IBM RAG挑战赛冠军方案第二弹:像素级复现→7大工程经验(内附AI播客)
这篇试图说清楚:Enterprise RAG Challenge 项目难点和冠军方案回顾、核心架构拆解、复现步骤参考、复现结果与创新点验证、可复制的工程化经验等

两个月前发布的一篇介绍 IBM RAG 挑战赛冠军方案的文章,在公众号和知乎的收获了很多正反馈,后续陆续有很多来自知识星球和后台私信的复现催更。p.s. 看来这种特定场景的最佳实践我得后续多找找发出来。

其实上周就做完了原项目复现的工作,只是为了让这篇文章不只是停留在复现的描述上,我又花了些几天时间梳理了下其中的工程化经验,也另外开发了一个简单的前端交互界面,更加可视化的对复现过程和结果进行观察。总体来说,这个项目中对复杂财报的处理中确实有挺多值得学习的工程巧思。
这篇试图说清楚:
Enterprise RAG Challenge 项目难点和冠军方案回顾、核心架构拆解、复现步骤参考、复现结果与创新点验证、可复制的工程化经验等
以下,enjoy:
1、项目挑战与方案
正式开始介绍前,先做个前情提要,和各位一起快速回顾下上篇已经提到过的项目挑战与解决方案。这部分请各位再看一遍,之后再翻阅下方的拆解和复现验证会更有概念些。
源链接:《IBM RAG挑战赛冠军方案全流程复盘 (附源码地址)》https://mp.weixin.qq.com/s/bBZq-k74Et6O3uXdGfea6g
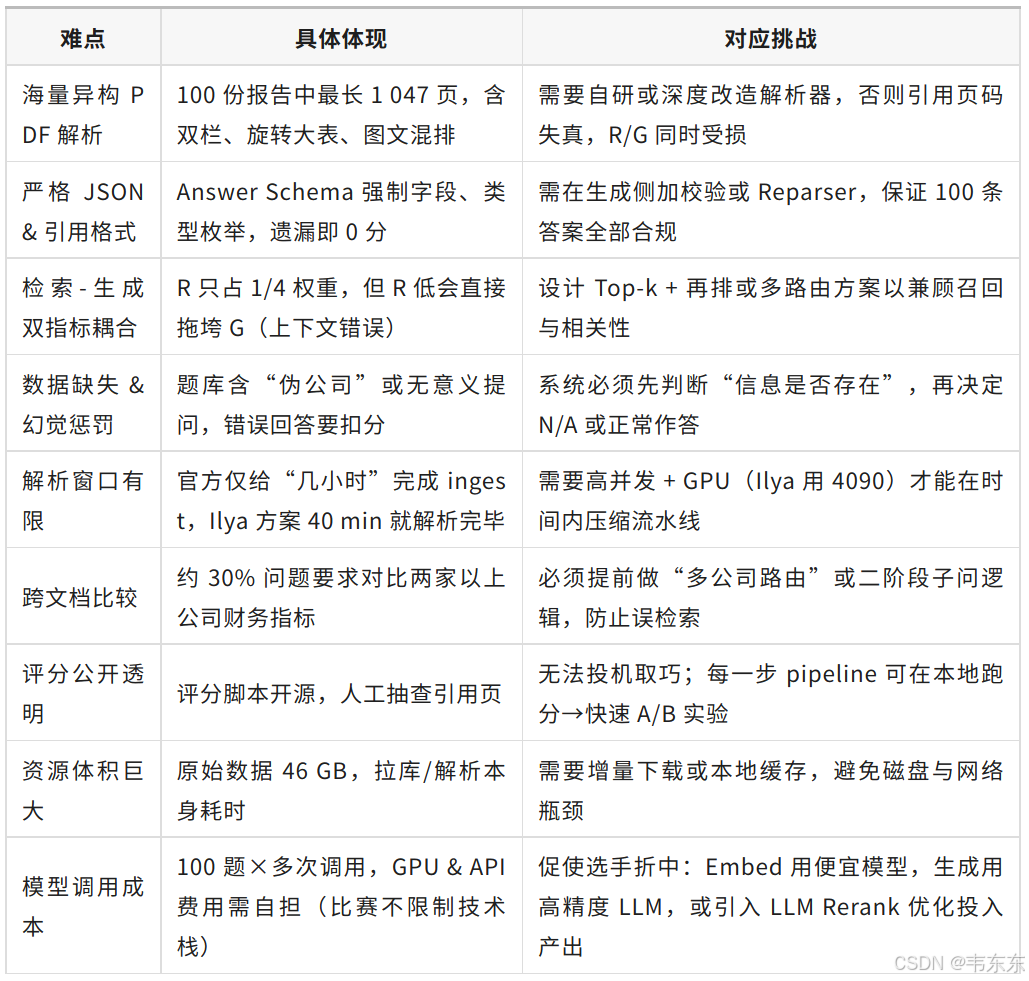
1.1、比赛挑战分析
Enterprise RAG Challenge 这个比赛需要选手在高精度、快速度、低成本三个方面约束条件下,在系统架构、算法选择和工程实现上进行大的创新。
1.2、方案创新思路
Ilya Rice的获胜方案在下述五个核心环节都体现了值得学习的工程优化思考:、
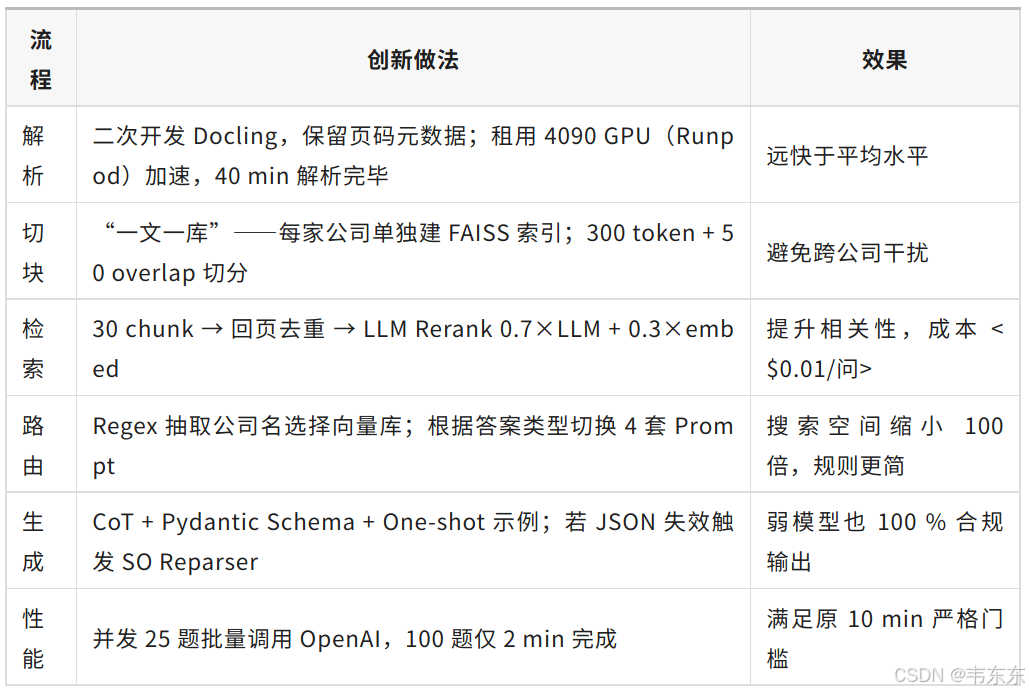
2、项目架构拆解
整个系统体现了工程化的设计理念,通过模块化组织和多层路由策略,在保证高精度的同时实现了成本控制。以下分成五部分简要进行说明,各位可以对照图示(复杂和简化版)进行查看。
注:这里但当涉猎即可,后续在复现结果验证环节会继续进一步说明。
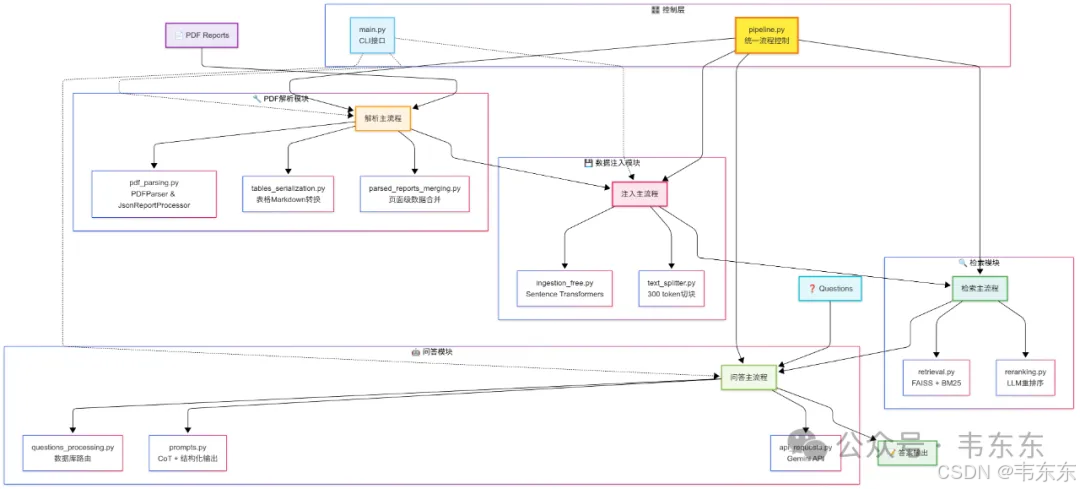
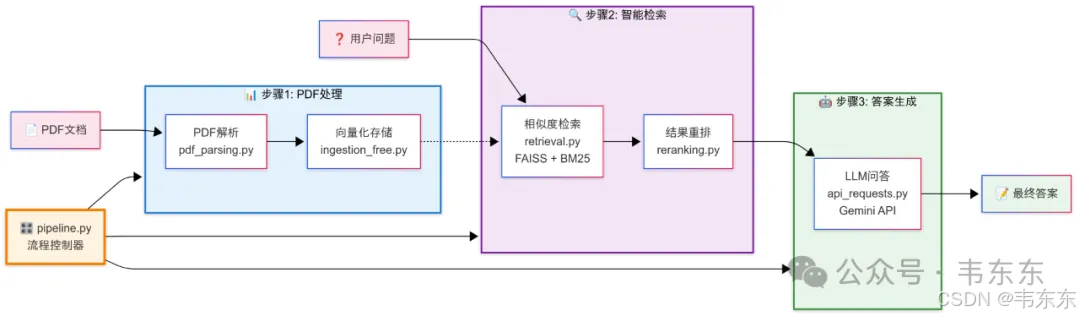
2.1、控制层:统一的流程编排
pipeline.py: 作为系统的"大脑",统一编排各个处理阶段,支持不同配置预设(如 ser_tab、no_ser_tab、gemini_thinking 等)
main.py: 提供 CLI(命令行界面)接口,支持灵活的命令行操作,便于分阶段执行和调试
2.2、PDF 解析模块:数据预处理
核心创新: 对 Docling 库进行定制化改造,实现 GPU 加速的 PDF 解析
表格处理: 通过 tables_serialization.py 把复杂表格转换为 LLM 友好的 Markdown 格式
数据规整: parsed_reports_merging.py 实现页面级数据合并和标准化处理
2.3、数据注入模块:嵌入方案
向量化: 使用 OpenAI 的 text-embedding-3-large 模型(1536 维向量)通过付费 API 进行嵌入计算,保证了高质量的语义表示
