[论文笔记]Conan-embedding: General Text Embedding with More and Better Negative Samples
⭐ 作者提出了Conan-Embedding模型,提出在训练过程中动态挖掘更好的难负样本的方法,取得了SOTA结果。
引言
今天带来论文Conan-embedding: General Text Embedding with More and Better Negative Samples的笔记。
标题翻译过来是 使用更多更优质的负样本进行通用文本嵌入,从题目可以看出来是基于对比学习的方法,并且主要关注于负样本的应用。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
嵌入模型主要通过对比学习进行训练,负样本是其中的关键组成部分。以往的工作提出了各种难负样本挖掘策略,但这些策略通常作为预处理步骤使用。本工作提出了一种名为conan-embedding的模型,最大程度地利用了更多更高质量的负样本。
具体地,由于模型处理负样本的能力在训练过程中不断演变。对比学习需要尽可能多的负样本,但受GPU内存限制,我们使用跨GPU平衡损失来为嵌入训练提供更多负样本,并在多个任务之间平衡批次大小。我们还发现,来自大语言模型的提示-响应对可以用于嵌入训练。
1. 总体介绍
通常,嵌入模型通过对比学习进行训练,负样本的质量对模型性能至关重要。先前的工作1和2提出了各种难负样本挖掘策略,在一定程度上提高了模型性能。然而,这些策略大多用作预处理步骤,限制了模型在处理复杂多变的训练数据时的性能。
为了解决这些问题,本文提出了Conan-Embedding模型,最大程度地利用更多更高质量的负样本。具体地,1) 在训练过程中迭代地挖掘困难负样本,使模型能够动态地适应不断变化的训练数据。此外,2) 引入了一种跨GPU平衡损失,以平衡多个任务中负样本的数量。我们发现, 3) 来自大语言模型的提示-响应对可以作为训练数据,进一步提升嵌入模型的性能。
2. 方法
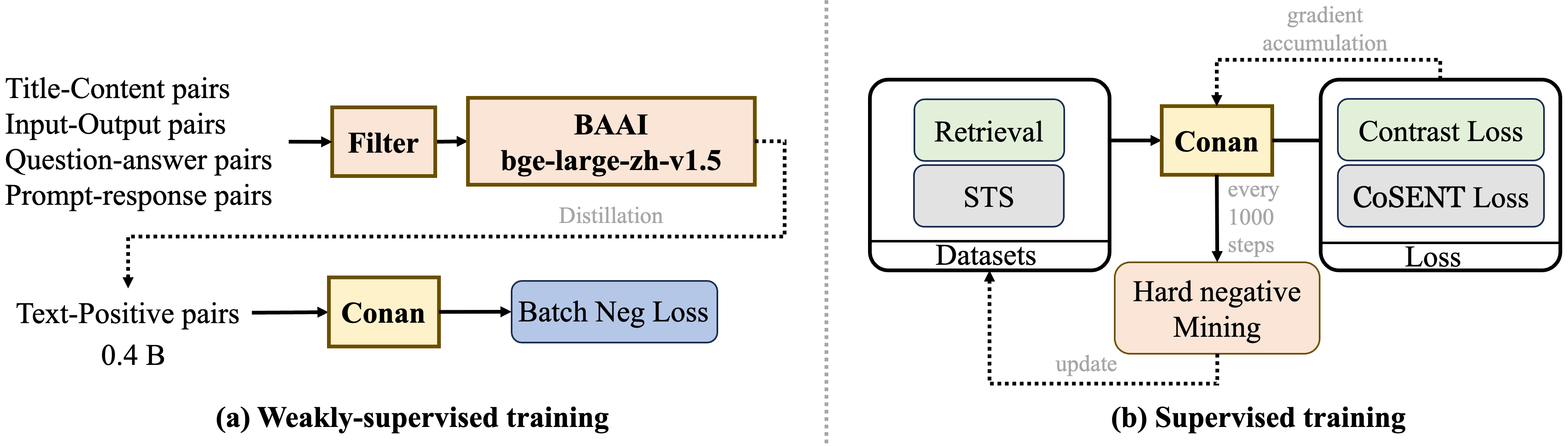
图 1:我们的方法的流程包括弱监督训练和监督训练。在弱监督训练期间,我们收集了 7.5 亿对数据集,并从中选择了 4 亿对。在监督训练期间,我们使用动态难负样本挖掘策略来更好地微调模型。
2.1 训练流程
2.1.1 预训练
遵循Li等人3的方法,这里也采用多阶段训练方法。将训练分为预训练和微调阶段。如图1(a)所示,在预训练阶段,使用Cai等人4中描述的标准数据过滤方法。过滤后,使用bge-large-zh-v1.5模型进行评分,然后丢弃所有得分低于0.4的数据。在训练中使用批内负样本的InfoNCE损失:
L neg = − ∑ i = 1 N log exp ( sim ( x i , y i + ) ) ∑ j = 1 M exp ( sim ( x i , y i ) ) (1) \mathcal L_\text{neg} = -\sum_{i=1}^N \log \frac{\exp(\text{sim}(x_i,{y_i^+}))}{\sum_{j=1}^M \exp (\text{sim}(x_i,y_i))} \tag 1 Lneg=−i=1∑Nlog∑j=1Mexp(sim(xi,yi))exp(sim(xi,yi+))(1)
x i x_i xi表示正样本的查询; y i + y_i^+ yi+表示正样本的段落; y i y_i yi代表同一批次内其他样本的段落,这些段落被视为负样本。
皮内负样本在每个小批次内,除了目标样本的正样本对外,所有其他样本都视为负样本。通过最大化正样本对的相似度并最小化负样本对的相似度,批内负样本InfoNCE损失可以有效地增强模型的判别能力和表征学习性能。通过充分利用小批量内的样本,提高了训练效率,减少了生成额外负样本的需求。
2.1.2 监督微调
在监督微调阶段,针对不同的下游任务进行特定任务的问题。如图1(b)所示,将任务分为两类:检索和STS(语义文本相似性)。检索任务包括查询、正文本和负样本,经典的损失函数时InfoNCE损失。STS任务涉及区分两个文本之间的相似性,经典的损失是交叉熵损失,但CoSENT损失略优于交叉熵损失,因此这里也采用CoSENT损失来优化STS任务,公式如下:
L cos = log ( 1 + ∑ sim ( i , j ) > sim ( k , l ) exp ( cos ( x k , x l ) − cos ( x i , x j ) τ ) ) (2) \mathcal L_\text{cos} = \log \left(1 + \sum_{\text{sim}(i,j) > \text{sim}(k,l)}\exp \left(\frac{\cos(x_k,x_l) - \cos(x_i,x_j)}{\tau} \right) \right)\tag 2 Lcos=log
1+sim(i,j)>sim(k,l)∑exp(τcos(xk,xl)−cos(xi,xj))
(2)
其中 τ \tau τ是温度; cos ( ⋅ ) \cos(\cdot) cos(⋅)是余弦相似度; sim ( k , l ) \text{sim}(k,l) sim(k,l)是 x i x_i xi和 x j x_j xj之间的相似度(监督信号)。
2.2 动态难负样本挖掘
