带你从入门到精通——自然语言处理(一. 文本的基本预处理方法和张量表示)
词嵌入(word embedding)指一种将词汇映射到低维稠密向量空间的方法,经过词嵌入后得到的词向量能够在不同的下游NLP任务之间共享(即进行迁移学习),但是无法很好地表示一些低频词和未知词。word2vec是一种常见的无监督词嵌入方法,它利用自身的文本信息来构建伪标签,并使用全连接神经网络进行训练,其中隐藏层的权重参数矩阵将作为最终的词向量矩阵,这些低维稠密的向量能够有效地捕捉词与词之间的语
目录
一. 文本的基本预处理方法和张量表示
文本预处理是指在自然语言处理(Natural Language Processing,NLP)任务中,针对原始文本进行清洗、转换、标准化等一系列预处理的过程,是NLP工作流程中至关重要的第一步,旨在去除文本数据中与任务无关或者冗余的部分,提高文本数据的质量和可用性。
1.1 文本的基本预处理方法
1.1.1 分词
分词就是指将连续的文本数据拆分成词、子词或字符等基本单元(一个基本单元也被称为一个token)的过程,是文本预处理的第一步,能够帮助我们更好地理解文本数据的结构和含义并且为其他各种NLP下游任务提供数据支持。
中文的分词通常使用jieba(结巴)来实现,它支持精确模式、全模式和搜索引擎模式三种分词模式,具体示例如下:
import jieba
def demo01():
sentence = '哪吒二之魔童闹海的票房突破一百亿'
print(list(jieba.cut(sentence, cut_all=False))) # 精确模式,参数cut_all默认为False
print(jieba.lcut(sentence, cut_all=True)) # 全模式
print(jieba.lcut_for_search(sentence)) # 搜索引擎模式
if __name__ == '__main__':
demo01()
'''
['哪吒', '二之魔童', '闹海', '的', '票房', '突破', '一百亿']
['哪吒', '二', '之', '魔', '童', '闹海', '的', '票房', '突破', '一百', '一百亿', '百亿']
['哪吒', '二之魔童', '闹海', '的', '票房', '突破', '一百', '百亿', '一百亿']
'''其中精确模式分词是指试图以人类的思维识别句子中的词语并将句子最精确地切分开;全模式分词是指将句子中所有可以成词的词语全部切分出来;搜索引擎模式分词是指在精确模式的基础上,对长词再次切分。
注意:每种分词模式都有cut和lcut两种切分方法,其中cut方法返回一个生成器对象(可以使用list()方法将其转换为列表),而lcut方法返回一个列表。
此外,jieba还可以预先加载用户自定义词典,加载词典后jiaba能够准确地识别出词典中出现过的词汇,词典的格式为每一行分三部分:词语、词频(可省略)、词性(可省略),各个部分用空格隔开且顺序不可颠倒,词典格式示例如下:
哪吒二之魔童闹海 1 n
一百亿 1 n分词示例代码如下:
import jieba
def demo01():
sentence = '哪吒二之魔童闹海的票房突破一百亿'
jieba.load_userdict('data/userdict.txt') # 加载用户自定义词典
print(list(jieba.cut(sentence, cut_all=False)))
print(jieba.lcut(sentence, cut_all=True))
print(jieba.lcut_for_search(sentence))
if __name__ == '__main__':
demo01()
'''
['哪吒二之魔童闹海', '的', '票房', '突破', '一百亿']
['哪吒', '哪吒二之魔童闹海', '闹海', '的', '票房', '突破', '一百', '一百亿', '百亿']
['哪吒', '闹海', '哪吒二之魔童闹海', '的', '票房', '突破', '一百', '百亿', '一百亿']
'''注意:对于中国香港、中国台湾等地区所使用的繁体字文本jiaba同样可以对其进行分词。
1.1.2 命名实体识别
命名实体识别(Named Entity Recognition,NER)是指从文本数据中识别出特定类别的具体实体名称(如人名、地名、机构名、日期、时间等),对文本数据进行命名实体识别可以帮助我们好地理解文本数据的结构和含义并且为其他各种NLP下游任务提供数据支持。