切块策略: text_splitter.py 实现 300 token 的重叠切块,为"小块检索,大块喂食"策略奠定基础
存储架构: 采用"一文一库"设计,每个 PDF 对应独立的 FAISS 数据库
2.4、检索模块:多重排序机制
混合检索: retrieval.py 结合 FAISS 向量检索和 BM25 词汇检索
LLM 重排序: reranking.py 使用轻量级 LLM 进行二次精排,采用 0.7×LLM + 0.3×embed 的加权策略
精度提升: 从 Top-30 向量结果中精选 Top-10 页面,显著提升上下文相关性
2.5、问答模块:智能路由与生成
多层路由: questions_processing.py 实现数据库路由、提示词路由和复合查询处理
结构化提示: prompts.py 采用 CoT(思维链) + 结构化输出的组合策略
API 集成: 主要使用 OpenAI GPT 系列模型(如 gpt-4o、gpt-4o-mini)。重排序也依赖 GPT-4o-mini 进行相关性评分
3、复现步骤参考
因为我的 OpenAI 的 API 莫名其妙突然被 ban,在复现过程中我对原项目相关脚本配置做了如下调整:嵌入模型: OpenAI text-embedding-3-large(1536 维) → all-MiniLM-L6-v2(384 维)、对话模型: GPT(gpt-4o、gpt-o3) → Gemini 2.5 Flash(每日 500 次免费额度)、重排序: 原方案的重排序也依赖 GPT-4o-mini 进行相关性评分,这次复现我省略了此部分,各位可自行添加测试。
3.1、环境配置
这个项目需要 GPU 资源才能运行,我提供了本地和云端租赁两种环境配置参考,各位根据实际情况进行选择:有本地 GPU -> 选项 A;反之 -> 选项 B。
选项 A:本地 GPU 环境配置
此路径适用于已拥有兼容 NVIDIA GPU 及 CUDA 环境的用户。
# 1. 创建Python虚拟环境
# 在计划存放项目的目录下执行
python -m venv venv
# 2. 激活虚拟环境
# Windows PowerShell:
.\venv\Scripts\Activate.ps1
# macOS/Linux:
# source venv/bin/activate
# 3. 安装适配本地CUDA的PyTorch
# 项目原要求 torch==2.0.0,但这可能与你的新版CUDA不兼容。
# 可以访问 PyTorch 官网 (https://pytorch.org/get-started/locally/)
# 根据你自己的CUDA版本,找到最接近 torch==2.1.0 的版本并获取安装命令。
# 以下命令以CUDA 12.1为例:
pip3 install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121基础环境配置完成后,继续执行下一步的项目设置与数据准备。
选项 B:云端 GPU 环境配置
这种方法适用于没有本地 GPU,需要租用云端资源的盆友。以下步骤以glows.ai平台(不是软广)为例。(主流云厂商没找到 4090 的分时租赁)
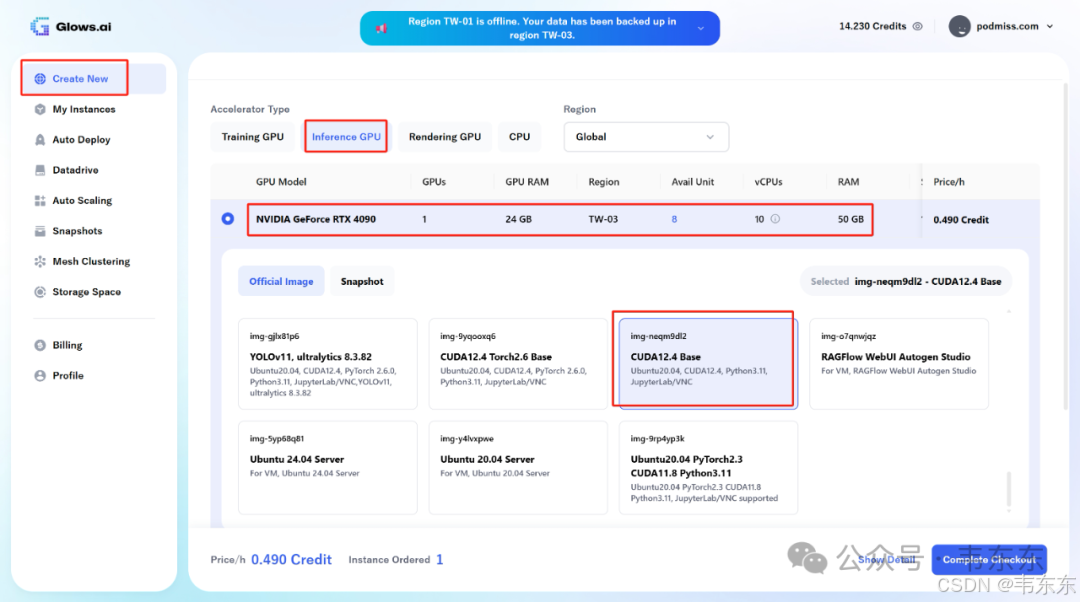