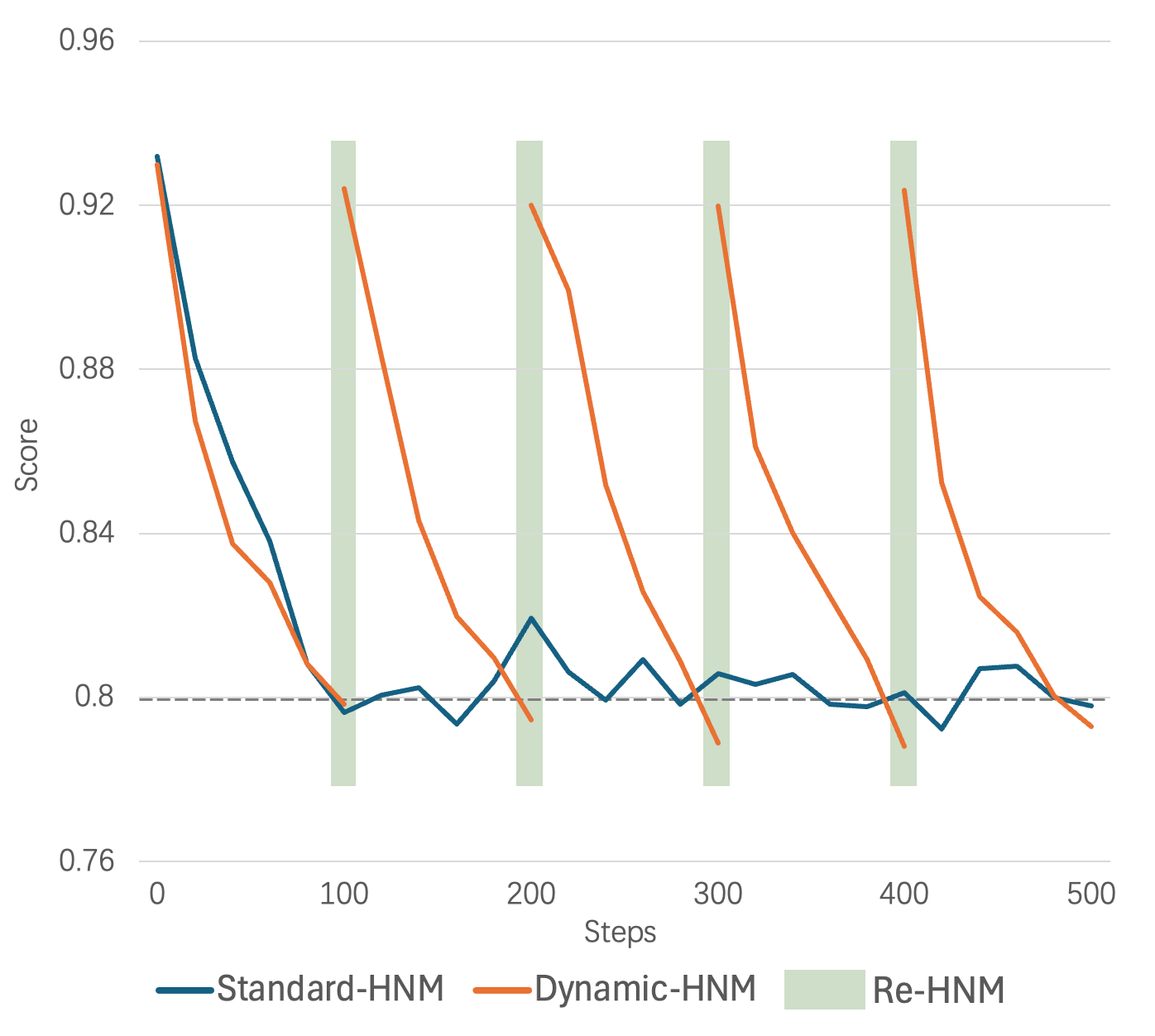
图 2:动态难负例挖掘与标准难负例挖掘:得分-步数曲线。每 100 步检查一次难负例。当得分乘以 1.15 小于初始得分且得分绝对值小于 0.8 时,我们认为负例不再困难,并用新的难负例替换它。
之前的工作主要集中在数据预处理阶段的难负样本挖掘,即难负样本是固定的。然而,随着训练的进行和模型权重的更新,对应于当前权重的难负样本会发生变化。在预处理阶段挖掘的难样本,在经过多次训练迭代后,可能变得不那么具有挑战性。
因此,我们提出了一种动态难负样本挖掘(dynamic hard negative mining)方法。对于每个数据点,记录当前难负样本相对于查询的平均得分。每100次迭代,如果得分乘1.15小于初始得分,且得分的绝对值小于0.8,则认为负样本不再困难,并进行新一轮的难负样本挖掘。
在每次动态难负样本挖掘过程中,如果需要替换难负样本,使用 ( i − 1 ) × n + 10 (i-1)\times n + 10 (i−1)×n+10到 i × n + 10 i\times n + 10 i×n+10个样本作为负例,其中 i i i代表第 i i i次替换, n n n代表每次使用的难负样本数量。整个过程的成本相当于一次迭代步骤。
与批内负样本InfoNCE损失相比,我们认为更高质量的难负样本(与当前模型权重更一致)更为重要。图2展示了动态难负样本挖掘(D-HNM)与标准难负样本挖掘(S-HNM)的正负样本得分步长曲线。随着步数的增加,S-HNM中的负样本得分停止下降并开始震荡,表明模型已经完成从该批负样本中学习。相比之下,D-HNM一旦检测到负样本不再对模型具有挑战性,就会替换这些难样本。
2.3 跨GPU批次平衡损失
为了更好利用困难样本,采用了跨GPU批次平衡损失(Cross-GPU Batch Balance Loss,CBB)。之前的方法通常在训练过程中随机地将任务分配给每个批次,我们将此称为顺序随机任务训练。这种训练通常会导致单次迭代中优化的搜索空间与嵌入模型的全局搜索空间之间存在不一致,从而在训练过程中造成振荡。这些振荡阻碍了模型收敛到全局最优,使得实现最佳性能更加困难。

图 3:跨 GPU 批次平衡损失的示例。对于检索任务,我们利用多个 GPU 来整合更多负样本。对于 STS 任务,我们增加批次大小以包含更多用于比较的案例。
为了解决这个问题,我们考虑在每个前向-损失-反向-更新循环中以平衡的方式引入每个任务。CBB策略不仅考虑不同GPU之间的通信,还考虑了不同任务之间的通信。如图3所示,为了在检索任务中利用更多难样本,确保每个GPU(gpu0、gpu1、gpu2、gpu3)拥有不同的负样本,同时共享相同的查询和正样本。对于Retri任务,每个GPU计算其对应批次的损失,并且结果汇总在gpu1。
