无水印视频解析难?这款工具手把手教你轻松获取
针对短视频无水印解析的实际需求,提供一款实用工具的详细使用教程,涵盖安装准备、操作步骤及常见问题处理,并分析不同场景下的使用方式,帮助用户高效获取无水印视频素材。

在日常获取短视频平台内容时,很多用户会遇到这样的问题:看中的视频带有平台水印,无论是用于学习参考、素材整理还是个人收藏,水印都会影响后续使用;而市面上部分解析工具要么操作步骤复杂,要么解析后视频格式不兼容,甚至出现画质压缩的情况。
这款无水印视频解析工具可解决这些问题,使用前需先确认设备是否安装基础运行环境。若打开工具时提示 “缺少必要组件”,只需在官方渠道搜索对应运行组件(如常见的框架类组件),下载后按照默认步骤安装,完成后重启设备即可。安装工具本身时,选择非系统盘(如 D 盘、E 盘)的空文件夹作为安装路径,避免因系统盘空间不足导致工具运行卡顿。
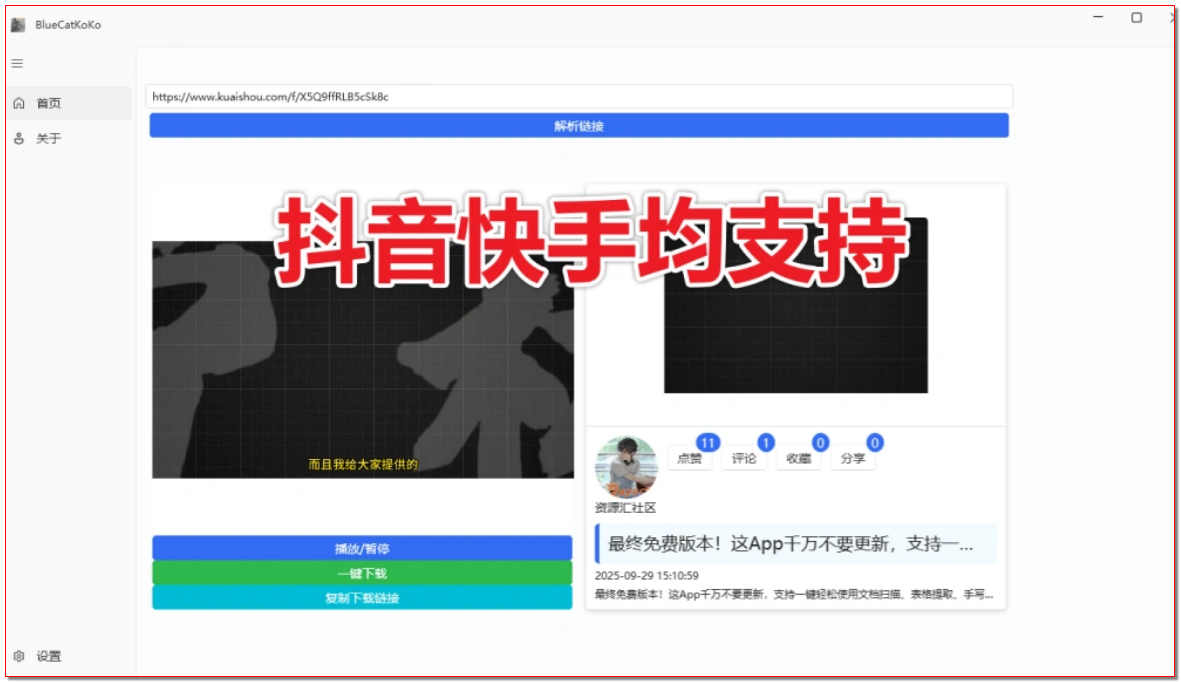
打开工具后,界面布局清晰,顶部为链接输入区域,中间是功能按钮区,底部显示下载进度与路径。操作时,先在目标短视频平台打开需要解析的视频,复制视频链接(注意区分 “分享链接” 与 “原始链接”,部分平台需选择 “复制链接” 而非 “分享到其他平台”);将复制的链接粘贴到工具的输入框中,点击 “解析” 按钮,工具会自动识别视频信息,过程通常持续 3-5 秒,若解析失败,可检查链接是否过期(重新复制最新链接)或网络是否稳定;解析成功后,界面会显示视频分辨率、时长等信息,点击 “选择路径” 可自定义保存位置,建议选择容易查找的文件夹(如桌面 “无水印视频” 文件夹),最后点击 “下载”,待进度条显示 100% 后,即可在设置的路径中找到无水印视频,且视频格式默认为通用的 MP4 格式,无需额外转换即可在电脑、手机等设备上播放。
对于自媒体从业者而言,获取无水印视频后,可更清晰地分析同行视频的镜头切换、文案结构,无需手动裁剪水印区域,节省素材整理时间;家长整理早教类短视频时,无水印画面能避免孩子被多余元素干扰,专注于视频中的知识内容;学生收集编程教学、学科科普类视频时,离线保存的无水印版本可随时反复观看重点片段,不受网络波动或平台广告影响。
相关的软件教程已打包整理,包含工具安装、运行环境配置、常见问题解决等内容,都放在网盘里,私信我备注文章标题即可获取完整软件教程。
# 安装依赖库:执行命令 pip install requests beautifulsoup4 lxml
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urlparse
def get_valid_headers():
"""配置请求头:模拟内网浏览器请求,避免被内网服务拦截"""
# 替换为内网环境下浏览器的真实User-Agent(可通过浏览器F12-网络-请求头获取)
return {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Referer": "https://内网短视频平台域名/", # 替换为内网平台实际域名
"Connection": "keep-alive"
}
def parse_intranet_video_url(share_url, headers):
"""解析内网短视频分享链接,提取真实无水印视频地址"""
try:
# 发送请求获取视频页面源码(内网环境超时可适当调整,默认10秒)
response = requests.get(share_url, headers=headers, timeout=10, verify=False)
response.raise_for_status() # 若请求状态码非200,抛出异常
# 解析页面:根据内网平台实际结构调整(示例为常见video标签src属性)
soup = BeautifulSoup(response.text, "lxml")
video_tag = soup.find("video", attrs={"class": "video-source"}) # 替换为内网平台视频标签的实际属性
if not video_tag or "src" not in video_tag.attrs:
return None, "未找到视频资源,请检查链接是否有效或页面结构是否变更"
# 处理相对路径:若src是相对地址,拼接内网域名转为绝对地址
video_src = video_tag["src"]
parsed_share_url = urlparse(share_url)
if not video_src.startswith(("http:", "https:")):
