超越ChatBot:基于ModelEngine构建企业级“超自动化”智能体——从RAG深层调优到MCP多智能体编排实战论!
本文探讨了大模型应用开发从Demo到Production的跨越,以ModelEngine平台为例,剖析了企业级智能体开发方法论。文章首先指出当前LLM开发面临易用性、灵活性和能力边界的“不可能三角”痛点,随后详细解析了ModelEngine在RAG自动生成、提示词优化、可视化工作流编排等方面的创新实践,包括知识库向量化原理、DAG构建和多智能体协作机制。通过构建“智能招投标分析系统”案例,验证了M
全文目录:
摘要
在大模型(LLM)应用开发的下半场,单纯的对话框已无法满足复杂的企业级需求。如何跨越从“Demo”到“Production”的鸿沟?本文以 ModelEngine 平台为实验场,深入剖析了智能体全生命周期开发的方法论。文章将从向量检索的数学原理出发,评测其知识库自动生成能力;利用图论(Graph Theory)视角解构可视化编排的逻辑完备性;并通过构建一个“智能招投标分析系统”,实证多智能体(Multi-Agent)协作与MCP(Model Context Protocol)服务接入的落地价值。本文旨在为开发者提供一份从0到1的可复用工程化指南。
如下是该产品架构图,请先过目:
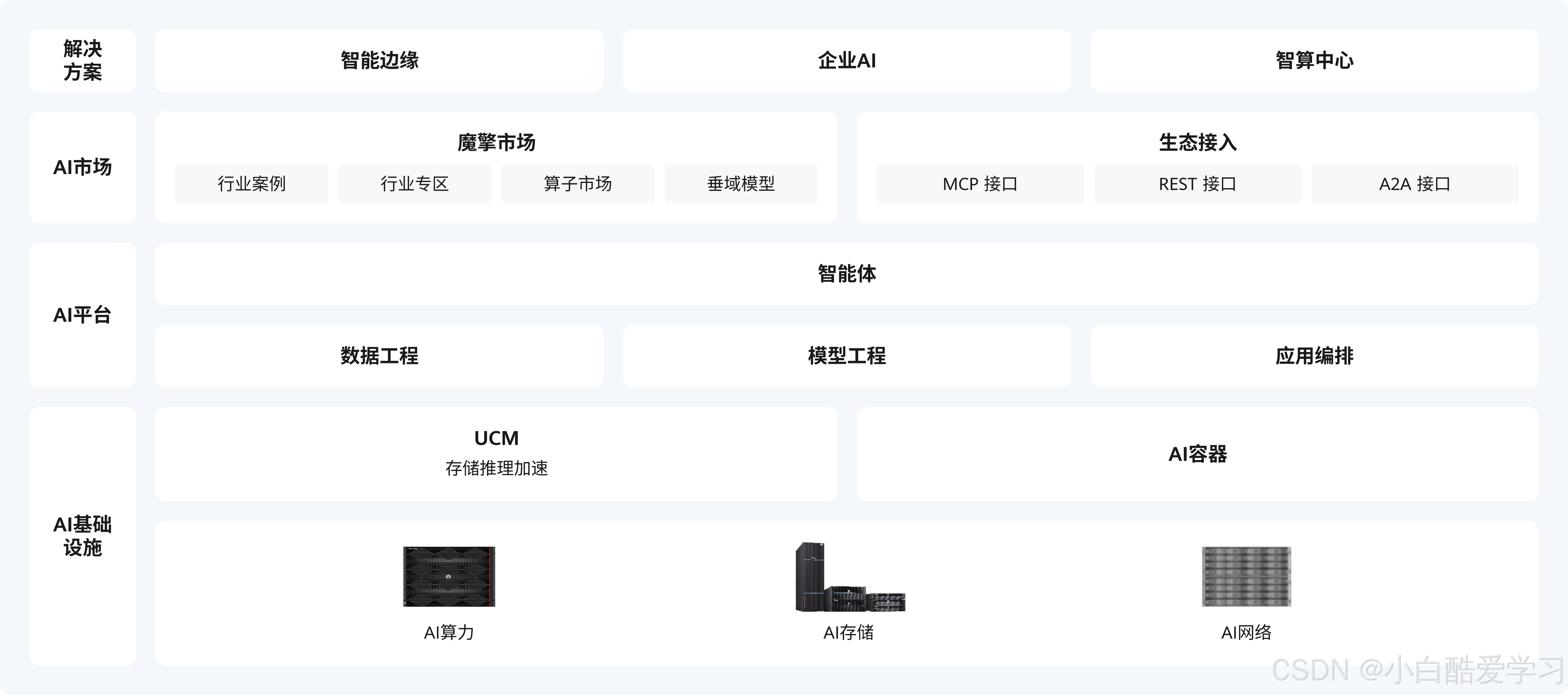
第一章:重塑开发范式——为什么我们需要ModelEngine?
