图解LSTM:NLP时代的旧王
LSTM我们主要把握好它的输入输出,以及门控机制的几个公式,就可以迅速掌握啦。如果之前了解过RNN的小伙伴就会知道,RNN天然有着许多不足,比如梯度爆炸和梯度消失的问题,不能解决长距离依赖。LSTM针对以上几点,通过门控机制对其作出了改进,使得LSTM大放异彩,同时有了很多变种,在NLP领域表现非常出色。
0 前言
如果之前了解过RNN的小伙伴就会知道,虽然RNN解决了神经网络不能很好的处理序列的问题,通过加入隐藏状态和转移矩阵,使得前后分词信息相关联,但是RNN依然存在自己的问题。
-
梯度消失问题:当序列较长时,误差梯度在反向传播过程中会逐渐减小,以至于梯度最终消失。
-
当梯度消失时,无法对先前的输入产生有效的权重更新。这意味着RNN难以学习长距离的依赖关系。
-
梯度爆炸问题:与梯度消失相反,有时梯度在反向传播中会指数级增长,导致模型不稳定,权重更新步长过大。不过,梯度爆炸问题可以通过梯度裁剪,一定程度上可以得到缓解。
其实在深度学习中,网络演进的过程都是类似的:
在CV中,LeNet有自己的局限性,网络不够深,没有使用Dropout容易过拟合;
AlexNet使用ReLu作为激活函数,并可以用多块显卡进行大规模训练;
而ResNet通过残差学习解决了深度网络的训练难题,使得网络可以极大加深,性能进一步提升。
在自然语言处理中,各个模型也是站在巨人的肩膀上,一点一点进步,比如从最早的全连接神经网络,走到了RNN,在RNN的基础上,LSTM进一步解决问题,并且出现了多种变体,比如GRU、双向LSTM,后来又出现了暴力机器Transformer,在Transformer的上又有了GPT、BERT......
1 LSTM介绍
LSTM又叫长短期记忆网络,为什么标题我们说LSTM是NLP旧时代的王,当代的大模型可能都是Transformer家族,但是在Transformer出现之前,LSTM应用非常广泛。我们一起看看LSTM牛叉在哪儿:
-
通过精巧的“门控机制”解决了RNN长序列时,出现“梯度消失/爆炸”的问题,可以学习长距离的依赖关系。
-
