RAG+LlamaIndex+Ollama中医临床诊疗问答,超详细版RAG知识点、实施步骤及代码解析注释
response = query_engine.query("疲乏无力,消瘦,,可伴见腹胀如水状,大便或黑,皮肤燥痒可能是哪些病症?")至此已经完成了RAG的检索->增强->生成。六、使用LlamaIndex存储和读取embedding向量在对文档进行切分,将切分后的片段转化为embedding向量,构建向量索引时,会花费大量的时间,所以如果你保存过这些向量,可以直接给它加载进来继续用。:用于存储
一、 RAG 技术概述
1.1 大模型目前固有的局限性
1.2 什么是 RAG?
阶段一:检索
-
知识库准备:
-
收集所有可能用到的文档(PDF, Word, 网页,数据库等)。
-
将这些文档切分成更小的、语义完整的文本块。这是因为模型有上下文token长度限制,且小块信息更易于精准检索。【这里注意最好是结构化】
-
使用嵌入embedding 模型将这些文本块转换为向量。这个过程被称为“向量化”。向量可以理解为一段文本在高维空间中的数学表示,语义相似的文本其向量在空间中的距离也更近。
-
将所有文本块的向量及其对应的原始文本存储到向量数据库中。
-
-
实时检索:
-
当用户提出一个问题时,系统使用同一个嵌入模型将这个问题也转换为一个向量。
-
在向量数据库中进行相似性搜索,找出与问题向量最相似的几个文本块向量。这些被找出来的文本块就是与问题最相关的“参考资料”。
-
阶段二:增强
-
将用户的原始问题 和 检索到的相关文本块 组合在一起,构建成一个新的、富含上下文的提示。
-
这个提示通常会遵循一个精心设计的模板,例如:
请根据以下提供的背景信息来回答问题。 【背景信息】 {这里插入检索到的相关文本块1} {这里插入检索到的相关文本块2} ... 【问题】 {用户的原始问题} 【要求】 如果背景信息足以回答问题,请根据背景信息生成答案。如果背景信息不足以回答,请说明你无法根据提供的信息回答问题。
-
这个过程就是“增强”,它用外部知识增强了原始提示。
阶段三:生成
-
将这个增强后的提示发送给大语言模型。
-
大语言模型基于这个包含背景信息的提示,生成一个精准、相关且可靠的答案。
-
最终,系统将答案和(可选的)引用的源文档返回给用户。
二、RAG 工程化
2.1 RAG系统的基本搭建流程
三、项目环境配置
3.1 使用 conda 创建项目环境
安装anaconda,打开你的命令行,或者 :
:
# 创建环境
conda create -n tcm-ai-rag python=3.10# 激活环境
conda activate tcm-ai-rag3.2 安装项目所需依赖库
# 安装 LlamaIndex 相关包
pip install llama-index
pip install llama-index-embeddings-huggingface
pip install llama-index-llms-huggingface
# 安装 CUDA 版本 Pytorch
pip install torch==2.6.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu118四、模型下载
安装Ollama,官网:Ollama
然后直接在Ollama就可以搜索选择模型下载,后面的8b就是模型参数量大小,越大模型效果越好,但也吃显存,选择一个合适的即可。
 当然,也可以去魔搭的模型库直接搜索下载:模型库首页 · 魔搭社区
当然,也可以去魔搭的模型库直接搜索下载:模型库首页 · 魔搭社区
为什么使用Ollama
-
性能考虑:Ollama 通常比直接加载 HuggingFace 模型更节省资源
-
懒人方便直接下载部署大模型。
方式 优点 缺点 HuggingFace直接加载 完全控制,无需网络 占用显存大,加载慢 Ollama API 资源占用小,启动快 需要服务运行,网络依赖
推荐使用 Ollama 方式,特别是对于大模型,它能更好地管理资源并提供稳定的服务。
如果你数据也特别大、就需要把数据和模型都加载到显存里。
4.1 下载 Embedding 模型权重
embedding 模型比较小,直接用使用 modelscope 提供的 sdk 进行模型下载
使用BAAI开源的中文bge模型作为embedding模型,使用modlescope提供的SDK将模型权重下载到本地(这里下载的模型放在D盘的 AIProject / modelscope):
-
BAAI/bge-large-zh: 智源出的中文Embedding模型,在中文任务上表现非常出色。
from modelscope import snapshot_download
# model_id 模型的id
# cache_dir 缓存到本地的路径
model_dir = snapshot_download(model_id="BAAI/bge-base-zh-v1.5", cache_dir="D:/AIProject/modelscope")Ollama也可以找一个300MB大小的embedding模型,自己选择【后面都要注意自己模型放的位置】
五、构建中医临床诊疗术语证候问答
5.1 语料准备
-
国家标准全文公开系统访问路径进入国家标准化管理委员会主办的 “国家标准全文公开系统”(https://openstd.samr.gov.cn/bzgk/gb),在搜索栏输入标准号或名称即可查询。