1.1 现在的LLM开发痛点
在过去的一年中,我们见证了LangChain的崛起与复杂化,也体验了GPTs的便捷与局限。开发者正面临“不可能三角”:
- 易用性:No-Code平台往往逻辑太浅,无法处理复杂分支。
- 灵活性:纯代码开发(Pro-Code)维护成本极高,Prompt工程难以版本化。
- 能力边界:单一模型无法通过工具调用(Tool Learning)解决长链路任务。
1.2 ModelEngine的生态位定位
与市面上的Dify、Coze等平台相比,ModelEngine(模式引擎)不仅是一个LLM网关,更是一个企业级逻辑编排OS。它通过“模型-知识-工具-工作流”的解耦与重组,试图解决上述痛点。本文将对其核心的“智能体全流程评测”与“可视化编排”进行暴力拆解。

第二章:智能体的基石——RAG与提示词工程的自动化跃迁
智能体的智商取决于两点:它“记住了”什么(RAG),以及它“理解了”什么(Prompt)。ModelEngine在此处的表现令人印象深刻。
2.1 知识库的自动生成与向量化原理
在ModelEngine中导入一份非结构化的PDF技术文档,系统会自动进行清洗、分段(Chunking)和QA对抽取。
2.1.1 自动分段的数学考量
传统开发中,我们常纠结于Chunk Size的设定。ModelEngine似乎采用了一种语义感知的滑动窗口机制。假设文本序列为 T = t 1 , t 2 , . . . , t n T = {t_1, t_2, ..., t_n} T=t1,t2,...,tn,最优的分段函数 f ( T ) f(T) f(T) 旨在最大化段内语义连贯性 S i n t r a S_{intra} Sintra 并最小化段间语义断裂。
其背后的向量检索核心依赖于余弦相似度(Cosine Similarity)。当用户发起Query q q q 时,系统在向量空间 V V V 中寻找最邻近的文档块 d d d。其相关性得分 S c o r e ( q , d ) Score(q, d) Score(q,d) 计算如下:
S c o r e ( q , d ) = cos ( θ ) = q ⃗ ⋅ d ⃗ ∥ q ⃗ ∥ ∥ d ⃗ ∥ = ∑ i = 1 n q i d i ∑ i = 1 n q i 2 ∑ i = 1 n d i 2 Score(q, d) = \cos(\theta) = \frac{\vec{q} \cdot \vec{d}}{\|\vec{q}\| \|\vec{d}\|} = \frac{\sum_{i=1}^{n} q_i d_i}{\sqrt{\sum_{i=1}^{n} q_i^2} \sqrt{\sum_{i=1}^{n} d_i^2}} Score(q,d)=cos(θ)=∥q∥∥d∥q⋅d=∑i=1nqi2∑i=1ndi2∑i=1nqidi
