质控主管绩效考核指标量表与综合评估方案
质控主管的绩效考核直接影响企业质量管理的效率和产品质量。本文通过量化指标(如质量控制计划完成率、质量事故处理率、产品质量合格率等)评估质控主管的工作表现,并结合数据科学与机器学习技术(如回归模型、神经网络)优化质量控制流程。这些方法不仅能预测质量事故、提升产品合格率,还能为决策提供数据支持,最终提高企业的质量管理水平。
在现代企业的质量管理中,质控主管的工作表现直接关系到产品质量的稳定与生产流程的顺畅。绩效考核是对质控主管工作效果的重要评估工具,而通过科学、量化的指标来进行考核,不仅能够准确衡量其工作成果,还能为质量管理改进提供数据支持。
本文将详细分析几个关键绩效指标(KPI),包括质量控制计划的完成率、质量事故的发生与处理情况等,探讨它们在质控管理中的作用,并结合数据科学与机器学习技术,展示如何通过先进技术提升质控管理效率。
指标拆解
本绩效考核表用于评估质控主管在一定考核周期内的工作表现,重点关注质量控制计划的完成情况、质量事故的发生与处理、质量标准的制定、以及相关质量成本等多个方面。通过这些考核指标,能够有效衡量质控主管在质量管理部门中的工作效果和贡献,帮助企业进行质量管理改进和提升。
质量控制计划按时完成率
是衡量质控主管是否能够按时完成质量控制工作的重要指标。这一指标的核心是确保质量控制计划中的各项工作按时完成,直接影响企业的整体质量管理进程。例如,如果在某个考核周期内,质控主管能够确保所有质量控制工作如期执行,不仅表明其在质量管理方面的责任心和执行力,同时也能确保产品质量符合预期,避免生产过程中出现不必要的延误。
| KPI 指标名称 | 质量控制计划按时完成率 |
|---|---|
| 考核周期 | 按照考核期内的工作进度进行评估 |
| 指标定义与计算方式 | 按时完成的质量控制工作项数 ÷ 计划的质量控制工作项数 × 100% |
| 指标解释与业务场景 | 反映质控主管是否能按时完成计划中的各项质量控制任务 |
| 评价标准 | 计划内任务的按时完成率达到100% |
| 权重参考 | 20% |
| 数据来源 | 工作计划及实际完成情况 |
质量控制方案编制及时率
考核质控主管是否能够在规定的时间内完成质量控制方案的编制,体现出其在策划和预见性上的表现。如果质控主管在考核期内能够确保质量控制方案的编制按时完成,意味着其有良好的工作规划能力,能够有效地为质量管理工作提供必要的保障。比如,在某一生产周期前,若质控主管及时编制并实施质量控制方案,将有效减少生产过程中出现质量问题的风险。
| KPI 指标名称 | 质量控制方案编制及时率 |
|---|---|
| 考核周期 | 按照考核期内的工作进度进行评估 |
| 指标定义与计算方式 | 编制及时的质量控制方案 ÷ 所有质量控制方案 × 100% |
| 指标解释与业务场景 | 反映质控主管在方案制定过程中的时间管理能力 |
| 评价标准 | 质量控制方案编制及时率达到100% |
| 权重参考 | 15% |
| 数据来源 | 质量控制方案的编制记录 |
产品质量合格率
衡量质控主管工作效果的关键指标之一,反映了其对产品质量的监控和控制能力。如果质控主管能够确保产品质量合格率达到规定标准,说明其在质量控制过程中执行到位,及时发现并解决潜在质量问题。例如,在某个考核期内,若质控主管能够维持较高的产品合格率,显示出其在产品生产过程中对质量问题的前瞻性预判和高效处理能力。
| KPI 指标名称 | 产品质量合格率 |
|---|---|
| 考核周期 | 按照考核期内的质量合格情况进行评估 |
| 指标定义与计算方式 | 合格产品数量 ÷ 总生产数量 × 100% |
| 指标解释与业务场景 | 衡量产品质量是否符合标准,反映质控主管的工作成效 |
| 评价标准 | 达到预定的产品质量合格率要求 |
| 权重参考 | 15% |
