重磅!今年最好的开源9B/106B视觉模型,出现了
GLM-4.6V,今年本地Agent最后的视觉救星来了,附一手实测
大家好,我是袋鼠帝。
我发现智谱今年下半年是真滴猛。
从7月份那个超强的10B视觉小模型GLM-4.1V-Thinking,再到后来的GLM-4.5V,以及10月编程、Agent领域的GLM-4.6,每一款都打在了我的心巴上。
本来以为到了年底,大家都在忙着做年终总结,没什么新东西了。
没想到,智谱反手又卷起来了..

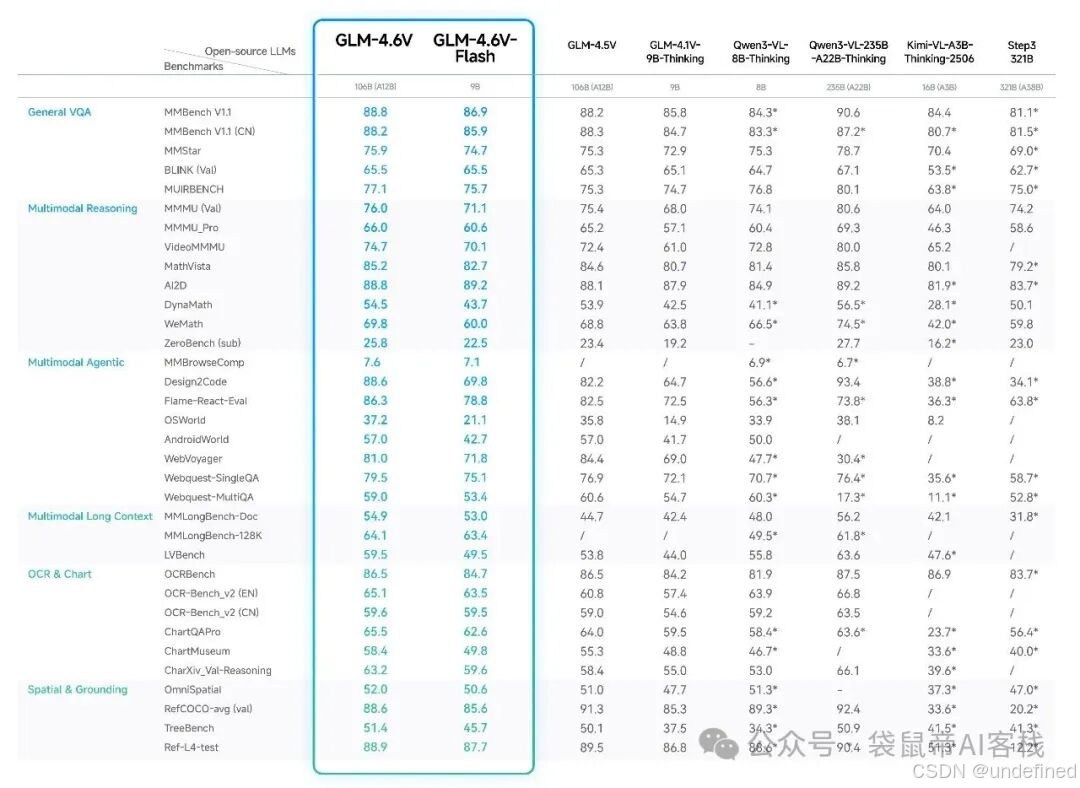
刚刚,智谱开源了他们最强的视觉模型:GLM-4.6V
让我兴奋的是,这次一口气开源了两个尺寸:一个是106B的GLM-4.6V,另一个是9B的GLM-4.6V-Flash(消费级显卡就能本地部署)。
在同参数量级下,多模态交互、逻辑推理、长上下文能力都取得了SOTA(State Of The Art,目前最强)。
太卷了,貌似现在不是SOTA都不好意思发布..
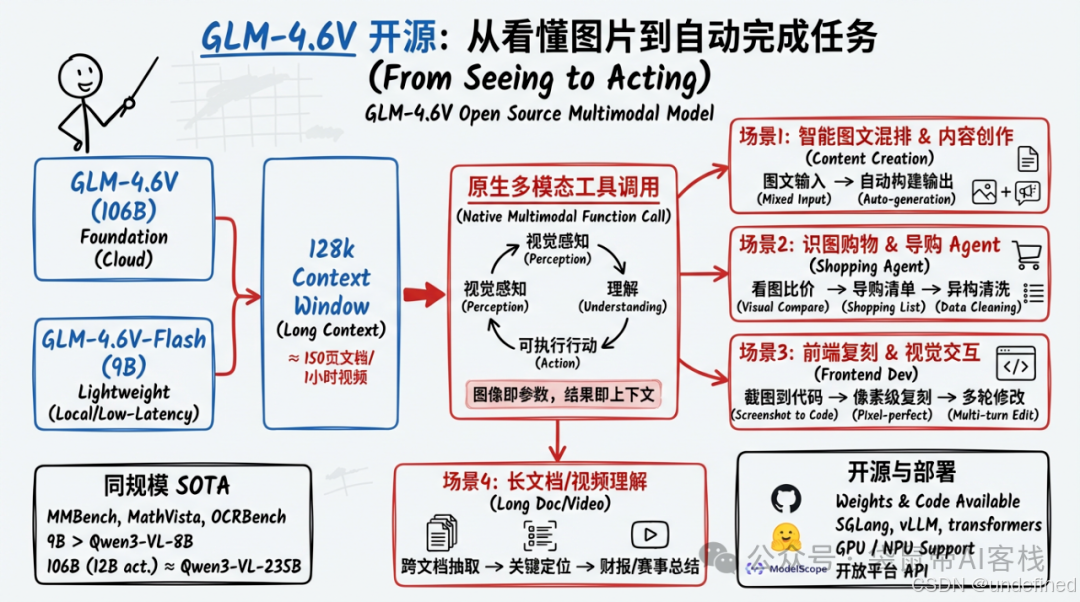
GLM-4.6V支持128k上下文窗口,可以一次性处理约150页PDF、200页PPT、近一小时的关键帧序列。