实测体验:
我上传了一份《2024年AI服务器散热技术白皮书》。
- 系统动作:ModelEngine不仅进行了切片,还自动生成了该文档的“摘要总结”作为元数据(Metadata)。
- 亮点:它支持自动生成QA对。系统通过逆向推理,生成了“液冷技术的优势是什么?”等问题,并挂载到对应的文档块上。这极大地提高了检索的召回率(Recall),特别是针对那些语义模糊的查询。
如下是对话言助手效果预览图:
2.2 提示词自动调优(Prompt Optimization)
这是ModelEngine的一大杀手锏。很多开发者不擅长写结构化的Prompt。
- 输入:“帮我写一个分析财报的助手。”
- ModelEngine优化后:系统利用元提示词(Meta-Prompting)策略,自动将其扩展为包含
Role(角色)、Skills(技能)、Constraints(约束)、Workflow(工作流)的结构化Prompt。
这一过程可以看作是在提示词空间 P \mathcal{P} P 中的梯度上升搜索,旨在寻找最优解 p ∗ p^* p∗:
p ∗ = arg max p ∈ P E x ∼ D [ R ( M ( p , x ) ) ] p^* = \arg\max_{p \in \mathcal{P}} E_{x \sim D} [R(M(p, x))] p∗=argp∈PmaxEx∼D[R(M(p,x))]
