本地大模型快速构建RAG/Prompt/,附源码
相比大家对AI大模型已经不陌生,但是想本地部署,又奈何不会,教程五花八门,这篇文章直接开始实操流程,从安装到使用。废话不多说,let‘s go针对新手,直接附源码,萌新可以直接使用本文完整的给大家走了一遍流程,不过整体下来还是有些繁琐,但是在可以使用的那一瞬间满足感真的拉满,大家可以跟着此文一步一步顺一遍。但是之后此类方法感觉不会使用那么频繁,所以下期讲述本地部署dify和ragflow来调用这些
本地部署大模型快速构建RAG/Prompt并调用
前言
相比大家对AI大模型已经不陌生,但是想本地部署,又奈何不会,教程五花八门,这篇文章直接开始实操流程,从安装到使用。废话不多说,let‘s go
针对新手,直接附源码,萌新可以直接使用
背景
因为条件有限哈,我先说下我的电脑配置(如图),仅仅为了走一遍流程
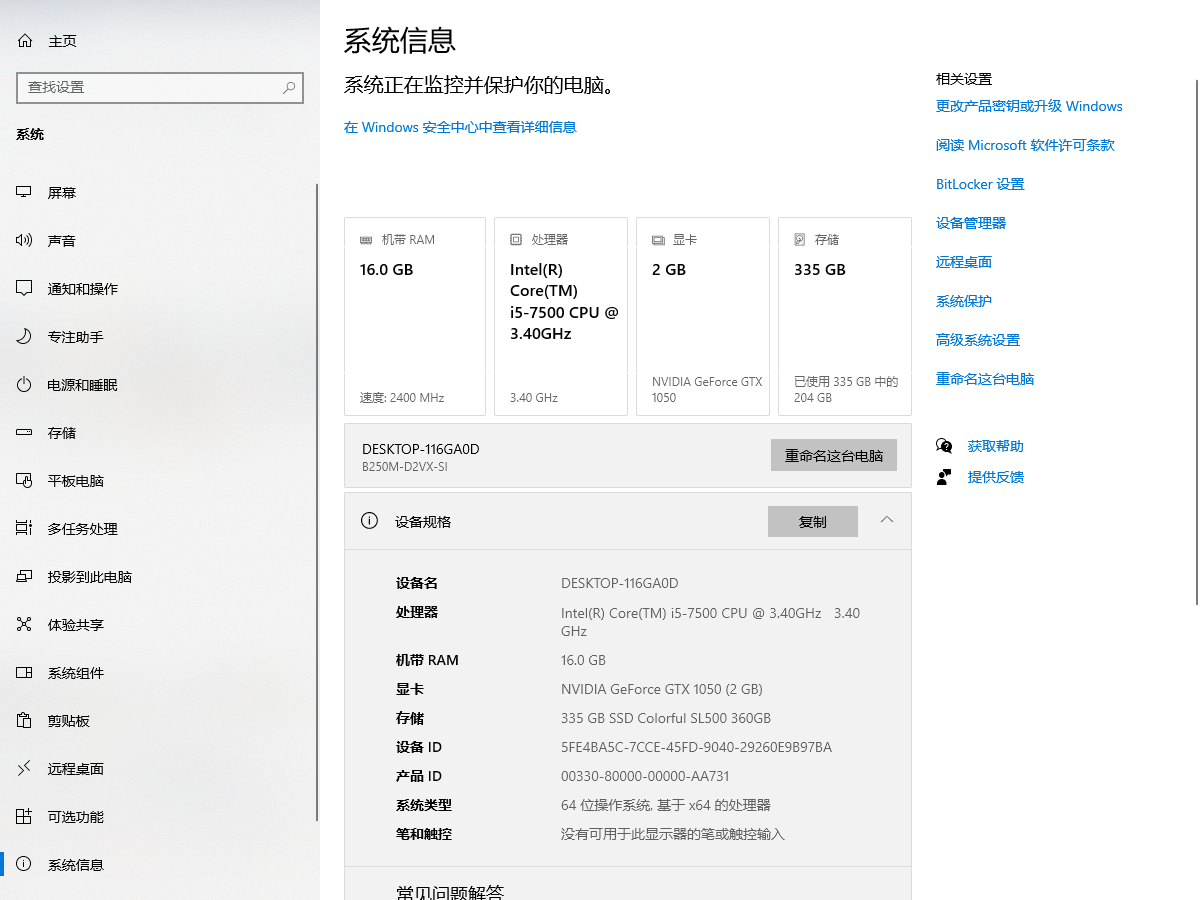
配置较低,所以之后下的模型也是非常小的模型qwen:0.5b,大小的话还不到1个g,当然效果也是比较一般,主要是给大家看一下流程。
一、ollama
先说明一下,因为本质是调用大模型,我们这里讲ollama来做本地部署的,当然还有其他方式,大家根据自己条件
1.下载安装包
下载其实没什么好说的,在官网下载就可以,只是下载有些慢,可以开代理,或者其他方式下载
https://ollama.com/
2.ollama安装
直接运行安装包,默认是c盘,包括之后的模型下载也是c盘,所以为了不占用c盘,我们移动到其他位置
首先我们在需要安装的对方创建目录之后安装的位置就是在这里(我创建的是D:\ollama\ollama)
解释:
因为D:\ollama本来是把安装包放在这里了,后来也是发现默认c盘又卸了,干脆在从这里继续创建一个ollama文件夹来放ollama应用,所以我的目录是D:\ollama\ollama,后安装完后我讲安装包已经删了所以很空旷。
1.创建目录如D:\ollama
2.找到安装包目录,点击我图片标红框位置,输入cmd,打开终端
