LangGraph 持久化
·
许多 AI 应用程序需要内存来跨多个交互共享上下文。在 LangGraph 中,通过 检查点 为任何 StateGraph 提供内存。
在创建任何 LangGraph 工作流时,您可以通过以下方式设置它们以持久保存其状态
- 一个 检查点,例如 MemorySaver
- 在编译图时调用
compile(checkpointer=my_checkpointer)。
import os
import getpass
# 导入所需的类型注解和模块
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
# 定义一个状态类,包含一个消息列表,消息列表带有 add_messages 注解
class State(TypedDict):
messages: Annotated[list, add_messages]
# 从 langchain_core.tools 导入工具装饰器
from langchain_core.tools import tool
# 定义一个名为 search 的工具函数,用于模拟网络搜索
@tool
def search(query: str):
"""通过网络来搜索人名,返回人民的相关信息"""
# 这是实际实现的占位符
print("搜索调用了",str)
return "阿里是一个人名,原名是张大胆,12岁"
# 将工具函数存入列表
tools = [search]
from langgraph.prebuilt import ToolNode
# 创建一个 ToolNode 实例,传入工具列表
tool_node = ToolNode(tools)
# 从 langchain_openai 导入 ChatOpenAI 模型
from langchain_openai import ChatOpenAI
# 创建一个 ChatOpenAI 模型实例,设置 streaming=True 以便可以流式传输 tokens
model = ChatOpenAI(base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-3ad75cfac6b4431********3d473b2a", model="qwen-plus")
# 将工具绑定到模型上
bound_model = model.bind_tools(tools)
# 导入 Literal 类型
from typing import Literal
# 定义一个函数,根据状态决定是否继续执行 返回值类型被注解为 字面量类型,即只能返回这两个字符串之一:"action" 或 "__end__"
def should_continue(state: State) -> Literal["action", "__end__"]:
"""Return the next node to execute."""
last_message = state["messages"][-1]
# 如果没有函数调用,则结束
if not last_message.tool_calls:
return "__end__"
# 否则继续执行
return "action"
# 定义一个函数调用模型
def call_model(state: State):
response = bound_model.invoke(state["messages"])
# 返回一个列表,因为这将被添加到现有列表中
return {"messages": response}
# 从 langgraph.graph 导入 StateGraph 和 START
from langgraph.graph import StateGraph, START
# 定义一个新的图形工作流
workflow = StateGraph(State)
# 添加两个节点,分别是 agent 和 action
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
# 设置入口点为 agent
workflow.add_edge(START, "agent")
# 添加条件边,根据 should_continue 函数决定下一个节点
workflow.add_conditional_edges(
"agent",
should_continue,
)
# 添加从 action 到 agent 的普通边
workflow.add_edge("action", "agent")
# 从 langgraph.checkpoint.memory 导入 MemorySaver
from langgraph.checkpoint.memory import MemorySaver
# 创建一个 MemorySaver 实例
memory = MemorySaver()
# 编译工作流,生成一个 LangChain Runnable
app = workflow.compile(checkpointer=memory)
# 从 langchain_core.messages 导入 HumanMessage
from langchain_core.messages import HumanMessage
# 设置配置参数
config = {"configurable": {"thread_id": "2"}}
# 创建一个 HumanMessage 实例,内容为 "hi! I'm bob"
input_message = HumanMessage(content="hi! I'm bob")
# 在流模式下运行应用程序,传入消息和配置,逐个打印每个事件的最后一条消息
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
# 创建一个 HumanMessage 实例,内容为 "what is my name?"
input_message = HumanMessage(content="hat is my name?")
# 在流模式下运行应用程序,传入消息和配置,逐个打印每个事件的最后一条消息
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
1. 第一次 HumanMessage(content="hi! I'm bob")
{"messages": [input_message]} 作为消息 传入 call_model
def call_model(state: State):
response = bound_model.invoke(state["messages"])
# 返回一个列表,因为这将被添加到现有列表中
return {"messages": response}返回的response是一个AIMessage。它会自动把本次返回的 response(单条或列表)追加到现有 state["messages"] 末尾,而不是覆盖原列表。
class State(TypedDict):
messages: Annotated[list, add_messages]messages: Annotated[list, add_messages] 是 LangGraph 状态管理里的 “一行代码搞定消息追加” 的写法,核心作用:
-
告诉图:我这个字段是 消息列表
-
再告诉图:每当节点返回新消息时,不要覆盖旧列表,而是 自动追加(reduce)
所以,无论 response 是一条 AIMessage 还是多条消息,最终效果都是:旧列表 + 新消息 → 新列表。
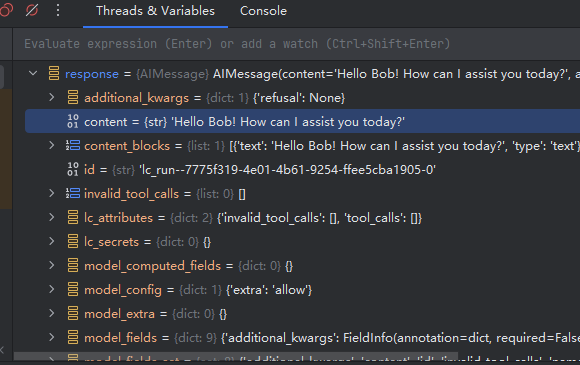
提问为涉及到工具调用,最终 should_continue判断走向__end__
第二次调用HumanMessage(content="what's my name?")
