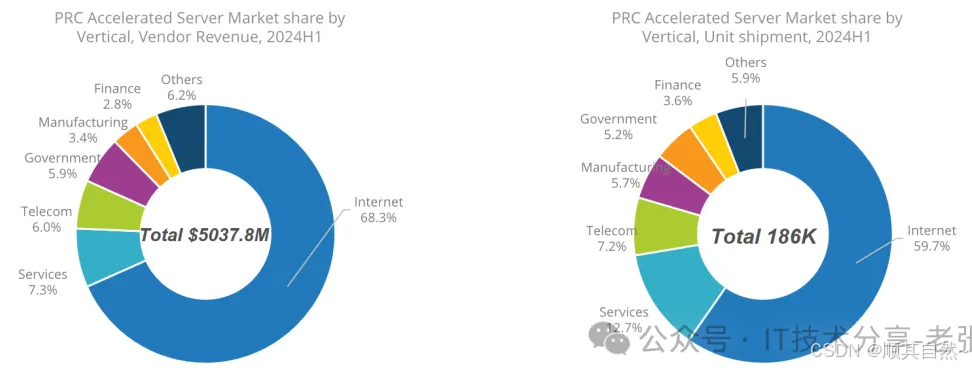
2、全行业的角度的GPU服务器采购分析,源引IDC 2024H1报告数据如下图,采购规模依次为:互联网、服务行业、电信、政府、制造和金融,从采购台数的角度为互联网、服务行业、电信、制造、政府和金融,仅供参考,服务行业我没太理解具体指是什么(欢迎大家评论区给我解答);仅互联网一个行业采购规模就高达近7成,这也是为什么头部厂商都要发力互联网的原因。
七、GPU服务器整机功率的情况
功率问题也是大家经常讨论的,我们选择几款主流GPU整机展开分析。
1、A100\H100\H200\B200整机功率情况,下面2张图都源引维谛科技和深知社发布的《智算中心基础设施演进白皮书》,我们可以看到,主流的H100仅八张GPU卡就有5.6kw,整机系统满配情况下约为10.2kw,而下一代的B200整机系统则有夸张的14.3kw(下面为理论最大功率,实际运营时可能要略低);
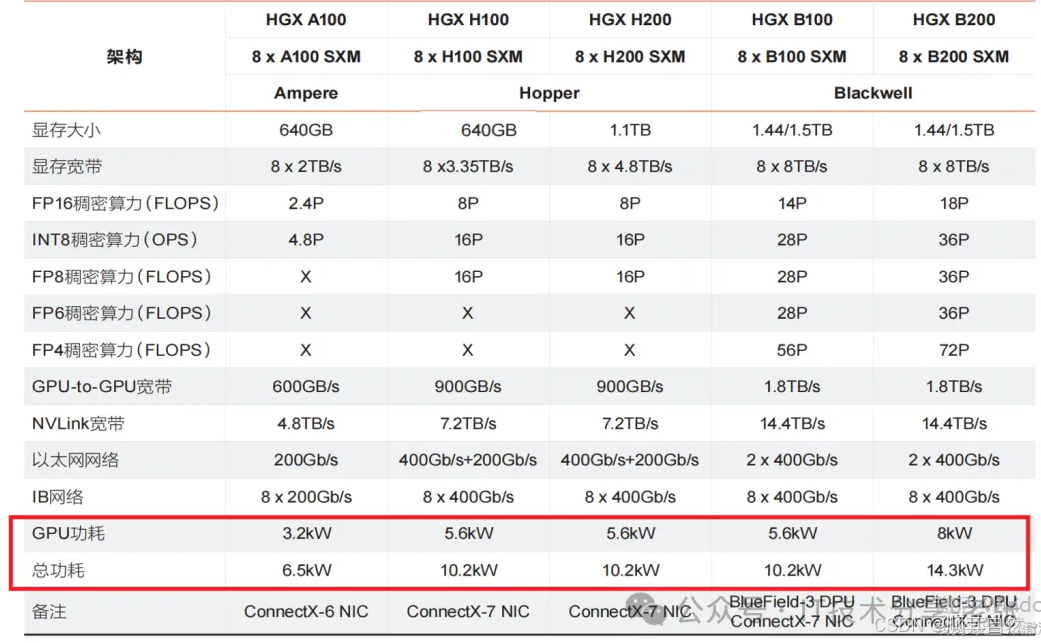
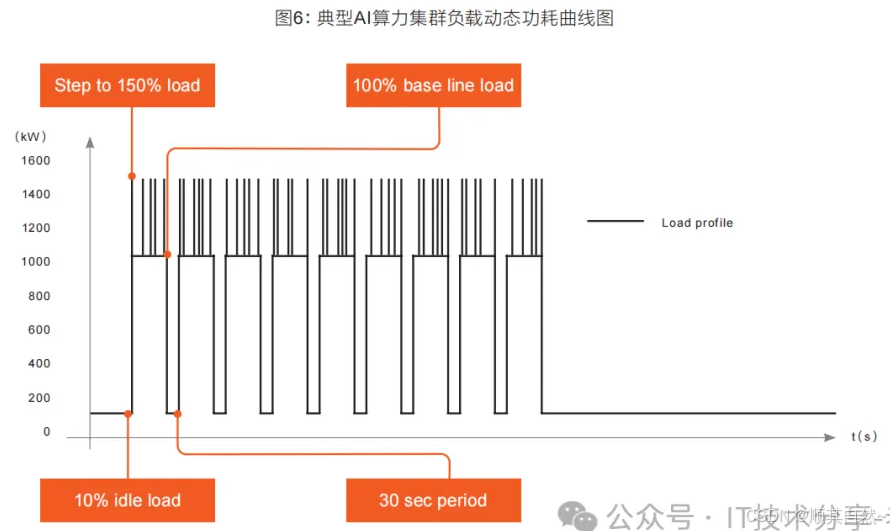
2、智算场景下GPU服务器“功率负载”的变化,AI大模型相关的负载运行特点是不断进行训练任务来进行高速运算,开始训练任务时,负载将会迅速上升到比较高的功耗值,甚至会到负载的极限值,周期的训练任务结束时负载又会迅速下降,降到最低值。总结为周期性、大幅度、并发性、瞬时冲击等,这种特性对于智算中心的配电和制冷都是一个很大的挑战。
1)周期性:智算负载呈现周期性波动,波动频率从分钟级到小时级不等;
2)大幅度:智算负载功耗波动幅度可能超过额定功耗的80%,即智算中心的负载功耗可能从10%快速突变至80%,甚至100%;
3)并发性:人工智能(AI)大模型具有并发运算的特点,故整体集群性总功耗呈现出动态快速变化;