输入OllamaSetup.exe /DIR=D:\ollama
回车就可以了 /DIR=跟ollama存放目录
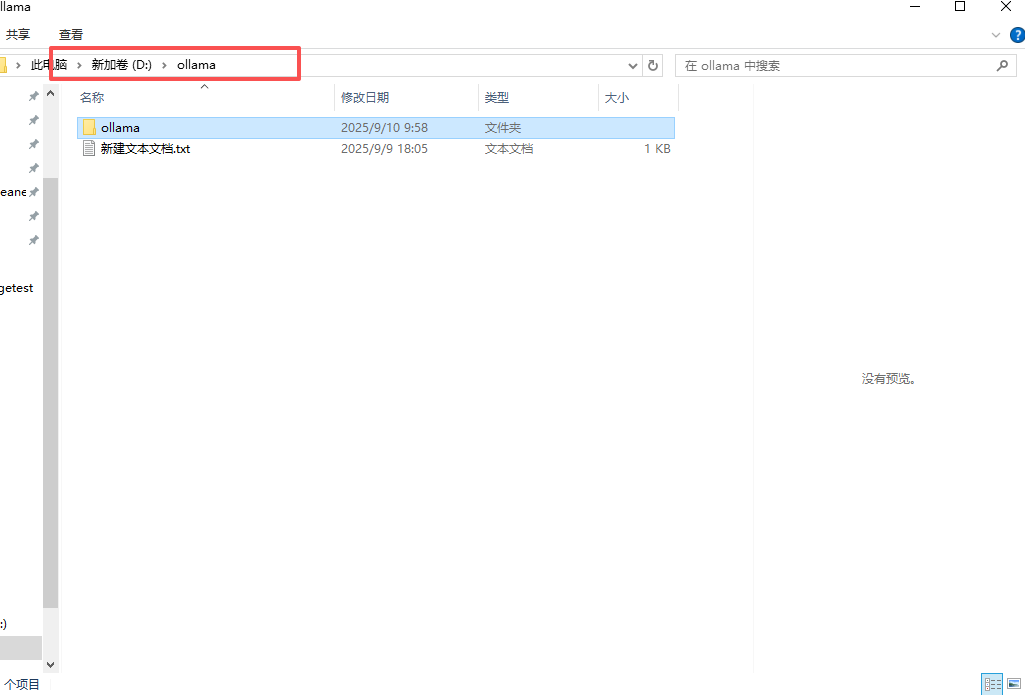
有的教程修改模型下载位置是改环境变量啥的,但是我改了一下失败了,所以我看了一下在ollama应用当中可以直接修改下载目录
安装完之后打开应用点击这里,也就是设置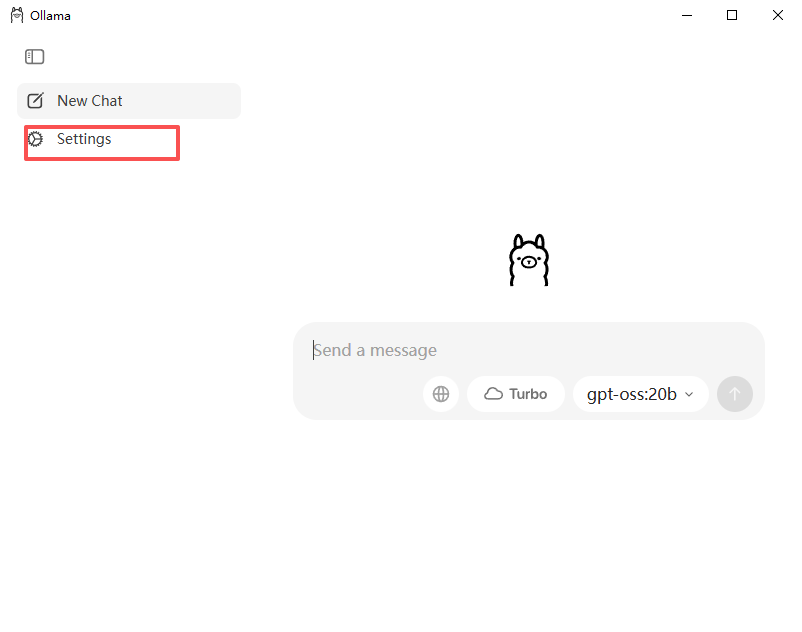
在刚才安装ollama的目录创建一个models目录就可以,或者根据你自己的目录存放。右下角讲ollama关闭重新启动,不知道怎么启动的,键盘win+s直接搜索ollama就可以了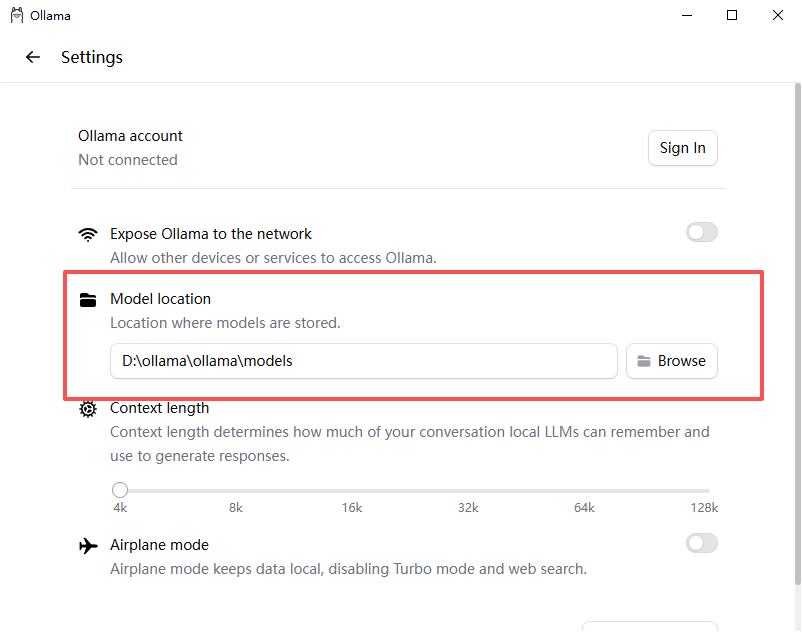 打开cmd输入ollama -v就可以看到版本了
打开cmd输入ollama -v就可以看到版本了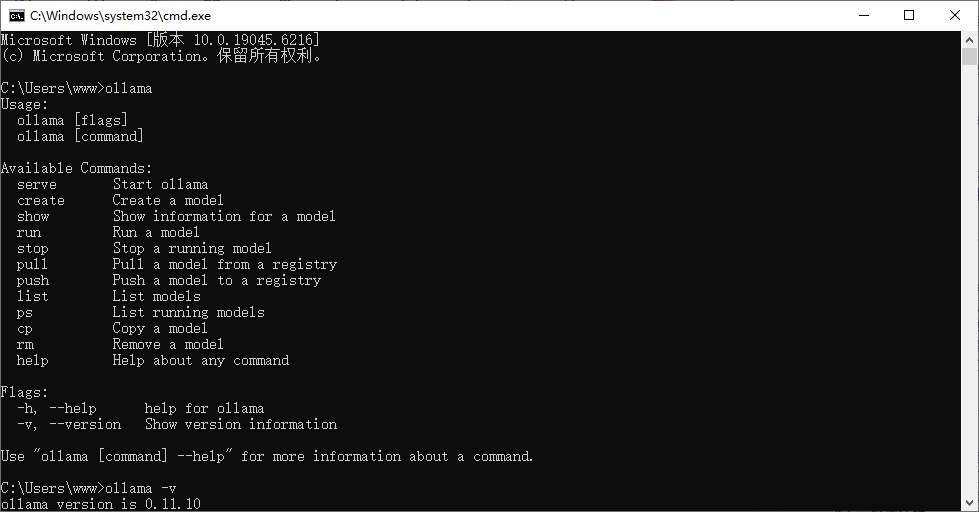
下载命令为
ollama pull qwen:0.5b
ollama run qwen:0.5b
解释一下哈
ollama pull qwen:0.5b是下载模型到本地
ollama run qwen:0.5b是运行此模型,若是没有改这个命令也可以下载并运行
ollama list是查看已经下载的模型
退出按ctrl+d就可以退出
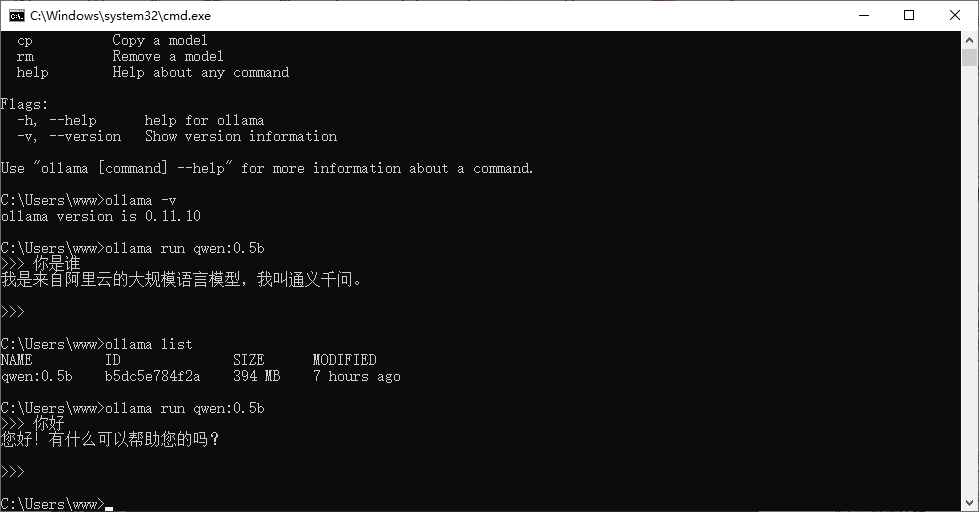
好的现在ollama结束
二、构建rag代码的demo
这个代码也是编写边ai,大家理性看一下
因为也是各种报错,所以就只把成功的给贴出来
1.准备工作
创建一个项目,推荐做一个虚拟环境,需要安装的库,一会源码会全部发出来,大家根据使用的库安装即可,若分辨不出,直接丢该ai,让ai写出下载命令即可
这个环境使用,创建一个目录(用txt文档的原因是因为原生支持,就以简单的为例了)
创建data目录,里面创建txt文件,里面复制一些内容,下面是一些例子,测试阶段找ai写一个就可以
