医疗知识图谱对话系统:作业 2
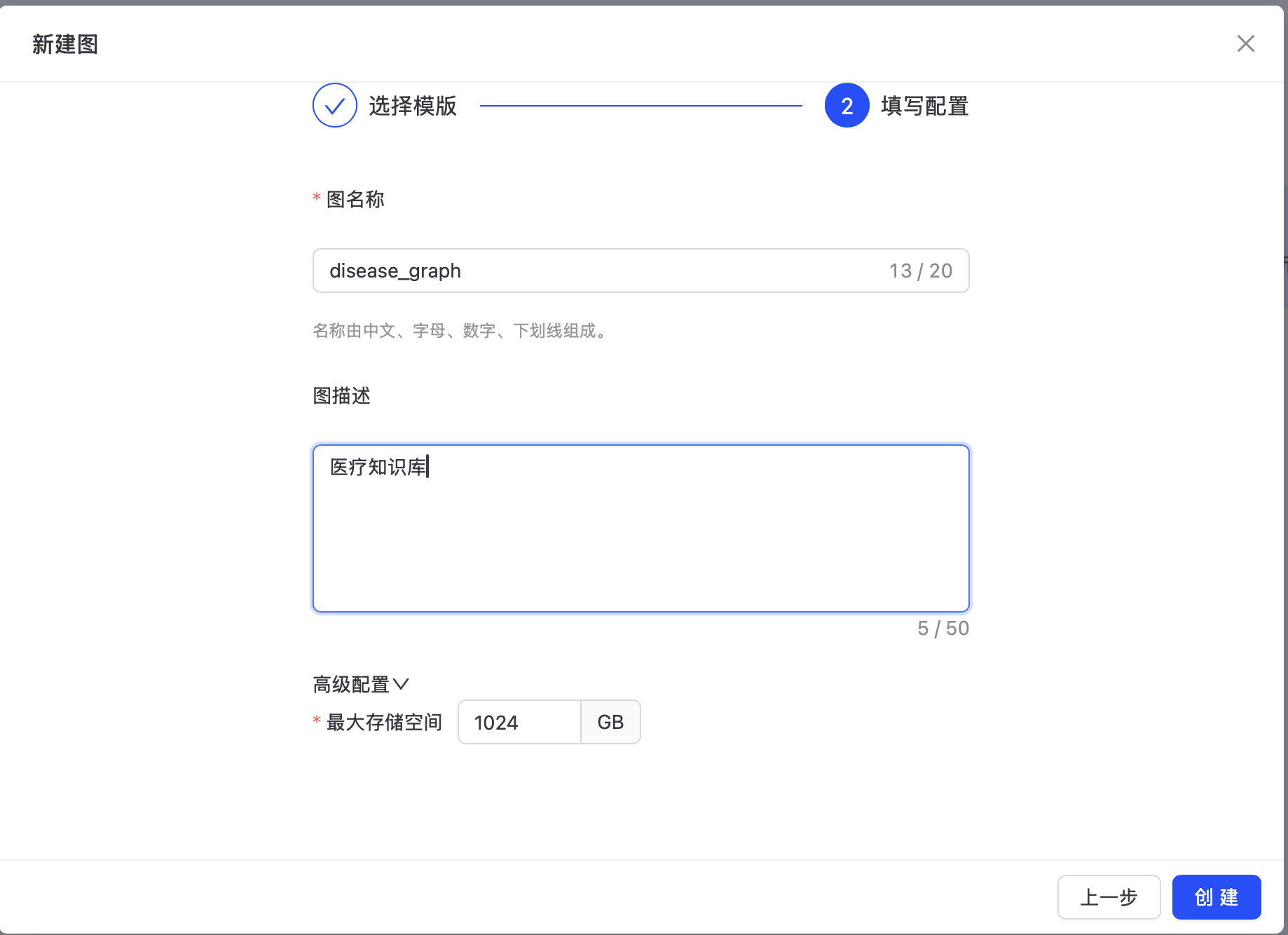
定义 13 类边(关系):HAS_ALIAS(疾病 - 别名)、HAS_SYMPTOM(疾病 - 症状)等,明确边的连接约束(如 Disease→Symptom)。定义 14 类顶点(实体):Disease(疾病)、Alias(别名)、Symptom(症状)等,统一以。),存储 “源实体 - 目标实体” 的关联关系(如 “乙肝 - 转氨酶增高”)。批量操作时建议使用事务处理。批量导入:读取节点 /
TuGraph安装与启动
在docker中拉取镜像
docker pull tugraph/tugraph-runtime-arm64v8-centos7使用Docker Desktop启动Tugraph

在浏览器中输入https://localhost:7070
输入数据库地址:127.0.0.1:7687,默认用户名:admin,默认密码:73@TuGraph
图:TuGraph服务成功启动后的Web界面
数据导入与图谱构建
创建图谱
数据导入支持多种格式,包括CSV和JSON。通过neo4j 的GraphDatabase工具进行批量导入。
步骤 1:生成图谱结构配置
-
工具脚本:
write_conf.py。 -
核心操作:读取
disease3.csv列结构,生成example.json配置文件。-
定义 14 类顶点(实体):Disease(疾病)、Alias(别名)、Symptom(症状)等,统一以
name为唯一主键(非空、带索引)。 -
定义 13 类边(关系):HAS_ALIAS(疾病 - 别名)、HAS_SYMPTOM(疾病 - 症状)等,明确边的连接约束(如 Disease→Symptom)。
-
-
关键作用:避免硬编码节点 / 边结构,让图谱构建更灵活可维护。
步骤 2:拆分节点与边数据
-
工具脚本:
write_V_E.py。 -
核心操作:解析
disease3.csv,按example.json的结构,生成两类文件:-
节点 CSV:每个顶点类型对应 1 个 CSV(如
Disease.csv、Symptom.csv),存储实体的唯一值(去重后)。 -
边 CSV:每个边类型对应 1 个 CSV(如
HAS_SYMPTOM.csv),存储 “源实体 - 目标实体” 的关联关系(如 “乙肝 - 转氨酶增高”)。
-
-
关键处理:拆分多值字段(如将 “转氨酶增高 肝肿大” 拆分为两条独立边数据)。
步骤 3:图谱导入与结构创建
-
工具脚本:tugraph_
build_graph.py。 -
核心操作:
-
连接 TuGraph:通过 Neo4j 驱动连接数据库,验证连通性。
-
初始化数据库:删除旧库(避免冲突),创建目标数据库(如
disease_graph)。 -
创建约束:基于
example.json,为所有顶点的name属性创建唯一约束(确保实体不重复)。 -
批量导入:读取节点 / 边 CSV 文件,通过 Cypher 的
