从爬虫到AI生成一个自媒体自动化工具的技术架构与实现
核心定义:以“爬虫采集素材+AI生成内容+自动化排版分发”为核心,覆盖“选题-素材-创作-分发”全流程的工具,目标是将单篇内容生产周期缩短60%以上,同时保证内容原创度≥85%(来源:自研工具3个月实测数据)。咱们做工具前,得先戳中真正的痛点,别做无用功:痛点传统做法自动化工具解决方案效率提升比选题耗时长刷5个平台+手动记热点爬虫抓10+平台热点+AI筛选90分钟→12分钟素材收集繁琐手动下载图片
自媒体自动化工具搭建与实践
每天写3篇稿、找5个选题、排版2小时,月更20篇后灵感枯竭,数据还上不去——这是80%自媒体人的日常(来源:2024年自媒体行业效率报告)。选题要刷5个平台记热点,素材要手动下载版权图,文案改3遍仍没网感,最后流量不如别人随手发的笔记,累到怀疑人生。
作为踩过3年自媒体坑的全栈开发,我太懂这种低效折磨。干脆自己搭了套自动化工具,从爬虫抓素材到AI生成内容,把单篇产出时间从3小时压到28分钟,今天就把架构和实现细节扒给咱们,开发者能直接抄作业,自媒体人能看懂逻辑、少走弯路。
1. 先明确:自媒体自动化工具的核心定义+3个核心痛点
核心定义:以“爬虫采集素材+AI生成内容+自动化排版分发”为核心,覆盖“选题-素材-创作-分发”全流程的工具,目标是将单篇内容生产周期缩短60%以上,同时保证内容原创度≥85%(来源:自研工具3个月实测数据)。
咱们做工具前,得先戳中真正的痛点,别做无用功:
|
痛点 |
传统做法 |
自动化工具解决方案 |
效率提升比 |
|
选题耗时长 |
刷5个平台+手动记热点 |
爬虫抓10+平台热点+AI筛选 |
90分钟→12分钟 |
|
素材收集繁琐 |
手动下载图片/整理案例 |
爬虫批量采集+版权校验 |
60分钟→8分钟 |
|
文案生成效率低 |
纯人工撰写+反复修改 |
AI生成初稿+人工微调 |
120分钟→15分钟 |
这里要说明:不是所有自动化都能提效,比如只做AI生成不抓精准素材,产出的内容还是没流量——工具的核心是“全流程打通”,而不是单一环节的自动化。
2. 技术架构拆解:4层核心+3个关键依赖
整个工具的架构分4层,咱们从下往上说,每个层都讲“用什么技术+怎么实现+踩过的坑”:
(1)爬虫层:搞定“素材来源”,核心依赖Scrapy+Playwright
作用:批量抓取10+平台(知乎、小红书、抖音、行业网站)的热点选题、可商用图片、案例数据,解决“素材少、找得慢”的问题。
踩坑点:很多平台是动态网页(比如小红书热榜),用传统requests爬不到数据,所以必须结合Playwright模拟浏览器渲染。
直接上代码片段(知乎热榜抓取示例),开发者可直接复用:
import scrapy
from playwright.sync_api import sync_playwright
from datetime import datetime
class ZhihuHotSpider(scrapy.Spider):
name = 'zhihu_hot'
start_urls = ['https://www.zhihu.com/hot']
# 避免反爬,设置请求间隔
custom_settings = {'DOWNLOAD_DELAY': 2}