- 输入 “GB/T 16751.1-2023” 可直达《中医临床诊疗术语 第 1 部分:疾病》现行版本
- 同理,输入 “GB/T 16751.2-2021” 和 “GB/T 16751.3-2023” 可分别获取证候和治法部分的全文。



- 国家中医药管理局官网(http://www.natcm.gov.cn),点击导航栏中的 “政策文件” 栏目,在搜索框输入 “中医临床诊疗术语” 即可找到相关通知及附件。
- 登录中国政府网(www.gov.cn),在 “政策” 栏目下选择 “国务院部门文件”,搜索 “中医临床诊疗术语” 即可找到两部门联合发布的通知及附件。
 也可直接从文章顶部资源绑定下载
也可直接从文章顶部资源绑定下载
 类似于这种结构化的比较好
类似于这种结构化的比较好
5.2 基于 LlamaIndex 来快速构建知识库
5.2.1 导入所需的包
import logging
import sys
import torch
from llama_index.llms.ollama import Ollama
from llama_index.core import PromptTemplate, Settings, SimpleDirectoryReader, VectorStoreIndex, load_index_from_storage, StorageContext, QueryBundle
from llama_index.core.schema import MetadataMode
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.node_parser import SentenceSplitter5.2.2 定义日志配置
# 定义日志配置
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))5.2.3 使用 llama_index_llms_Ollama 调用本地大模型
# 使用 Ollama 部署的 deepseek-r1 模型
llm = Ollama(
model="deepseek-r1:8b", # 模型名称
base_url="http://localhost:11434",# Ollama服务地址
system_prompt="你是一个有帮助的AI助手,请用中文回答",
request_timeout=1200.0,# 请求超时时间
context_window=8192, # 上下文窗口大小,根据模型能力调整
max_new_tokens=2048,# 生成的最大新 token 数
temperature=0.1,# 温度 [0-1] ,模型的随机性(是不是固定的回答【如果有知识库的时候】){创意生成、文案写作的可以往上调}
# 其他可选参数
top_p=0.9,# 核采样 [0-1],控制词汇多样性
)
Settings.llm = llmOllama提供了丰富的参数来配置模型行为、有些模型支持、有的模型不支持、但大部分都支持。
下面是一些参数,你可以选择调整的。
llm = Ollama(
# 1. 基本模型参数
model="deepseek-r1:8b", # 模型名称
base_url="http://localhost:11434", # Ollama服务地址
request_timeout=120.0, # 请求超时时间
# 2. 生成参数
temperature=0.7, # 温度 [0-1],控制随机性
top_p=0.9, # 核采样 [0-1],控制词汇多样性
top_k=40, # 候选词数量
num_predict=2048, # 最大生成token数
repeat_penalty=1.1, # 重复惩罚 [1.0-2.0]
presence_penalty=0.0, # 存在惩罚
frequency_penalty=0.0, # 频率惩罚
# 3. 上下文和系统设置
context_window=8192, # 上下文窗口大小
system_prompt="你是一个有帮助的AI助手", # 系统提示词
num_ctx=4096, # 上下文长度
num_thread=4,
# 3. 高级配置
seed=42, # 随机种子,确保可重复性
mirostat=0, # Mirostat采样 [0,1,2]
mirostat_tau=5.0, # Mirostat tau参数
mirostat_eta=0.1, # Mirostat eta参数
tfs_z=1.0, # 尾部自由采样
stop=["\n", "。", "!"], # 停止序列
)5.2.4 使用 llama_index_embeddings_huggingface 调用本地 embedding 模型
刚刚下载的embedding模型就在这里调用了
# 调用本地 embedding 模型
Settings.embed_model = HuggingFaceEmbedding(
model_name="D:/AIProject/modelscope/BAAI/bge-base-zh-v1___5"
)5.2.5 读取文档
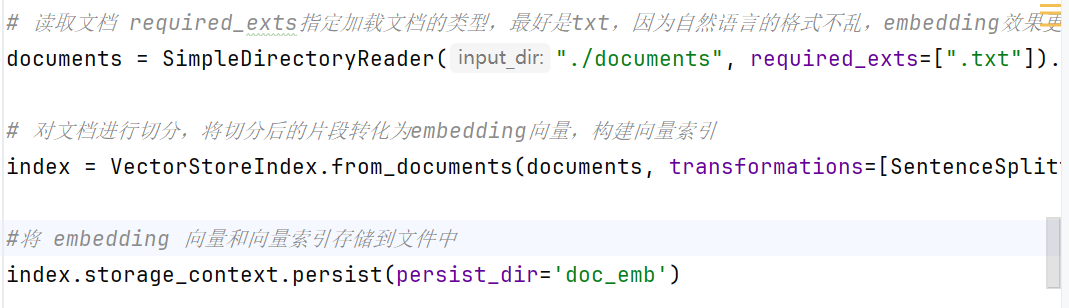