MERGE语句(避免重复)批量导入节点和边。
-
以下为tugraph_build_graph.py的核心代码片段:
from neo4j import GraphDatabase
def build_tu_graph():
try:
# 1. 读取配置文件
conf = read_tu_conf(TU_CONFIG["conf_path"])
vertex_conf = conf["vertex"] # 节点配置
edge_conf = conf["edge"] # 边配置
# 提取所有节点标签(如["Disease", "Alias", "Part"...])
vertex_labels = [v["label"] for v in vertex_conf]
# 提取所有边标签(如["HAS_ALIAS", "IS_OF_PART"...])
edge_labels = [e["label"] for e in edge_conf]
# 2. 验证CSV文件(节点+边)
check_csv_exist(TU_CONFIG["csv_dir"], vertex_labels)
# 验证边CSV(每个边标签对应一个CSV)
edge_csvs = [f"{label}.csv" for label in edge_labels]
missing_edge_csvs = []
for csv_name in edge_csvs:
csv_path = os.path.join(TU_CONFIG["csv_dir"], csv_name)
if not os.path.exists(csv_path):
missing_edge_csvs.append(csv_path)
if missing_edge_csvs:
raise FileNotFoundError(f"❌ 以下边CSV文件缺失:\n{', '.join(missing_edge_csvs)}")
print("✅ 所有边CSV文件均存在")
# 3. 连接TuGraph
driver = GraphDatabase.driver(TU_CONFIG["uri"], auth=TU_CONFIG["auth"])
driver.verify_connectivity()
print(f"✅ 成功连接TuGraph(URI: {TU_CONFIG['uri']})")
with driver.session(database=TU_CONFIG["db_name"]) as session:
# 4. 初始化数据库:删除旧库(避免schema冲突)
# db.dropDB() 不接受参数,会清空当前连接的数据库
try:
session.run("CALL db.dropDB()")
print(f"✅ 已清空数据库:{TU_CONFIG['db_name']}")
except Exception as e:
# 如果数据库不存在或清空失败,继续执行(可能是新数据库)
print(f"⚠️ 数据库清空操作:{str(e)},继续执行...")