选择带有 NVIDIA GPU 的实例,并确保镜像包含 CUDA 和 Python 3.11+(例如 CUDA12.4 Base 镜像)。为了稳定连接,强烈建议在本地 VS Code 中使用 SSH 配置文件 (Remote-SSH: Open SSH Configuration File...) 并通过别名连接到远程主机。当成功连接到云主机后,执行以下命令:
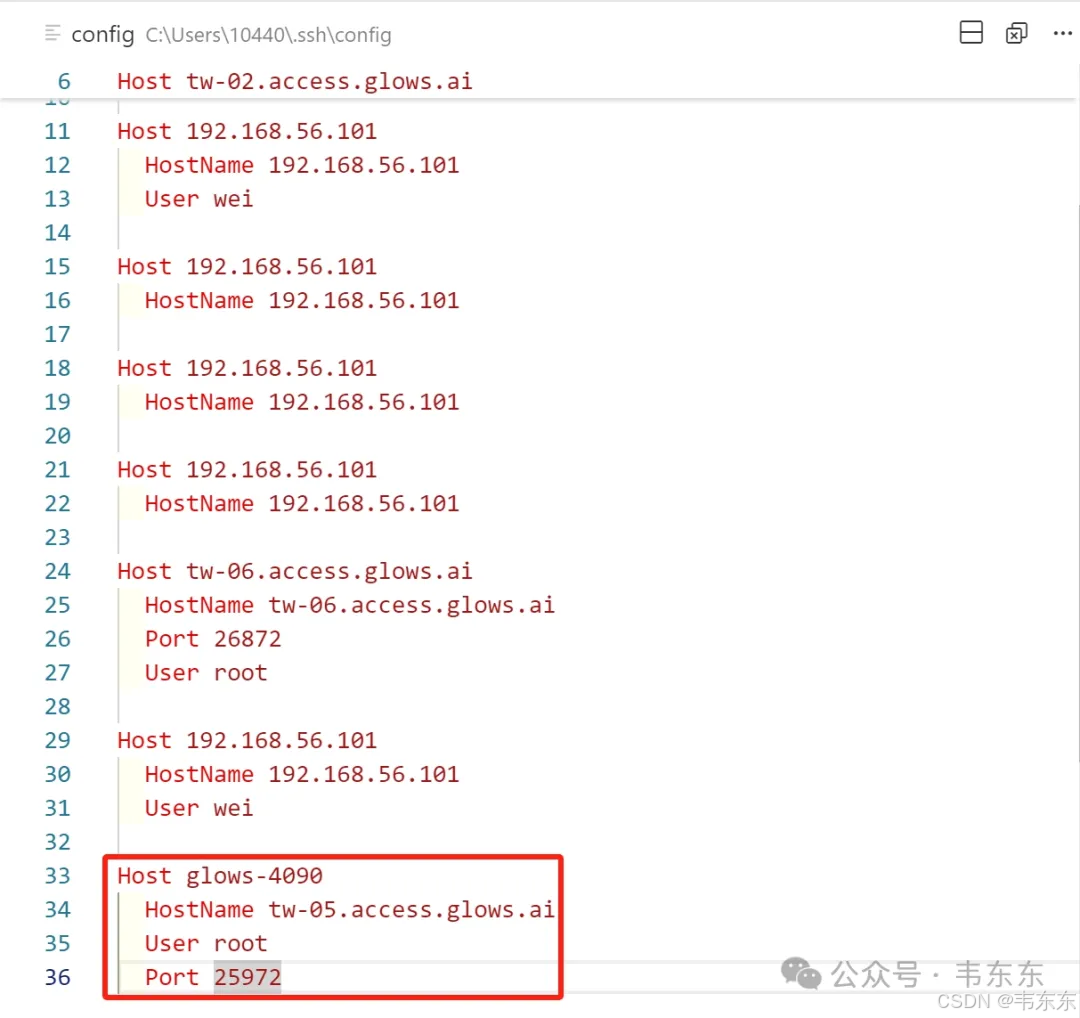
# 1. 系统更新与Git安装 (如果镜像不包含)
apt update
apt install git -y
# 2. 创建虚拟环境
# 在您计划存放项目的目录下执行
python3 -m venv venv
# 3. 激活虚拟环境
source venv/bin/activate
# 4. 安装适配云端CUDA的PyTorch
# 由于RTX 4090等新GPU需要较新的CUDA,我们选择安装与之兼容的torch==2.1.0版本。
pip3 install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu1213.2、项目设置与数据准备
无论使用本地还是云端环境,接下来的步骤都是相同的。
# 1. 克隆代码到当前目录
git clone https://github.com/IlyaRice/RAG-Challenge-2.git
# 2. 进入项目目录
cd RAG-Challenge-2
# 3. 安装项目特定的依赖
# (此时PyTorch已安装,pip会自动跳过)
pip install -e . -r requirements.txt为了确保从零开始完整复现,请手动删除 data/test_set/ 目录下任何可能存在的 databases 和 debug_data 两个子文件夹。这两个文件夹包含作者预处理好的中间结果。删除它们可以保证复现的每一步都使用自己生成的数据(只保留圈出来的部分)。
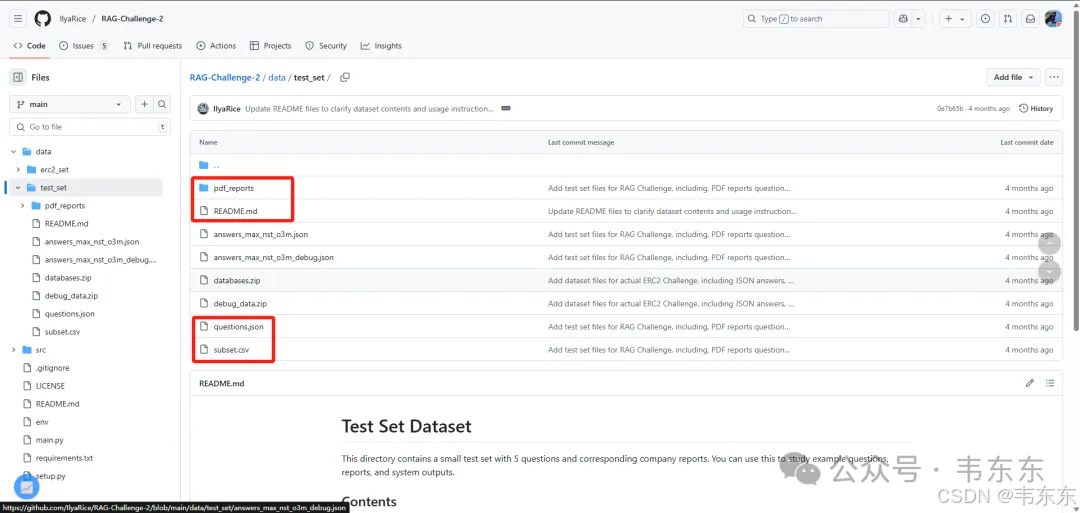
同时,为了加速初步测试流程,建议从 data/test_set/pdf_reports/ 目录中删减 PDF 报告数量,可仅保留两份进行首轮端到端测试(原项目是 5 份,本次复现演示的是圈出来的两个)。
3.3、核心流水线执行
在项目根目录下 (RAG-Challenge-2/),创建 .env 文件并填入 API 密钥。如果你有 OpenAI 的有效 API key,那么可以不用对原项目做任何更改,按照下述流程执行即可。如果没有可以自行更改脚本或者参考我的修改之后的项目进行复现。
OPENAI_API_KEY="sk-..."GEMINI_API_KEY="AIza..."JINA_API_KEY="jina_..."
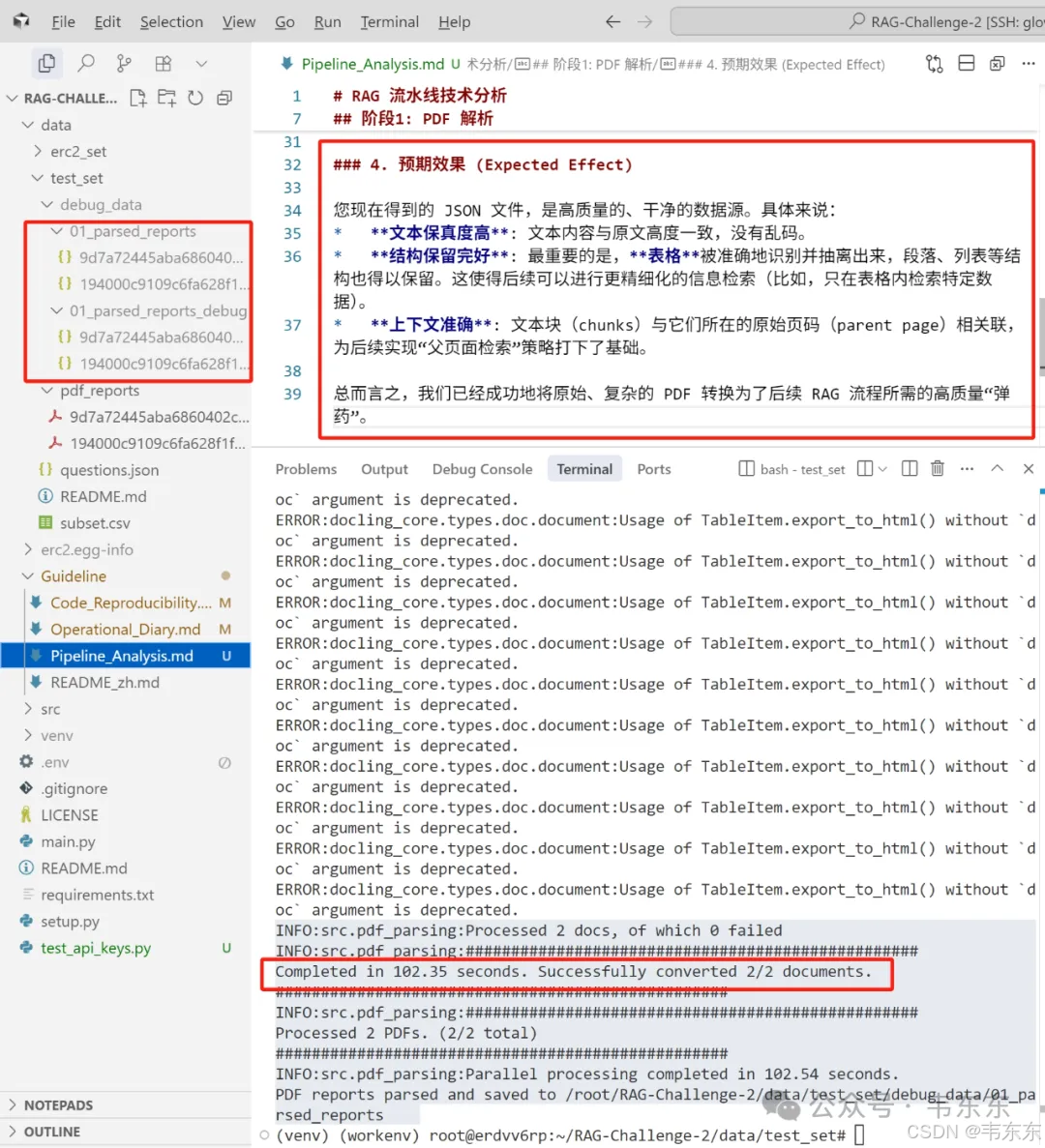
执行 PDF 解析
这一步会利用 GPU 对 PDF 进行解析,并把结构化结果存为 JSON 文件。命令成功执行后,解析的文件会出现在新建的 debug_data/parsed_reports/目录中。
# 1. 切换到测试数据目录cd data/test_set# 2. 从项目根目录执行解析命令python ../../main.py parse-pdfs
序列化表格
这一步把解析出的表格转换为对 LLM 更友好的格式。命令执行成功后,debug_data 中会生成包含序列化表格的新 JSON 文件(本次复现未进行这一步,原因见下一步的附注)。