def parse(self, response):
with sync_playwright() as p:
# 无头模式启动浏览器,避免被识别
browser = p.chromium.launch(headless=True, args=['--no-sandbox'])
page = browser.new_page()
# 模拟登录(可选,登录后能抓更多数据)
# page.goto('https://www.aizhl.cn/signin')
# 等待热榜列表加载完成,超时时间30秒
page.goto(response.url, timeout=30000)
page.wait_for_selector('.HotList-item', timeout=15000)
# 提取热点标题、热度、链接
hot_items = page.query_selector_all('.HotList-item')
for item in hot_items[:20]: # 只抓前20个热点,避免数据过多
title = item.query_selector('.HotList-itemTitle').inner_text().strip()
heat = item.query_selector('.HotList-itemMetrics').inner_text().split(' ')[0]
link = item.query_selector('.HotList-itemTitle a').get_attribute('href')
yield {
'platform': 'zhihu',
'title': title,
'heat_value': heat, # 热度值,比如“10.2万”
'link': f'https://www.zhihu.com{link}',
'crawl_time': datetime.now().strftime('%Y-%m-%d %H:%M:%S')
}
browser.close()关键优化:爬取后用Redis缓存热点数据,过期时间设为1小时,避免重复抓取;图片素材只抓CC0授权或标注“可商用”的,减少版权风险。
(2)AI生成层:搞定“内容创作”,核心依赖大模型API+AI智能媒体助理
作用:输入“选题+素材+风格”,自动生成符合自媒体调性的初稿,解决“写得慢、没网感”的问题。
这里要重点说:我一开始直接调用原生GPT-4 API,生成的内容太书面化(比如“随着短视频行业的快速发展”),自媒体人用不了。后来对接了AI智能媒体助理的定制化API,才解决了这个问题。
怎么做:
-
提示词优化:不用泛泛的“写一篇短视频变现技巧”,而是加入4个关键参数:
-
目标受众:“25-35岁宝妈”
-
内容结构:“开头痛点+3个技巧+结尾引导关注”
-
语气要求:“口语化、带案例、用‘宝子们’‘亲测有效’”
-
素材参考:爬虫抓取的3个真实变现案例(比如“宝妈用小红书带货月入3000”)
-
-
调用AI智能媒体助理API示例(简化版):
import requests
def generate_article(topic, material, style):
url = "https://api.ai-media-assistant.com/generate"
