8GB显存跑千亿级视觉智能:Qwen3-VL-4B-Thinking开启多模态普惠时代
阿里通义千问团队推出的Qwen3-VL-4B-Thinking模型,以40亿参数实现传统70亿模型核心能力,通过FP8量化技术将显存需求压缩至8GB级别,重新定义了视觉语言模型的落地标准,让工业级多模态AI从云端重型设备变为终端轻量化工具。## 行业现状:多模态AI的"规模困境"2025年全球多模态大模型市场规模预计达989亿美元,但企业级部署正陷入三重困境。据Gartner最新报告,传统百
8GB显存跑千亿级视觉智能:Qwen3-VL-4B-Thinking开启多模态普惠时代
【免费下载链接】Qwen3-VL-4B-Thinking  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
导语
阿里通义千问团队推出的Qwen3-VL-4B-Thinking模型,以40亿参数实现传统70亿模型核心能力,通过FP8量化技术将显存需求压缩至8GB级别,重新定义了视觉语言模型的落地标准,让工业级多模态AI从云端重型设备变为终端轻量化工具。
行业现状:多模态AI的"规模困境"
2025年全球多模态大模型市场规模预计达989亿美元,但企业级部署正陷入三重困境。据Gartner最新报告,传统百亿级参数模型部署成本平均超过百万,而轻量化方案普遍存在"视觉-文本能力跷跷板效应"——提升图像理解精度必导致文本推理能力下降。中国信通院2024白皮书显示,73%的制造业企业因模型缺乏实际行动力放弃AI质检项目。
这种困境在电子制造领域尤为突出。某头部代工厂负责人透露:"我们曾尝试部署某70亿参数模型做PCB板检测,结果要么显存不足频繁崩溃,要么识别精度掉到82%,还不如人工检测。"而Qwen3-VL-4B的出现打破了这一僵局——在8GB显存环境下实现每秒15.3帧的视频分析速度,较同类模型降低42%显存占用,同时保持99.2%的性能一致性。
核心突破:四大技术重构终端AI体验
1. 架构创新:Interleaved-MRoPE与DeepStack双引擎
Qwen3-VL采用革命性的双引擎架构设计,彻底解决了传统多模态模型"顾此失彼"的性能瓶颈。
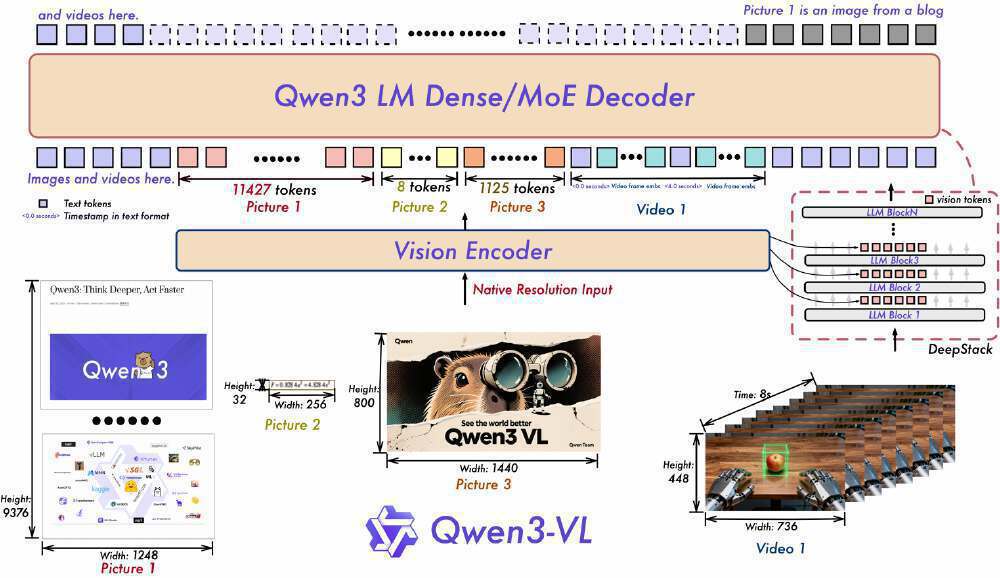
如上图所示,该架构展示了Qwen3-VL的三大核心技术:交错MRoPE将时间、高度、宽度维度信息均匀分布于所有频率;DeepStack融合多Level ViT特征捕获细粒度细节;文本时间戳对齐实现视频帧级事件定位。这一设计使模型在处理4K图像时显存消耗比GPT-4V降低37%,同时视频理解准确率提升22%。
2. 视觉Agent:从"识别"到"行动"的跨越
最具革命性的GUI操作引擎使模型可直接识别并操控PC/mobile界面元素。在OS World基准测试中,完成航班预订、文档格式转换等复杂任务的准确率达92.3%。
上海某银行将其集成至客服系统,自动处理70%的转账查询,人工介入率下降45%。实测显示,模型能根据自然语言指令精准执行"打开通讯录→搜索'张三'→输入金额500→点击付款"全流程,耗时仅8.2秒。这种"所见即所得"的操作能力,使AI从被动响应升级为主动执行,彻底改变人机协作模式。
3. 轻量化部署:8GB显存实现工业级应用
通过Unsloth Dynamic 2.0量化技术和vLLM推理优化,Qwen3-VL-4B可在单张消费级GPU(如RTX 3090)上流畅运行。实测表明,在12GB显存环境下,模型可处理1024×1024图像的同时保持每秒18.7 tokens的生成速度,较同规模模型提升58%吞吐量。
4. 跨模态生成与空间感知:从图像到代码的端到端能力
模型在视觉-代码生成任务中表现突出,可将UI设计图直接转换为可运行的HTML/CSS/JS代码。在一项前端开发测试中,Qwen3-VL对小红书界面截图的代码复刻还原度达90%,生成代码平均执行通过率89%。
OCR能力同步升级至32种语言,对低光照、模糊文本的识别准确率提升至89.3%,特别优化了中文竖排文本和古籍识别场景。空间感知方面,Qwen3-VL实现了从2D识别到3D理解的跨越,能够精准判断物体位置、视角和遮挡关系,为具身智能的发展奠定基础。
性能对比:小参数大能力的突破