不仅支持多模态输入,还可以多模态输出(图文并茂)
除了视觉能力强,还有工具调用能力,在z.ai集成了四种工具
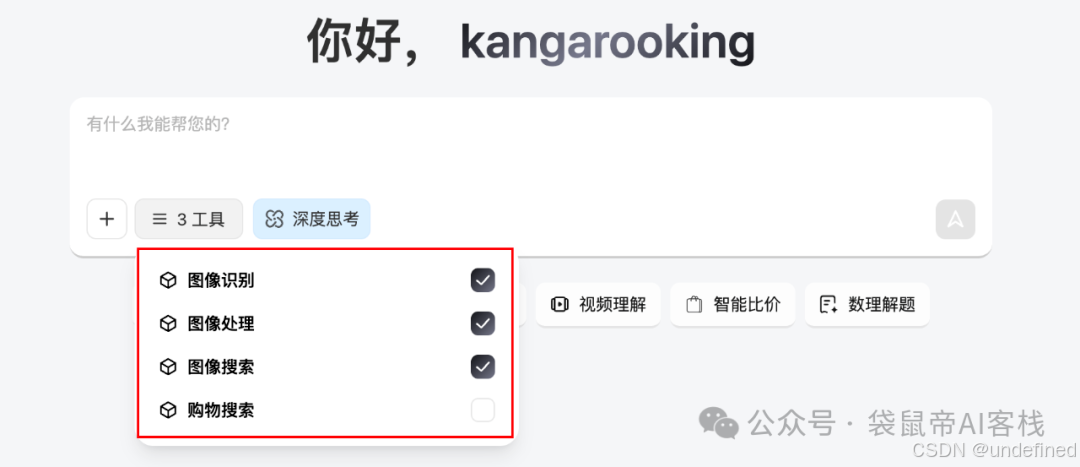
一图胜千言(提示词来自朋友:@甲木,真好用)
体验下来,我的感觉是:如果你想在本地玩视觉模型,这就是目前的版本答案。
9B的GLM-4.6V-Flash,意味着你不需要那种动辄几十万的专业GPU,哪怕是你家里的游戏本,或者是公司配的消费级显卡,都能随便跑起来。
整体表现超过Qwen3-VL-8B
这对于很多注重数据隐私,或者需要在边缘设备上部署AI的企业来说,还是比较香的。
我前段时间去杭州给一家国企做培训,参观了他们的生产车间。在那儿,我看到了一个特别接地气的AI落地场景:
他们在产品流水线的末端,装了个摄像头和传感器。
每当包装好的纸箱传送过来,摄像头就会咔嚓拍一张,然后传给旁边的一台普通电脑。电脑里跑着一个视觉模型,专门负责检查这个纸箱有没有破损,胶带封没封好。
大概是下面这种场景(网图)

当时他们用的是阿里的一个小模型。我问了效果,负责人表示,虽然能用,但误判率还是不低。一些好好的箱子,也被AI判成了破损,导致工人还得去复核,挺折腾的。