1.1.3 词性标注
词性标注(Part-Of-Speech tagging,POS)是指为分词后的文本数据中的每个词分配一个语法类别(即词性),例如名词、动词、形容词等。对文本数据进行词性标注可以帮助我们好地理解文本数据的结构和含义并且为其他各种NLP下游任务提供数据支持,此外还可以消除词的歧义,例如单词'lead'可能是动词(意为引导)也可能是名词(意为铅)。
常见词性表示有:名词 n;动词 v;形容词 a;副词 d;代词 r;介词 p。
POS和NER的示例如下:
import jieba.posseg as pseg
def demo02():
sentence = '周杰伦在唱青花瓷'
named_entities = []
words = pseg.lcut(sentence)
print(words)
# [pair('周杰伦', 'nr'), pair('在', 'p'), pair('唱', 'v'), pair('青花瓷', 'n')]
# 列表中的元素为一个pair对象
for word, flag in words:
if flag in ['nr', 'n']:
named_entities.append(word)
print(named_entities)
if __name__ == '__main__':
demo02() # ['周杰伦', '青花瓷']1.2 文本的张量表示
文本数据的张量表示是指将文本数据表示成张量形式,即通过向量表示分词后的每个token,称为词向量,各个词向量按顺序组成文本数据的张量表示。
1.2.1 独热编码
独热编码,也叫one-hot编码,该编码方法会将每个单词表示为一个唯一的稀疏向量,该稀疏向量的长度等于词汇表的大小,并且其中只有一个位置的值为1,其他位置的值为0,具体示例如下:
import joblib
from tensorflow.keras.preprocessing.text import Tokenizer
def demo03():
vocabularies = ['哪吒', '敖丙', '太乙真人', '申公豹', '申小豹', '申正道']
n = len(vocabularies)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(vocabularies)
joblib.dump(tokenizer, 'data/tokenizer')
tokenizer = joblib.load('data/tokenizer')
print(tokenizer.word_index)
# {'哪吒': 1, '敖丙': 2, '太乙真人': 3, '申公豹': 4, '申小豹': 5, '申正道': 6}
print(tokenizer.index_word)
# {1: '哪吒', 2: '敖丙', 3: '太乙真人', 4: '申公豹', 5: '申小豹', 6: '申正道'}
one_hot_vocabs = [[0] * n for _ in range(n)]
for i, v in enumerate(vocabularies):
idx = tokenizer.word_index[v] - 1
one_hot_vocabs[i][idx] = 1
print(one_hot_vocabs)
# [[1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0],
# [0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 1]]
token = '敖丙'
idx = tokenizer.word_index[token] - 1
print(f'{token}的独热编码为: {one_hot_vocabs[idx]}')
# 敖丙的独热编码为: [0, 1, 0, 0, 0, 0]
if __name__ == '__main__':
demo03()独热编码胜在实现简单、容易理解,但会产生高维稀疏的词向量,并且无法捕捉词与词之间的语义关系。
1.2.2 word2vec
1.2.2.1 word2vec概述
词嵌入(word embedding)指一种将词汇映射到低维稠密向量空间的方法,经过词嵌入后得到的词向量能够在不同的下游NLP任务之间共享(即进行迁移学习),但是无法很好地表示一些低频词和未知词。