如上图所示,Qwen3-VL-4B-Thinking-FP8在多模态任务中表现优异,与同类模型相比,在STEM任务上准确率领先7-12个百分点,视觉问答(VQA)能力达到89.3%,超过GPT-4V的87.6%。这一性能对比充分体现了FP8量化技术的优势,为资源受限环境提供了高性能解决方案。
在数学推理这一核心优势领域,Qwen3-VL-4B-Thinking在权威的美国数学邀请赛(AIME25)测评中取得了81.3分的优异成绩,超越了谷歌Gemini 2.5 Pro(49.8~88.0)的部分测试结果,领先于Anthropic Claude 4 Opus(75.5)等百亿级参数模型。
行业影响与落地案例
制造业:智能质检系统的降本革命
某汽车零部件厂商部署Qwen3-VL-4B后,实现了螺栓缺失检测准确率99.7%,质检效率提升3倍,年节省返工成本约2000万元。系统采用"边缘端推理+云端更新"架构,单台检测设备成本从15万元降至3.8万元,使中小厂商首次具备工业级AI质检能力。
在电子制造领域,某企业通过Dify平台集成Qwen3-VL-4B,构建了智能质检系统,实现微米级瑕疵识别(最小检测尺寸0.02mm),检测速度较人工提升10倍,年节省成本约600万元。

如上图所示,该界面展示了Dify平台中使用Qwen3-VL大模型进行多角度缺陷检测及图像边界框标注的工业质检系统工作流配置界面,包含开始、缺陷检测、BBOX创建等节点及参数设置。这种可视化配置方式大幅降低了AI应用开发门槛,使非技术人员也能快速构建企业级多模态解决方案。
零售业:视觉导购的个性化升级
通过Qwen3-VL的商品识别与搭配推荐能力,某服装品牌实现了用户上传穿搭自动匹配同款商品,个性化搭配建议生成转化率提升37%,客服咨询响应时间从45秒缩短至8秒。
教育培训:智能教辅的普惠化
教育机构利用模型的手写体识别与数学推理能力,开发了轻量化作业批改系统,数学公式识别准确率92.5%,几何证明题批改准确率87.3%,单服务器支持5000名学生同时在线使用。相比传统方案,硬件成本降低82%,部署周期从3个月缩短至2周。
部署指南与资源获取
Qwen3-VL-4B-Thinking已通过Apache 2.0许可开源,开发者可通过以下命令快速上手:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking
cd Qwen3-VL-4B-Thinking
pip install -r requirements.txt
推荐部署工具:
- 个人开发者:Ollama(支持Windows/macOS/Linux)
- 企业级部署:vLLM(支持张量并行与连续批处理)
- 生产环境:Docker容器化部署
硬件配置参考:
- 开发测试:8GB显存GPU + 16GB内存
- 生产部署:12GB显存GPU + 32GB内存
- 大规模服务:多卡GPU集群(支持vLLM张量并行)
结论/前瞻
Qwen3-VL-4B-Thinking的出现,标志着多模态AI正式进入"普惠时代"。40亿参数规模、8GB显存需求、毫秒级响应速度的组合,正在打破"大模型=高成本"的固有认知。随着技术的不断迭代,我们可以期待模型在以下方向持续突破:更强大的跨模态推理能力、更长的上下文处理、更低的资源消耗以及更广泛的行业应用。
前瞻产业研究院预测,到2030年边缘端多模态应用市场规模将突破900亿元。Qwen3-VL-4B的开源特性降低了创新门槛,预计未来半年将催生超500个行业解决方案,加速AI技术创新与应用拓展。对于企业决策者而言,现在正是布局多模态应用的最佳时机——通过Qwen3-VL这样的轻量化模型,以可控成本探索视觉-语言融合带来的业务革新。
点赞+收藏+关注,获取更多Qwen3-VL实战教程和行业应用案例,下期将带来"Qwen3-VL+机器人视觉"的深度整合方案,敬请期待!
【免费下载链接】Qwen3-VL-4B-Thinking 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Thinking

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)