# (仍在 data/test_set 目录下)python ../../main.py serialize-tables
数据注入 (创建数据库)
这一步是 RAG 的核心之一,它会读取解析后的文本,通过 API 生成向量,并构建本地检索引擎。此处的命令执行时间较长,因为它会为大量文本块调用 Embedding API。成功后,databases 目录下会生成新的 FAISS 和 BM25 索引文件。
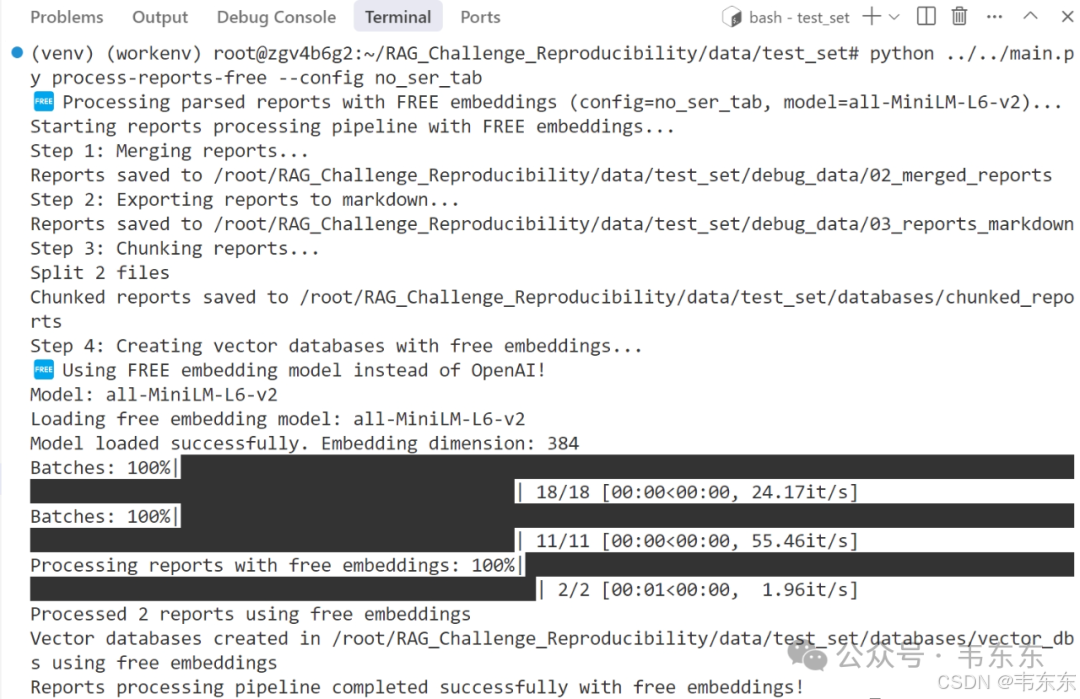
# (仍在 data/test_set 目录下)python ../../main.py process-reports-free --config no_ser_tab
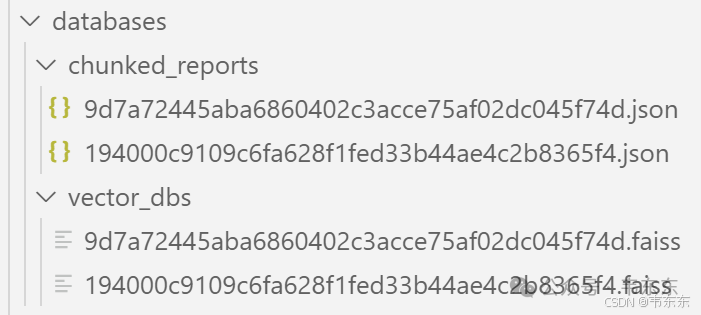
注:--config no_ser_tab 表示使用未序列化表格的数据,Ilya Rice 认为 Docling 解析表格的效果足够好,增加更多文本反而降低了信噪比,因此推荐使用 no_ser_tab 配置,即使你执行了序列化步骤。
执行 RAG 问答
这是最后一步,模拟用户提问,并使用前面构建的 RAG 系统来生成答案。系统会处理测试集中的问题,并最终在 debug_data/相应目录中生成包含答案的 JSON 文件。
# (仍在 data/test_set 目录下)# 使用Gemini替代原始o3m配置python ../../main.py process-questions --config gemini_thinking
为了更好的保存测试工作,可以考虑分批推送到 Gihub 仓库。具体步骤这里不做赘述。
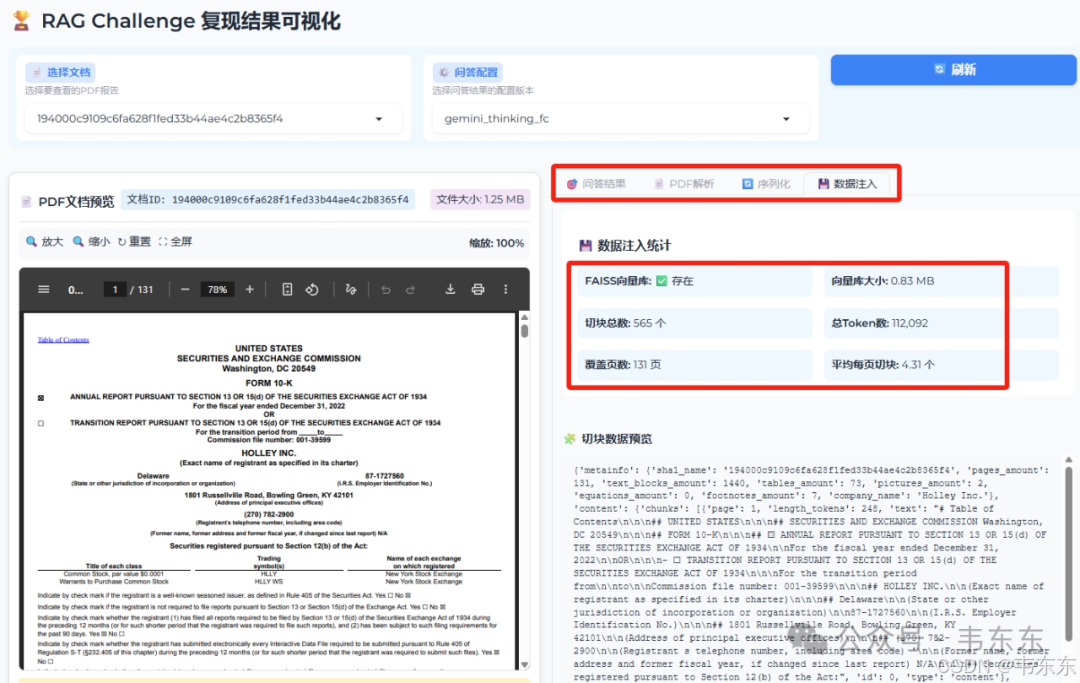
4、可视化界面
传统的 RAG 系统复现往往是黑盒验证,没法形象的观察中间处理过程。鉴于这个项目的复杂度,为了更好介绍下述的结果验证部分,我单独编写了这套可视化方案,把整个 RAG 流水线的每个阶段都透明化展示,模块化组件设计如下:
data_loader.py # 数据统一抽象层├── PDF文档扫描与加载├── 多配置版本管理├── 统计信息自动计算└── 异常处理与恢复pdf_viewer.py # 原始数据展示层├── Base64在线预览├── 跨浏览器兼容└── 移动端适配json_viewer.py # 结构化数据分析层├── 树状JSON展示├── 数据类型高亮└── 深度限制控制stats_viewer.py # 量化分析层├── 实时统计计算├── 交互式图表└── 多维度指标

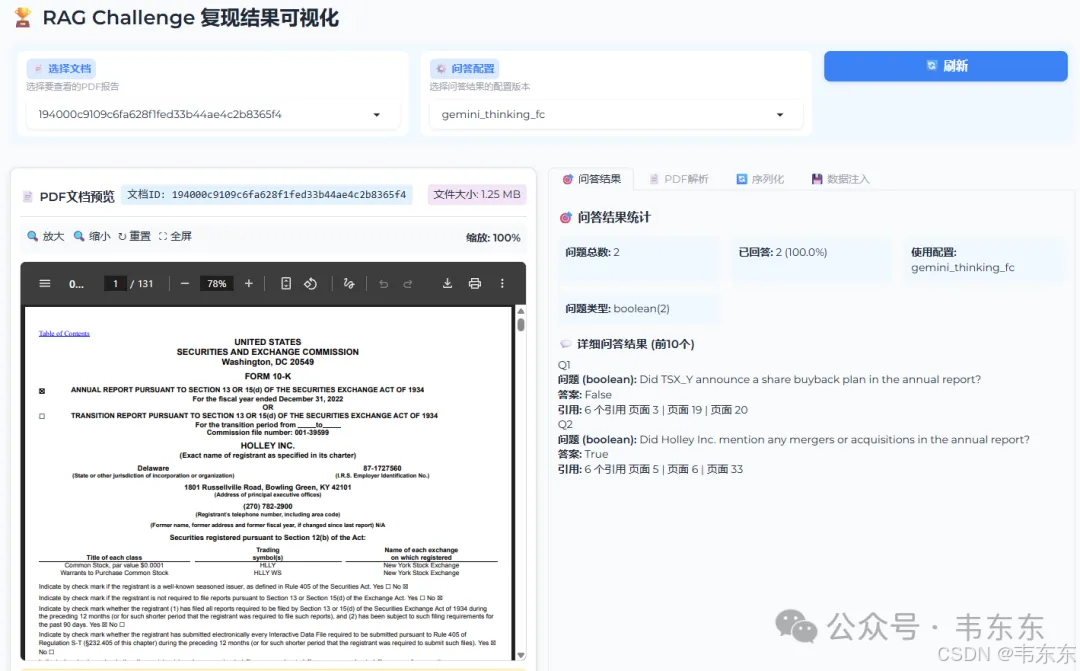
5、复现结果验证
这次复现验证选择了两个具有代表性的测试问题,这两个问题分别考验了系统在语义精确性判断和信息全面性召回方面的表现,同时验证了免费化技术栈替换后的实际效果。
路由准确率: 100% - 成功识别并路由到正确的公司数据库答案准确率: 100% - 两个问题都得到了正确的布尔答案推理质量: 优秀 - 提供了详细的逻辑分析过程引用完整性: 100% - 每个答案都有完整的页面引用免费化效果: 成功 - 证明开源模型可达到企业级应用标准
5.1、测试问题分析
问题 1:股票回购计划判断

中文翻译: "TSX_Y 公司是否在年度报告中宣布了股票回购计划?"