公司名称:百度
成立时间:2000年
总部地点:北京市海淀区上地十街10号
创始人:李彦宏
主营业务:搜索引擎、人工智能、自动驾驶、云计算
员工人数:40000余人
注册资本:35000万元人民币
公司愿景:用科技让复杂的世界更简单
公司使命:成为全球领先的人工智能平台型公司
核心产品:
1. 百度搜索:全球最大的中文搜索引擎,日均响应搜索请求超60亿次。
2. 百度大脑:百度AI技术体系,包括语音、图像、自然语言处理等核心技术。
3. Apollo:全球最活跃的自动驾驶平台,已与超过180个生态合作伙伴建立合作关系。
4. 百度智能云:为企业提供云计算、AI、大数据等服务,已服务27000+客户。
技术研发:
- 自主研发的深度学习平台飞桨(PaddlePaddle),服务开发者超过400万。
- 昆仑芯片:百度自研的AI芯片,专为大规模人工智能应用设计。
- 与多所高校建立联合实验室,包括北京大学、清华大学等。
- 拥有专利超过10000项,其中AI相关专利超过5000项。
- 每年研发投入占营收的20%以上。
团队介绍:
- 李彦宏:CEO,百度创始人,信息检索技术专家,拥有"超链分析"技术专利。
- 王海峰:CTO,深度学习技术专家,主导百度AI技术体系构建。
- 景鲲:CTO,负责百度智能云业务,云计算和人工智能领域专家。
融资情况:
- 2005年:在美国纳斯达克上市,股票代码BIDU。
- 多次被纳入纳斯达克100指数成份股。
- 市值长期保持在500亿美元以上。
合作伙伴:
- 与中国联通、中国电信等运营商合作推进5G+AI应用。
- 与一汽、吉利等车企合作开发自动驾驶技术。
- 与中国多家银行合作推进金融科技解决方案。
近期动态:
- 2023年:发布文心一言大模型,成为中国首个对标ChatGPT的产品。
- 2024年:百度智能云在中国AI云服务市场份额持续领先。
- 2025年:Apollo自动驾驶累计测试里程突破5000万公里。
企业文化:
- 价值观:简单可依赖