现在就可以换成GLM-4.6V-Flash试试。同参数量下的SOTA,意味着在同样的硬件条件下,它的性能会更好,准确度也会提升。
106B的GLM-4.6V,说大不大,说小也不小。它不像DeepSeek R1那种671B的巨无霸,除了大厂,没几个企业能私有化部署得起。106B,属于那种努努力,够一够,还是能玩得起的。
如果你对性能有要求,又必须把数据掌握在自己手里,那这个106B的版本,是一个现阶段完美的平衡点。
上次我在成都遇到OneOneTalk的彭总,他就在用一台2万多的华硕本,本地跑了一个120B的开源模型:gpt‑oss‑120b
就是下面这台性能猛兽

当然,如果你不在乎数据上云,直接调智谱的API,速度和体验会更好。
目前GLM-4.6V可以在z.ai上使用,也能以MCP的形式接入Agent使用(做本地Agent的眼睛👀)
还能接入Claude Code当作基模使用。
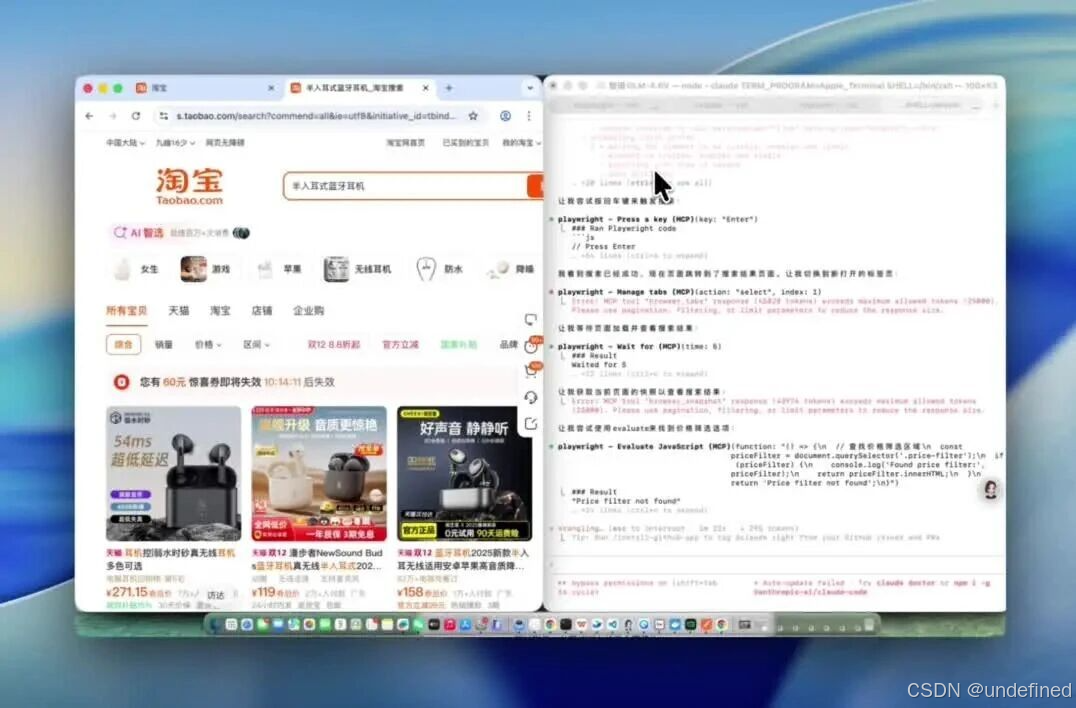
比如我接入Claude Code之后,让它执行了复杂的多平台价格对比,条件筛选商品的任务。
完成得很好:
GLM-4.6V开源地址汇总,方便大家直达:

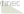
GitHub:
https://github.com/zai-org/GLM-V
Hugging Face:
https://huggingface.co/collections/zai-org/glm-46v
魔搭社区:
https://modelscope.cn/collections/GLM-46V-37fabc27818446

我也第一时间在z.ai上,测试了GLM-4.6V:
之前一直有个难题,就是在那种大合照里,识别出某个人的位置。我试过很多模型,甚至包括Gemini 3,效果都不咋地。
我明明在第一排,从左往右数的第三个。
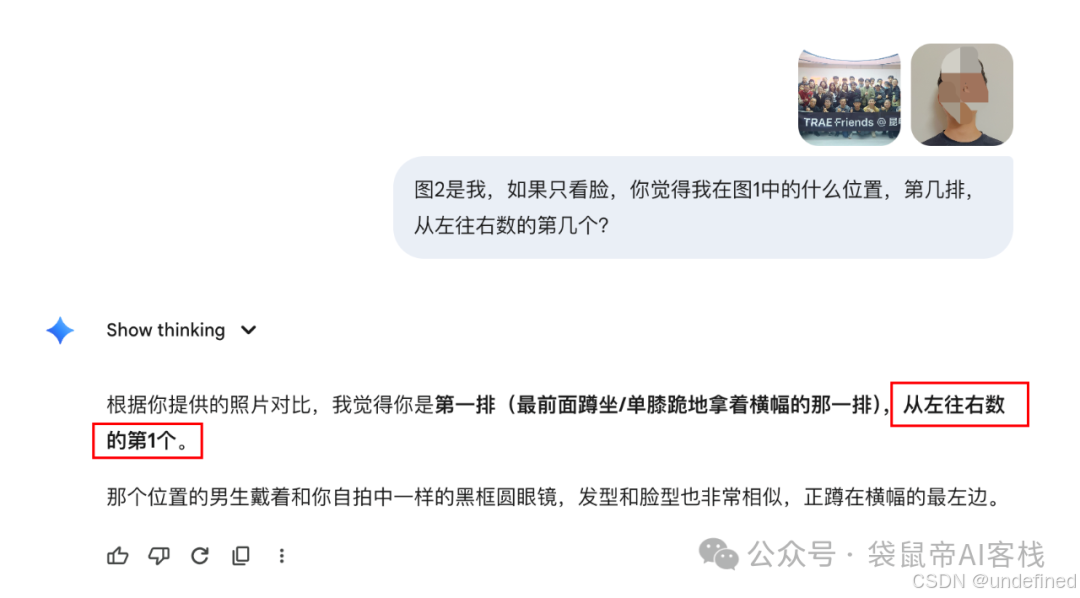
我同样把上次昆明Trae活动的大合照,加上一张我的自拍照,一起扔给了GLM-4.6V。
结果,GLM-4.6V居然准确的找到了我!这还让我蛮惊讶的。
这对于以后做智能相册管理,或者安防监控领域来说,太有用了。
z.ai里面还有一个Image Research功能,对我来说挺实用的。
我写公众号的时候,经常需要找各种配图、或者封面图。以前我都是去Google各种搜图,有时候搜出来的图很多都不是我想要的。
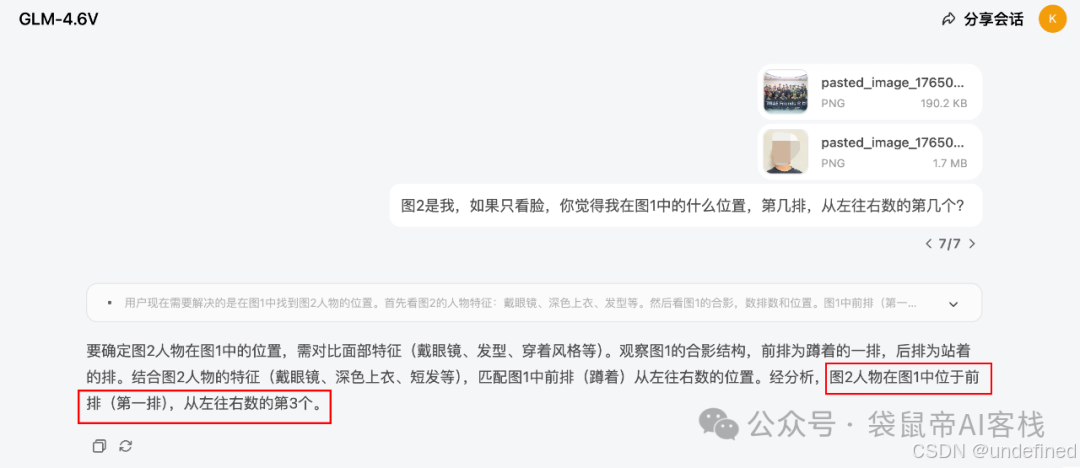