打印如下:
================================ Human Message =================================
hi! I'm bob
================================== Ai Message ==================================
Hi Bob! How can I assist you today?# 在流模式下运行应用程序,传入消息和配置,逐个打印每个事件的最后一条消息
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()第二次返送人工消息的时候,state包含了之前的对话消息。
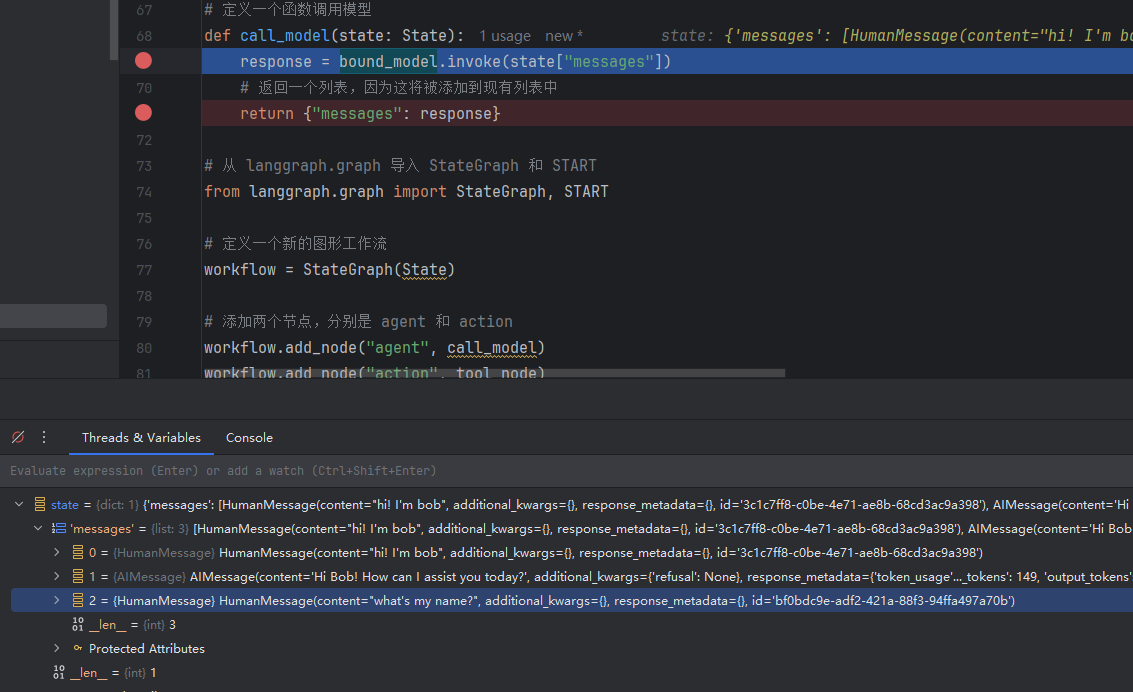
================================ Human Message =================================
what's my name?