video_src = f"{parsed_share_url.scheme}://{parsed_share_url.netloc}{video_src}"
return video_src, "解析成功"
except requests.exceptions.Timeout:
return None, "请求超时,请检查内网网络连接"
except requests.exceptions.RequestException as e:
return None, f"解析失败:{str(e)}"
def download_intranet_video(video_url, save_dir="intranet_videos", headers=None):
"""下载无水印视频到指定目录,支持进度显示"""
# 创建保存目录(不存在则自动创建)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 提取视频文件名(从URL末尾获取,避免重复)
video_filename = os.path.basename(urlparse(video_url).path)
if not video_filename.endswith((".mp4", ".mov", ".flv")): # 补充内网平台支持的视频格式
video_filename = f"video_{os.path.splitext(video_filename)[0]}.mp4"
save_path = os.path.join(save_dir, video_filename)
try:
# 流模式下载:避免大文件占用过多内存
response = requests.get(video_url, headers=headers, timeout=30, stream=True, verify=False)
response.raise_for_status()
# 获取视频总大小(用于进度计算)
total_size = int(response.headers.get("Content-Length", 0))
downloaded_size = 0
# 写入视频文件
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=1024*1024): # 1MB分块下载
if chunk:
f.write(chunk)
downloaded_size += len(chunk)
# 显示下载进度(仅当能获取总大小时)
if total_size > 0:
progress = (downloaded_size / total_size) * 100
print(f"下载进度:{progress:.1f}% | 已下载:{downloaded_size//1024}KB")
return save_path, "下载完成"
except requests.exceptions.RequestException as e:
# 下载失败时删除不完整文件
if os.path.exists(save_path):
os.remove(save_path)
return None, f"下载失败:{str(e)}"
# ------------------- 运行示例(需根据内网实际情况修改) -------------------
if __name__ == "__main__":
# 1. 配置内网环境参数
intranet_share_url = "https://内网短视频平台域名/share/xxxxxx" # 替换为内网实际分享链接
headers = get_valid_headers()
# 2. 解析视频地址
video_url, parse_msg = parse_intranet_video_url(intranet_share_url, headers)
print(f"解析结果:{parse_msg}")
if not video_url:
exit() # 解析失败则退出
# 3. 下载视频
save_path, download_msg = download_intranet_video(video_url, headers=headers)
print(f"下载结果:{download_msg}")
if save_path:
print(f"视频保存路径:{os.path.abspath(save_path)}")
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)