上交&中山导航智能体的自我进化!EvolveNav:大模型驱动的自改进式具身推理与导航
EvolveNav通过引入形式化CoT监督微调和自反思后训练,有效提升了LLM在VLN任务中的推理能力和决策准确性!
·

- 作者:Bingqian Lin1^{1}1 , Yunshuang Nie2^{2}2, Khun Loun Zai2^{2}2, Ziming Wei2^{2}2, Mingfei Han3^{3}3, Rongtao Xu3^{3}3, Minzhe Niu4^{4}4, Jianhua Han4^{4}4, Liang Lin2^{2}2, Cewu Lu1^{1}1, Xiaodan Liang2^{2}2
- 单位:1^{1}1上海交通大学,2^{2}2中山大学,3^{3}3沙迦穆罕默德·本·扎耶德人工智能大学,$^{4}华为诺亚方舟实验室
- 论文标题:EvolveNav: Self-Improving Embodied Reasoning for LLM-Based Vision-Language Navigation
- 论文链接:https://arxiv.org/pdf/2506.01551
- 代码链接:https://github.com/expectorlin/EvolveNav
主要贡献
- 提出EvolveNav框架,通过自改进式具身推理提升LLM在VLN任务中的泛化和适应能力。
- 构建形式化的思维链(CoT)标签用于监督式微调,引入自增强CoT标签增强策略和自反思辅助任务,以自修正方式学习正确推理模式,减轻过拟合。
- 在R2R和CVDN两个标准VLN基准测试中,EvolveNav优于其他基于LLM的方法,为设计进一步具身推理范式提供有意义的见解。
研究背景
-
视觉语言导航(VLN)是具身AI领域的重要研究方向,目标是让智能体根据自然语言指令在复杂视觉环境中导航至目标位置。
-
早期工作通过设计专用模型架构、引入强大的学习范式和开发有用的数据增强技术来提升VLN性能。然而,这些方法受限于预训练和VLN领域数据的有限规模,无法充分学习导航推理知识,难以处理各种未见的导航场景。
-
随着大型语言模型(LLM)的发展,其丰富的现实世界常识和强大的推理能力为VLN任务带来了新的机遇。一些研究尝试以零样本或可训练的方式构建基于LLM的VLN模型。
-
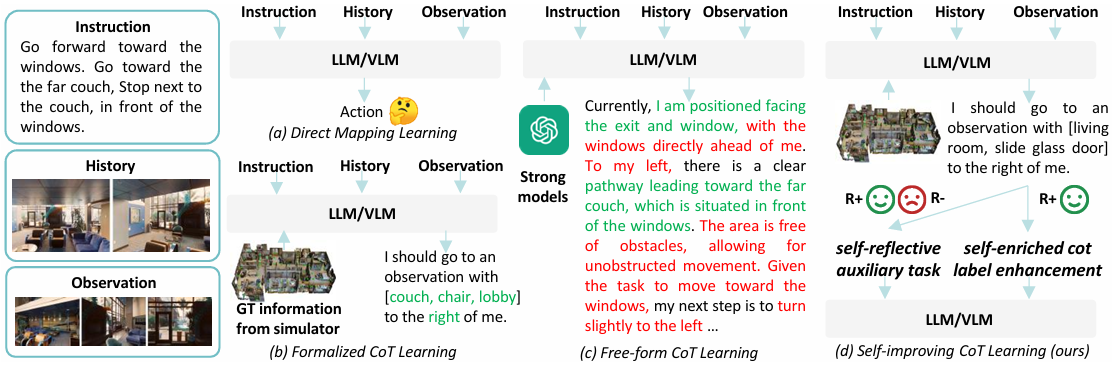
