LLM大模型实践6-信息提取
信息提取是自然语言处理(NLP)的重要组成部分,它帮助我们从文本中抽取特定的、我们关心的信 息。在接下来的示例中,我们将要求模型识别两个关键元素: 购买的商品和商品的制造商。想象一下,如果你正在尝试分析一个在线电商网站上的众多评论,了解评论中提到的商品是什么、由谁 制造,以及相关的积极或消极情绪,将极大地帮助你追踪特定商品或制造商在用户心中的情感趋势。在接下来的示例中,我们会要求模型将回应以一个
信息提取是自然语言处理(NLP)的重要组成部分,它帮助我们从文本中抽取特定的、我们关心的信 息。我们将深入挖掘客户评论中的丰富信息。在接下来的示例中,我们将要求模型识别两个关键元素: 购买的商品和商品的制造商。
想象一下,如果你正在尝试分析一个在线电商网站上的众多评论,了解评论中提到的商品是什么、由谁 制造,以及相关的积极或消极情绪,将极大地帮助你追踪特定商品或制造商在用户心中的情感趋势。
在接下来的示例中,我们会要求模型将回应以一个 JSON 对象的形式呈现,其中的 key 就是商品和品牌。
商品信息提取
# 中文
prompt = f"""
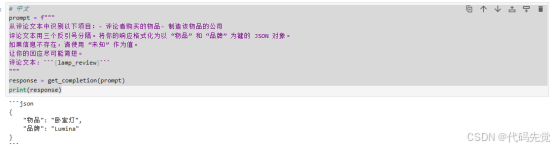
从评论文本中识别以下项目:- 评论者购买的物品- 制造该物品的公司
评论文本用三个反引号分隔。将你的响应格式化为以 “物品” 和 “品牌” 为键的 JSON 对象。
如果信息不存在,请使用 “未知” 作为值。
让你的回应尽可能简短。
评论文本: ```{lamp_review}```
"""
response = get_completion(prompt)
print(response)
综合情感推断和信息提取
# 中文
prompt = f"""
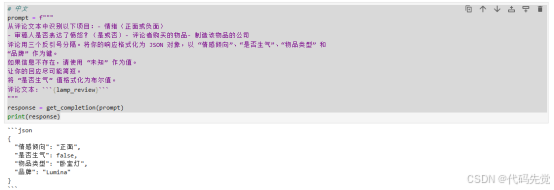
从评论文本中识别以下项目:- 情绪(正面或负面)
- 审稿人是否表达了愤怒?(是或否)- 评论者购买的物品- 制造该物品的公司
评论用三个反引号分隔。将你的响应格式化为 JSON 对象,以 “情感倾向”、“是否生气”、“物品类型” 和
“品牌” 作为键。
如果信息不存在,请使用 “未知” 作为值。
让你的回应尽可能简短。
将 “是否生气” 值格式化为布尔值。
评论文本: ```{lamp_review}```
"""
response = get_completion(prompt)
print(response)
主题推断
# 中文
story = """
在政府最近进行的一项调查中,要求公共部门的员工对他们所在部门的满意度进行评分。
调查结果显示,NASA 是最受欢迎的部门,满意度为 95%。
一位 NASA 员工 John Smith 对这一发现发表了评论,他表示:
“我对 NASA 排名第一并不感到惊讶。这是一个与了不起的人们和令人难以置信的机会共事的好地方。我为成
为这样一个创新组织的一员感到自豪。”
NASA 的管理团队也对这一结果表示欢迎,主管 Tom Johnson 表示:
“我们很高兴听到我们的员工对 NASA 的工作感到满意。
我们拥有一支才华横溢、忠诚敬业的团队,他们为实现我们的目标不懈努力,看到他们的辛勤工作得到回报是太
棒了。”
调查还显示,社会保障管理局的满意度最低,只有 45%的员工表示他们对工作满意。
政府承诺解决调查中员工提出的问题,并努力提高所有部门的工作满意度。
"""
推断讨论主题
# 中文
prompt = f"""
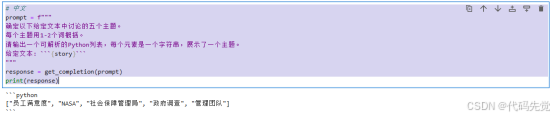
确定以下给定文本中讨论的五个主题。
每个主题用1-2个词概括。
请输出一个可解析的Python列表,每个元素是一个字符串,展示了一个主题。
给定文本: ```{story}```
"""
response = get_completion(prompt)
print(response)
为特定主题制作新闻提醒
# 中文
prompt = f"""
判断主题列表中的每一项是否是给定文本中的一个话题,
以列表的形式给出答案,每个元素是一个Json对象,键为对应主题,值为对应的 0 或 1。
主题列表:美国航空航天局、当地政府、工程、员工满意度、联邦政府
给定文本: ```{story}```
"""
response = get_completion(prompt)
print(response)


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)