LSTM成熟之后,在NLP领域大行其道,各种各样的变体,在机器翻译、文本摘要、对话系统等任务上取得了突破性进展。
-
LSTM几乎一统天下,无论是文本分类、情感分析、命名实体识别,还是更复杂的生成任务,LSTM几乎是大家的首选。
1.1 LSTM难在哪儿
讲道理虽然LSTM这么牛,但是有些人只会做无情的调包侠(比如之前的我),看到LSTM那个图就头疼,完全没欲望钻研下去。但是这份苦,我替大家吃了,我好好钻研一下,再讲给大家听。(狗头)
LSTM主要是有很多门控机制混在一块儿,有些小伙伴甚至都还没弄懂RNN,来学习LSTM那更是一头雾水。
比如你没学习乘法,就学习了幂,那肯定头大。如果不了解RNN的小伙伴,可以先看看我之前对RNN的图解,再来学习LSTM就会非常简单哦。
我们先回忆一下RNN的网络结构:
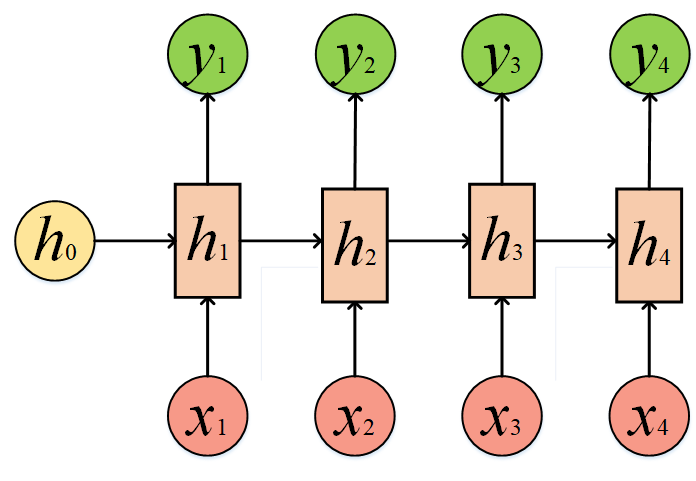
输出y是通过前一步的隐藏状态h以及当下的输入x得到的,下面我们就对比一下RNN和LSTM的结构,具体来看看它们的区别在哪里。
1.2 LSTM的网络结构
我将RNN的图和LSTM的基本结构图放在了一起做对比:
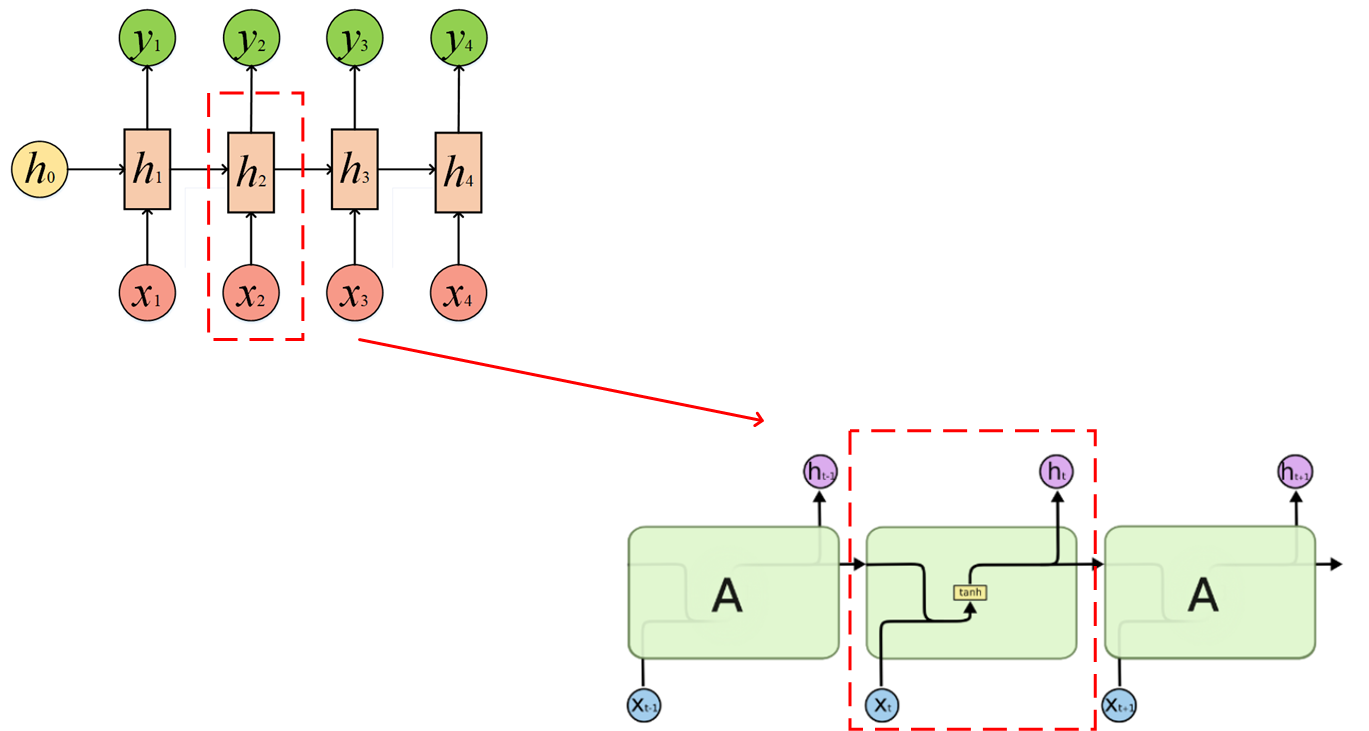
但是实际的LSTM结构比这还要复杂一些,ht事实上有两个分支,还流向了下一个细胞里面,这个和RNN的流向也是一致的。
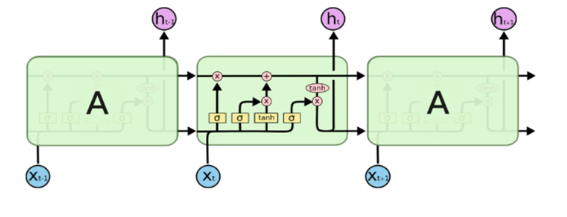
1.3 LSTM结构分析
至此我们已经通过一步步变化,得到了LSTM的结构图,是不是有些头晕,没关系,如果是在没弄明白RNN和LSTM的关系也不要紧,我们直接分析LSTM的网络结构图,看看它的工作机理。
我们单独把一个细胞拎出来研究:
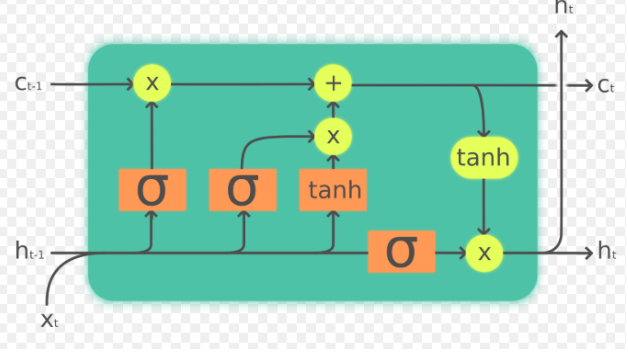
输入和输出:
此时我们将这个细胞视为一个整体,我们梳理清楚它的输入和输出。这也是理解LSTM的关键所在。
输入包含Ct-1、ht-1以及xt;输出包含Ct-1、ht-1。这个结构其实也是循环的,前面细胞的输出是下一个细胞的输入。这个和RNN类似。