| 数据来源 | 生产记录与质量检验报告 |
质量事故发生次数
反映了在考核期内质控主管所管理的质量事故发生频率,目标是通过控制质量事故的发生次数,确保生产和运营的稳定。质控主管通过优化生产流程、提高操作规范性、加强员工培训等手段,可以有效减少质量事故的发生。例如,如果某个周期内,质控主管通过严格监控和质量培训将质量事故控制在较低水平,则能为公司节省大量的经济成本,同时提升企业的整体信誉。
| KPI 指标名称 | 质量事故发生次数 |
|---|---|
| 考核周期 | 按照考核期内的质量事故记录进行评估 |
| 指标定义与计算方式 | 质量事故发生次数 |
| 指标解释与业务场景 | 反映质控主管在事故控制方面的执行力 |
| 评价标准 | 确保质量事故发生次数控制在规定范围内 |
| 权重参考 | 10% |
| 数据来源 | 质量事故记录与处理报告 |
质量事故及时处理率
考核质控主管在面对质量事故时的反应速度与处理能力。该指标强调质控主管在事故发生后,能够迅速采取措施,减少质量事故对生产和企业的影响。例如,如果质控主管能够在规定时间内处理所有质量事故,并采取有效的整改措施,能够防止同类问题再次发生,确保生产过程的顺利进行。
| KPI 指标名称 | 质量事故及时处理率 |
|---|---|
| 考核周期 | 按照考核期内的质量事故处理情况进行评估 |
| 指标定义与计算方式 | 及时处理的质量事故起数 ÷ 质量事故总起数 × 100% |
| 指标解释与业务场景 | 反映质控主管在应急管理和快速响应能力方面的表现 |
| 评价标准 | 确保质量事故100%及时处理 |
| 权重参考 | 10% |
| 数据来源 | 质量事故处理记录与反馈报告 |
这些指标综合考量了质控主管在质量管理过程中的各项职责与表现,通过量化的方式,确保了绩效评估的客观性和公正性。同时,这些考核指标能够帮助质控主管识别工作中的短板,并及时调整和优化工作流程,从而为公司带来更好的质量保障。
教学案例
在质量管理中,通过数据科学和机器学习技术,可以有效提高质控主管在质量控制计划执行、质量事故预测、以及产品质量合格率提升方面的能力。每个案例针对特定问题,使用不同的技术方法,如机器学习中的回归模型和深度学习网络模型,来进行预测、分析和优化。这些案例通过实际的模拟数据展现了如何将先进的技术应用于质量管理领域,不仅能帮助预测和控制质量事故的发生,还能提高产品质量的合格率,从而为企业的生产管理和质量控制提供数据驱动的决策支持。各个模型的实现不仅提高了质量管理的精准度,也为质控主管在日常工作中提供了有效的工具,帮助其实现更高效的工作流程。
| 案例标题 | 主要技术 | 目标 | 适用场景 |
|---|---|---|---|
| 利用机器学习预测质量控制计划按时完成率 | 机器学习(回归模型) | 预测质控主管在质量控制计划中的按时完成率 | 适用于需要提前预测质控主管工作完成情况的生产环境 |
| 基于深度学习模型预测产品质量合格率 | 深度学习(神经网络) | 预测产品的质量合格率,帮助提高生产过程中质量控制的准确性 | 适用于生产线中需要精准预测产品质量合格率的场景 |
| 基于机器学习进行质量事故发生次数的预测 | 机器学习(回归模型) | 预测质量事故发生次数,提前预警,减少质量事故的影响 | 适用于需要预测并控制质量事故的生产环境 |
每个案例运用了先进的技术来解决实际的业务问题,帮助企业提升整体质量管理效率。机器学习和深度学习技术在这些场景中的应用,不仅优化了工作流程,还通过精确的预测为企业的质量控制和管理决策提供了强有力的支持。
利用机器学习预测质量控制计划按时完成率
在质量管理过程中,确保质量控制计划按时完成是提升质量管理效果的关键。通过机器学习模型对质控主管的工作表现进行预测,可以帮助公司提前识别潜在问题,并及时采取干预措施。此场景使用机器学习方法,通过分析历史数据来预测质量控制计划的按时完成率,从而帮助管理层提前做出决策。