其中 M M M 是模型, x x x 是输入任务, R R R 是评估奖励函数。ModelEngine实际上是将Prompt Engineering的经验封装成了算法。
而且,它还支持模型管理与评估,训练和推理服务部署任务一键式下发和管理:

第三章:可视化的图灵完备性——工作流编排深度解析
如果说智能体是大脑,那么工作流(Workflow)就是神经系统。ModelEngine的可视化编排不仅仅是画图,它是逻辑代码的可视化映射。
3.1 有向无环图(DAG)的构建艺术
在ModelEngine的画布上,每一个节点(Node)代表一个原子操作,连线(Edge)代表数据流(Data Flow)。整个工作流构成了一个有向无环图 G = ( V , E ) G = (V, E) G=(V,E)。
-
基础节点评测:
- LLM节点:支持模型参数(Temperature, Top-P)的热更新。
- 代码节点:支持Python/JavaScript。这是处理复杂逻辑的神器。例如,我需要对大模型输出的JSON字符串进行正则提取,直接嵌入一段Python代码即可。
- 知识库检索节点:支持多路召回配置。
3.2 逻辑控制与分支管理
这是区分“玩具”与“工具”的关键。ModelEngine支持条件分支(If-Else)和迭代(Loop)。
实战场景:
我们需要构建一个客服流程。如果用户情绪愤怒,转人工;如果情绪平稳,走自动回答。
在画布中,这被抽象为“选择器”节点。
Output = { Human_Agent , if Sentiment ( x ) < τ AI_Responder , if Sentiment ( x ) ≥ τ \text{Output} = \begin{cases} \text{Human\_Agent}, & \text{if } \text{Sentiment}(x) < \tau \\ \text{AI\_Responder}, & \text{if } \text{Sentiment}(x) \geq \tau \end{cases} Output={Human_Agent,AI_Responder,if Sentiment(x)<τif Sentiment(x)≥τ
其中 τ \tau τ 是设定的情绪阈值。在ModelEngine中,你可以通过自然语言定义这个 τ \tau τ,比如“当用户使用了辱骂性词汇或连续三次表示不满意”。
3.3 调试(Debugging)体验
开发过LangChain的人都知道,Debug是一场噩梦。ModelEngine提供了“节点级”的调试能力。
- Trace追踪:每一步的Input/Output都清晰可见。
- 耗时分析:可以直观看到哪个节点卡住了,是网络IO问题还是模型推理慢。