word2vec是一种常见的无监督词嵌入方法,它利用自身的文本信息来构建伪标签,并使用全连接神经网络进行训练,其中隐藏层的权重参数矩阵将作为最终的词向量矩阵,这些低维稠密的向量能够有效地捕捉词与词之间的语义关系(语义相近的词的词向量有着更高的相似度),但需要大量的语料来进行训练。
1.2.2.2 连续词袋模型
连续词袋(continuous bag of words,CBOW)模型是word2vec的一种,该模型通过上下文词来预测中心词,例如:在窗口大小为4的CBOW模型中,使用前后4个上下文词来预测中心词。
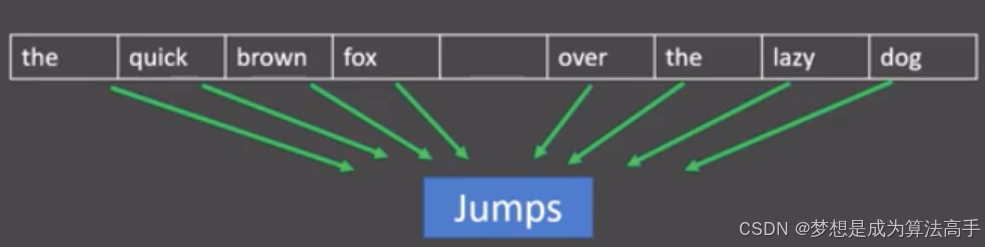
CBOW模型的计算流程如下:
1. 将窗口内的上下文词进行独热编码,每个词的词向量形状为1 * m。
2. 将进行独热编码后的词向量送入形状为m * n的嵌入矩阵(也可以视为送入了一个有n个神经元的全连接神经网络),得到每个词的低维词向量表示,形状为1 * n。
3. 将每个词的低维词向量做平均,得到一个平均词向量。
4. 将平均词向量送入形状为n * m的输出矩阵(也可以视为送入了一个有m个神经元的全连接神经网络),得到一个形状为1 * m的输出向量。
5. 将输出向量送入softmax激活函数进行归一化并与中心词的独热编码形式做交叉熵损失计算得到最终的损失值。
1.2.2.3 skip-gram模型
skip-gram模型也是word2vec的一种,该模型通过中心词来预测上下文词,例如:在窗口大小为4的skip-gram模型中,使用中心词来预测前后4个上下文词。
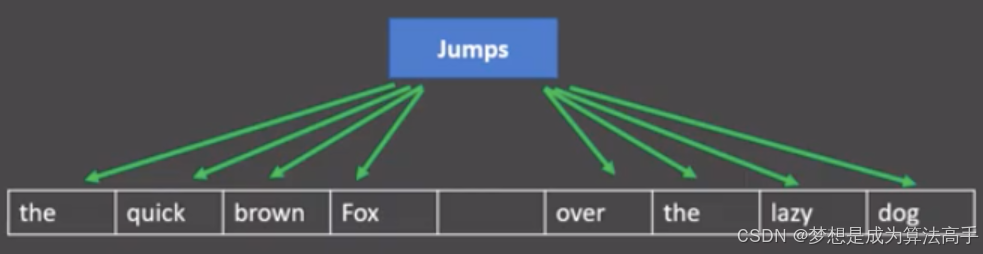
skip-gram模型的计算流程如下:
1. 将窗口内的中心词进行独热编码,中心词的词向量形状为1 * m。
2. 将进行独热编码后的词向量送入形状为m * n的嵌入矩阵(也可以视为送入了一个有n个神经元的全连接神经网络),得到中心词的低维词向量表示,形状为1 * n。
3. 将中心词的词向量送入多个形状为n * m的输出矩阵(也可以视为送入了多个有m个神经元的全连接神经网络),得到多个形状为1 * m的输出向量。
4. 将多个输出向量送入softmax激活函数进行归一化并与上下文词的独热编码形式依次做交叉熵损失计算并相加作为最终的损失值。
注意:CBOW模型和skip-gram模型最终训练得到的嵌入矩阵中的每个行向量即为每个词最终的词向量,将某个词的独热编码词向量与嵌入矩形做矩阵乘法即可检索到该词最终的低维词向量。
1.2.2.4 word2vec示例
word2vec的示例代码如下:
import fasttext
def train():
# 创建模型,其中第一个参数为语料库路径,第二个参数为word2vec模型的类型
# 第三个参数为词向量维度,第四个参数为训练轮数,第五个参数为学习率,第六个参数为线程数
model = fasttext.train_unsupervised('data/fil9', model='skipgram',
dim=100, epoch=1, lr=0.1, thread=12)
# 保存模型
model.save_model('data/fil9.bin')
def use(token):
# 加载模型
model = fasttext.load_model('data/fil9.bin')
# 获取sports的词向量
vec = model.get_word_vector(token)
print(len(vec)) # 100
# 获取与sports最相似的3个词,通过余弦相似度进行比较
words = model.get_nearest_neighbors(token, k=3)
print(words)
# [(0.9070223569869995, 'sport'), (0.8829970359802246, 'sportsnet'), (0.8677799701690674, 'sporting')]
if __name__ == '__main__':
train()
use('sports')余弦相似度的计算公式如下:
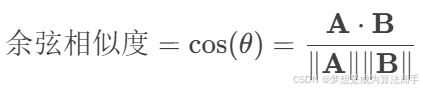
其中,A ⋅ B表示是向量A和B的点积(内积),∥A∥ 和∥B∥分别表示是向量A和向量B的模长。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 45
45 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)