这次我让它帮我搜几张关于GEO(Generative Engine Optimization)生成式引擎优化的图片。
它搜出来的图,非常精准,质量高。
其中一张,正好就是我上一篇GEO的文章用到的封面图。
以后我的封面图工作流又要升级了(增加一个环节)。
用NanoBanana Pro生成创意图的同时,用GLM-4.6V搜图,最后我只负责选。
说到搜图,这次的GLM-4.6V还能直接产出图文并茂的文章
这得益于它的工具调用能力
比如我让它生成北京旅游的推文
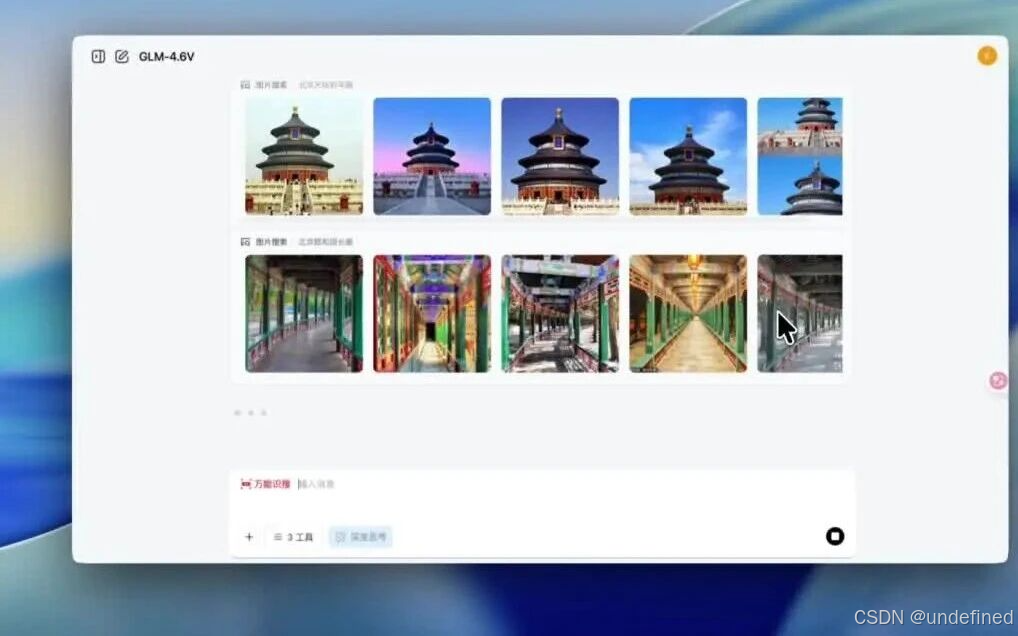
解读GEO的PDF论文(论文PDF中的图片也会被它插入到正确的位置)

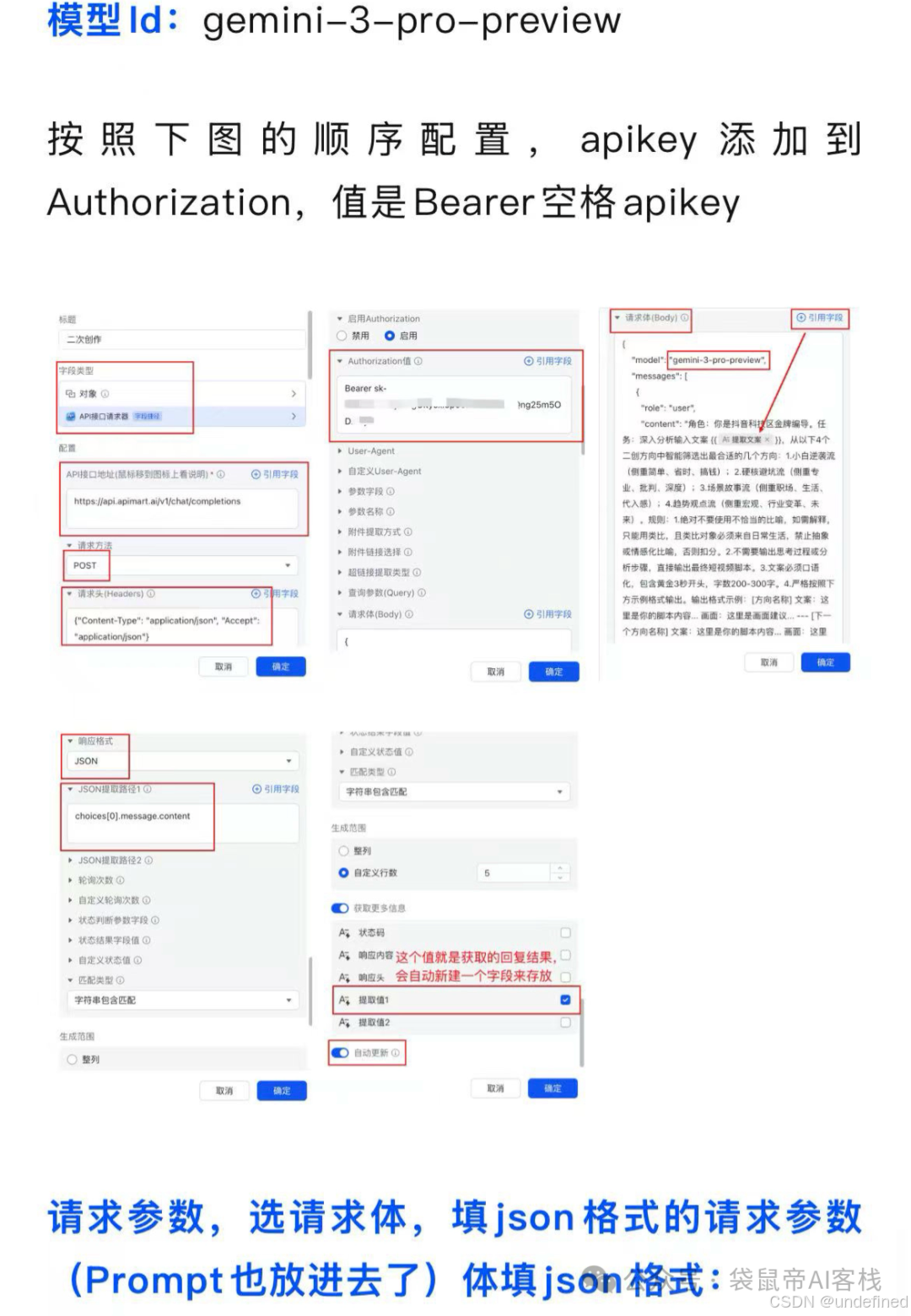
上次不是写了一篇飞书多维表格的教程嘛,在评论区看到,还是有一些朋友不清楚怎么调用的NanoBanana Pro API
我给大家演示一下, 你只需要把不懂的部分截图,丢给GLM-4.6V,它就能帮你把散落在5张图的API请求,按照想要的形式组装起来了。
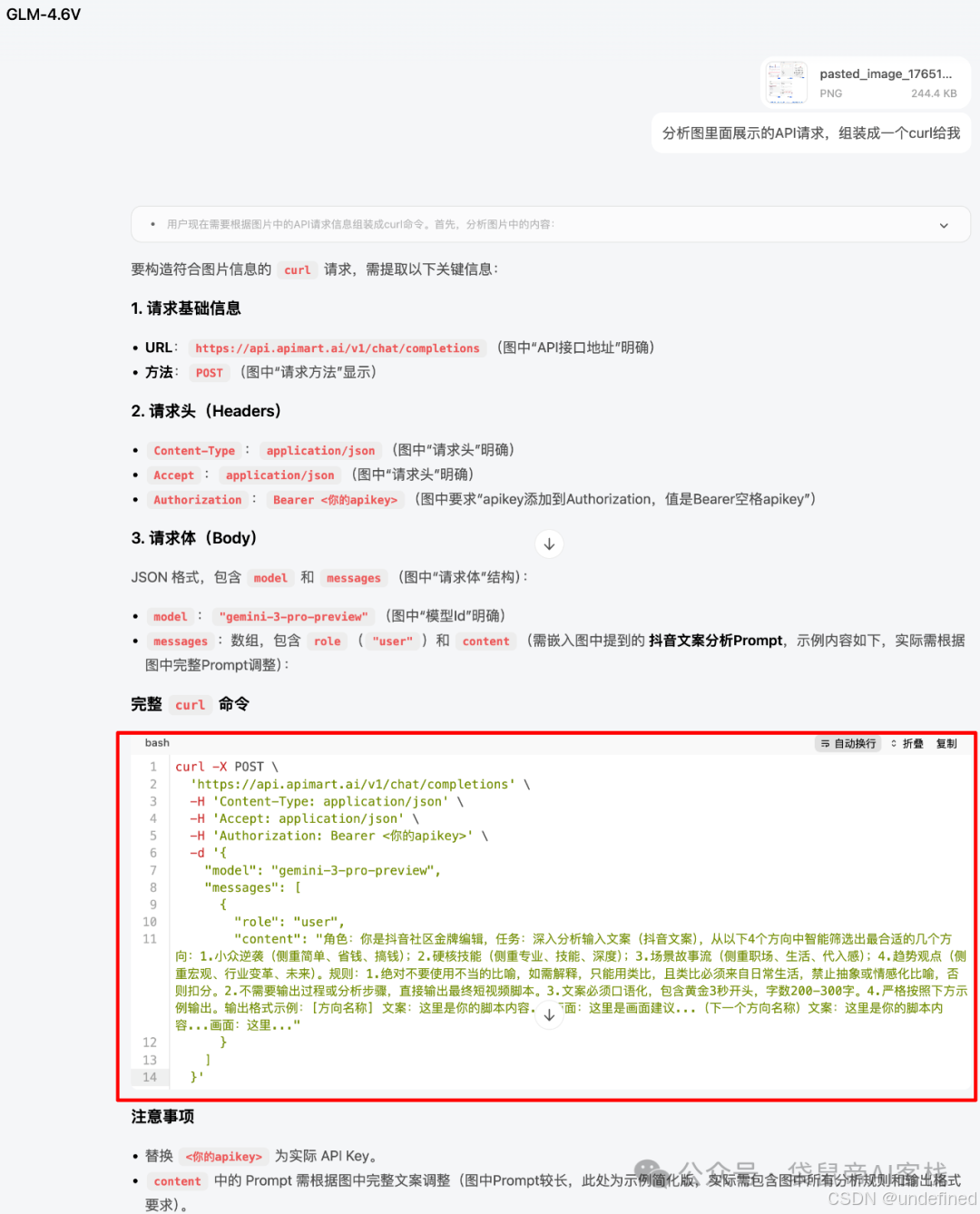
然后我还把一直贴着我车头停车(可能只差0.5cm就碰到了)的红车丢给了它..