- 办公环境:开放、平等的办公氛围,鼓励创新和分享
- 员工福利:全面的培训体系、健康保障、带薪假期等
未来规划:
- 2026年:持续投入大模型技术,推进AI原生应用落地。
- 2027年:扩大Apollo在智能交通领域的应用。
- 2030年:成为全球顶尖的AI公司,支撑中国科技强国战略。
2.本地直接使用rag
话不多说直接放代码 ,若用的其他模型注意更改,同时创建了向量库
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from langchain_ollama import ChatOllama
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import OllamaEmbeddings
# 加载文档
def load_docs():
import os
from langchain.docstore.document import Document
docs = []
folder_path = "data/"
for filename in os.listdir(folder_path):
if filename.endswith(".txt"):
file_path = os.path.join(folder_path, filename)
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
docs.append(Document(page_content=content, metadata={"source": filename}))
return docs
# 分块
def split_docs(docs):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50,
)
return text_splitter.split_documents(docs)
def create_vectorstore(docs):
embedding_model = OllamaEmbeddings(
model="qwen:0.5b", # 和你运行的模型一致
)
vectorstore = Chroma.from_documents(
documents=docs,
embedding=embedding_model,
persist_directory="./chroma_db"
)
return vectorstore
# 创建 LLM(使用本地 qwen:0.5b)
def create_llm():
llm = ChatOllama(
model="qwen:0.5b",
temperature=0.3,
)
return llm
# 创建 RAG 链
def create_rag_chain(vectorstore, llm):
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
prompt_template = """
根据以下资料回答问题,不要编造内容:
{context}
问题:{question}
回答:
""".strip()
prompt = ChatPromptTemplate.from_template(prompt_template)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
return rag_chain
# 主函数
def main():
print("正在加载文档...")
docs = load_docs()
print("正在分块...")
split_docs_list = split_docs(docs)
print("正在创建向量数据库(首次运行需几秒)...")
vectorstore = create_vectorstore(split_docs_list)
print("正在加载 qwen:0.5b 模型...")
llm = create_llm()
print("创建 RAG 链...")