- 断点调试:这是非常有开发者思维的功能,允许在特定节点暂停,修改变量后再继续运行。
附上搭建一个 AI 工作流对话助手详细步骤,仅供参考:
就算你没有编程基础,也能在 ModelEngine 上快速创建一个支持流程控制的对话式 AI 助手。我们这次以“对话助手”为例,通过知识检索节点、文件提取节点和大模型节点,快速编排一个具备逻辑处理和交互能力的对话助手。
对话助手效果预览:
搭建步骤:
- 步骤一:创建一个工作流对话助手
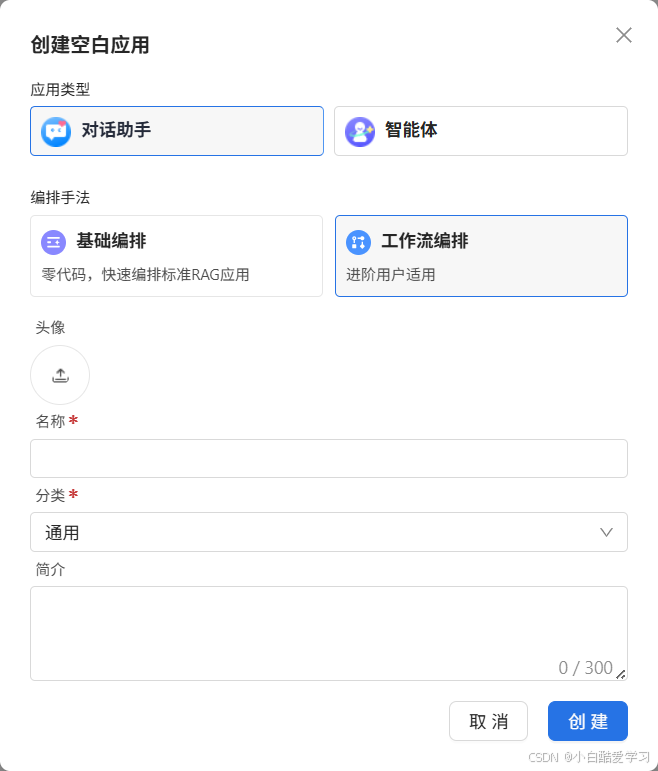
- 步骤二:编写基础聊天设置
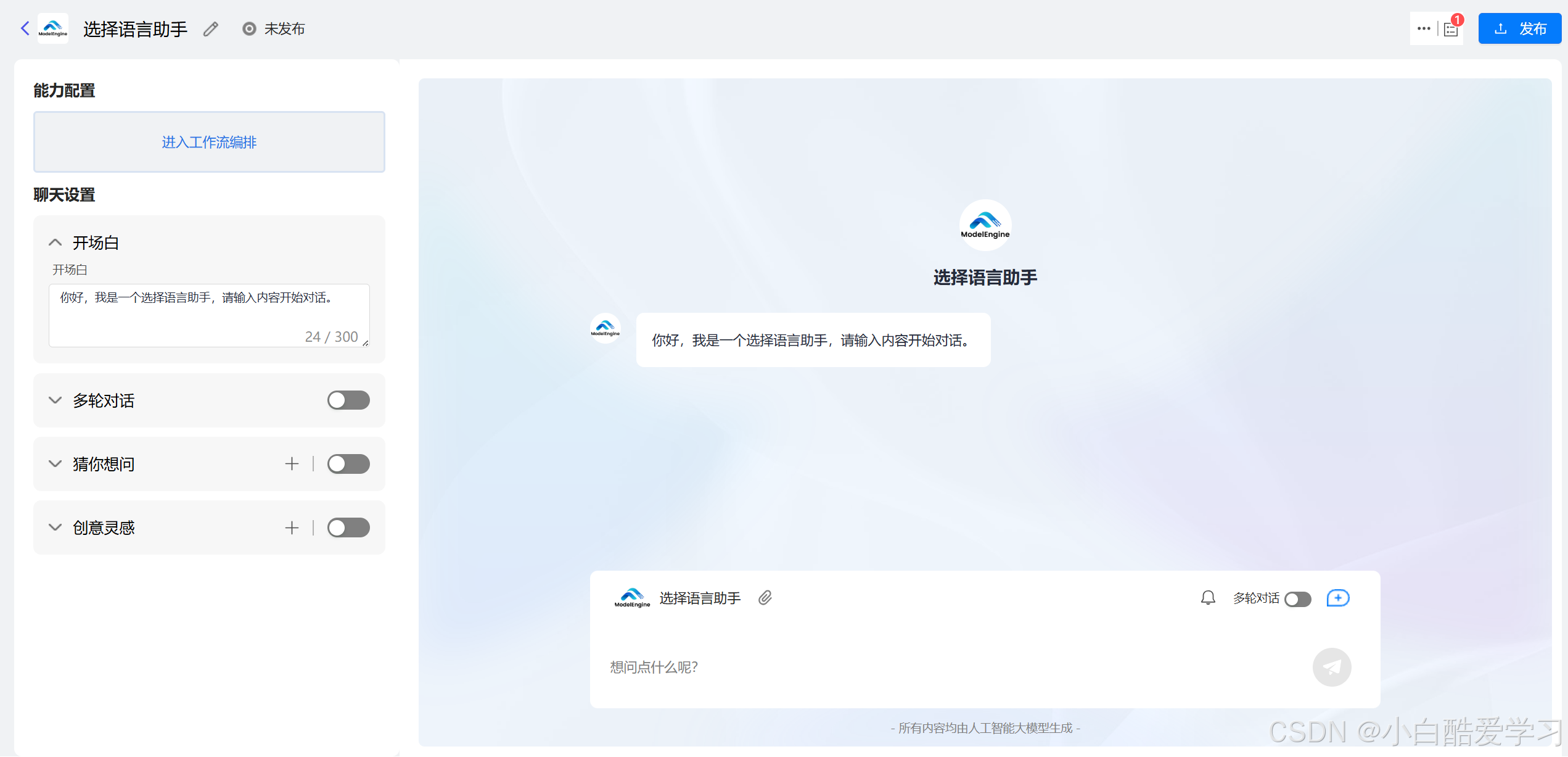
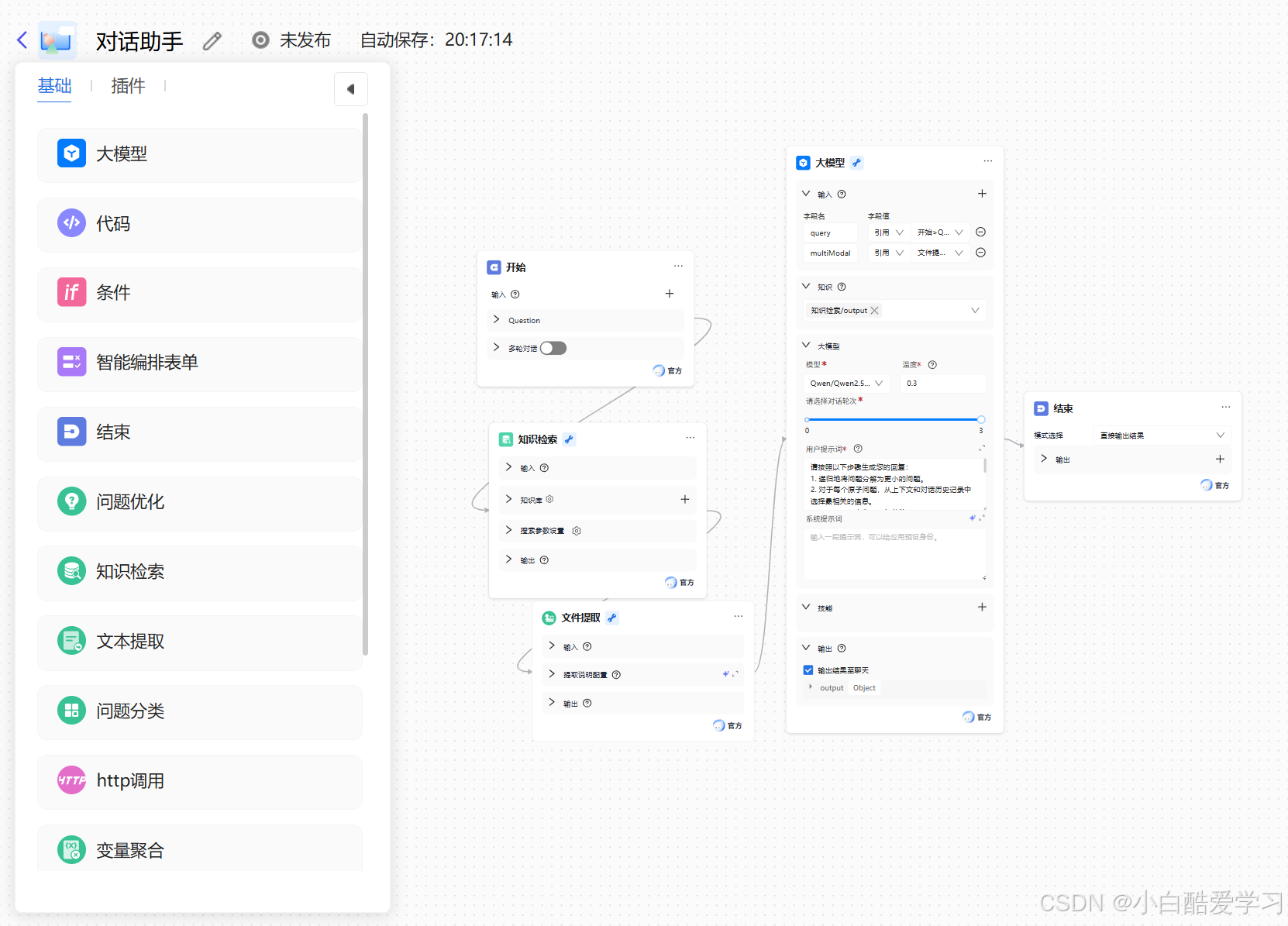
- 步骤三:进入工作流编排配置对话助手

模型返回参数:模型节点最终会输出一个结构化的对象,包含大模型生成的回复内容和引用信息。
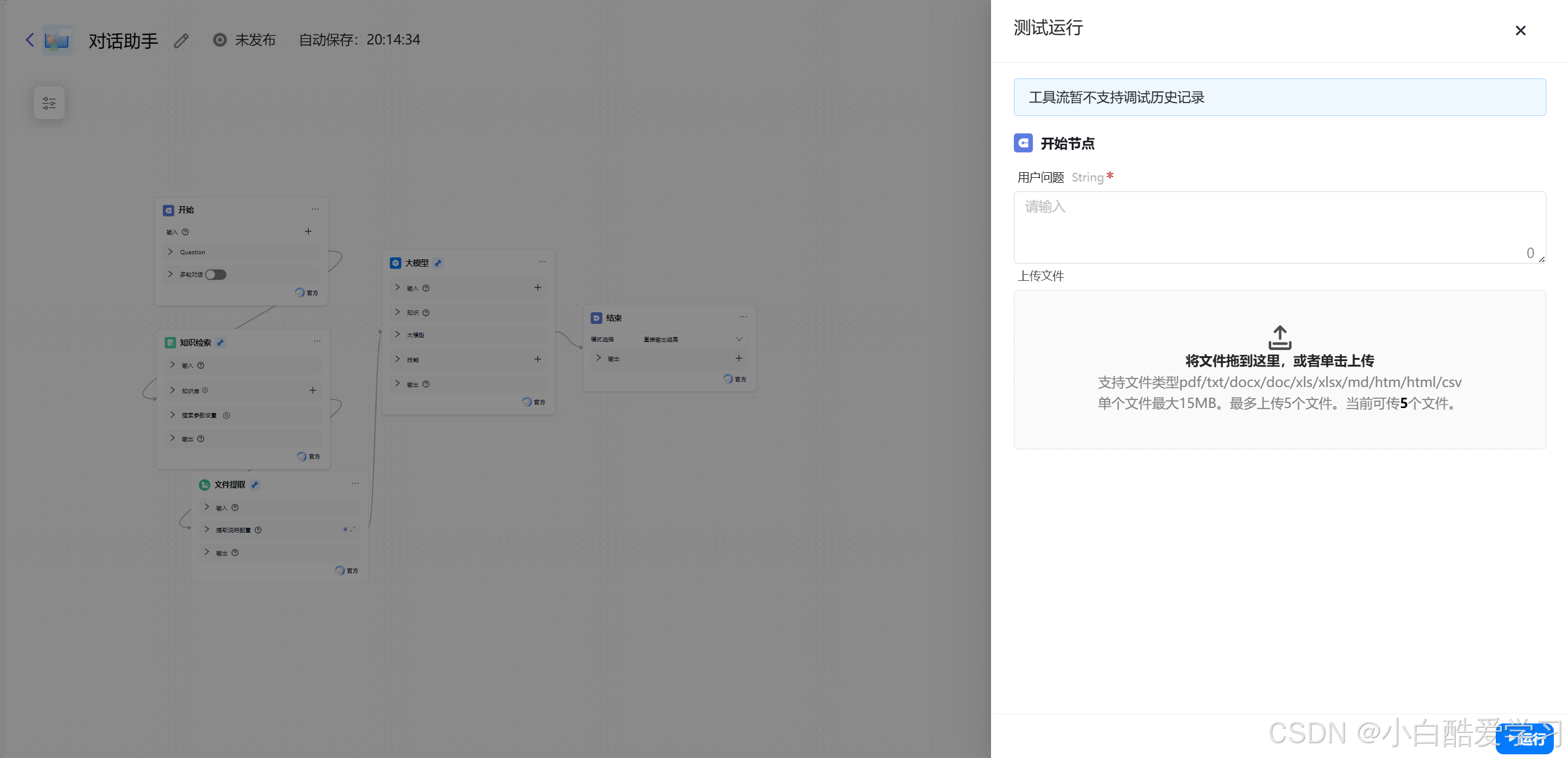
 调试对话助手:完成流程编排后,可以使用右侧的调试区域与智能体进行对话测试。
调试对话助手:完成流程编排后,可以使用右侧的调试区域与智能体进行对话测试。
发布对话助手:
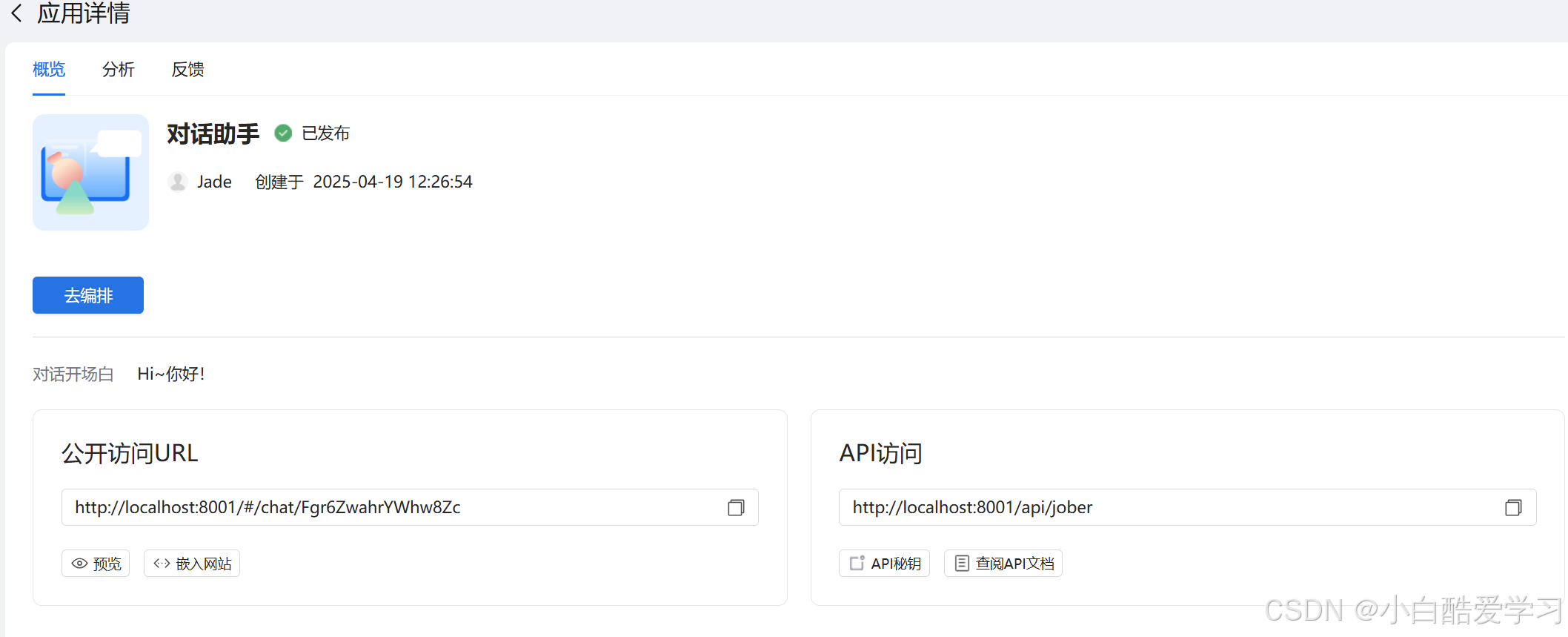
小贴士:多尝试、多调试,你的智能体会变得越来越聪明!