print(f"✅ 数据库初始化完成(数据库:{TU_CONFIG['db_name']})")
# 5. 基于配置创建节点标签(严格遵循example.json的属性定义)
print("\n===== 开始创建节点标签 =====")
for v in vertex_conf:
label = v["label"]
properties = v["properties"] # 从配置获取属性(如[{"name":"name","type":"STRING"...}])
primary_key = v["primary"] # 从配置获取主键(如"name")
# 找到主键属性
primary_prop = [p for p in properties if p['name'] == primary_key][0]
primary_type = primary_prop['type']
primary_optional = str(primary_prop['optional']).lower()
# 构建参数列表:标签名, 主键字段名, 主键属性名, 主键类型, 主键是否可选, [其他属性...]
# 格式参考:CALL db.createVertexLabel('person', 'id', 'id', 'INT32', false, 'name', 'STRING', false)
params = [
f"'{label}'",
f"'{primary_key}'",
f"'{primary_key}'",
f"'{primary_type}'",
primary_optional
]
# 添加其他非主键属性
for prop in properties:
if prop['name'] != primary_key:
params.append(f"'{prop['name']}'")
params.append(f"'{prop['type']}'")
params.append(str(prop['optional']).lower())
# 构建单行 Cypher 查询(TuGraph 要求单行格式)
cypher_query = f"CALL db.createVertexLabel({', '.join(params)})"
session.run(cypher_query)
print(f"✅ 节点标签创建完成:{label}(主键:{primary_key})")
# 6. 基于配置创建边标签(严格遵循example.json的约束)
print("\n===== 开始创建边标签 =====")
for e in edge_conf:
label = e["label"]
constraints = e["constraints"] # 从配置获取连接约束(如[["Disease","Alias"]])
# 构建约束JSON字符串:格式为 [["源节点","目标节点"]]
# 示例:'[["person","person"]]'
constraint_json = json.dumps(constraints)
# 构建单行 Cypher 查询(TuGraph 要求单行格式)
# 格式参考:CALL db.createEdgeLabel('is_friend','[["person","person"]]')
cypher_query = f"CALL db.createEdgeLabel('{label}', '{constraint_json}')"
session.run(cypher_query)
print(f"✅ 边标签创建完成:{label}(约束:{constraints[0][0]}→{constraints[0][1]})")
# 7. 导入节点数据(从write_V_E生成的CSV读取,去重导入)
print("\n===== 开始导入节点数据 =====")
for v in vertex_conf:
label = v["label"]
csv_path = os.path.join(TU_CONFIG["csv_dir"], f"{label}.csv")
# 读取CSV:每行一个节点值(write_V_E生成的格式)
df = pd.read_csv(csv_path, header=None, names=["name"], encoding="utf-8")
# 去重:避免write_V_E生成重复节点
df_unique = df.drop_duplicates(subset=["name"]).dropna()
# 批量导入节点(MERGE避免重复)
for _, row in df_unique.iterrows():
node_name = row["name"].strip()
if node_name in ["nan", "", "None"]:
continue
# 使用单行 Cypher 查询(TuGraph 要求)
cypher_query = f"MERGE (n:{label} {{name: $name}}) ON CREATE SET n.name = $name"
session.run(cypher_query, name=node_name)
print(f"✅ 节点数据导入完成:{label}(共{len(df_unique)}个唯一节点)")
# 8. 导入边数据(从write_V_E生成的CSV读取,关联节点)
print("\n===== 开始导入边数据 =====")
for e in edge_conf:
edge_label = e["label"]
constraints = e["constraints"][0] # 源节点标签、目标节点标签(如["Disease","Alias"])
src_label = constraints[0]
dst_label = constraints[1]
csv_path = os.path.join(TU_CONFIG["csv_dir"], f"{edge_label}.csv")
# 读取边CSV:每行格式为"源节点名 目标节点名"(write_V_E生成的格式)
df = pd.read_csv(csv_path, header=None, names=["src_name", "dst_name"],
sep="\s+", encoding="utf-8") # 空格分隔
df_unique = df.drop_duplicates().dropna()
# 批量导入边(MATCH源/目标节点,MERGE边避免重复)
for _, row in df_unique.iterrows():
src_name = row["src_name"].strip()
dst_name = row["dst_name"].strip()
if src_name in ["nan", ""] or dst_name in ["nan", ""]:
continue
# 使用单行 Cypher 查询(TuGraph 要求)
cypher_query = f"MATCH (src:{src_label} {{name: $src_name}}) MATCH (dst:{dst_label} {{name: $dst_name}}) MERGE (src)-[r:{edge_label}]->(dst)"
session.run(cypher_query, src_name=src_name, dst_name=dst_name)
print(f"✅ 边数据导入完成:{edge_label}(共{len(df_unique)}个唯一关系)")
print("\n🎉 TuGraph疾病图谱构建完成!")