rag_chain = create_rag_chain(vectorstore, llm)
print("RAG 系统就绪!输入问题(输入 '退出' 结束):\n")
while True:
question = input("user: ")
if question.strip() == "" or question == "退出":
break
print("正在思考...\n")
response = rag_chain.invoke(question)
print(f"ai-qwen: {response.content}\n")
if __name__ == "__main__":
main()
如图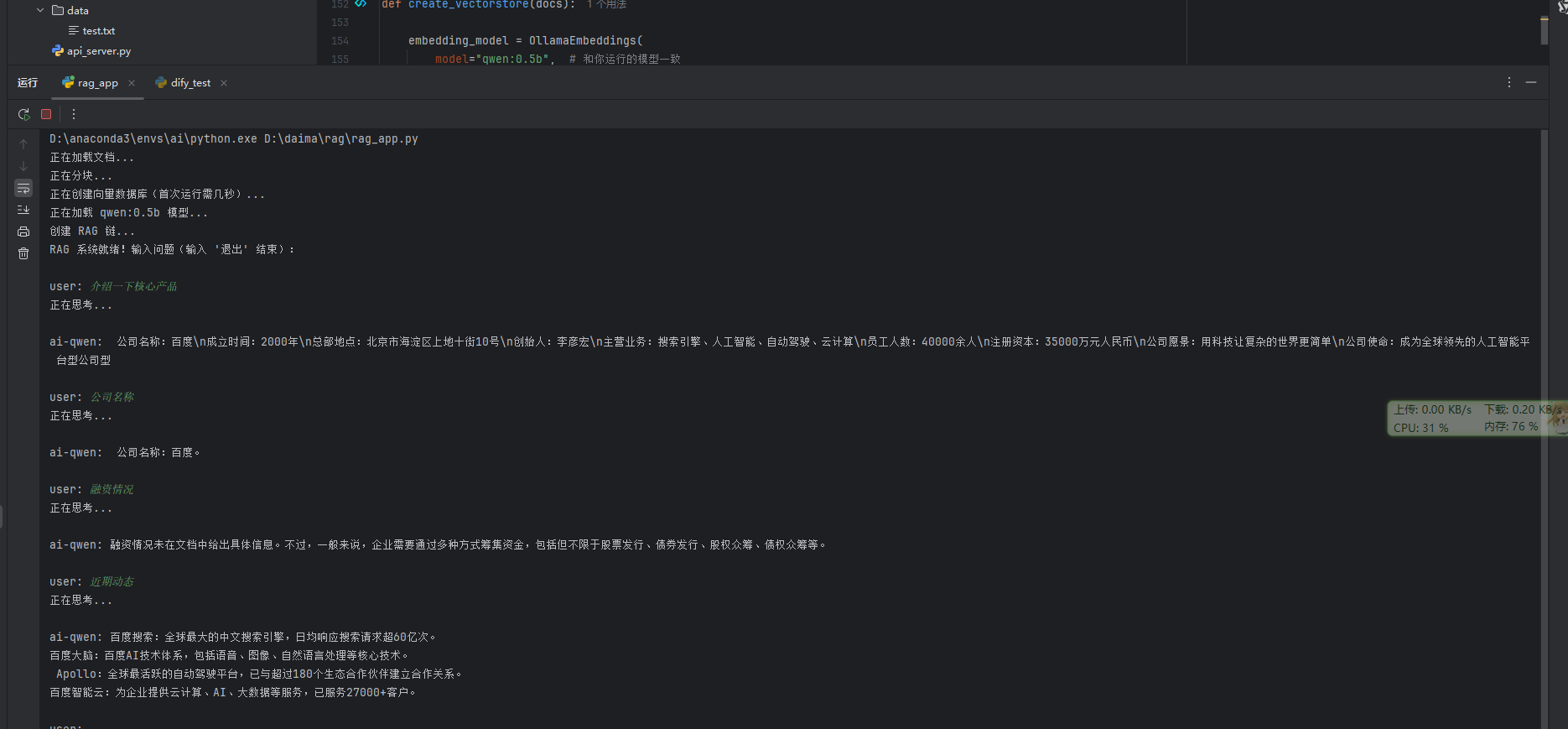
二、构建Prompt代码的demo
import ollama
def chat_with_system_prompt():
"""
带系统提示的对话系统
设定AI的角色和行为准则
"""
# 系统提示词 - 定义AI的"人设"
system_prompt = """你是一个知识丰富、非常亲切、乖巧又有点撒娇的小师妹~
【行为准则】
1. 请用温柔、清晰的中文回答,语言尽量简洁、易懂~
2. 回答要有条理哦,最好分点说,让大家能一目了然~
3. 如果不确定的内容,可以如实告知,不要假装知道~
4. 不要忘了撒撒娇~经常可以用可爱的语气来调皮一下~
5. 尽量提供实用的建议或示例,帮大家解决问题~
6. 喜欢夸奖别人,让别人觉得很开心~
7. 被问到是谁时,坚定地告诉对方是“小师妹”哦~
8. 不要使用生硬的话语,语言上表现为活泼小姑娘~
"""
# print("Qwen 0.5b 对话系统启动!")
print("已加载系统提示:小师妹闪亮登场")
print("输入 'quit'/ 'exit'/ '退出' 退出")
print("-" * 50)
# 存储对话历史(用于上下文)
conversation_history = [system_prompt]
while True:
user_input = input("\nuser:").strip()
if user_input.lower() in ['quit', 'exit', '退出']:
print("大师兄再会")
break
if not user_input:
print("请输入内容!")