问题难点:
需要区分"报告过去活动"与"宣布新计划"的语义差异
涉及专业金融术语(NCIB、股票回购等)
要求对时间概念的精确理解
问题 2:并购活动识别

中文翻译: "Holley Inc.公司是否在年度报告中提及了任何合并或收购活动?"
问题难点:
需要识别多种并购术语的变体(merger, acquisition, M&A, Business Combination 等)
信息分散在报告的多个章节中
要求全面的信息召回能力
5.2、最终答案验证
问题 1:
系统答案: 否
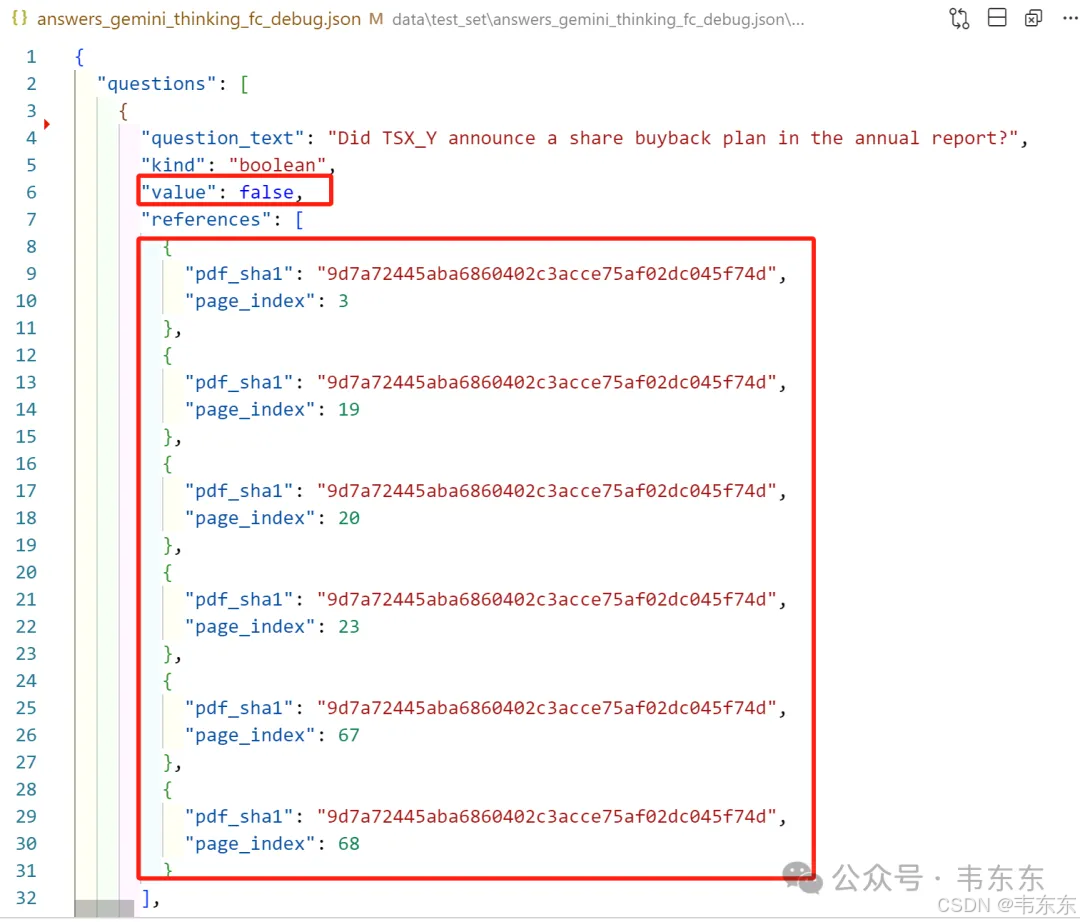
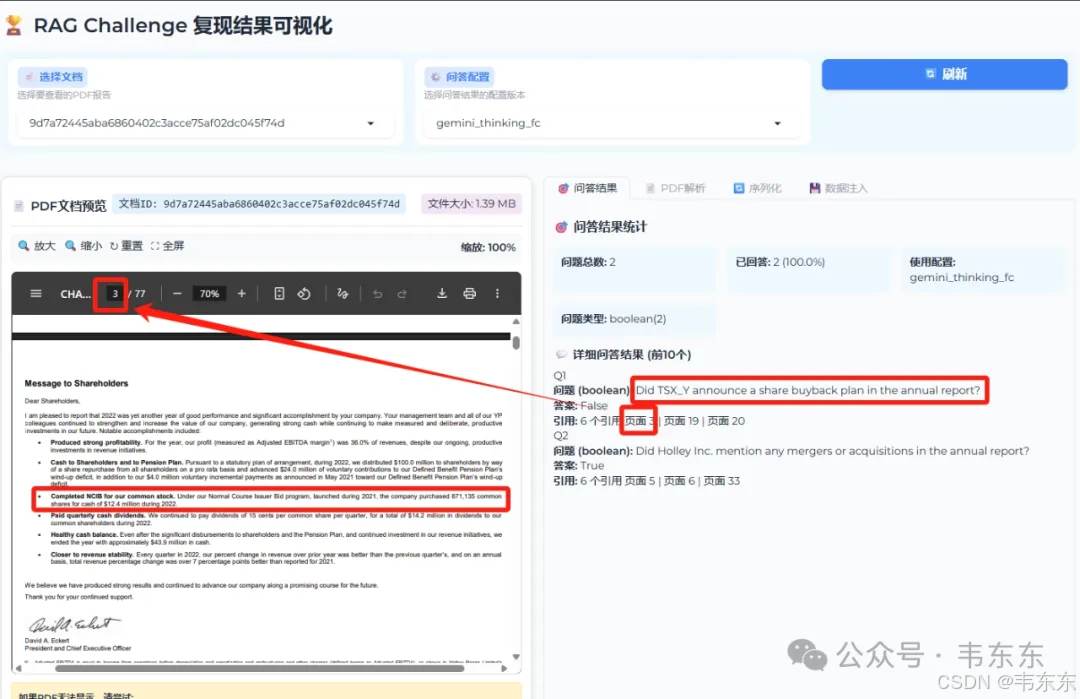
第3页包含CEO致股东信,其中明确提到:> "Completed NCIB for our common stock. Under our Normal Course Issuer Bid program, launched during 2021, the company purchased 871,135 common shares for cash of $12.4 million during 2022."💡 这段话是完美的反证:关键词分析:"Completed" - 过去完成时,表示已结束的活动"purchased... during 2022" - 明确的过去时态"launched during 2021" - 该计划是2021年启动的,2022年完成逻辑推理:✅ 有回购活动 - 证明文档确实涉及股票回购内容❌ 没有新计划宣布 - 描述的是已完成的历史活动,不是未来计划
TSX_Y在年报中确实提到了股票回购,但这是对过去已完成活动的报告,而非对未来新计划的宣布。系统准确区分了"回顾历史活动"和"宣布未来计划"这一微妙差异。
问题 2:
系统答案: 是
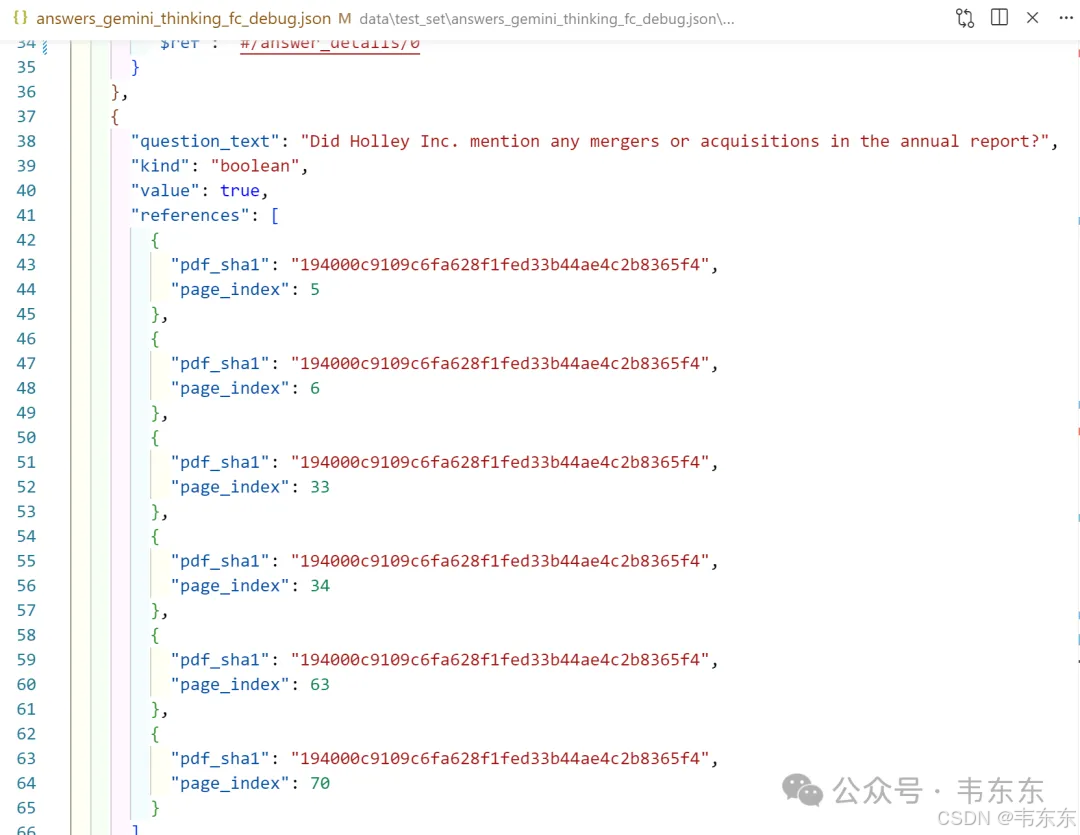
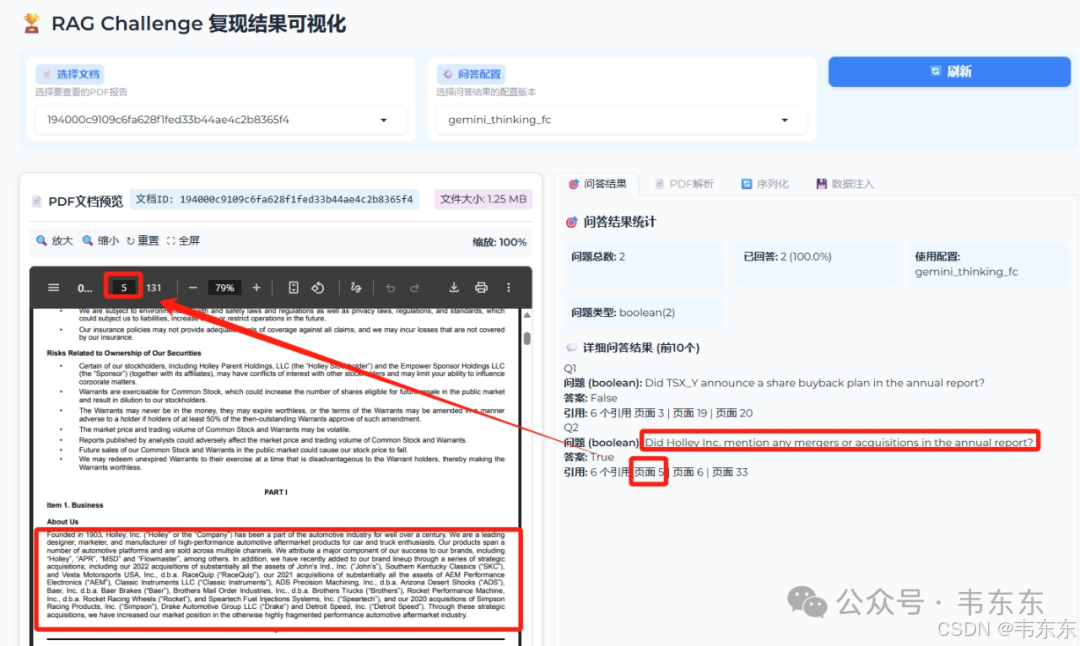
🎯 第5页 - "About Us"部分(最直接证据)根据系统分析,第5页在公司介绍部分明确列举了具体的收购案例:> "In addition, we have recently added to our brand lineup through a series of strategic acquisitions, including our 2022 acquisitions of substantially all the assets of John's Ind., Inc. ('John's'), Southern Kentucky Classics ('SKC'), and Vesta Motorsports USA, Inc., d.b.a. RaceQuip ('RaceQuip'), our 2021 acquisitions of substantially all the assets of AEM Performance Electronics ('AEM'), Classic Instruments LLC ('Classic Instruments'), ADS Precision Machining, Inc., d.b.a. Arizona Desert Shocks ('ADS'), Baer, Inc, d.b.a. Baer Brakes ('Baer'), Brothers Mail Order Industries, Inc., d.b.a. Brothers Trucks ('Brothers'), Rocket Performance Machine, Inc., d.b.a. Rocket Racing Wheels ('Rocket'), and Speartech Fuel Injections Systems, Inc. ('Speartech'), and our 2020 acquisitions of Simpson Racing Products, Inc. ('Simpson'), Drake Automotive Group LLC ('Drake') and Detroit Speed, Inc. ('Detroit Speed')."💡 为什么第5页是最佳证据:✅ 明确性 - 直接使用"acquisitions"关键词✅ 具体性 - 列出具体的被收购公司名单✅ 时间性 - 涵盖2020-2022年的收购活动✅ 位置重要 - 在公司简介部分,说明M&A是核心业务策略📋 第6页 - "Business Strategy"部分(战略确认)第6页提供了战略层面的证据:> "Accelerate Growth Through Continued M&A" 和 "Business Combination"