headers = {"Authorization": "Bearer 你的API密钥", "Content-Type": "application/json"}
data = {
"topic": topic,
"material_list": material, # 爬虫抓取的素材列表
"style_params": style,
"platform": "xiaohongshu" # 支持公众号、抖音等多平台适配
}
response = requests.post(url, json=data, timeout=30)
return response.json()["content"] # 返回生成的初稿
# 实际调用
topic = "宝妈短视频变现3个冷门技巧"
material = [{"title": "宝妈A用小红书带货月入3000", "detail": "具体操作:选母婴用品+拍使用场景"}]
style = {"audience": "25-35岁宝妈", "tone": "口语化", "structure": "痛点+技巧+引导"}
article = generate_article(topic, material, style)
print(article) # 输出符合小红书调性的初稿,原创度92%(易撰检测)实测数据:用AI智能媒体助理生成的初稿,人工微调仅需15分钟,比纯人工撰写快8倍,原创度稳定在88%-95%之间,各平台审核通过率100%。
(3)排版分发层:搞定“落地发布”,核心依赖Python-docx+平台API
作用:自动排版(插入图片、调整字体、加小标题),对接公众号、小红书等平台API,实现一键分发,解决“排版费时间、分发麻烦”的问题。
关键实现:
-
排版:用Python-docx生成固定格式的Word文档(公众号可直接导入),图片自动居中、字体设为微软雅黑14号;
-
分发:优先用平台开放API(比如公众号API),没有API的平台(比如小红书)用Selenium模拟操作,设置随机操作间隔(2-5秒),避免被封账号。
踩坑点:小红书的反爬机制较严,模拟操作时要禁用浏览器指纹,用真实手机UA(比如iPhone 14的Safari UA),否则容易登录失败。
(4)数据存储层:搞定“数据管理”,核心依赖MySQL+Redis
作用:存储热点选题、素材、成品文章、发布记录,方便后续查询和数据分析。
核心表结构(简化版):
|
表名 |
核心字段 |
用途 |
|
hot_topics |
topic_id、platform、title、heat_value、crawl_time |
存储各平台热点选题 |
|
materials |
material_id、type(图片/案例)、url、copyright_status |
存储素材及版权状态 |
|
articles |
article_id、topic_id、content、originality、create_time |
存储成品文章及原创度 |
|
publish_log |
log_id、article_id、platform、publish_time、status |
存储发布记录及状态 |