================================== Ai Message ==================================
Your name is Bob! 😊调用Tool
上述节点未调用Tool,因为大模型任务该问题不需要调用。
# 定义一个名为 search 的工具函数,用于模拟网络搜索
@tool
def search(query: str):
"""通过网络来搜索人名,返回人民的相关信息"""
# 这是实际实现的占位符
print("搜索调用了",str)
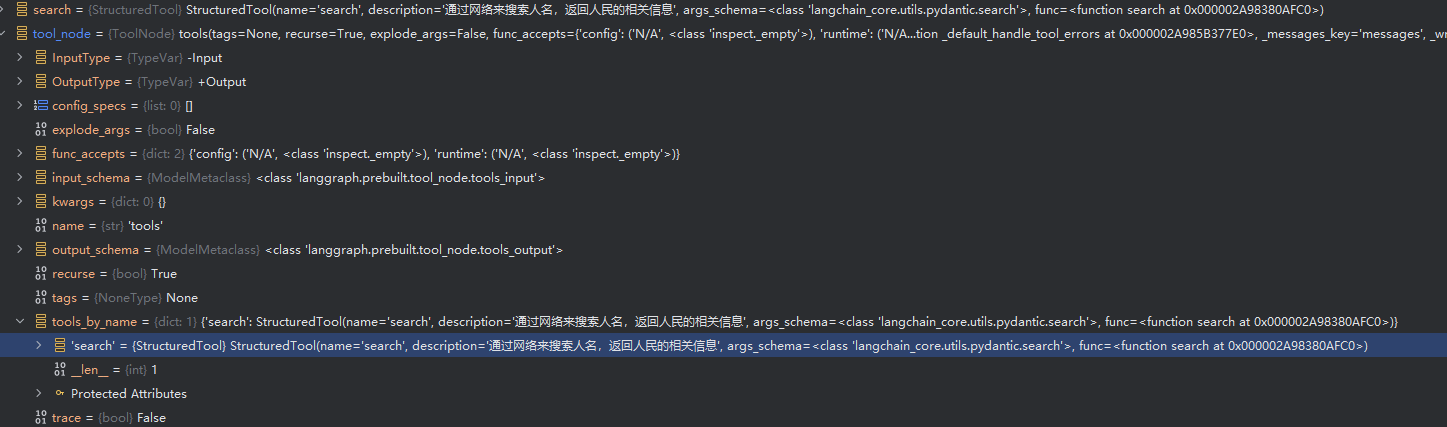
return "阿里是一个人名,原名是张大胆,12岁"# 创建一个 ToolNode 实例,传入工具列表 tool_node = ToolNode(tools)
调用大模型返回结果,结果中包含了tool_calls列表,会传入哪些参数,tool名词等。
然后 should_continue表条件判断指向下个节点action,即调用search函数。action下一个边设置为agent即 把结果又给到大模型,让大模型组织回复。
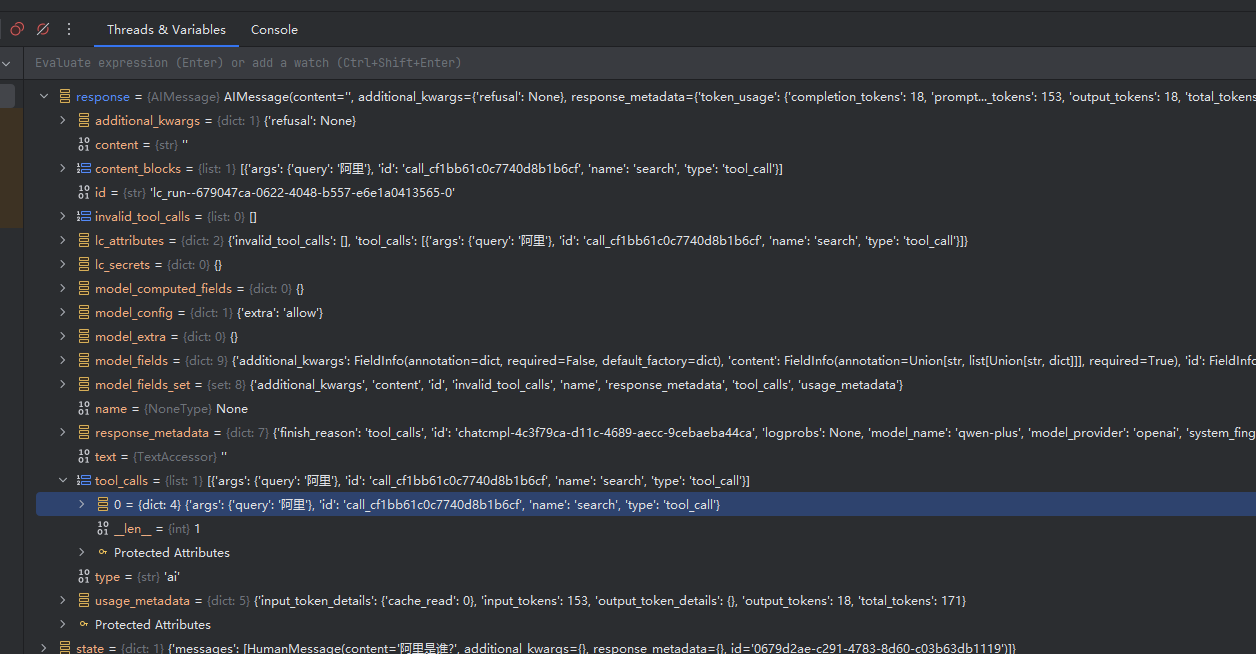
================================ Human Message =================================
阿里是谁?
================================== Ai Message ==================================
Tool Calls:
search (call_cf1bb61c0c7740d8b1b6cf)
Call ID: call_cf1bb61c0c7740d8b1b6cf
Args:
query: 阿里
搜索调用了 <class 'str'>
================================= Tool Message =================================
Name: search
阿里是一个人名,原名是张大胆,12岁

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)