然而,这些方法通常直接将导航输入映射到决策,缺乏明确的中间推理步骤,导致决策不可解释,并可能限制性能。
方法
问题定义
- 在视觉语言导航(VLN)任务中,智能体需要根据自然语言指令从起始位置导航到目标位置。
- 在每个时间步 ttt,智能体接收一个全景观察 OtO_tOt,包含多个单视图观察 Ot,kO_{t,k}Ot,k。
- 智能体需要从可导航视图中选择一个动作 ata_tat,并记录之前的导航历史。
模型架构
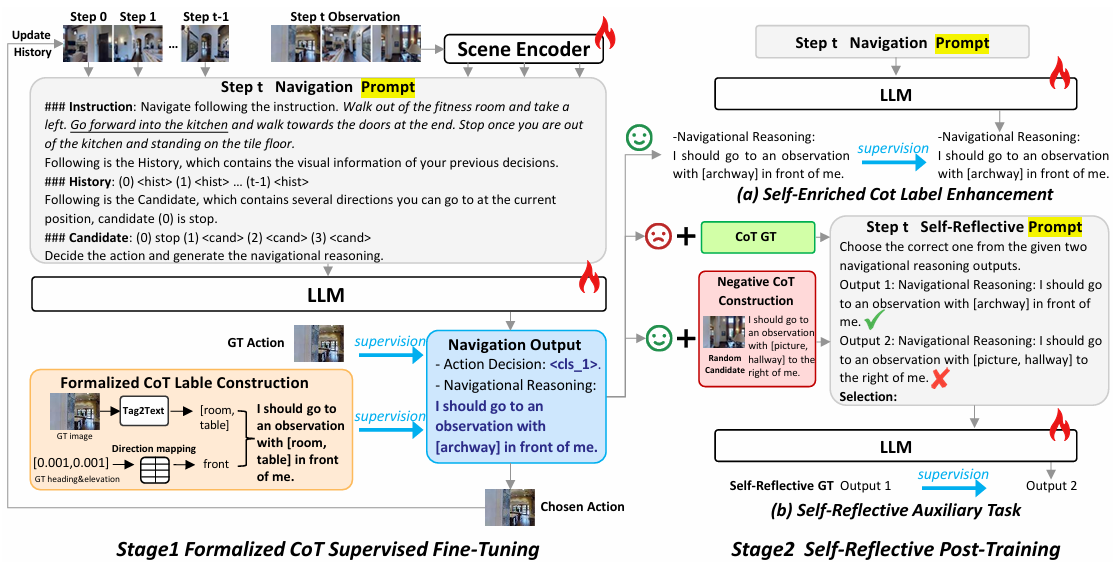
EvolveNav框架基于LLM的导航智能体包含三个主要部分:
- 场景编码器FvF_vFv:将可导航视图转换为视觉表示。
- LLM主干FLLMF_{LLM}FLLM:接收导航提示 PPP,生成动作决策和导航思维链(CoT)。
- 动作预测头FactionF_{action}Faction:根据CoT推理生成最终动作 ata_tat。
自改进式具身推理
EvolveNav框架包含两个阶段的训练:
- 形式化CoT监督微调:
- 形式化CoT标签收集:从真实动作对应的观察中提取地标和方向信息,构建形式化的CoT标签,如“我应该去一个有[地标]在我[方向]的观察点”。
- 监督微调:使用形式化CoT标签对LLM进行监督微调,激活模型的导航推理能力,同时提高推理速度。训练目标 LSFTL_{SFT}LSFT 最大化生成CoT标签的似然,总训练目标 LStage1L_{\text{Stage1}}LStage1 为 Laction+λLSFTL_{action} + \lambda L_{SFT}Laction+λLSFT。
- 自反思后训练:
- 自增强CoT标签增强:如果模型的行动决策与真实动作一致,则将模型自己的推理输出作为新的CoT标签,增加监督的多样性。
- 自反思辅助任务:通过对比正确和错误的推理输出,训练模型识别正确的推理模式,进一步提升推理能力。总训练目标 LStage2L_{\text{Stage2}}LStage2 为 Laction+λ1LSFT+λ2LsrL_{action} + \lambda_1 L_{SFT} + \lambda_2 L_{sr}Laction+λ1LSFT+λ2Lsr。
实验
实验设置
- 数据集:R2R(90个室内环境,7189条轨迹)和CVDN(2050个对话,7000条轨迹)。
- 评估指标:TL(轨迹长度)、NE(导航误差)、SR(成功率)、SPL(路径长度加权成功率)、OSR(Oracle成功率)、GP(目标进展)。