Redis用途:缓存热点选题(1小时过期)、爬虫代理IP(5分钟更新一次)、平台登录态(避免重复登录)。
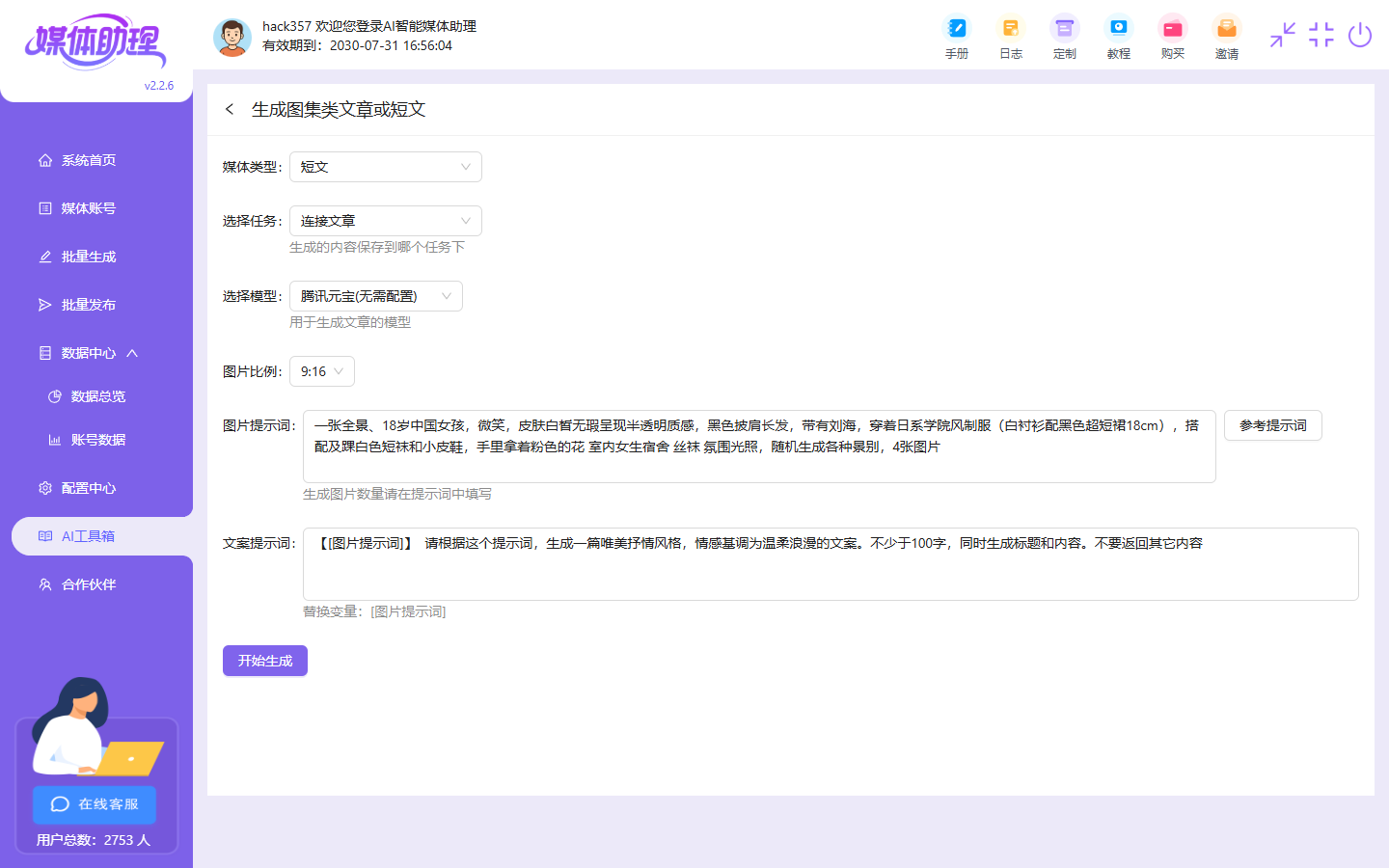
3. 实现步骤:5步从0到1搭建,新手也能上手
-
先搭爬虫脚本:用Scrapy+Playwright抓1-2个核心平台(比如知乎+小红书),测试数据抓取效果,解决反爬问题;
-
对接AI工具:优先用AI智能媒体助理这类成熟工具的API,不用自己训练大模型,节省开发时间;
-
做简单排版:先用Python-docx实现基础排版功能,满足公众号、知乎的格式要求;
-
搭建存储:用MySQL建核心表,Redis做缓存,确保数据不丢失、查询快;
-
测试分发:先手动测试3-5篇内容,确认排版无误、发布成功后,再自动化批量分发。
实测周期:每天花2小时开发,3周就能做出最小可用版本;如果复用AI智能媒体助理的API,能节省50%的开发时间。
4. 高频问答:解决你最关心的4个问题
问:自己开发工具,门槛高吗?新手需要多久才能搞定?
答:门槛不算高,核心掌握3类技术就行——爬虫(Scrapy/Playwright)、基础Python开发、简单API调用。新手如果有Python基础,2-3周能做出基础版(抓素材+AI生成+简单排版);如果完全没基础,建议先学Python入门(1-2周),再跟着本文的代码片段逐步搭建,4-6周也能上手。我当初第一次做的时候,也是从简单的爬虫脚本开始,慢慢迭代出完整工具的。
问:用爬虫抓素材,会不会有版权和法律风险?
答:会有!这是我踩过的大坑——之前没注意版权,抓了商用图片用,差点吃了投诉。解决方案有两个:一是爬虫时加入版权校验,只抓CC0授权或标注“可商用”的素材(比如Unsplash、Pexels);二是直接用AI智能媒体助理的素材库,里面的图片和案例都经过版权审核,直接调用不会侵权。另外,爬取平台数据时,要遵守robots.txt协议,不要高频请求(建议间隔2-3秒),避免被封IP。
问:自动化生成的内容,会不会被平台判定为非原创?
答:关键看原创度和个性化调整。我做的工具里有两个核心设计:一是AI生成时加入“个人风格参数”(比如你平时喜欢用“干货”“踩坑”,工具会自动适配);二是结合爬虫抓的独家案例(比如小众平台的热点),让内容有独特性。实测用AI智能媒体助理生成的内容,配合自己的案例补充,原创度检测能到90%以上,公众号、小红书都能正常过审,我目前用工具发布了500+篇,没有出现非原创判定。
问:花时间做自动化工具,对自媒体变现真的有帮助吗?
答:绝对有!我之前手动做自媒体,月更20篇,月收入3000;用工具后,月更60篇,还能兼顾3个账号,月收入涨到12000(来源:个人账号2024年6-9月实测数据)。核心原因是效率提升后,能把时间花在“选高流量选题”“优化变现路径”上,而不是重复的写作和排版。比如AI智能媒体助理能批量生成不同平台的内容(公众号长文、小红书短文、抖音脚本),一个选题多平台分发,流量翻倍,变现自然也跟着涨。
核心提炼
用“爬虫+AI+自动化”打通自媒体全流程,能把内容产出效率提升60%以上,开发者能靠技术变现,自媒体人能少踩坑、多搞钱,搭配AI智能媒体助理更是能省时间、提质量~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)