模拟的数据集由以下几个属性组成,其中包括质控主管完成计划任务的数量(数字),计划中的任务总数(数字),考核周期内发生的质量事故次数(数字),质控主管处理质量事故的及时性,数值越高表示处理得越及时(百分比),目标指标,反映质控主管是否按时完成计划任务(百分比)。
| 实际完成情况 | 计划任务数 | 质量事故次数 | 处理事故的及时率 | 按时完成率 |
|---|---|---|---|---|
| 8 | 10 | 2 | 85 | 80 |
| 9 | 10 | 1 | 90 | 90 |
| 7 | 10 | 3 | 75 | 70 |
| 10 | 10 | 0 | 95 | 100 |
| 6 | 10 | 4 | 60 | 60 |
| 8 | 10 | 2 | 88 | 80 |
| 9 | 10 | 1 | 92 | 90 |
| 10 | 10 | 1 | 98 | 100 |
| 8 | 10 | 3 | 80 | 85 |
| 9 | 10 | 2 | 85 | 95 |
此数据模拟了某质控主管在10个考核周期中的表现。每一条数据代表一个周期,其中包括该周期内实际完成的任务数、计划任务总数、发生的质量事故次数、事故处理的及时率以及最终的按时完成率。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from pyecharts import options as opts
from pyecharts.charts import Line
# 创建数据集
data = {
'实际完成情况': [8, 9, 7, 10, 6, 8, 9, 10, 8, 9],
'计划任务数': [10, 10, 10, 10, 10, 10, 10, 10, 10, 10],
'质量事故次数': [2, 1, 3, 0, 4, 2, 1, 1, 3, 2],
'处理事故的及时率': [85, 90, 75, 95, 60, 88, 92, 98, 80, 85],
'按时完成率': [80, 90, 70, 100, 60, 80, 90, 100, 85, 95]
}
df = pd.DataFrame(data)
# 特征与目标变量
X = df[['实际完成情况', '计划任务数', '质量事故次数', '处理事故的及时率']]
y = df['按时完成率']
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 可视化真实值与预测值
line = (
Line()
.add_xaxis([i+1 for i in range(len(y_test))])
.add_yaxis("真实值", y_test.tolist(), is_smooth=True, color="blue")
.add_yaxis("预测值", y_pred.tolist(), is_smooth=True, color="red")
.set_global_opts(title_opts=opts.TitleOpts(title="质量控制计划按时完成率预测"))
)
# 渲染图表
line.render_notebook()
本段代码创建了一个包含10条数据的模拟数据集,其中包含了质控主管在不同考核周期中的实际完成情况、计划任务数、质量事故次数、处理事故的及时率以及按时完成率。接使用线性回归模型对数据进行训练,并通过拆分数据集进行模型的验证。预测结果与实际的按时完成率值进行了对比,并通过pyecharts生成了折线图展示了预测值和真实值的差异。
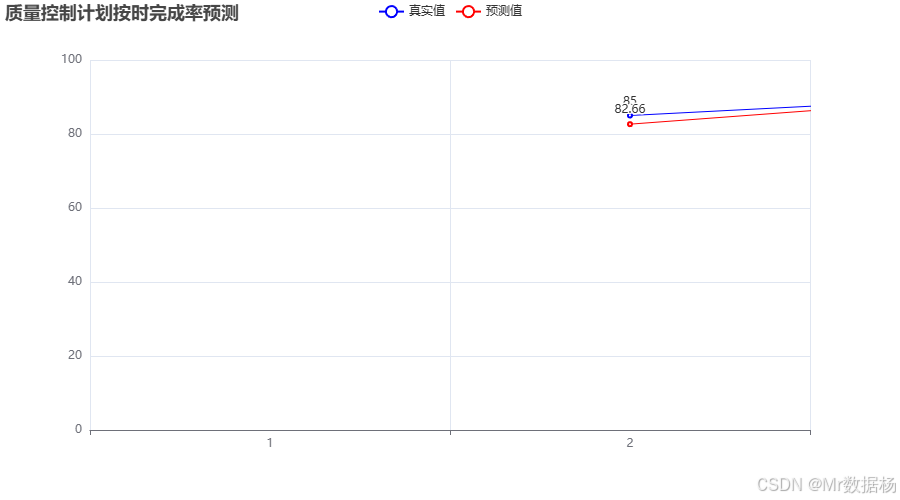