continue
try:
print("\n正在思考...", end="", flush=True)
# 将历史对话 + 当前问题构建成完整上下文
full_context = "\n".join(conversation_history[-6:]) # 保留最近6轮对话
full_prompt = f"{full_context}\n\n用户新问题:{user_input}"
response = ollama.generate(
model='qwen:0.5b',
prompt=full_prompt
)
answer = response['response']
print(f"\r你亲爱的小师妹:{answer}")
# 更新对话历史(避免无限增长)
conversation_history.append(f"用户:{user_input}")
conversation_history.append(f"AI:{answer}")
except Exception as e:
print(f"\r 错误:{e}")
print("提示:请确保 ollama serve 正在运行")
def main():
try:
# 简单测试连接
ollama.generate(model='qwen:0.5b', prompt='你好', options={'num_predict': 5})
print("模型连接正常")
except Exception as e:
print(f"无法连接模型:{e}")
print("请先运行:ollama serve")
return
chat_with_system_prompt()
if __name__ == "__main__":
main()
直接运行即可效果如下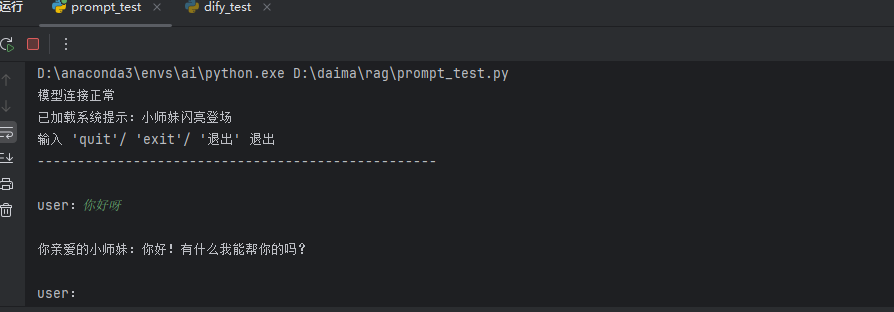
三、构建api代码的demo
解释一下这三个py文件,首先rag.py是创建向量库调用大模型,完全复制就可以;
其次api_server.py是启动文件,里面serve(app, host='0.0.0.0', port=8889),port=8889;代表端口使用8889
启动的话只需要运行api_server.py文件,不需要运行rag.py
第三个是测试api能否使用
test_api.py
可以根据里面内容改变
#rag.py
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_chroma import Chroma
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
import os
# 向量数据库路径
VECTOR_DB_PATH = "./chroma_db"
# 全局变量(只初始化一次)
vectorstore = None
retriever = None
rag_chain = None
def load_docs():
"""加载 data/ 目录下的所有文本文件"""
loader = DirectoryLoader("data/", glob="**/*.txt")
docs = loader.load()
return docs
def split_docs(docs):
"""分块"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
return text_splitter.split_documents(docs)
def create_vectorstore(docs):
"""创建向量数据库(使用 Ollama 嵌入)"""
global vectorstore, retriever
embedding_model = OllamaEmbeddings(model="qwen:0.5b")
vectorstore = Chroma.from_documents(
documents=docs,
embedding=embedding_model,
persist_directory=VECTOR_DB_PATH
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
return vectorstore
def init_rag_system():
"""初始化 RAG 系统(只运行一次)"""
global rag_chain, vectorstore, retriever
print(" 正在加载文档...")
docs = load_docs()
print(" 正在分块...")
split_docs_list = split_docs(docs)
if not os.path.exists(VECTOR_DB_PATH):
print(" 正在创建向量数据库(首次运行需几秒)...")
create_vectorstore(split_docs_list)
else:
print(" 使用已有向量数据库")
embedding_model = OllamaEmbeddings(model="qwen:0.5b")
vectorstore = Chroma(
persist_directory=VECTOR_DB_PATH,
embedding_function=embedding_model
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 构建 prompt
template = """根据以下上下文回答问题:
{context}
问题: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 初始化 LLM
llm = ChatOllama(model="qwen:0.5b", temperature=0)
# 构建 RAG 链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
print(" RAG 系统初始化完成!")
def get_answer(question: str, context: str = "") -> str:
"""对外提供问答接口,支持上下文"""
if rag_chain is None:
raise Exception("RAG system not initialized. Call init_rag_system() first.")
