全网最全的pandas教学(包含17种处理函数)
带你畅游AI数据处理大门。全网最全的pandas教学(包含17种处理函数)
文章目录
- 1、pandas在AI应用中的重要性
- 2、常用函数
-
- pd.read_excel()
- df['城市'].unique().tolist()
- 列表推导式
- isin
- df.to_excel('', index=)
- with pd.ExcelWriter()
- df.info()
- pd.DataFrame()
- dict.fromkeys()
- df[''].value_counts()
- df.fillna('')
- df.merge()
- df.drop()
- pd.read_excel('', nrows = 10)
- unique()和nunique()
- df.isin()
- df.drop_duplicates(subset=[''], keep='first')
🍃作者介绍:双非本科大四网络工程专业在读,阿里云专家博主,前三年专注于Java领域学习,擅长web应用开发,目前已转行人工智能领域。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、pandas在AI应用中的重要性
在AI应用开发中,pandas作为数据处理的核心工具,扮演着数据预处理引擎和结构化数据分析桥梁的关键角色,其重要性主要体现在以下几个方面:
1️⃣ 数据预处理的基石作用
AI模型性能的70%依赖数据质量,而pandas为数据清洗与转换提供了高效解决方案:
- 缺失值处理:
fillna()、interpolate()等方法支持灵活填充策略(均值/中位数/前后项插值) - 异常值检测:结合
describe()统计描述与quantile()分位数分析,快速定位数据偏差 - 数据规范化:
apply()函数实现自定义数据转换逻辑(如归一化、标准化) - 特征编码:
get_dummies()一键生成独热编码,factorize()实现类别标签数字化
案例:在图像分类任务中,pandas可高效处理标注CSV文件,清洗错误标签并提取结构化特征(如图像尺寸、拍摄时间等元数据)。
2️⃣ 特征工程的加速器
pandas的矢量化操作和链式语法显著提升特征构建效率:
- 时间序列处理:
resample()重采样、rolling()滑动窗口计算(如移动平均) - 多表关联:
merge()实现SQL风格的JOIN操作,整合多源异构数据 - 分组聚合:
groupby().agg()支持复杂统计指标并行计算(如用户行为RFM分析) - 内存优化:
astype()类型转换可减少70%以上内存占用(如category类型优化)
示例代码:
features = (
raw_data.drop_duplicates()
.pipe(handle_outliers, columns=['sensor_value'])
.assign(log_value = lambda x: np.log(x['value']))
.groupby('device_id')
.agg({'temperature': ['mean', 'std'], 'vibration': 'max'})
)
3️⃣ 与AI技术栈的无缝集成
pandas在AI工具链中处于承上启下的关键位置:
- 上游对接:直接读取SQL/Hadoop/Spark数据(通过
read_sql/PySpark DataFrame转换) - 下游输出:DataFrame可零成本转为NumPy数组(
.values)或PyTorch/TensorFlow张量 - 可视化衔接:与Matplotlib/Seaborn深度集成,
df.plot()快速生成EDA图表 - 分布式扩展:通过Dask或Modin实现PB级数据并行处理(API兼容原生pandas)
典型工作流:
原始数据 → Pandas清洗 → 特征工程 → NumPy/Tensor转换 → 模型训练
4️⃣ 在特定AI领域的不可替代性
- 表格数据建模:XGBoost/LightGBM等树模型直接接受DataFrame输入,保留列名元信息
- 时序预测:
DatetimeIndex配合shift()生成滞后特征,构建LSTM/Prophet输入序列 - 推荐系统:处理用户-物品交互矩阵,计算协同过滤所需的共现矩阵
- NLP预处理:结构化存储文本元数据(作者/时间/情感标签),辅助多模态模型训练
5️⃣ 行业地位分析
- 开发者调研数据:2023年Kaggle调查显示,83%的数据科学家在日常工作中高频使用pandas
- 工具链生态:PyData生态核心组件,被Scikit-learn、PyTorch Lightning等框架官方推荐
- 学习曲线价值:成为AI工程师的入门必修工具,GitHub相关代码库年增长量超40%
6️⃣ 挑战与演进
尽管存在内存限制(10GB+数据需切换至Dask/Spark),但通过:
- 惰性计算优化:
eval()/query()提升计算效率 - 类型系统增强:Arrow后端支持更高效的内存管理
- GPU加速:通过 cuDF 实现GPU端DataFrame操作
pandas持续巩固其作为AI数据管道标准接口的地位,成为连接数据工程与模型开发的战略支点。
其直观的二维数据抽象,使得复杂的数据转换逻辑能以接近自然语言的方式表达,这正是AI工程化落地不可或缺的特性。
2、常用函数
import pandas as pd
下面就统一使用"pd"。
pd.read_excel()
查看源码:
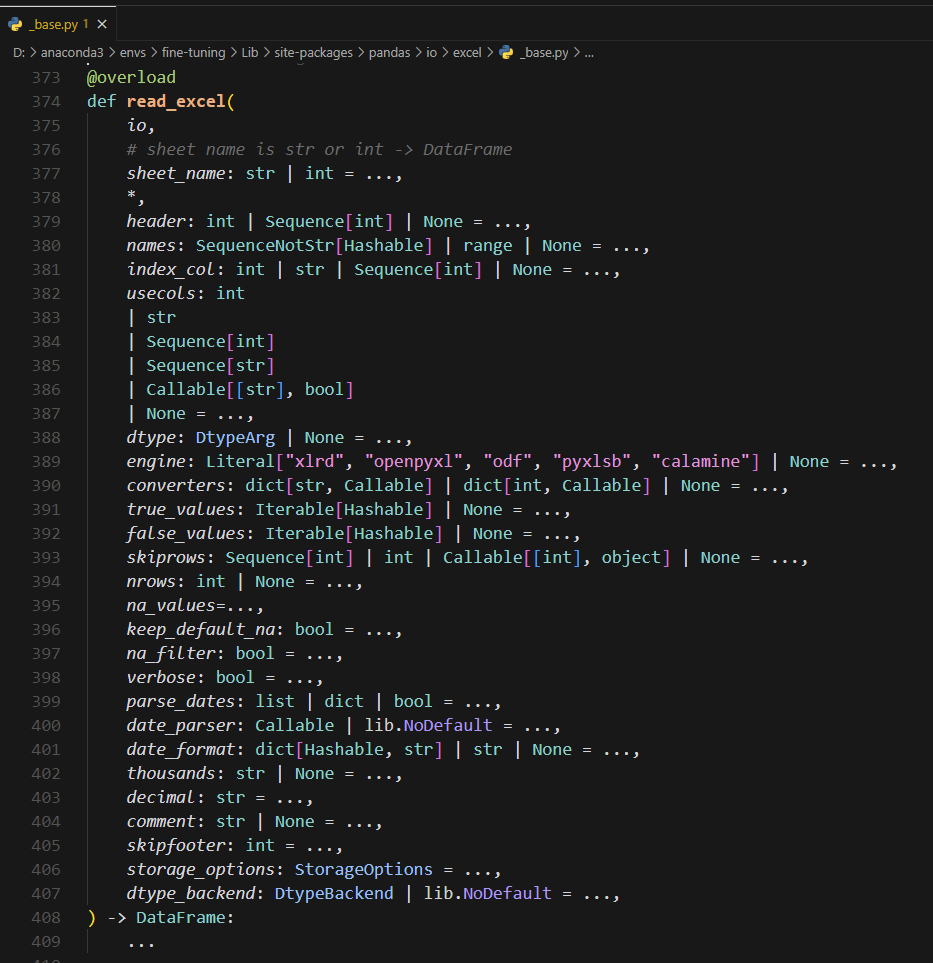
如下:
@overload
def read_excel(
io,
# sheet name is str or int -> DataFrame
sheet_name: str | int = ...,
*,
header: int | Sequence[int] | None = ...,
names: SequenceNotStr[Hashable] | range | None = ...,
index_col: int | str | Sequence[int] | None = ...,
usecols: int
| str
| Sequence[int]
| Sequence[str]
| Callable[[str], bool]
| None = ...,
dtype: DtypeArg | None = ...,
engine: Literal["xlrd", "openpyxl", "odf", "pyxlsb", "calamine"] | None = ...,
converters: dict[str, Callable] | dict[int, Callable] | None = ...,
true_values: Iterable[Hashable] | None = ...,
false_values: Iterable[Hashable] | None = ...,
skiprows: Sequence[int] | int | Callable[[int], object] | None = ...,
nrows: int | None = ...,
na_values=...,
keep_default_na: bool = ...,
na_filter: bool = ...,
verbose: bool = ...,
parse_dates: list | dict | bool = ...,
date_parser: Callable | lib.NoDefault = ...,
date_format: dict[Hashable, str] | str | None = ...,
thousands: str | None = ...,
decimal: str = ...,
comment: str | None = ...,
skipfooter: int = ...,
storage_options: StorageOptions = ...,
dtype_backend: DtypeBackend | lib.NoDefault = ...,
) -> DataFrame:
①基本参数:
io: # Excel文件路径或文件对象
sheet_name: str | int = 0 # 工作表名称或索引,默认为第一个工作表
header: int | Sequence[int] | None = 0 # 表头行号,默认为第一行
index_col: int | str | Sequence[int] | None = None # 索引列
②数据选择参数
usecols: # 要读取的列,可以是列索引、列名或函数
skiprows: # 跳过的行号
nrows: int | None = None # 读取的行数
skipfooter: int = 0 # 跳过末尾的行数
③数据解析参数
dtype: # 列的数据类型
na_values: # 识别为NA的值
parse_dates: # 需要解析为日期的列
converters: # 自定义列转换函数
thousands: str | None = None # 千位分隔符
decimal: str = "." # 小数点符号
④引擎参数
engine: Literal["xlrd", "openpyxl", "odf", "pyxlsb", "calamine"] | None
# Excel读取引擎,支持不同格式:
# - xlrd: 支持旧版.xls文件
# - openpyxl: 支持新版Excel格式
# - odf: 支持OpenDocument格式
# - pyxlsb: 支持二进制Excel格式
# - calamine: 支持多种Excel和OpenDocument格式
⑤常用示例:
# 基本读取
df = pd.read_excel("file.xlsx")
# 指定工作表
df = pd.read_excel("file.xlsx", sheet_name="Sheet2")
# 选择特定列
df = pd.read_excel("file.xlsx", usecols="A:C")
# 跳过行并指定类型
df = pd.read_excel(
"file.xlsx",
skiprows=2,
dtype={"A": int, "B": float}
)
# 处理日期列
df = pd.read_excel(
"file.xlsx",
parse_dates=["date_column"],
date_format="%Y-%m-%d"
)
对于引擎参数:
- 对于新版Excel文件(.xlsx),优先使用openpyxl
- 对于旧版Excel文件(.xls),使用xlrd
- 对于开源文档格式,使用odf
- 如果性能是主要考虑因素,可以尝试calamine
- 如果不确定,让pandas自动选择引擎
df[‘城市’].unique().tolist()
1 df_googleUK[‘城市’] - 获取DataFrame中的’城市’列
2 .unique() - 获取唯一值(去重)
3 .tolist() - 将结果转换为Python列表
常见用法:
# 基本用法 - 去重后转列表
cities = df['城市'].unique().tolist()
# 先排序再转列表
cities = df['城市'].unique().sort().tolist()
# 忽略空值
cities = df['城市'].dropna().unique().tolist()
# 转换为小写后去重
cities = df['城市'].str.lower().unique().tolist()
列表推导式
例如:
shop_postcode_normalized = [str(code).lower().replace(' ', '').replace(',', '')
for code in shop_postcode_list if pd.notna(code) and code != "Post Code"]
代码拆解:
shop_postcode_normalized = [
# 对每个code进行的处理
str(code) # 转换为字符串
.lower() # 转小写
.replace(' ', '') # 删除空格
.replace(',', '') # 删除逗号
# 条件筛选
for code in shop_postcode_list # 遍历原列表
if pd.notna(code) # 排除空值
and code != "Post Code" # 排除表头
]
isin
unmatched_postcodes_df = df[df['邮编地址'].isin(unmatched_postcodes_dict.keys())]
这段代码的作用是筛选出 df 中 '邮编地址' 列的值存在于 unmatched_postcodes_dict 的键中的所有行,并将这些行存储在新的 DataFrame unmatched_postcodes_df 中。
简而言之,它用于提取匹配特定条件的数据子集。
几个方法介绍:
isin()方法:- 用于检查某一列的值是否在指定的列表(或其他可迭代对象)中。
- 返回一个布尔数组,表示每个值是否满足条件。
- 字典的
.keys()方法:- 返回字典的键的视图。这些键可以作为
.isin()方法的输入,用于匹配。
- 返回字典的键的视图。这些键可以作为
- 布尔索引:
- 使用布尔数组对 DataFrame 进行索引,可以筛选出满足条件的行。
df.to_excel(‘’, index=)
对应这个代码,是把当前的DataFrame写入到Excel文件当中。
DataFrame是 pandas 库中最常用的数据结构之一,它是一种二维的表格数据结构,类似于 Excel 表格或者数据库中的表。每一列可以有不同的数据类型,比如整数、浮动、字符串等。
每一行和每一列都可以通过标签(索引)进行访问。
DataFrame的特点:
- 行和列: 数据以行和列的形式存储,可以使用标签访问行和列。
- 异构数据: 每列的数据类型可以不同,一列可以是整数,另一列可以是浮动,甚至字符串。
- 强大的索引功能: 每一行和每一列都有标签(可以是数字或者字符串),可以根据这些标签方便地访问数据。
- 数据处理: 提供了许多方法来进行数据处理、清洗、筛选、聚合等操作。
df.to_excel(‘保存的路径’, index=True、False)
这个代码是直接覆盖写入的,最终的Excel表格长什么样子,就取决于当前的df是什么样子。
with pd.ExcelWriter()
追加写入文件,而不是覆盖原有文件,可以通过ExcelWriter和mode='a'来实现追加写入。
示例如下:
with pd.ExcelWriter('data/未匹配到邮编的英国门店数据.xlsx', mode='a', engine='openpyxl') as writer:
unmatched_postcodes_df.to_excel(writer, index=False)
df.info()
在Pandas中,df.info()用于快速查看DataFrame的基本信息。
通过这个方法,可以了解数据集的一些基本结构,如数据的类型、缺失值的情况、每列的数据类型等。
执行df.info()时,通常会返回以下几项信息:
- DataFrame的总行数:显示DataFrame中数据的行数。
- 列的数量:显示DataFrame中列的总数。
- 每一列的名称:列出所有列名。
- 每一列的数据类型:显示每一列的数据类型(如
int64、float64、object等)。 - 非空值的数量:每一列中非空(非缺失)数据的数量。
- 内存占用:显示DataFrame占用的内存大小。
pd.DataFrame()
unmatched_df = pd.DataFrame({
'未匹配邮编': sorted(unmatched_original)
})
- pd.DataFrame(…):使用 Pandas 库创建一个新的 DataFrame。
- {‘未匹配邮编’: …}:这是一个字典,键为 ‘未匹配邮编’,值为排序后的 unmatched_original 列表。
- sorted(unmatched_original):对 unmatched_original 列表进行排序,以确保未匹配的邮政编码按字母顺序排列。
DataFrame是什么?
DataFrame 是 Pandas 库中最重要的数据结构之一,它用于存储和处理表格数据。可以将 DataFrame 想象成一个二维的表格,类似于电子表格或数据库表。
以下是 DataFrame 的一些关键特性:
- 二维数据结构:DataFrame 由行和列组成,行表示数据的记录,列表示数据的特征。
- 标签化的轴:每一列和每一行都有标签(索引),这使得数据的访问和操作更加方便。
- 多种数据类型:DataFrame 可以存储不同类型的数据,例如整数、浮点数、字符串等,每一列可以是不同的数据类型。
- 灵活的数据操作:Pandas 提供了丰富的函数和方法来对 DataFrame 进行操作,例如筛选、排序、分组、合并等。
- 与其他数据源的兼容性:DataFrame 可以方便地从多种数据源创建,例如 CSV 文件、Excel 文件、SQL 数据库等。
dict.fromkeys()
postal_code_dict_googleUK = dict.fromkeys(df_googleUK['邮政编码'], '')
解释:
- df_googleUK[‘邮政编码’]:
- 这是一个 Pandas DataFrame df_googleUK 中的列,包含了所有的邮政编码。通过 df_googleUK[‘邮政编码’],您可以获取这一列的所有值。
- dict.fromkeys(…):
- fromkeys() 是字典类的一个类方法,用于创建一个新字典。它接受两个参数:
- 第一个参数是一个可迭代对象(如列表、元组等),用于作为字典的键。
- 第二个参数是所有键的初始值。在这个例子中,所有键的初始值都被设置为空字符串 ‘’。
- postal_code_dict_googleUK:
- 这是新创建的字典,键是来自 df_googleUK[‘邮政编码’] 列的所有邮政编码,值都是空字符串 ‘’。这个字典可以用于后续的操作,例如存储与每个邮政编码相关的信息。
df[‘’].value_counts()
google_counts = df[''].value_counts()
解释:
- df[‘’]:这是一个 Pandas DataFrame df 中的列,包含了所有的谷歌数据编号。
- value_counts():用于计算 Series 中每个唯一值的出现次数。它返回一个新的 Series,其中索引是唯一值,值是这些唯一值的计数。
- google_counts:
- 这是一个新的 Series,包含了 谷歌数据编号 列中每个唯一编号的计数。索引是谷歌数据编号,值是对应的出现次数。
df.fillna(‘’)
fillna() 是 Pandas 中的一个方法,用于填充缺失值(NaN)。
所有的空值(NaN)会替换为一个空字符串 ‘’。
df.merge()
df_merged = df_final.merge(
df_google[['No'] + list(google_columns.keys())],
left_on='谷歌数据编号',
right_on='No',
how='left'
)
解释:
- df_final:
- 这是一个 Pandas DataFrame,包含了最终需要处理的数据,可能包含多个列和记录。
- df_google[[‘No’] + list(google_columns.keys())]:
- 这是对 df_google DataFrame 的选择操作。您选择了 No 列和 google_columns 字典中的所有键(列名)。
- google_columns.keys() 返回字典 google_columns 中的所有键,list(google_columns.keys()) 将其转换为列表。
- 通过 [[‘No’] + list(google_columns.keys())],您创建了一个新的 DataFrame,只包含 No 列和与谷歌相关的其他列。
- left_on=‘谷歌数据编号’:
- 这是指定在 df_final DataFrame 中用于合并的列名。在这个例子中,您使用 谷歌数据编号 列作为左侧 DataFrame 的合并键。
- right_on=‘No’:
- 这是指定在 df_google DataFrame 中用于合并的列名。在这个例子中,您使用 No 列作为右侧 DataFrame 的合并键。
- how=‘left’:
- 这是指定合并的方式。在这个例子中,使用 left 表示左连接(left join)。这意味着合并结果将包含 df_final 中的所有行,即使在 df_google 中没有匹配的行。如果没有匹配的行,合并结果中的相关列将填充为 NaN。
- df_merged:
- 这是合并后的结果 DataFrame,包含了来自 df_final 和 df_google 的数据。合并的结果将根据指定的键(谷歌数据编号 和 No)进行匹配。
df.drop()
df_merged = df_merged.drop(['No_x', 'No_y'], axis=1)
解释:
- df_merged:
- 这是一个 Pandas DataFrame,包含了之前合并后的数据,可能包含多个列和记录。
- drop([‘No_x’, ‘No_y’], axis=1):
- drop() 是 Pandas 中的一个方法,用于删除指定的行或列。
- [‘No_x’, ‘No_y’] 是要删除的列名列表。在合并操作中,如果两个 DataFrame 中都有名为 No 的列,Pandas 会自动为它们添加后缀以区分,通常是 _x 和 _y。因此,No_x 和 No_y 分别表示来自左侧和右侧 DataFrame 的 No 列。
- axis=1 表示要删除的是列。如果设置为 axis=0,则表示删除行。
pd.read_excel(‘’, nrows = 10)
df = pd.read_excel(origin_excel_path, nrows=10)
nrows=10:指定只读取文件中的前 10 行数据。
unique()和nunique()
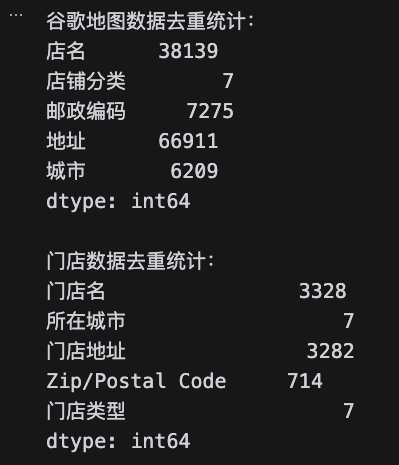
df.unique()和df.nunique(),表示对整个对象的每一列进行去重统计,比如:
# 统计谷歌地图数据各列去重数量
print("谷歌地图数据去重统计:")
print(df_googleMap_Germany.nunique())
print("\n门店数据去重统计:")
print(df_shop_Germany.nunique())
df.isin()
unmatched_stores = df_shop_Germany[df_shop_Germany['Zip/Postal Code'].isin(not_match_postcodes)]
这行代码的作用是从 df_shop_Germany 数据框中提取所有邮政编码不在 not_match_postcodes 集合中的门店记录。
具体来说:
- df_shop_Germany[‘Zip/Postal Code’].isin(not_match_postcodes) 会返回一个布尔系列,指示每个门店的邮政编码是否在 not_match_postcodes 中。
- 使用这个布尔系列来索引 df_shop_Germany,从而得到所有未匹配的门店信息。
df.drop_duplicates(subset=[‘’], keep=‘first’)
google_unique = google.drop_duplicates(subset=['地址'], keep='first')
这行代码的作用是从 google 数据框中删除重复的地址记录,具体说明如下:
- drop_duplicates(subset=[‘地址’], keep=‘first’) 方法用于去除重复行。
- subset=[‘地址’] 指定了要检查重复的列,这里是“地址”列。
- keep=‘first’ 表示在遇到重复时,保留第一次出现的记录,删除后续的重复记录。
最终,google_unique 将包含所有唯一的地址记录,确保每个地址只保留一条记录。这在进行数据合并时非常重要,以避免因重复地址导致的多对多匹配问题。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)