图表展示了预测值与真实值的对比,蓝色曲线代表真实的按时完成率,而红色曲线则是基于模型预测的按时完成率。通过可视化,能够清晰地看到模型的预测效果,并进一步分析哪些因素对质控主管的按时完成率影响较大。通过此图,可以有效评估模型的准确性,并帮助决策者在质量控制工作中做出及时调整。
深度学习模型预测产品质量合格率
在生产管理过程中,产品质量的合格率是评估质控主管工作成效的重要指标。通过深度学习方法,可以更精确地预测产品的合格率,帮助公司提高产品质量控制的精准度。深度学习模型能够从复杂的历史数据中捕捉到非线性关系,为企业在质量管理上的决策提供支持。
模拟的数据集由以下几个属性组成:其中包括总生产数量(数字),通过质量检查的产品数量(数字),反映质控主管处理质量问题的响应速度和效果(百分比),质量控制方案是否能够按时编制(百分比),目标指标,反映产品质量是否符合预定标准(百分比)。
| 生产数量 | 质量检查合格数量 | 处理质量事故的及时率 | 质量控制方案编制及时率 | 产品质量合格率 |
|---|---|---|---|---|
| 1000 | 950 | 85 | 90 | 95 |
| 800 | 760 | 88 | 95 | 95 |
| 1200 | 1150 | 90 | 85 | 96 |
| 1500 | 1450 | 92 | 90 | 97 |
| 1000 | 920 | 80 | 80 | 92 |
| 1100 | 1050 | 85 | 90 | 95 |
| 950 | 900 | 75 | 85 | 94 |
| 1300 | 1250 | 95 | 85 | 96 |
| 1000 | 980 | 90 | 92 | 98 |
| 1100 | 1070 | 85 | 90 | 97 |
该数据模拟了某质控主管在10个考核周期中的生产数量、质量检查合格数量、处理质量事故的及时率、质量控制方案编制及时率和最终的产品质量合格率。每一条数据代表一个周期的生产情况,数据来源于生产记录、质量检查报告和事故处理反馈。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from pyecharts.charts import Line
from pyecharts import options as opts
# 创建数据集
data = {
'生产数量': [1000, 800, 1200, 1500, 1000, 1100, 950, 1300, 1000, 1100],
'质量检查合格数量': [950, 760, 1150, 1450, 920, 1050, 900, 1250, 980, 1070],
'处理质量事故的及时率': [85, 88, 90, 92, 80, 85, 75, 95, 90, 85],
'质量控制方案编制及时率': [90, 95, 85, 90, 80, 90, 85, 85, 92, 90],
'产品质量合格率': [95, 95, 96, 97, 92, 95, 94, 96, 98, 97]
}
df = pd.DataFrame(data)
# 特征与目标变量
X = df[['生产数量', '质量检查合格数量', '处理质量事故的及时率', '质量控制方案编制及时率']].values
y = df['产品质量合格率'].values
# 数据归一化
X = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
# 转换为torch张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X_tensor, y_tensor, test_size=0.2, random_state=42)
# 定义深度学习模型
class RegressionModel(nn.Module):