- 实现细节:使用Vicuna 7B作为LLM主干,训练分为两个阶段,第一阶段全参数训练,第二阶段LoRA训练。第一阶段训练约1.5天,第二阶段训练约1天。
与现有方法的比较
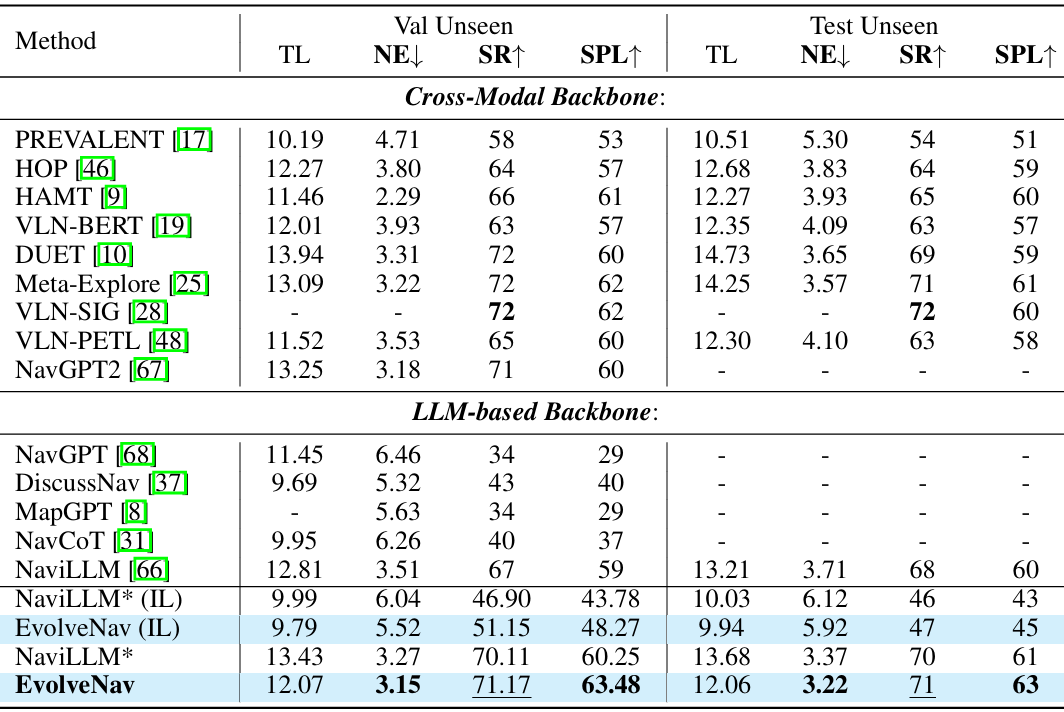
- R2R数据集:EvolveNav在Val Unseen和Test Unseen上优于基线方法NaviLLM*,SPL分别提高4.5%和3.2%。
- CVDN数据集:EvolveNav在Val Unseen和Test上优于NaviLLM*,GP分别提高0.7和0.27。
消融研究
- 不同方法组件的效果:
- 形式化CoT监督微调:显著提升了导航性能,SR从46.90%提高到49.62%,SPL从43.78提高到46.26%。
- 自增强CoT标签和自反思辅助任务:进一步提升了性能,SR提高到50.47%,SPL提高到47.98%。
- 完整模型:在所有变体中表现最佳,SR为51.15%,SPL为48.27%。
- 不同CoT标签的效果:
- 形式化CoT标签:减少了冗余推理信息,提高了推理速度(约3倍提升),并优于仅使用方向或地标信息的标签。
- 自由形式CoT标签:推理时间长,性能略低于形式化CoT标签。
- 仅方向或仅地标:性能不如形式化CoT标签,表明地标和方向信息都很重要。
可视化

- 动作决策可视化:
- EvolveNav生成的导航推理更合理,能够正确选择动作,而NaviLLM在某些情况下会做出错误决策。例如,在选择正确门口时,EvolveNav能够准确推断,而NaviLLM则可能选择错误的路径。
- 地标提取可视化:
- 形式化CoT标签通过结合图像描述模型和NLP工具提取地标,能够有效减少冗余和幻觉,保留有用信息。
- 自增强CoT标签可视化:
- 自增强CoT标签增加了监督多样性,帮助智能体学习更细粒度的指令,提高泛化能力。
结论与未来工作
- 结论:
- EvolveNav通过引入形式化CoT监督微调和自反思后训练,有效提升了LLM在VLN任务中的推理能力和决策准确性,同时减轻了对训练推理标签分布的过拟合,提高了泛化能力。
- 未来工作:
- 未来工作将探索更高效的参数训练策略或更轻量级的LLM,以降低计算资源消耗,并提高CoT标签构建的准确性。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)