阿里再开源多模态大模型Qwen2.5-Omni
多模态模型成为了研究与应用的热门领域。其中,阿里巴巴团队研发的 Qwen2.5-Omni 脱颖而出,以其创新的架构设计、卓越的性能表现以及丰富的应用场景,为多模态交互带来了全新的解决方案,引领着人工智能迈向更加智能、自然的交互时代。
多模态模型成为了研究与应用的热门领域。其中,阿里巴巴团队研发的 Qwen2.5-Omni 脱颖而出,以其创新的架构设计、卓越的性能表现以及丰富的应用场景,为多模态交互带来了全新的解决方案,引领着人工智能迈向更加智能、自然的交互时代。
一、Qwen2.5-Omni 的架构创新
Qwen2.5-Omni 采用了独特的 Thinker-Talker 架构,这一架构设计的核心在于实现了端到端的多模态感知与交互。它能够同时处理文本、图像、音频和视频等多种模态的输入信息,并以流式的方式生成文本和自然语音响应,打破了传统模型在处理多模态信息时的局限性,极大地提升了交互的实时性与流畅性。
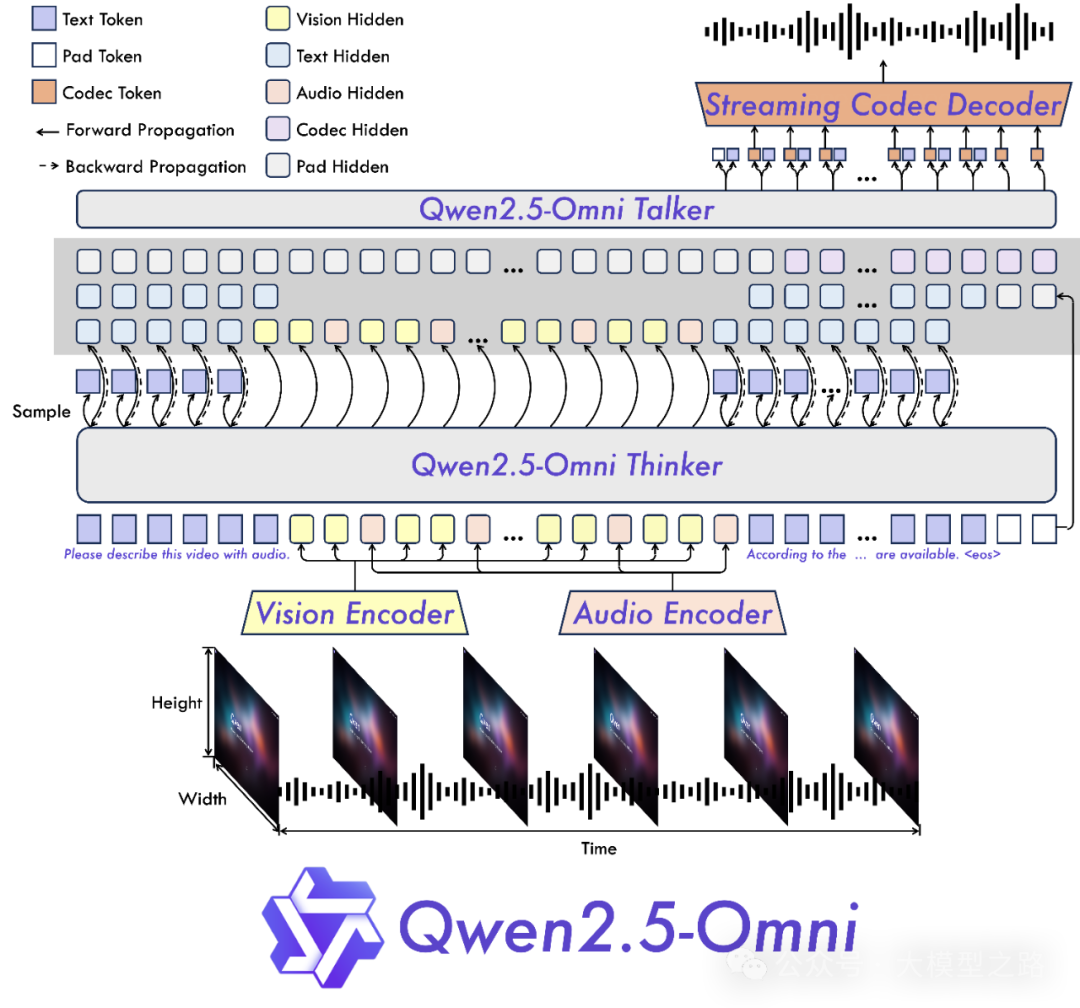
在这一架构中,时间对齐多模态旋转位置嵌入(TMRoPE)技术尤为关键。在处理视频和音频输入时,不同模态的信息往往存在时间戳上的差异,这会影响模型对信息的准确理解和处理。TMRoPE 通过创新的位置嵌入方式,能够精确地同步视频输入与音频的时间戳,确保模型在处理多模态信息时,各个模态之间的时间关系得到准确表达,从而更精准地融合不同模态的数据,提升模型对复杂场景的理解和处理能力。这种创新的架构设计为 Qwen2.5-Omni 在多模态交互领域的卓越表现奠定了坚实基础。
二、卓越的性能表现
(一)跨模态综合优势
Qwen2.5-Omni 在性能上展现出了跨模态的强大优势。与同规模的单模态模型相比,它在各个模态的任务中都表现出色。在音频能力方面,超越了类似规模的 Qwen2-Audio,在语音识别、音频理解等任务上展现出更高的准确率和更好的理解能力;在图像和视频处理方面,与 Qwen2.5-VL-7B 相比,能够实现相当的性能表现,无论是图像推理还是视频理解,都能准确地分析和解读相关信息。
在综合多模态任务的 OmniBench 基准测试中,Qwen2.5-Omni 更是取得了领先的成绩。这一成绩的背后,是模型强大的多模态融合能力,它能够有效地整合不同模态的信息,进行全面而深入的分析,从而在复杂的多模态任务中展现出卓越的性能,为用户提供更加准确和有用的回答。
(二)单模态任务的出色表现
在单模态任务中,Qwen2.5-Omni 同样成绩斐然。在语音识别任务(如 Common Voice 数据集测试)中,它能够准确地将语音转换为文本,识别准确率高,对不同口音和语言环境的适应性强;在翻译任务(如 CoVoST2 数据集测试)中,无论是从语音到文本的翻译,还是文本之间的翻译,都能提供高质量的翻译结果,语言表达自然流畅。