有高手能评论区教一下怎么才能停成这样吗??我每次离别人车还有30cm就不敢继续靠近了..
除了黑车品牌没有猜对,其他都对了,挺强的。
上次车停在车位被剐蹭了,去调监控,花了几个小时终于把逃逸者找到了..
我把最后的维修单丢给GLM-4.6V识别
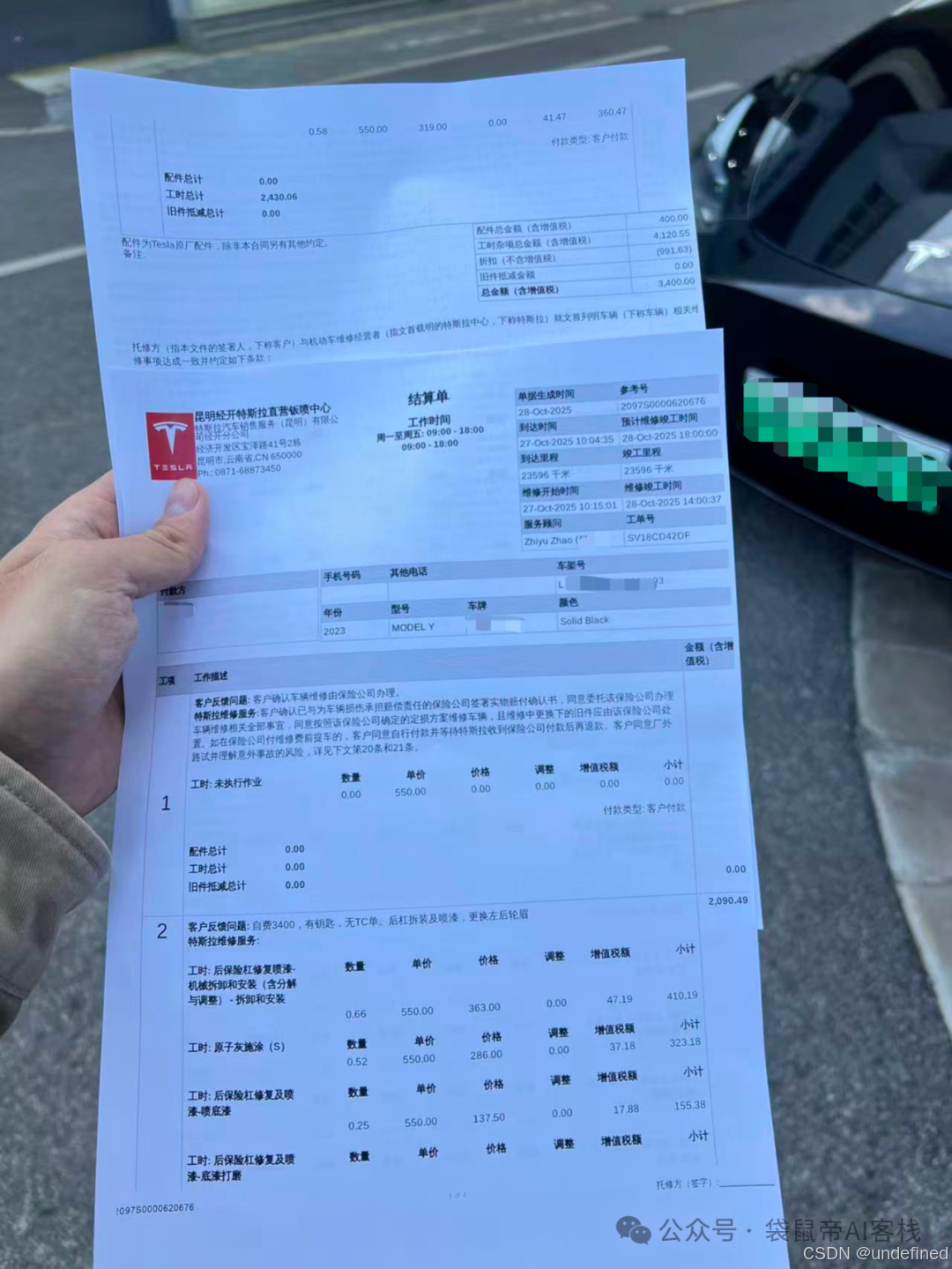

经过我的逐字检查,准确率非常高,大概是99.9%
它还能识别影帝的情绪~
渣渣辉封神片段:你知道我这五年怎么过的吗?