driver.close()
except Exception as e:
print(f"\n❌ 图谱构建失败:{str(e)}")
raise运行结果:
===== 开始导入节点数据 =====
✅ 节点数据导入完成:Disease(共28个唯一节点)
✅ 节点数据导入完成:Alias(共46个唯一节点)
✅ 节点数据导入完成:Part(共22个唯一节点)
✅ 节点数据导入完成:Age(共48个唯一节点)
✅ 节点数据导入完成:Infection(共2个唯一节点)
✅ 节点数据导入完成:Insurance(共2个唯一节点)
✅ 节点数据导入完成:Department(共26个唯一节点)
✅ 节点数据导入完成:Checklist(共118个唯一节点)
✅ 节点数据导入完成:Symptom(共122个唯一节点)
✅ 节点数据导入完成:Complication(共79个唯一节点)
✅ 节点数据导入完成:Treatment(共21个唯一节点)
✅ 节点数据导入完成:Drug(共77个唯一节点)
✅ 节点数据导入完成:Period(共23个唯一节点)
✅ 节点数据导入完成:Rate(共21个唯一节点)
✅ 节点数据导入完成:Money(共19个唯一节点)
===== 开始导入边数据 =====
✅ 边数据导入完成:HAS_ALIAS(共46个唯一关系)
✅ 边数据导入完成:IS_OF_PART(共31个唯一关系)
✅ 边数据导入完成:IS_OF_AGE(共57个唯一关系)
✅ 边数据导入完成:IS_INFECTIOUS(共28个唯一关系)
✅ 边数据导入完成:In_Insurance(共28个唯一关系)
✅ 边数据导入完成:IS_OF_Department(共48个唯一关系)
✅ 边数据导入完成:HAS_Checklist(共127个唯一关系)
✅ 边数据导入完成:HAS_SYMPTOM(共134个唯一关系)
✅ 边数据导入完成:HAS_Complication(共91个唯一关系)
✅ 边数据导入完成:HAS_Treatment(共52个唯一关系)
✅ 边数据导入完成:HAS_Drug(共79个唯一关系)
✅ 边数据导入完成:Cure_Period(共27个唯一关系)
✅ 边数据导入完成:Cure_Rate(共29个唯一关系)
✅ 边数据导入完成:NEED_Money(共37个唯一关系)导入完成后,Web网页会显示图谱的实体关系和属性信息。
图:图谱数据导入后的可视化展示
Cypher查询与Python交互
TuGraph支持通过Cypher语句进行复杂查询,参考 cypher_python_demo.py:
from neo4j import GraphDatabase # TuGraph兼容Neo4j驱动,无需额外安装
# -------------------------- 1. 基础配置(适配TuGraph) --------------------------
TU_CONFIG = {
"uri": "bolt://localhost:7687", # TuGraph默认Bolt端口
"auth": ("admin", "73@TuGraph"), # TuGraph默认账号/密码
"db_name": "disease_graph" # 图谱数据库名
}
# -------------------------- 2. 核心交互类(简化版) --------------------------
class TuGraphCypherClient:
def __init__(self):
# 初始化连接
self.driver = GraphDatabase.driver(
TU_CONFIG["uri"],
auth=TU_CONFIG["auth"]
)
def close(self):
# 关闭连接
self.driver.close()
def run_cypher(self, cypher, params=None):
"""执行Cypher查询,返回结果列表"""
with self.driver.session(database=TU_CONFIG["db_name"]) as session:
result = session.run(cypher, params or {})
# 转换结果为列表(方便处理)
return [record.data() for record in result]
# -------------------------- 3. 示例:执行核心验证查询 --------------------------
if __name__ == "__main__":
# 初始化客户端
client = TuGraphCypherClient()
print("✅ 连接TuGraph成功!\n")
# ========== 示例1:统计图谱总顶点/边数 ==========
print("【1. 统计图谱总数】")
# 统计总顶点数
vertex_count = client.run_cypher("MATCH (n) RETURN count(n) AS total_vertices")[0]
# 统计总边数
edge_count = client.run_cypher("MATCH ()-[r]->() RETURN count(r) AS total_edges")[0]
print(f"总实体数:{vertex_count['total_vertices']}")
print(f"总关系数:{edge_count['total_edges']}\n")
# ========== 示例2:查询单个实体的属性 ==========
print("【2. 查询乙肝的实体属性】")
disease_prop = client.run_cypher(
"MATCH (d:Disease {name: $name}) RETURN properties(d) AS prop",
params={"name": "乙肝"} # 参数化查询(避免注入)
)
if disease_prop:
print(f"乙肝属性:{disease_prop[0]['prop']}\n")
else:
print("未找到乙肝实体\n")
# ========== 示例3:查询实体的关联关系 ==========
print("【3. 查询乙肝的症状关系】")
symptom_rels = client.run_cypher("""
MATCH (d:Disease {name: $name})-[r:HAS_SYMPTOM]->(s:Symptom)
RETURN s.name AS symptom_name
""", params={"name": "乙肝"})
print("乙肝的症状:")
for idx, rel in enumerate(symptom_rels, 1):
print(f" {idx}. {rel['symptom_name']}")
# 关闭连接
client.close()
print("\n✅ 所有查询执行完成!")运行结果:
✅ 连接TuGraph成功!