在音频理解任务(MMAU)中,Qwen2.5-Omni 能够深入理解音频中的语义信息,不仅能够识别语音内容,还能分析语音中的情感、意图等深层次信息;在图像推理任务(MMMU、MMStar)中,它能够对图像中的物体、场景、关系等进行准确推理,理解图像的含义并进行合理的预测;在视频理解任务(MVBench)中,能够处理动态的视频信息,理解视频中的动作、事件发展等内容。在语音生成任务(Seed-tts-eval 和主观自然度评估)中,生成的语音自然、流畅,与人类语音高度相似,在鲁棒性和自然度方面超越了许多现有的模型。
(三)端到端语音指令执行能力
Qwen2.5-Omni 在端到端语音指令跟随方面表现出色,通过 MMLU、GSM8K 等基准测试可以发现,其在理解和执行语音指令方面的性能与处理文本输入指令的效果相当。这意味着用户可以通过自然的语音指令与模型进行交互,无论是复杂的问题求解、任务执行还是信息查询,Qwen2.5-Omni 都能够准确理解用户意图,并给出合适的回应,极大地提升了用户与模型交互的便捷性和效率。
三、便捷的使用方法与工具
(一)安装与环境配置
为了使用 Qwen2.5-Omni,用户需要进行一系列的安装和环境配置工作。由于其在 Hugging Face Transformers 上的代码处于拉取请求阶段,尚未合并到主分支,因此用户可能需要从源代码构建安装。首先,使用pip uninstall transformers命令卸载已安装的 transformers 库,然后通过pip install git+https://github.com/huggingface/transformers@3a1ead0aabed473eafe527915eea8c197d424356命令安装特定版本的 transformers 库,同时还需要安装accelerate库以优化模型运行性能。
为了更方便地处理各种音频和视觉输入,Qwen2.5-Omni 提供了qwen-omni-utils工具包。在安装该工具包时,如果系统安装了ffmpeg,并且希望更快地加载视频,可以使用pip install qwen-omni-utils[decord]命令进行安装,decord库能够加速视频处理。如果用户的系统不是 Linux,可能无法从 PyPI 安装decord,此时可以使用pip install qwen-omni-utils命令,该命令会回退到使用torchvision进行视频处理。当然,用户也可以从源代码安装decord以在加载视频时使用它。
(二)使用示例
在使用 Qwen2.5-Omni 进行多模态交互时,用户可以参考以下代码示例:
import soundfile as sf
from transformers import Qwen2_5OmniModel, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# 加载模型
model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
# 构建对话
conversation = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."