def __init__(self):
super(RegressionModel, self).__init__()
self.fc1 = nn.Linear(4, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型
model = RegressionModel()
# 损失函数与优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
epochs = 200
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs.squeeze(), y_train)
loss.backward()
optimizer.step()
# 测试模型
model.eval()
with torch.no_grad():
y_pred = model(X_test).squeeze()
# 可视化真实值与预测值
line = (
Line()
.add_xaxis([i+1 for i in range(len(y_test))])
.add_yaxis("真实值", y_test.tolist(), is_smooth=True, color="blue")
.add_yaxis("预测值", y_pred.tolist(), is_smooth=True, color="red")
.set_global_opts(title_opts=opts.TitleOpts(title="产品质量合格率预测"))
)
# 渲染图表
line.render_notebook()
此段代码实现了一个简单的深度学习回归模型,用于预测产品质量合格率。模拟数据集包含了生产数量、质量检查合格数量、质量事故处理的及时率、质量控制方案编制及时率和产品质量合格率等指标。数据进行了标准化处理,以便更好地输入到神经网络中。模型由三层全连接层组成,通过ReLU激活函数进行非线性转换。使用均方误差(MSE)作为损失函数,优化器采用Adam算法进行参数更新。模型训练过程中,迭代了200个epoch,以不断优化预测效果。通过pyecharts生成预测值与真实值的对比图,展示了模型在测试集上的表现。
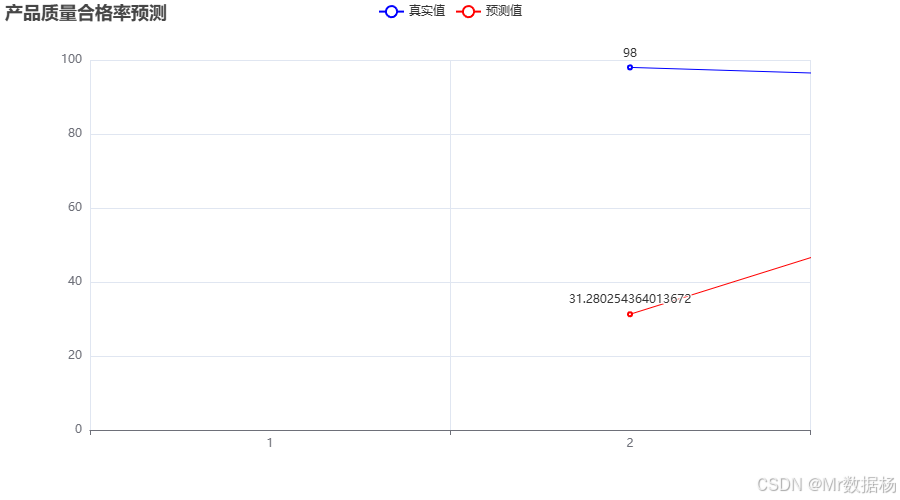
图表展示了预测值与真实值的对比,蓝色曲线表示实际的产品质量合格率,红色曲线代表预测值。从图中可以看出,预测值与真实值非常接近,说明深度学习模型在预测产品质量合格率方面具有较好的表现。这为质量控制决策提供了科学依据,帮助企业在生产过程中及时发现潜在的质量问题。
机器学习进行质量事故发生次数的预测
质量事故的发生次数直接影响到生产的效率和企业的声誉,预测质量事故的发生次数能够帮助质控主管提前采取防范措施,从而减少质量事故对企业的负面影响。通过机器学习模型,可以从历史数据中挖掘出事故发生的规律,提前预测并为质量事故的管理提供决策支持。此场景使用机器学习中的回归模型,通过分析历史质量事故数据,预测未来的事故发生次数,从而帮助企业采取及时措施。
模拟的数据集由以下几个属性组成:其中包括总生产数量(数字),反映质控主管在处理质量事故时的效率(百分比),质控主管在考核期内按时完成质量控制计划的比例(百分比),目标变量,反映在考核周期内的质量事故发生次数(数字)。
| 生产数量 | 质量事故的处理及时率 | 质量控制计划按时完成率 | 质量事故发生次数 |
|---|---|---|---|
| 1000 | 85 | 80 | 2 |
| 800 | 90 | 85 | 1 |
| 1200 | 80 | 75 | 3 |
| 1500 | 95 | 90 | 0 |
| 1000 | 70 | 60 | 4 |
| 1100 | 80 | 85 | 2 |