SimpleDirectoryReader是llamaindex加载文档的函数
# 读取文档 required_exts指定加载文档的类型,最好是txt,因为自然语言的格式不乱,embedding效果更好
# 在你当前文件夹下新建一个documents文件夹,把数据换成txt格式放到documents文件夹下
# 读取文档 required_exts指定加载文档的类型,最好是txt,因为自然语言的格式不乱,embedding效果更好
# 在你当前文件夹下新建一个documents文件夹,把数据换成txt格式放到documents文件夹下
documents = SimpleDirectoryReader("./documents", required_exts=[".txt"]).load_data()5.2.6 对文档进行处理【重点】
- 对原始文档进行切分
- 将切分后的文本片段转换为embedding向量表示
- 基于向量化结果构建高效索引
# 对文档进行切分,将切分后的片段转化为embedding向量,构建向量索引
index = VectorStoreIndex.from_documents(documents, transformations=[SentenceSplitter(chunk_size=256)])
代码解释:
VectorStoreIndex:这是一个索引类(常见于 LlamaIndex 等框架),用于管理文档的向量表示。它的本质是将文本转换为数值向量(通过嵌入模型)并组织存储,方便后续通过 “语义相似性” 快速检索相关内容。
from_documents:这是VectorStoreIndex的类方法,用于从原始文档直接创建索引。它简化了 “文档处理→向量生成→索引构建” 的流程。
documents:传入的参数,是一个文档集合(通常是列表形式)刚刚加载的txt文件。这些文档可以是从文本文件、PDF、网页等提取的原始文本数据(例如Document对象列表)。
transformations=[SentenceSplitter(chunk_size=256)]:文档预处理的转换步骤,这里使用了
SentenceSplitter(句子分割器):
SentenceSplitter的作用是将长文档切割成较小的文本块(“chunk”)。
chunk_size=256表示每个文本块的长度限制(通常以字符或词为单位,具体取决于实现),即每个块大约包含 256 个字符。
5.2.7 将 embedding 向量和向量索引存储到文件中
#将 embedding 向量和向量索引存储到文件中
index.storage_context.persist(persist_dir='doc_emb')在当前目录下新建一个doc_emb文件夹,储存这些向量,用storage_context.persist方法给它储存下来,方便下次调用。
这时候有一个问题、为啥要用向量索引,向量索引又是什么:
向量索引(Vector Index)是专门为高维向量(如 embedding 向量)设计的 “快速检索数据结构”,核心作用是解决 “当向量数量极大时(如百万、亿级),如何快速找到与查询向量相似的向量” 的问题。
为什么需要向量索引?
假设你有 100 万个文档,每个文档对应一个 768 维的 embedding 向量。当用户输入一个查询(比如 “如何学习 Python”),系统会先将查询转为向量,然后需要从 100 万个向量中找到 “最相似” 的 Top N 个(这是 RAG 等语义检索的核心步骤)。
如果没有索引,只能用 “暴力搜索”:逐个计算查询向量与 100 万个向量的相似度(如余弦相似度),然后排序取 Top N。但这种方式有两个致命问题:
- 速度太慢:每个相似度计算需要 O (d) 时间(d 是向量维度,如 768),100 万向量就是 O (10⁶×d),实际中可能需要几秒甚至几十秒,无法满足实时需求。
- 资源消耗大:大量计算会占用极高的 CPU/GPU 资源,成本不可接受。
向量索引的作用就是:通过预先构建特殊的数据结构,将原本 “全量比对” 的过程优化为 “定向快速筛选”,大幅降低计算量,让相似向量检索从 “不可用” 变得 “实时可用”。
向量索引的核心原理
向量索引本质是一种 “空间组织策略”—— 它不存储原始向量的全部信息,而是通过对向量的空间分布进行 “预处理”,构建一个 “导航结构”,让查询时能快速缩小范围,只对少量候选向量计算相似度。
常见的向量索引类型:精确索引和近似索引
1. 精确索引(Exact Index)
- 原理:保证能找到所有真正相似的向量,无遗漏。
- 典型代表:KD 树(KD-Tree)、球树(Ball Tree)。
- 局限性:仅适合低维向量(如 d<20),当维度超过 50 时,查询速度会急剧下降(“维度灾难”),无法处理百万级以上向量。
2. 近似索引(Approximate Index,主流选择)
- 原理:牺牲极少量召回率(比如从 100% 降到 95%),换取 10-100 倍的速度提升,在实际场景中(如搜索、推荐)用户几乎感知不到差异。
- 典型代表:
-
IVF(Inverted File Index,倒排文件索引):先对所有向量做聚类(比如聚成 1000 个簇),每个簇有一个 “中心向量”。查询时,先找到与查询向量最接近的几个簇(比如 Top 10),只在这些簇内的向量中计算相似度。核心:通过 “聚类缩小范围”,把 100 万向量的比对变成 10 个簇(假设每个簇 1000 个向量)共 1 万向量的比对,速度提升 100 倍。