推理亮点: 系统成功识别了各种并购术语,并准确定位到相关章节
6、工程经验总结
经过以上的初步验证之后,最后再来梳理下值得参考的核心工程经验,各位可以视情况在其他项目中进行进一步的测试使用。
6.1、Docling 定制化改造:深度工程实践
虽然 Docling 是个挺强大的 PDF 解析器,但其原版功能分散在不同配置中,无法组合使用。Ilya Rice 需要同时获得高质量的表格解析、图片处理和结构化 JSON 输出。
自定义 JsonReportProcessor 类
# src/pdf_parsing.py 第250行 - 完全重写的处理器class JsonReportProcessor:def assemble_report(self, conv_result, normalized_data=None):assembled_report = {}assembled_report['metainfo'] = self.assemble_metainfo(data)assembled_report['content'] = self.assemble_content(data)assembled_report['tables'] = self.assemble_tables(conv_result.document.tables, data) assembled_report['pictures'] = self.assemble_pictures(data)
统一数据格式: 将 Docling 的分散输出整合为统一的 JSON 结构
页面标准化: 通过 _normalize_page_sequence 方法填补缺失页面,确保页码连续性
双格式表格: 同时生成 Markdown 和 HTML 格式,为后续序列化提供选择
表格处理的工程突破
# 关键改造:表格转Markdown的鲁棒性处理def _table_to_md(self, table):try:md_table = tabulate(table_data[1:], headers=table_data[0], tablefmt="github")except ValueError:# 容错处理:禁用数字解析避免格式错误md_table = tabulate(table_data[1:], headers=table_data[0], tablefmt="github", disable_numparse=True)
双重容错机制确保即使在表格格式异常时也能生成可用的 Markdown 输出。
注:debug版本的PDF解析结果相比正常版本保留了完整的Docling原始数据结构。由于Ilya Rice对Docling进行了深度定制,debug数据帮助验证:
1、组引用展开: expand_groups方法是否正确处理了$ref。
2、文本处理: _process_text_reference是否保留了必要信息。
3、数据完整性: 自定义的JsonReportProcessor是否遗漏关键数据。
6.2、"一文一库"架构的工程价值
这是本项目最核心的架构创新,通过为每个 PDF 文档创建独立的向量数据库,实现了精度与性能的双重提升。
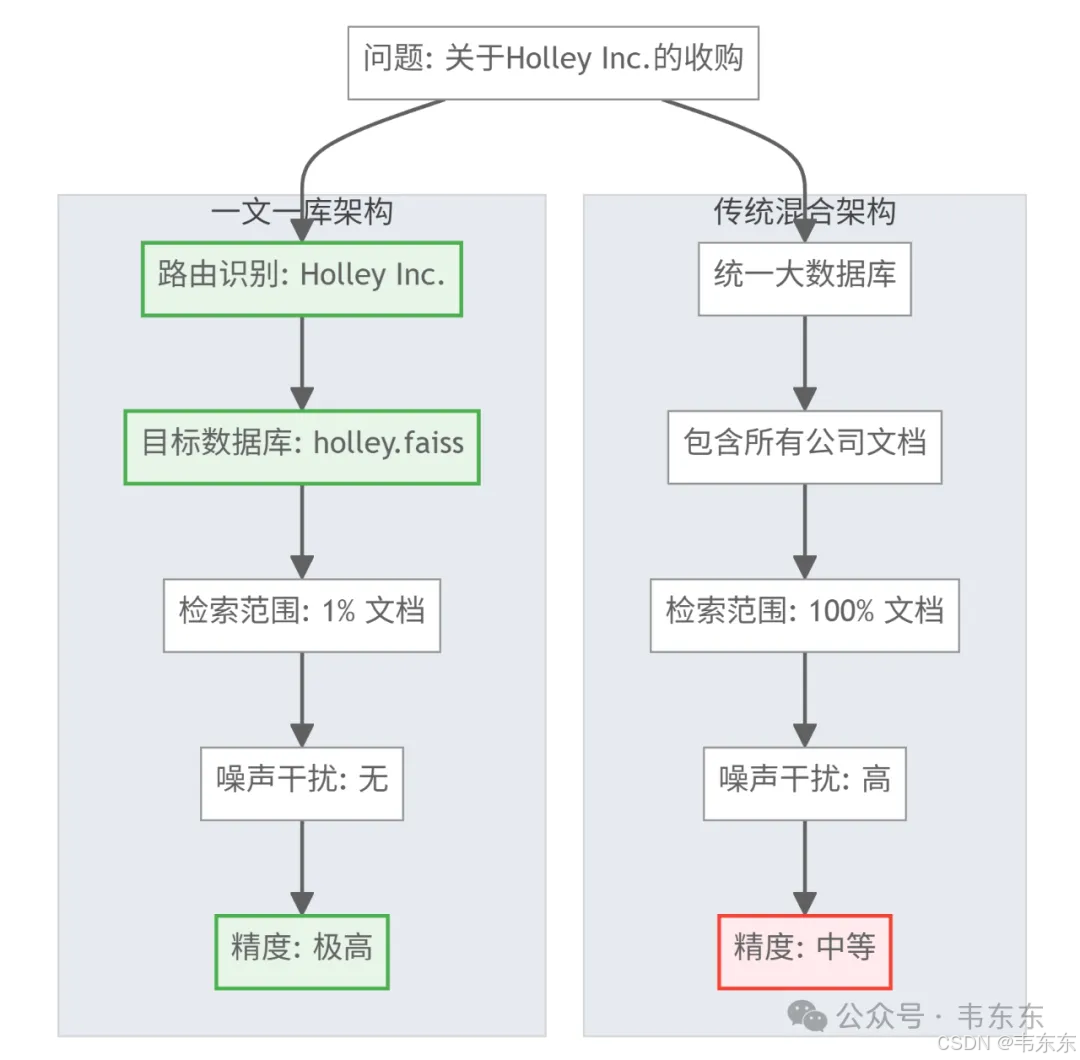
通过物理隔离实现了检索精度的本质提升。传统 RAG 系统把所有文档混合在一个大数据库中,导致检索时面临严重的噪声干扰。这个项目创新性地为每个 PDF 创建独立的 FAISS 数据库,配合智能路由机制,将检索范围从 100%文档缩小到 1%,很好的消除了跨文档噪声。