我当时在学习LSTM的时候就一直找不到主线,其实学习LSTM很简单,把握两点:
1、知道输入(Ct-1、ht-1以及xt)和输出(Ct-1、ht-1)是什么,并且知道当前细胞的输出就是下一细胞的输入;
2、知道输出(Ct-1、ht-1)怎么通过输入(Ct-1、ht-1以及x)和里面五花八门的门控机制计算得到的,就理解了LSTM。
1.4 LSTM的门控机制
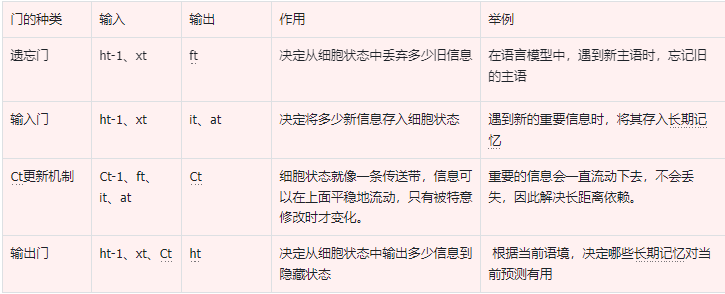
我们需要理解LSTM的内部构造,就需要理解LSTM的遗忘门、输入门、输出门以及Ct的更新机制。
此时再回到刚才那张图,我们逐一分析:
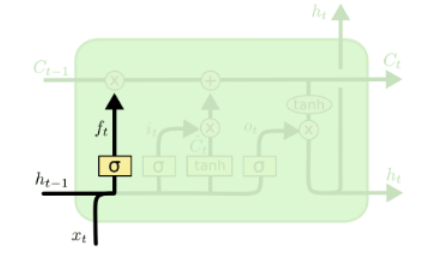
1.4.1 遗忘门
遗忘门(forget gate)顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:
注意:
把ht-1和xt放在这个横线上不是随便画的,放在这个横线上意味着要做矩阵的线性变换。
比如ht-1的变换矩阵是Wf,xt的变换矩阵是Uf,此时在经过激活函数之前,我们需要针对ht-1和xt做矩阵相乘并且加上偏置bf,然后再经过激活函数,做非线性变换,因此ft的公式为:
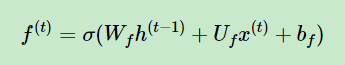
其中Wf,Uf,bfWf,Uf,bf为线性关系的系数和偏置,和RNN中的类似。σ为sigmoid激活函数。
1.4.2 输入门
输入门依旧是针对ht-1和xt做线性变换再加上偏置,只不过遗忘门得到的只有一个结果ft,而输入门得到的有两个结果:it和at:
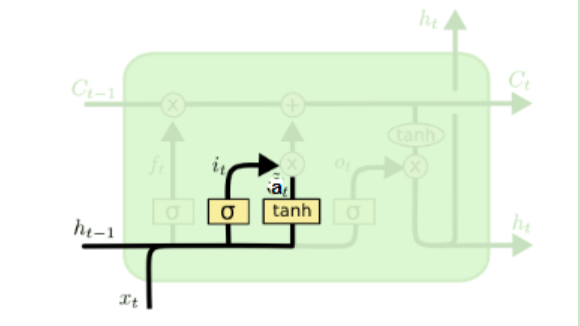
it和at在经过σ为函数和tanh函数之前其实是一样的,只不过对ht-1和xt做矩阵相乘并且加上偏置bf后,它们经过发的激活函数不同,公式为:
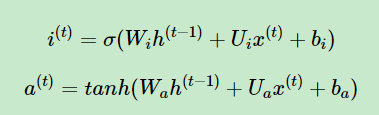
其中:
Wi,Ui,bi,Wa,Ua,ba,Wi,Ui,bi,Wa,Ua,ba,为线性关系的系数和偏置,和RNN中的类似。σ为sigmoid激活函数。