对于STS任务,gpu4运行STS任务并获得相应的损失。最后,将结果汇总以计算当前迭代的组合CBB损失。相应的公式如下:
L CBB = − 1 n ∑ i N log exp ( s ( x i , y i + ) / τ ) exp ( s ( x i , y i + ) / τ ) + ∑ k = 1 N ∑ j = 1 n exp ( s ( x i , y j − ) / τ ) + β × L cos (3) \mathcal L_\text{CBB} = -\frac{1}{n}\sum_i^N \log \frac{\exp(\text{s}(x_i,{y_i^+})/\tau)}{\exp(\text{s}(x_i,y_i^+)/\tau) +\sum_{k=1}^N \sum_{j=1}^n \exp (\text{s}(x_i,y_j^-)/\tau)} + \beta \times \mathcal L_\text{cos} \tag 3 LCBB=−n1i∑Nlogexp(s(xi,yi+)/τ)+∑k=1N∑j=1nexp(s(xi,yj−)/τ)exp(s(xi,yi+)/τ)+β×Lcos(3)
其中 s ( x i , y i + ) s(x_i,y_i^+) s(xi,yi+)是查询 x i x_i xi和正样本 y i + y_i^+ yi+之间的评分函数,通常为余弦相似度; N N N是共享查询 x i x_i xi和正样本 y i + y_i^+ yi+的GPU数量; τ \tau τ是尺度温度; β \beta β设置为0.8。
3. 实验
3.1 实现细节
利用BERT作为基础模型,将线性层维度从1024扩展到1792,模型的总参数为326M。还利用Matryoshka表示学习计数来实现灵活的维度长度。
最大输入长度512个token。采用混合精度和DeepSpeed ZERO-stage1。使用AdamW优化器和1e-5的学习率,以及0.05的预热比例和0.001的权重衰退。批大小设置为8。
4. 结论
本文介绍了 conan-embedding 模型,该模型旨在通过最大化负样本的质量和数量来提高嵌入模型的性能。该方法围绕两个关键创新:动态难负样本挖掘和跨 GPU 平衡损失。
总结
⭐ 作者提出了Conan-Embedding模型,提出在训练过程中动态挖掘更好的难负样本的方法,取得了SOTA结果。
引用

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)