},
{
"role": "user",
"content": [{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"}]
}
]# 数据预处理
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=True)
inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True)inputs =
inputs.to(model.device).to(model.dtype)
# 推理
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write("output.wav", audio.reshape(-1).detach().cpu().numpy(), samplerate=24000)
在这段代码中,首先加载了 Qwen2.5-Omni 模型和处理器,然后构建了一个包含视频输入的对话。通过process_mm_info函数处理多模态信息,将对话内容转换为模型能够处理的输入格式。在推理阶段,模型根据输入生成文本和音频输出,最后将生成的文本打印出来,并将音频保存为output.wav文件。
四、使用技巧与注意事项
(一)音频输出设置
如果用户需要音频输出,系统提示必须设置为特定内容:“You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.” 否则,音频输出可能无法正常工作。这是因为模型在处理音频输出时,需要根据特定的系统提示来激活相应的语音生成功能,确保生成的语音符合预期的角色设定和交互逻辑。
(二)视频音频使用
在多模态交互过程中,视频通常会伴随着音频信息,这些音频信息对于模型理解视频内容、提供更好的交互体验至关重要。因此,Qwen2.5-Omni 提供了相关参数来控制是否使用视频中的音频。在数据预处理阶段,通过audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)设置使用视频中的音频;在模型推理阶段,通过text_ids, audio = model.generate(**inputs, use_audio_in_video=True)确保模型在生成输出时考虑视频音频信息。需要注意的是,在多轮对话中,这两个地方的use_audio_in_video参数必须设置相同,否则可能会出现意外结果,影响模型对多模态信息的准确处理。
(三)是否使用音频输出
Qwen2.5-Omni 支持文本和音频两种输出方式。如果用户不需要音频输出,可以在from_pretrained函数中设置enable_audio_output=False,这样可以节省大约 2GB 的 GPU 内存。但需要注意的是,此时generate函数中的return_audio选项只能设置为False。为了获得更灵活的使用体验,建议用户在初始化模型时将enable_audio_output设置为True,然后在调用generate函数时根据实际需求决定是否返回音频。当return_audio设置为False时,模型将只返回文本输出,能够更快地获得文本响应。
(四)输出音频的语音类型更改
Qwen2.5-Omni 支持更改输出音频的语音类型,“Qwen/Qwen2.5-Omni-7B” 检查点支持两种语音类型:Chelsie(女性语音,声音甜美、柔和,带有温柔的温暖和明亮的清晰度)和 Ethan(男性语音,声音明亮、乐观,充满感染力,给人温暖、亲切的感觉)。用户可以通过generate函数的spk参数指定语音类型,默认情况下,如果不指定spk参数,将使用 Chelsie 语音类型。例如:
text_ids, audio = model.generate(**inputs, spk="Chelsie")
text_ids, audio = model.generate(**inputs, spk="Ethan")
(五)使用 Flash-Attention 2 加速
为了进一步提升模型的生成速度,Qwen2.5-Omni 支持使用 Flash-Attention 2 技术。首先,用户需要确保安装了最新版本的 Flash-Attention 2,可以使用pip install -U flash-attn --no-build-isolation命令进行安装。同时,硬件需要与 Flash-Attention 2 兼容,具体信息可以参考 Flash-Attention 官方文档。Flash-Attention 2 只能在模型以torch.float16或torch.bfloat16加载时使用。在加载模型时,添加attn_implementation="flash_attention_2"参数即可启用该技术,例如:
from transformers import Qwen2_5OmniModel
model = Qwen2_5OmniModel.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
)
Qwen2.5-Omni 作为一款创新的多模态模型,以其独特的架构设计、卓越的性能和丰富的使用功能,为多模态交互领域带来了新的突破和发展方向。它不仅在当前的人工智能研究和应用中展现出巨大的潜力,也为未来的智能交互发展奠定了坚实基础。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献314条内容
已为社区贡献314条内容

所有评论(0)