1.4.3 Ct的更新机制
本来要先讲输出门的,但是我们没有搞清楚细胞状态怎么更新的话,没有办法去计算输出门,因此首先我们研究一下Ct是怎么更新的。
在此前我们已经学习了遗忘门的结果ft,输入门的结果it和at,此时我们再加上上一时刻的细胞状态Ct-1,就可以开始合成大法,计算出Ct了。
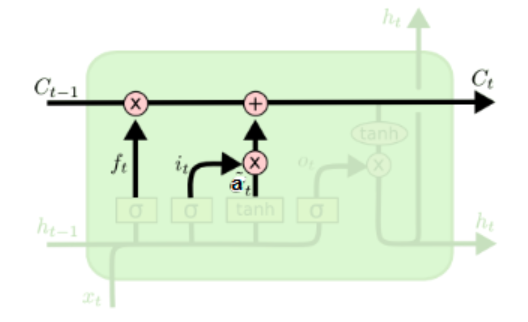
细胞状态C(t)由两部分组成,第一部分是C(t−1)和遗忘门输出f(t)的乘积,第二部分是输入门的i(t)和a(t)的乘积,然后再相加:
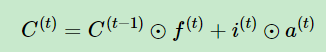
其中,⊙为点积(点积是向量间的一种基本运算,结果为标量)。
1.4.4 输出门
有了新的隐藏细胞状态C(t),我们就可以计算出输出门的结果ht。
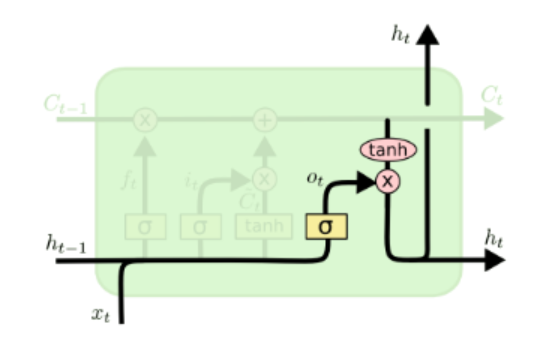
其中ht的计算由两部分做点积而成:
1、ht-1和xt做变换并且加上偏置bf后经过σ函数得到ot;
2、Ct经过tanh函数得到一个结果,公式为:
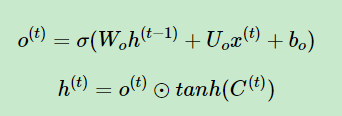
至此,我们就弄清楚了每个门是干啥的,以及具体做什么运算了。
2 门控总结
我们对几种机制做一个总结:
3 LSTM的局限性
LSTM并没有阻止梯度流动,这个细胞Ct的更新机制有点像修了一条高速公路,通过几个门控可以决定哪些信息是有用的,可以进入下一个细胞里,哪些信息是没用的,就遗忘掉。
因此与RNN相比,对于信息的掌控力更强了,有效的我就保留,即使你距离再远 ,我也能给你传递下去;没用的就丢弃,哪怕就在眼前,也不会传入下一个细胞中。RNN相比就无脑一些,没什么把门的机制。
LSTM讲到这里就结束啦,如果有问题评论区可以和我讨论哈。下一次理论分享,我们将带来暴力机器:Transformer。
如果你觉得写的不错,也可以关注我的gzh:阿龙AI日记,有问题我都会回复。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)