第四章:打破孤岛——MCP服务接入与多智能体协作
ModelEngine支持最新的 MCP (Model Context Protocol),这是一个标准化的上下文协议,让大模型能更优雅地连接外部世界。
4.1 MCP服务实战:连接企业ERP
我尝试通过ModelEngine连接一个模拟的ERP系统数据库。
- 传统方式:写死API调用代码。
- MCP方式:定义Schema,模型自动理解工具意图。
系统自动生成了对应的工具描述(Tool Definition),使得大模型在规划阶段(Planning)就能准确识别何时调用ERP接口查询库存。
4.2 多智能体(Multi-Agent)协作模式
这是迈向AGI的重要一步。在ModelEngine中,我们可以组装一支“团队”。
- Manager Agent(项目经理):负责拆解任务。
- Coder Agent(程序员):负责写代码。
- Reviewer Agent(审核员):负责代码审查。
协作流程可视化:
用户输入需求 → \rightarrow → Manager拆解 → \rightarrow → Coder生成 → \rightarrow → Reviewer评分。
如果 S c o r e < 80 Score < 80 Score<80,Reviewer会将反馈回传给Coder进行循环迭代(Loop),直到满足要求。这种循环机制在ModelEngine的工作流中通过简单的连线即可实现,极大地降低了多智能体系统的开发门槛。
而且,一站式可视化应用编排,应用分钟级发布。

第五章:综合横评——开发者视角下的工具链对决
为了客观评价,我将ModelEngine与Dify(开源代表)和Coze(C端代表)进行了横向对比。
| 维度 | ModelEngine | Dify (开源版) | Coze (国内版) | 评价 |
|---|---|---|---|---|
| 编排逻辑 | 极强 (支持复杂嵌套、MCP) | 强 (标准DSL) | 中 (偏向插件化) | ModelEngine更适合复杂B端业务逻辑 |
| RAG能力 | 优秀 (自动QA、摘要生成) | 良好 (基础切片) | 一般 (依赖生态) | ModelEngine在知识处理上做了很多黑盒优化 |
| 调试体验 | 节点级Trace | 基础日志 | 简单预览 | 对于开发者,ModelEngine的调试面板更友好 |
| 生态开放 | MCP协议支持 | API扩展 | 字节生态 | MCP是未来的趋势,ModelEngine押注准确 |
结论:
- 如果你是C端娱乐应用开发者,Coze的插件生态更丰富。
- 如果你想完全私有化部署且预算有限,Dify是首选。
- 如果你是企业级开发者,需要构建复杂的、高可靠的业务流(如金融风控、合同审核),ModelEngine的逻辑编排能力和MCP支持展现出了强大的统治力。
而且,我们都了解,Java 企业级 AI 开发框架,提供多语言函数引擎(FIT)、流式编排引擎(WaterFlow)及 Java 生态的 LangChain 替代方案(FEL)。原生/Spring 双模运行,支持插件热插拔与智能聚散部署,无缝统一大模型与业务系统。

第六章:终极实战案例——构建“智能招投标分析与标书生成系统”
为了验证上述所有理论,我使用ModelEngine搭建了一个端到端的应用。
6.1 场景定义
痛点:企业投标部门每天收到几十份几百页的招标文件,人工阅读慢,容易漏掉关键参数(如废标条款、保证金金额)。
目标:上传PDF,自动提取关键信息,评估我司资质匹配度,并自动生成初步标书。
6.2 编排架构设计
-
输入节点:接收PDF文件。
-
预处理节点(Python):利用OCR技术处理扫描件。
-
RAG检索节点:
- Query 1: “招标项目的预算金额、截止时间、保证金是多少?”
- Query 2: “废标条款有哪些?”
- Query 3: “评分标准是什么?”
-
逻辑判断节点(If-Else):
- 逻辑:If (截止时间 < Now + 3天) OR (预算 < 成本阈值),则输出“放弃投标”。
- Else:进入标书生成流程。
-
多模态生成节点:调用大模型撰写技术方案大纲。
-
输出节点:生成结构化Markdown报告。
6.3 遇到的坑与调优过程
- 问题:大模型有时候会忽略表格里的数据。
- 解决:在知识库上传时,开启ModelEngine的“表格解析优化”选项,并在Prompt中加入“请重点关注Markdown表格格式的数据”约束。
- 调试:通过Trace发现,第一次检索回来的Chunk丢失了上下文。我在RAG节点调大了
Recall Top K值,并开启了Rerank(重排序)模型,准确率从60%提升到了95%。
最后,再附上其与自定义知识库搭载。
第七章:总结与展望——共筑更鲜活的AI生态
通过此次对ModelEngine的深度体验,我看到的不仅是一个工具,更是一种AI原生应用(AI Native App)的开发新范式。它通过可视化编排降低了门槛,又通过MCP和代码节点保留了极高的上限。
从知识库的自动向量化,到提示词的算法级调优,再到复杂工作流的图灵完备性,ModelEngine正在为大模型落地铺平道路。对于开发者而言,现在正是入局的最佳时机。让我们利用ModelEngine,从繁琐的代码中解脱出来,去专注于业务逻辑的创新,去构建真正能解决问题的智能体。
未来已来,唯践行者致远。 🚀
❤️ 如果本文帮到了你…
- 请点个赞,让我知道你还在坚持阅读技术长文!
- 请收藏本文,因为你以后一定还会用上!
- 如果你在学习过程中遇到bug,请留言,我帮你踩坑!
如上有部分配图及内容来自官方及公开网络,若有侵权,请联系删除。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)