Hive (Cloudera CDH7.3(国产信创ARM版))在 Qwen 微调实施方案记录
Hive → 数据清洗 → 导出 JSONL/Parquet → GPU 集群 + Transformers 微调 Qwen。Hive(Cloudera CDH7.3(国产信创版)) 作为 Qwen 模型微调流程中上游的数据工厂,发挥重要作用。# 使用 Hive 命令导出为 JSONL(每行一个 JSON 对象)假设你要微调一个企业客服 Qwen 模型,训练数据来自历史工单系统。步骤 3:在 AI
- Hive (Cloudera CDH7.3(国产信创版))在 Qwen 微调流程中的正确角色:数据准备与预处理
Hive(Cloudera CDH7.3(国产信创版)) 作为 Qwen 模型微调流程中上游的数据工厂,发挥重要作用。
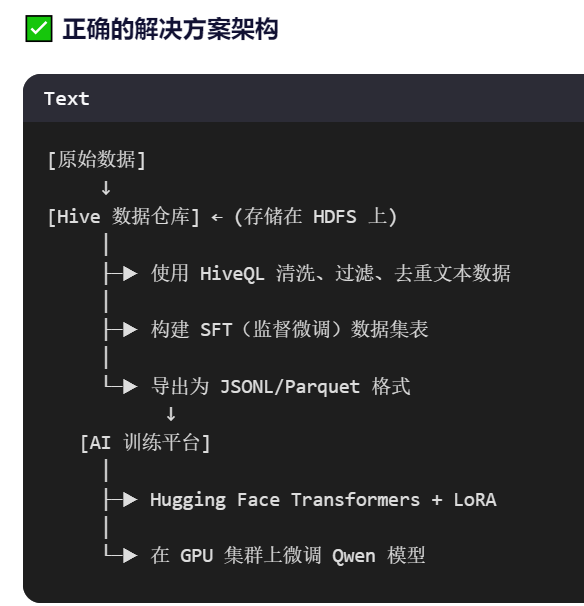
二、Hive 如何支持 Qwen 微调?—— 实际应用示例
假设你要微调一个企业客服 Qwen 模型,训练数据来自历史工单系统。
步骤 1:在 Hive 中准备训练数据
-- 创建原始工单表
CREATE TABLE customer_tickets_raw (
ticket_id STRING,
user_query STRING,
agent_response STRING,
category STRING,
create_time TIMESTAMP
) STORED AS ORC;
-- 清洗数据:去除空值、敏感信息、低质量对话
CREATE TABLE qwen_sft_data_clean AS
SELECT
CONCAT('请回答客户问题:', user_query) AS instruction,
'' AS input,
agent_response AS output,
'customer_service' AS dataset_type
FROM customer_tickets_raw
WHERE user_query IS NOT NULL
AND agent_response IS NOT NULL
AND LENGTH(user_query) > 10
AND LENGTH(agent_response) > 20
AND category IN ('technical', 'billing', 'account');步骤 2:导出数据供 AI 平台使用
# 使用 Hive 命令导出为 JSONL(每行一个 JSON 对象)
# 使用 Hive 命令导出为 JSONL(每行一个 JSON 对象)
beeline -u jdbc:hive2://hive-server:10000 \
-e "SELECT instruction, input, output FROM qwen_sft_data_clean" \
--outputformat=tsv2 \
| sed 's/\t/\",\"/g; s/^/{"instruction":"/; s/$/"}"/' > qwen_train.jsonl或使用 Spark 将 Hive 表转为 Parquet:
df = spark.sql("SELECT instruction, input, output FROM qwen_sft_data_clean")
df.write.mode("overwrite").parquet("s3://ai-bucket/qwen/train/")步骤 3:在 AI 平台微调 Qwen(Python 示例)
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
import datasets
# 加载从 Hive 导出的数据
dataset = datasets.load_dataset('json', data_files='qwen_train.jsonl')
# 加载 Qwen 模型
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B")
# 配置 LoRA 微调
lora_config = LoraConfig(r=64, lora_alpha=16, target_modules=["q_proj", "v_proj"], task_type="CAUSAL_LM")
model = get_peft_model(model, lora_config)
# 开始训练(需 GPU)
trainer = Trainer(model=model, train_dataset=dataset['train'], args=training_args)
trainer.train()替代建议:更现代化的集成方案
如果企业已有 Hive/CDH 生态,可考虑以下升级路径:

|
Hive 能做什么? |
✅ 作为数据源,使用 HiveQL 清洗、构建高质量微调数据集。 |
|
正确的流程是什么? |
Hive → 数据清洗 → 导出 JSONL/Parquet → GPU 集群 + Transformers 微调 Qwen。 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)