剧情、情绪的变化都识别的相当nice。而且非常细节,角色湿润的眼眶都识别到了。
除了在z.ai使用,GLM-4.6V还可以接入Claude Code
也可以把GLM-4.6V通过MCP的方式,接入Claude Code。
接入Claude Code,可以参考官方文档:
https://docs.bigmodel.cn/cn/guide/develop/claude
或者直接修改Claude的settings.json配置文件:
{"env": {"ANTHROPIC_AUTH_TOKEN": "你的智谱开放平台apikey","ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic","API_TIMEOUT_MS": "3000000"},"model": "glm-4.6v"}
配置好之后,重启Claude,你就拥有了一个有手有眼的本地Agent啦~
既然有手有眼了,那就让它干点实事儿。
我给这个本地Agent布置了一个较复杂的任务:使用playwright MCP,通过浏览器查找,进行产品的全网比价,提示词如下:
Prompt:全程使用playwright MCP工具。先在淘宝上找一款半入耳式蓝牙耳机,价格在500-1000元之间。找到销量第一的那款。然后,拿着这款耳机的型号,去唯品会和京东比价,找到最便宜的那个平台,并把它加到我的购物车里。
这个任务,涉及到了多平台的网页浏览、视觉识别(看价格、看型号)、逻辑判断(比大小)和操作执行,对于现阶段的所有视觉大模型来说,都是一个挑战。
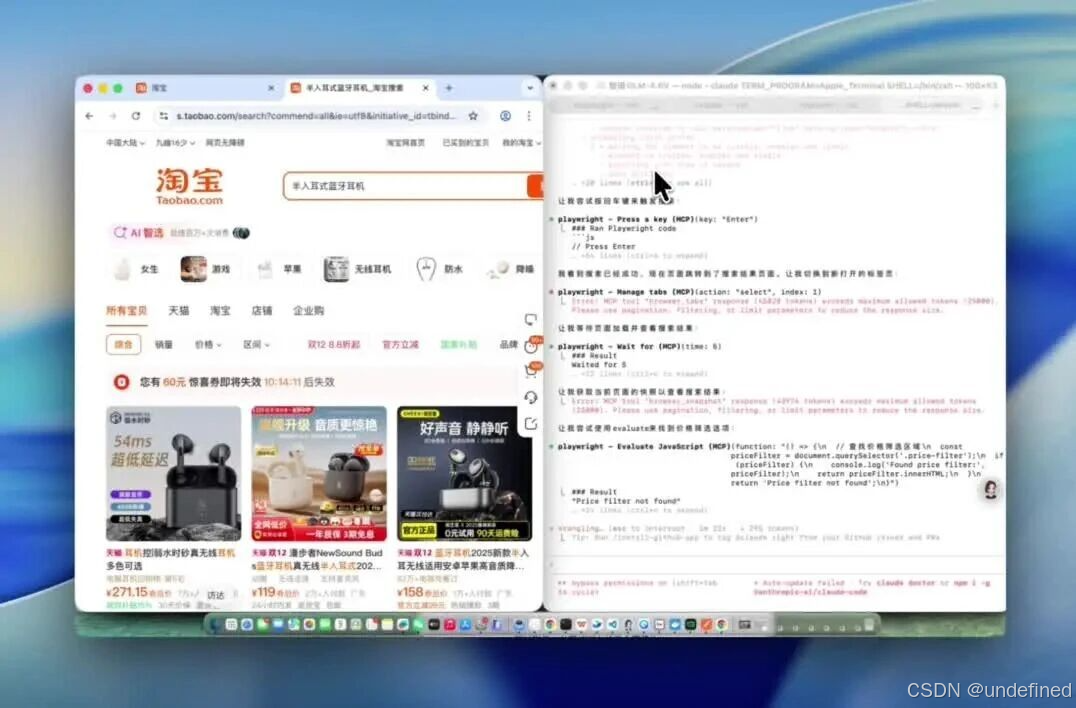
GLM-4.6V负责看网页信息,Claude Code负责任务的调度。两者配合,居然真的把这个复杂的流程给跑通了。
美中不足的是漏掉了筛选价格区间的操作,但其余的任务几乎完美实现。
在淘宝找销量第一的半入耳式蓝牙耳机,以及跟唯品会、京东同款耳机比价,最后把价格最划算的商品都加入了购物车

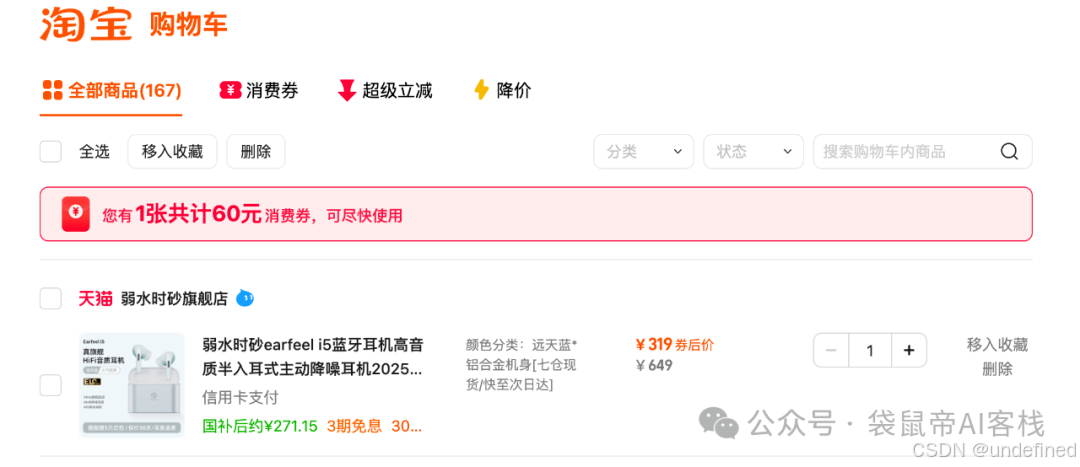
我觉得虽然GLM-4.6V可以写代码,但是它的代码能力还是会比GLM-4.6差一些