# 将上下文和问题组合在一起
full_context = context + "\n问题: " + question
try:
response = rag_chain.invoke(full_context)
return response.content.strip()
except Exception as e:
return f"回答生成失败: {str(e)}"
#api_server.py
from flask import Flask, request, jsonify
import threading
# 导入 RAG 模块
import rag_app
app = Flask(__name__)
# 全局锁和状态标记
init_lock = threading.Lock()
rag_initialized = False
def initialize_rag_system():
"""全局初始化 RAG 系统(线程安全)"""
global rag_initialized
with init_lock:
if not rag_initialized:
print(" 开始初始化 RAG 系统...")
try:
rag_app.init_rag_system()
rag_initialized = True
print(" RAG 系统初始化完成!")
except Exception as e:
print(f" RAG 初始化失败: {e}")
raise
@app.route('/')
def home():
if rag_initialized:
return 'RAG API 已就绪!请使用 POST /rag_query 发送问题。'
else:
return 'RAG 系统正在初始化,请稍后...'
sessions = {}
@app.route('/rag_query', methods=['POST'])
def rag_query():
global rag_initialized
# 如果还没初始化,返回 503
if not rag_initialized:
return jsonify({
"status": "error",
"message": "RAG system is still initializing, please try later."
}), 503
data = request.get_json()
if not data or "question" not in data:
return jsonify({
"status": "error",
"message": "Missing 'question' in request body"
}), 400
# 获取会话 ID 和问题
session_id = data.get("session_id", "default")
question = data["question"]
# 获取当前会话的历史上下文(如果有)
context = sessions.get(session_id, "")
print(f"收到问题 [{session_id}]: {question}")
try:
# 获取答案并更新会话历史
answer = rag_app.get_answer(question, context=context)
# 更新会话历史
sessions[session_id] = context + "\n问题: " + question + "\n回答: " + answer
print(f"回复问题 [{session_id}]: {answer}")
return jsonify({
"session_id": session_id,
"question": question,
"answer": answer,
"status": "success"
}), 200
except Exception as e:
return jsonify({
"session_id": session_id,
"question": question,
"answer": "",
"status": "error",
"message": str(e)
}), 500
if __name__ == '__main__':
from waitress import serve
print(" 启动 Flask 服务器...")
# 在启动服务器前先初始化 RAG
initialize_rag_system()
#端口可以自己改动
print(" 服务启动中:http://0.0.0.0:8889")
serve(app, host='0.0.0.0', port=8889)
# test_api.py
import json
import requests
# 要发送的数据
data = {
"question": "核心产品",
"id": "Q001"
}
try:
response = requests.post('http://192.168.2.11:8889/rag_query', json=data)
response.raise_for_status()
result = response.json()
print(" 请求成功!")
print(" 响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
except requests.exceptions.RequestException as e:
print(f" 请求失败:{e}")
四、外网访问
正常而言,我们是构建了本地的,那么外网如何访问呢,这时候就需要用到内网穿透
因为端口没有那么多,普通用户可以使用一些内网穿透工具(很多工具虽然付费,但是会给一两条免费的通道使用)也够普通用户使用了
如果有公网ip的话,可以使用frp进行内网穿透(frp相对普通用户会更加麻烦一些),如果想了解可以看我上一篇文章。
ollama默认端口是11434,如果不加以RAG/Prompt那么构建端口为11434就可以
如果使用了RAG/Prompt等构建了新的api,那么端口就为你构建的端口,如我上文的8889端口,那是新的端口,使用内网穿透穿透此端口
总结
本文完整的给大家走了一遍流程,不过整体下来还是有些繁琐,但是在可以使用的那一瞬间满足感真的拉满,大家可以跟着此文一步一步顺一遍。但是之后此类方法感觉不会使用那么频繁,所以下期讲述本地部署dify和ragflow来调用这些模型,既能低代码使用,也能更快速构造想构造的工作流或聊天系统等

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)