# src/ingestion_free.py 第101行 - 独立数据库创建faiss_file_path = output_dir / f"{sha1_name}.faiss"faiss.write_index(index, str(faiss_file_path))
通过 CSV 元数据进一步实现"一文一库"的精准路由:

# src/questions_processing.py 第162行 - 智能公司名匹配
def _extract_companies_from_subset(self, question_text: str) -> list[str]:
found_companies = []
# 关键优化:按长度倒序排列,避免短名称误匹配
company_names = sorted(self.companies_df['company_name'].unique(),
key=len, reverse=True)
for company in company_names:
escaped_company = re.escape(company)
# 精确边界匹配:确保完整公司名匹配
pattern = rf'{escaped_company}(?:\W|$)'
if re.search(pattern, question_text, re.IGNORECASE):
found_companies.append(company)
# 匹配后移除,防止重复匹配
question_text = re.sub(pattern, '', question_text, flags=re.IGNORECASE)这种架构天然支持多租户场景,不同客户的数据物理隔离,既保证了安全性又提升了检索精度。
6.3、"小块检索,大块喂食"策略
这是平衡检索精度与上下文完整性的工程智慧,通过精细的切块策略和父页面回溯机制,实现了最优的信息检索效果。
# src/text_splitter.py 第75行 - 300 token切块参数
def _split_page(self, page: Dict[str, any], chunk_size: int = 300, chunk_overlap: int = 50):
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4o",
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)300-token 是 Ilya Rice 经过实践验证的最优平衡点,既保证了语义单元的完整性,又避免了过小切块导致的上下文碎片化。50-token 重叠确保了跨块信息的连续性。
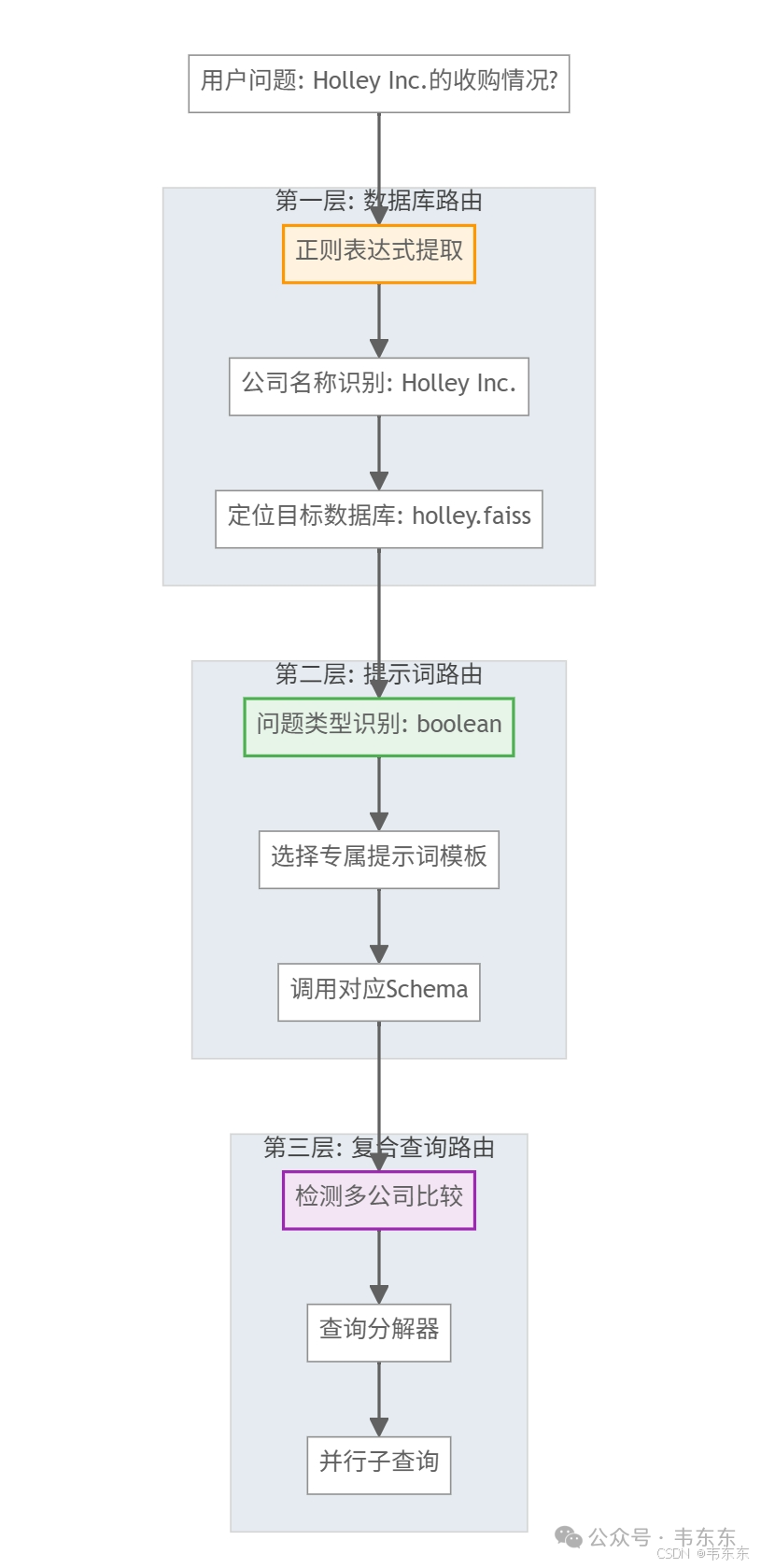
6.4、多层路由系统的工程实践
系统设计了三层渐进式路由机制,从粗粒度到细粒度实现精准的查询分发,体现了分层解耦的架构思想。
# src/questions_processing.py 第162-180行 - 智能公司路由
def _extract_companies_from_subset(self, question_text: str) -> list[str]:
found_companies = []
company_names = sorted(self.companies_df['company_name'].unique(), key=len, reverse=True)
for company in company_names:
escaped_company = re.escape(company)
pattern = rf'{escaped_company}(?:\W|$)'
if re.search(pattern, question_text, re.IGNORECASE):
found_companies.append(company)code按公司名称长度逆序排列避免了短名称的误匹配,如"Apple Inc."会优先于"Apple"被匹配,体现了细致的工程考量。
6.5、LLM 重排序的工程化应用
创新性地引入轻量级 LLM 作为"二次精排器",通过加权融合向量相似度和语义相关性(本次复现中没有测试这部分)。
# src/reranking.py 第108-113行 - 加权排序策略
def rerank_documents(self, query: str, documents: list, llm_weight: float = 0.7):