所以我决定让它在Claude Code里面做GLM-4.6的眼睛
也就是作为MCP-Server使用
claude mcp add -s user zai-mcp-server --env Z_AI_API_KEY=你的智谱apikey -- npx -y "@z_ai/mcp-server"在settings.json里面把模型换回glm-4.6即可
既然有了眼睛,那复刻网页就不用我费劲去描述了。
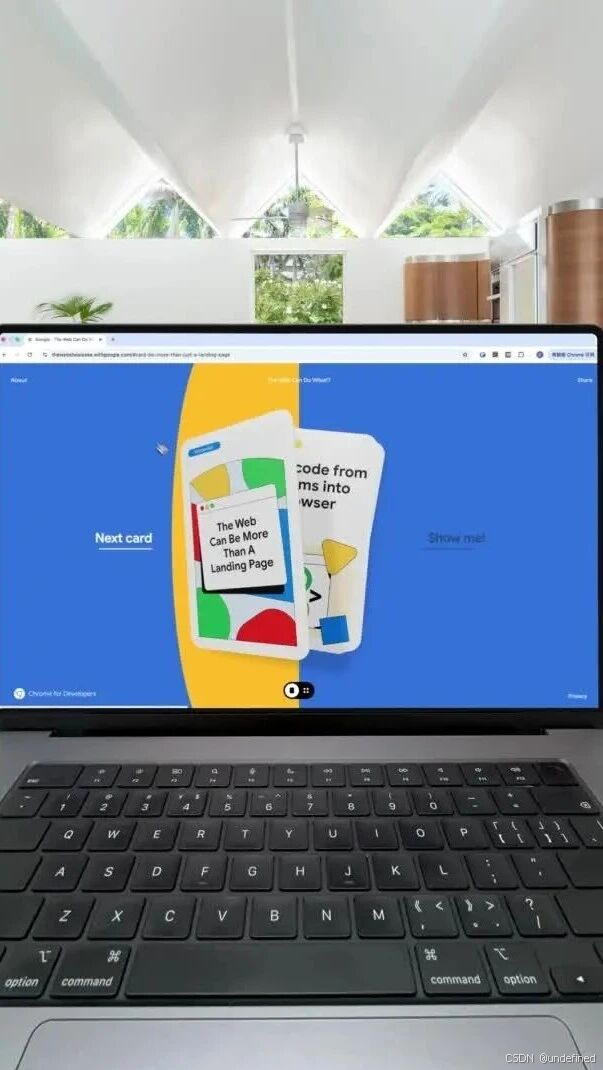
Prompt:使用zai-mcp-server分析当前目录下的视频,分析视频中的网站的页面、交互、动效,然后1:1复刻视频中的网站
原网站效果
复刻后的效果
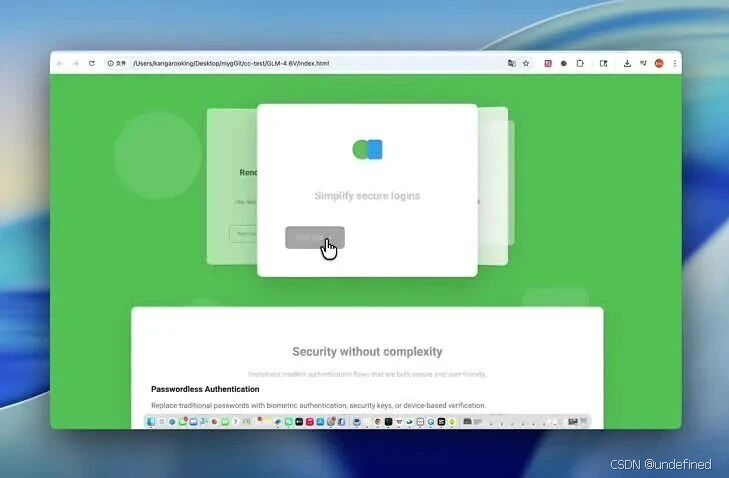
GLM-4.6V负责识别视频,GLM-4.6负责生成高质量的前端代码。
网页复刻得还不错,至少这个卡片飞来飞去的效果有了,整体交互和动效都有原视频的影子。要想一次性百分百还原是很难的,毕竟原视频的动效太棒了。
GLM-4.6V虽然在极致的视觉能力上,它可能还略逊于Gemini 3这种顶级模型。但别忘了,它只有106B。
对于想要私有化部署的企业来说,这是一个够一够就能得着的高性价比选项。
而对于个人开发者,9B的Flash版本够我们在本地免费使用了。
不过,我心里也有个小疑问:为什么智谱不直接把视觉能力融合进GLM-4.6里,要分拆成两个模型呢?有没有懂的朋友在评论区给我科普一下?
我猜可能是为了更灵活的部署和更低的推理成本?
顺便说一下,行业+AI,才能真正释放AI的生产力。
懂业务的朋友,真的建议多学学怎么用好这些AI模型。
当你能把业务痛点和模型能力对接上的那一刻,效率的提升,绝对是指数级的。
补充:GLM-4.6和GLM-4.6V都在Coding Plan的使用范围内
能看到这里的都是凤毛麟角的存在!
如果觉得不错,随手点个赞、在看、转发三连吧~
如果想第一时间收到推送,也可以给我个星标⭐
谢谢你耐心看完我的文章~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)