4)瞬时冲击:某些算力模型可能出现400us~50ms左右的负载冲击,幅度可能达到额定负载功耗的150%,它取决于POD运算模型及软件算法;
八、GPU服务器的机柜部署情况
单柜内部署GPU服务器的数量需考虑的因素比较多,除电源功率外还需要考虑散热、承载、维护等,传统IDC机房单柜功率通常在4-8kw,如果部署H100整机单柜都放不下一台,据了解目前H100部署多为单柜单台,4090八卡机通常为1-2台;
举例1:以NV DGX H100举例,单台8U高,每机柜最大可部署4台,下图是英伟达官方的建议文档,可以判断单台机柜肯定要有40kw以上。

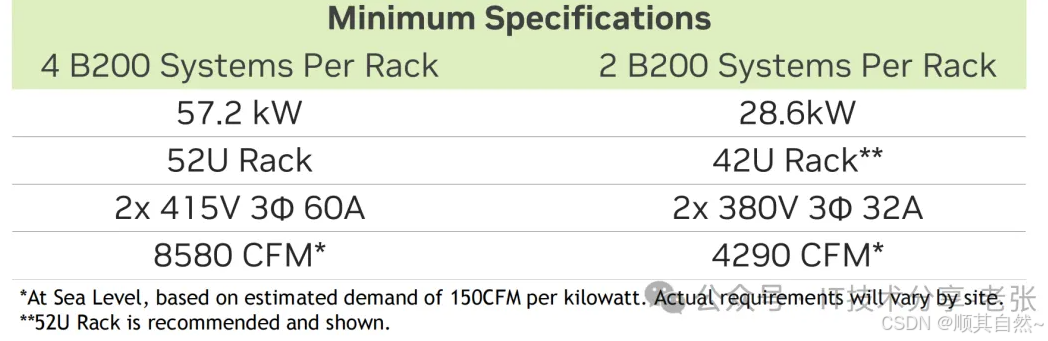
举例2:下一代NV DGX B200采用10U风冷设计,根据机柜功率不同可选择2/4台每机柜的方案,具体如下:

机柜功率的发展趋势如何呢?下图源引维谛公司的公开资料(供参考),可能很多朋友英文不太好,我翻译了一下。
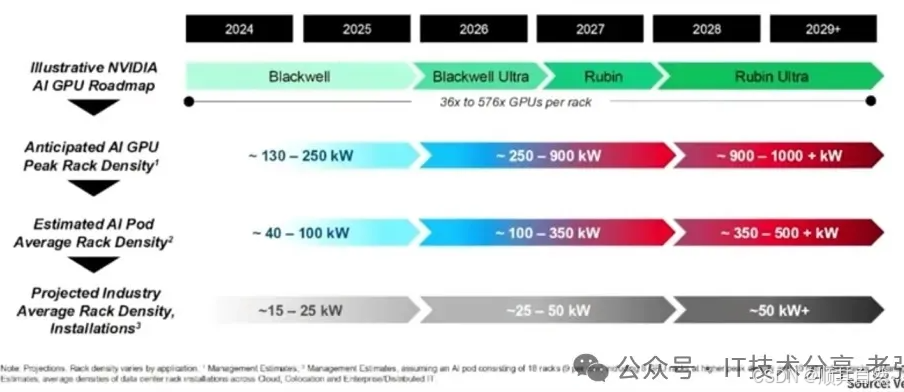
第一行:NV产品迭代,从目前发布的B200 Blackwell 到未来的Rubin架构。第二行:AI GPU算力单柜的峰值变化,到2029年预计将达到900-1000KW+ 第三行:AIPod资源池的平均机架密度,到2029年预计将达到350-500KW+ 第四行:整个IDC行业机架的平均功率密度,到2029年预计将达到50KW+。
九、国产平台的GPU服务器情况
说到GPU服务器我们通常默认就是Intel或者AMD平台了。但是随着我国信创产业持续发展,国产CPU的GPU整机需求越来越多,现在发展的怎么样了?从如下3个方面简单分析:
1、Intel&AMD平台适配国产AI芯片,目前来看已经没有问题了,各服务器厂商都对国产主流的AI芯片型号进行了适配(比较成熟不再展开)。
2、国产CPU+英伟达GPU,据悉目前市场比较成熟的有海光CPU+NV GPU,飞腾CPU+NV GPU(也有厂商能做了),下图是我们公司(超云)基于国产C86和ARM平台打造的训练和推理平台(主流NV卡都能适配);

3、国产CPU+国产AI芯片,个人认为CPU本身和AI芯片都是理论上兼容的,但是在国内通常会进行“组合”销售,比如HW的KP+ST,HG的CPU+DCU等,这是一个厂商同时具有CPU和AI芯片的情况的,但是的AI芯片品牌众多,很多AI芯片公司通常选择一到几家服务器厂商进行适配(基于Intel或者AMD的GPU机型),国产AI芯片厂商主动适配国产CPU平台的不多(除非客户指定,因为国产AI芯片本身出货量就不多)。
十、GPU服务器的液冷落地情况如何?
从产品技术发展的角度,GPU整机的特点是功耗高、算力密度大、散热要求也高,对于液冷技术应用是比较“迫切”的,以英伟达的NVL72为例,产品设计原生就是基于冷板式液冷,另外马斯克的xAI十万卡的H100集群采用的是液冷冷板方案(超微的整体方案);

国内GPU整机液冷方案落地如何呢?个人看到的情况是需求很多,落地的少、规模很小(宣传和实验为主)。在智算中心方案设计时往往要考虑技术领先性,都会进行液冷方面的调研和设计,但是一顿操作下来还是选择了风冷,原因为何呢?主要是风险更高、资金投入更大,更重要的一点是液冷并非必须项。
未来的趋势如何?随着芯片持续迭代风冷肯定会遇到瓶颈,GPU服务器+液冷是必然,相比于浸没式会优先采用冷板液冷,因为成熟度更高,但是会导致额外的成本增加,比如GPU卡的风冷改液冷成本、原厂无法质保等情况。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)