vector_weight = 1 - llm_weight
doc_with_score["combined_score"] = round(
llm_weight * ranking["relevance_score"] +
vector_weight * doc['distance'],
4
)ThreadPoolExecutor 实现批量重排序,提升处理效率。当 LLM 响应不完整时自动填充默认评分,确保系统稳定性。
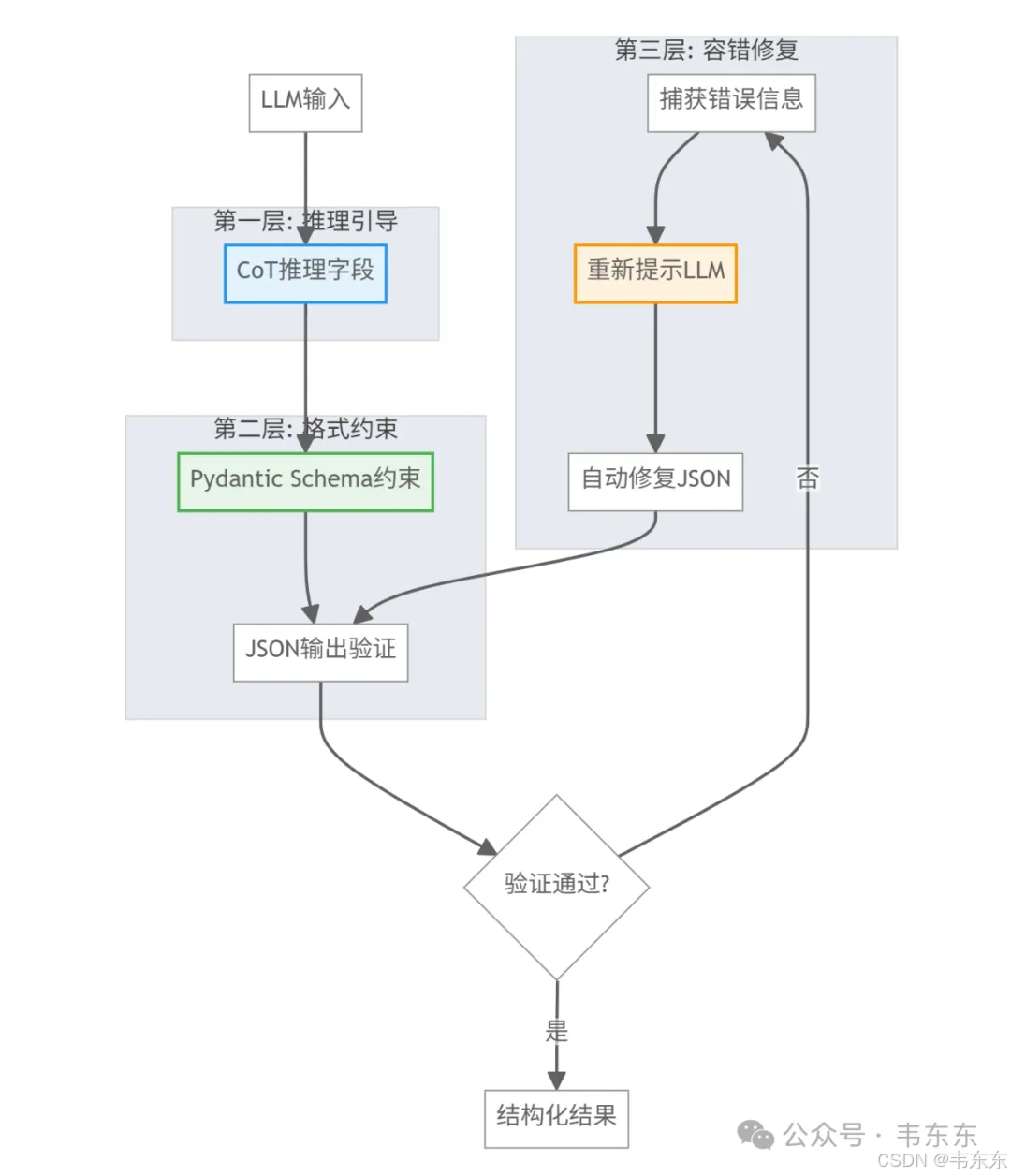
6.6、结构化输出的容错工程
通过 CoT 推理、Schema 约束和自动修复的三层保障,实现了 100%可用的结构化输出,是生产级系统的关键特征。
# src/prompts.py 示例 - CoT推理字段设计
class AnswerSchema(BaseModel):
step_by_step_analysis: str = Field(description="详细的逐步分析过程")
reasoning_summary: str = Field(description="推理过程的简洁总结,约50字")
final_answer: Union[str, int, float, bool]reasoning 字段不仅提供了可解释性,更重要的是引导模型进行逻辑思考,显著提升答案质量。自动重试机制确保系统在面对格式错误时的自愈能力。
6.7、提示词即代码(Prompt-as-Code)的管理实践
把提示词工程化为可版本控制、可模块复用的代码资产,也体现了现代软件工程在 AI 应用中的最佳实践。
# src/prompts.py 结构示例
class SystemPrompts:
base_instruction = "您是一个专业的财务分析师..."
class SchemaDefinitions:
boolean_answer = BooleanAnswerSchema
numeric_answer = NumericAnswerSchema
class OneShots:
boolean_example = {
"question": "示例问题",
"step_by_step_analysis": "详细分析过程",
"final_answer": True
}在企业级 RAG 系统中,提示词是核心业务逻辑的载体,需要像对待代码一样进行专业化管理,包括版本控制、测试验证和持续优化。
7、写在最后
这个冠军方案虽然在标准化竞赛环境中表现的可圈可点,但走向企业生产环境,仍有许多更现实的问题需要克服:
7.1数据复杂性的升级
竞赛中的 PDF 格式虽然布局复杂,但也相对标准,而企业实际场景可能涉及扫描件、多语言混排、非标准表格等更复杂的文档类型。原方案的 Docling 定制化改造思路可以借鉴,但具体实现需要针对新场景重新优化。
7.2业务逻辑的深度耦合:
"一文一库"架构虽然巧妙,但企业实际应用中可能需要跨文档关联分析、历史版本对比、实时数据更新等更复杂的业务需求。路由机制需要从简单的公司名匹配升级为多维度的业务实体识别。
7.3工程经验的迁移与创新
这个获胜方案最大的价值不在于特定的技术栈选择,而在于其系统性的工程思维。这些工程原则在垂直行业落地时具有普适性,但具体实现需要结合行业特点进行深度定制。
1、模块化设计使得技术栈可以灵活替换,为企业的渐进式升级提供了可能
2、配置驱动的架构让同一套代码可以适配不同的业务场景和成本要求
3、验证驱动的开发流程确保了迭代优化的方向正确性
最后还是那话,技术毕竟只是工具,产生业务价值才是目的。在 LLM 能力还没有明显收敛的今天,工程化能力可能比单纯的算法优势更能决定企业大模型应用落地的效果天花板。也正如 Ilya Rice 在竞赛中的表现所证明的,RAG 的魔力在于细节。如何基于行业 Know-how 进行快速试错,并系统性地参考不同行业的最佳实践,是每一个一线从业者都需要持续回答的命题。
项目复现的中间结果文件、可视化组件源码,以及对原项目进行嵌入和问答模型的改造及中文注释等内容,已发布在知识星球中,按需自取。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)