-
HNSW(Hierarchical Navigable Small World,分层导航小世界):构建多层 “图结构”:底层是所有向量的连接图(每个向量连接几个近邻),上层是精简的 “导航图”(保留更重要的连接)。查询时从顶层开始,通过导航图快速定位到大致区域,再逐层下探到具体向量。优势:速度极快,是目前工业界最常用的索引之一(Milvus、FAISS 等库均支持)。
-
Annoy(Approximate Nearest Neighbors Oh Yeah):构建多棵随机二叉树,每棵树通过随机超平面将向量空间二分。查询时,在每棵树中快速找到候选向量,最后合并结果。适合中小规模向量集。
-
向量索引的关键指标
- 召回率(Recall):索引返回的 “相似向量” 中,真正属于 “最相似 Top N” 的比例(近似索引会低于 100%)。
- 查询延迟(Latency):单条查询从输入到返回结果的时间(目标是毫秒级)。
- 构建时间(Indexing Time):构建索引所需的时间(数据量越大,时间越长)。
- 存储空间(Memory/Disk Usage):索引本身占用的存储(通常远小于原始向量,但因结构不同差异较大)。
5.2.8 构建查询引擎
基于已构建的向量索引(index),创建一个用于处理用户查询的 “查询引擎” 对象,并指定每次查询仅返回与查询语义最相似的前 5 个文本片段
query_engine = index.as_query_engine(similarity_top_k=5)query_engine
这是创建后的查询引擎对象(用as_query_engine方法),是后续处理用户查询的核心工具。它封装了 “查询向量化→相似文本检索→结果整理(或结合大模型生成回答)” 的完整逻辑,只需调用它的query()方法输入问题,就能直接得到结果。
index
即之前通过VectorStoreIndex.from_documents()创建的向量存储索引。它内部存储了切割后的文本块及其对应的 embedding 向量,还有对应索引,是查询引擎的 “数据来源”。
as_query_engine()
这是VectorStoreIndex类的核心方法,作用是将 “静态的向量索引” 转换为 “可交互的查询引擎”。它相当于给向量索引套了一层 “交互接口”,让索引从 “仅存储向量的数据结构” 变成 “能理解用户查询、返回相关结果的工具”。
similarity_top_k=5
这是查询引擎的关键参数,控制检索结果的数量:
similarity:表示检索逻辑基于 “语义相似度”(通过向量相似度计算)。
top_k=5:表示每次查询时,仅从向量索引中返回与查询向量语义最相似的前 5 个文本块(即 Top 5 相似片段)。
查询引擎的工作流程:
当你用query_engine.query("你的问题")发起查询时query_engine会按以下步骤执行:
查询向量化 -> 相似文本检索(返回前五个相似度最高的) -> 结果处理与返回
查询引擎会将检索到的 5 个文本块整理成结构化结果,具体返回形式取决于配置:
- 默认基础模式:直接返回这 5 个文本块的内容及相似度分数。
- 结合大模型模式(RAG 核心):将这 5 个文本块作为 “上下文”,传递给大模型(如 GPT、Llama),让模型基于这些精准上下文生成自然、连贯的回答,而非依赖模型自身的训练数据。
5.2.9 最后一步,调用生成
response = query_engine.query("疲乏无力,消瘦,,可伴见腹胀如水状,大便或黑,皮肤燥痒可能是哪些病症?")
print(response)至此已经完成了RAG的检索 -> 增强 -> 生成。
六、使用LlamaIndex存储和读取embedding向量

- default_vector_store.json:用于存储embedding向量
- docstore.json:用于存储文档切分出来的片段
- graph_store.json:用于存储知识图数据
- image__vector_store.json:用于存储图像数据
- index_store.json:用于存储向量索引
存储
# 将embedding向量和向量索引存储到文件中
# ./doc_emb 是存储路径
index.storage_context.persist(persist_dir='./doc_emb')
# 很方便的集成目前主流的向量数据集 chroma上面用这个persist方法存储,如何读取呢?先从存储文件中加载,再直接构建到内存中
# 从存储文件中读取embedding向量和向量索引
storage_context = StorageContext.from_defaults(persist_dir="doc_emb")
# 根据存储的embedding向量和向量索引重新构建检索索引
index = load_index_from_storage(storage_context)
把这三步可以直接换成上面的就可以了


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐

 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)