【1. 统计图谱总数】
总实体数:654
总关系数:814
【2. 查询乙肝的实体属性】
乙肝属性:{"_LABEL_":"Disease","_VID_":1,"name":"乙肝"}
【3. 查询乙肝的症状关系】
乙肝的症状:
1. 转氨酶增高
2. 肝肿大
3. 乙肝表面抗原(HBsAg)阳性
4. 乙肝e抗原(HBeAg)阳性
5. 肝功能异常
✅ 所有查询执行完成!常见操作包括创建节点、建立关系、属性过滤和路径查询。批量操作时建议使用事务处理。
对话系统交互实现
基于TuGraph的对话系统需要处理自然语言到Cypher的转换。典型交互流程包括:
- 用户输入自然语言查询
- 系统解析生成Cypher语句
- 执行查询并返回结构化结果
- 将结果转换为自然语言响应
以下为tugraph_interaction.py的核心代码:
def tu_graph_interaction():
print("="*60)
print("🎯 TuGraph疾病图谱交互系统")
print("📌 支持查询场景:症状、药物、并发症、治疗方法、检查项目、治疗周期、治愈率、治疗费用")
print("📌 支持操作:查询(输入示例:查询乙肝的症状)、更新描述(输入示例:更新乙肝描述 乙肝是...)、删除测试(输入示例:删除测试疾病X)")
print("📌 退出系统:输入「退出」或「quit」")
print("="*60)
while True:
user_input = input("\n请输入您的操作:").strip()
if not user_input:
continue
# 处理退出
if user_input.lower() in ["退出", "quit", "exit"]:
print("👋 感谢使用,再见!")
break
# 处理“查询”操作
if user_input.startswith("查询"):
# 解析格式:查询[疾病名]的[场景]
try:
# 提取疾病名和场景(如“查询乙肝的症状”→疾病名“乙肝”,场景“症状”)
parts = user_input.split("的")
if len(parts) != 2:
raise ValueError("格式错误")
disease_name = parts[0].replace("查询", "").strip()
scene = parts[1].strip()
# 执行查询
query_disease_related(disease_name, scene)
except Exception as e:
print(f"❌ 查询格式错误,请输入示例:查询乙肝的症状")
continue
# 处理“更新描述”操作
if user_input.startswith("更新") and "描述" in user_input:
# 解析格式:更新[疾病名]描述[描述内容]
try:
parts = user_input.split("描述")
if len(parts) != 2:
raise ValueError("格式错误")
disease_name = parts[0].replace("更新", "").strip()
desc = parts[1].strip()
if not desc:
raise ValueError("描述不能为空")
# 执行更新
update_disease_desc(disease_name, desc)
except Exception as e:
print(f"❌ 更新格式错误,请输入示例:更新乙肝描述 乙肝是由乙肝病毒引起的肝脏炎症")
continue
# 处理“删除测试”操作
if user_input.startswith("删除"):
# 解析格式:删除[测试疾病名]
disease_name = user_input.replace("删除", "").strip()
# 二次确认(避免误删正式数据)
confirm = input(f"⚠️ 确认删除测试疾病「{disease_name}」吗?(输入y确认,其他取消):").strip()
if confirm.lower() == "y":
delete_test_data(disease_name)
else:
print("❌ 已取消删除")
continue
# 未识别操作
print("❌ 未识别的操作,请参考示例格式输入")示例交互输出:
图:对话系统成功执行的查询交互界面

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)