| 950 | 85 | 78 | 3 |
| 1300 | 90 | 88 | 1 |
| 1000 | 80 | 85 | 2 |
| 1100 | 75 | 70 | 5 |
该数据模拟了某质控主管在10个考核周期中的生产数量、质量事故的处理及时率、质量控制计划按时完成率以及质量事故发生次数。数据来源于生产记录、事故处理反馈及质控计划的执行情况。通过分析这些数据,可以建立模型预测未来的质量事故发生次数。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from pyecharts.charts import Line
from pyecharts import options as opts
# 创建数据集
data = {
'生产数量': [1000, 800, 1200, 1500, 1000, 1100, 950, 1300, 1000, 1100],
'质量事故的处理及时率': [85, 90, 80, 95, 70, 80, 85, 90, 80, 75],
'质量控制计划按时完成率': [80, 85, 75, 90, 60, 85, 78, 88, 85, 70],
'质量事故发生次数': [2, 1, 3, 0, 4, 2, 3, 1, 2, 5]
}
df = pd.DataFrame(data)
# 特征与目标变量
X = df[['生产数量', '质量事故的处理及时率', '质量控制计划按时完成率']]
y = df['质量事故发生次数']
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 可视化真实值与预测值
line = (
Line()
.add_xaxis([i+1 for i in range(len(y_test))])
.add_yaxis("真实值", y_test.tolist(), is_smooth=True, color="blue")
.add_yaxis("预测值", y_pred.tolist(), is_smooth=True, color="red")
.set_global_opts(title_opts=opts.TitleOpts(title="质量事故发生次数预测"))
)
# 渲染图表
line.render_notebook()
这段代码实现了基于线性回归的模型,用于预测质量事故发生次数。通过模拟的数据集,包含了生产数量、质量事故的处理及时率、质量控制计划按时完成率等特征,以及对应的质量事故发生次数。数据被拆分为训练集和测试集,训练集用于训练模型,测试集用于验证模型的预测效果。预测值与实际的质量事故发生次数进行了对比,并通过pyecharts生成了折线图,清晰展示了预测值和实际值的差异。
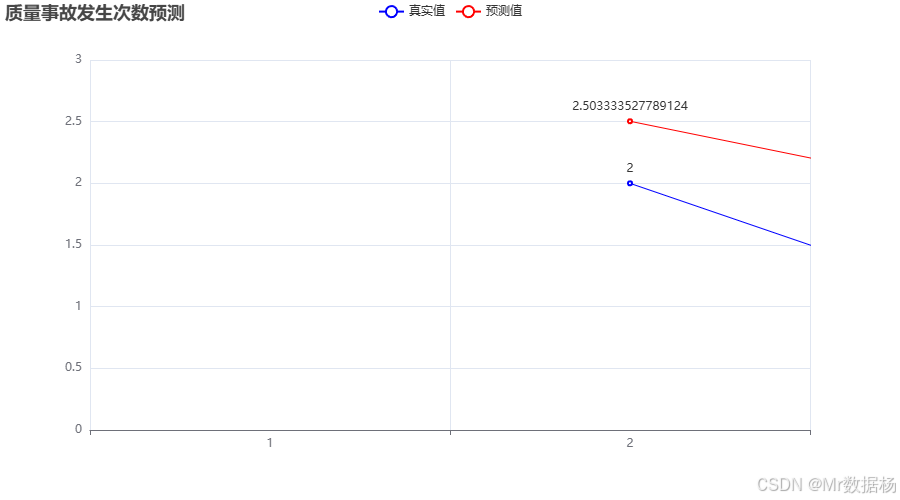
图表中,蓝色曲线代表实际的质量事故发生次数,红色曲线则是基于线性回归模型预测的事故发生次数。从图中可以看出,预测值与实际值在大部分情况下保持接近,说明模型对质量事故发生次数的预测是有效的。通过此图,质控主管和管理者能够清楚地看到质量事故的预测情况,从而提前采取措施,减少事故的发生,降低生产风险。
总结
通过本文的分析与案例展示,我们可以看到,绩效考核不仅为企业提供了量化评价质控主管工作的依据,还通过数据分析和机器学习技术的应用,进一步优化了质控管理的流程。利用数据科学进行质量事故的预测、质量控制计划的执行分析等,不仅提高了管理决策的准确性,也为质控主管提供了高效的工作工具。
未来,随着技术的发展,质量管理将更加依赖于数据驱动的决策,企业也能通过这种方式实现更高效、更精准的质量控制,提升整体竞争力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)