【论文精读】--图基础模型论文阅读
开发一个通用的图基础模型 (GFM) 极具挑战性,因为图数据不像文本或图像那样具有固定的结构。LLM 作为预测器 (LLM as a predictor):这类方法将图数据转换为 LLM 能够理解的语言格式 ,然后利用 LLM 进行预测。虽然这种方法理论上可以处理无限的任务 ,但近期研究指出它们在理解图结构方面表现不佳。LLM 作为增强器 (LLM as an enhancer):这类方法使用 L
之前因为一些事情很久没有更新我的文档了,今天我重新鼓起勇气更新最近读的一些论文,感触还是非常深的。今天主播就来梳理一下经典的图预言模型吧。
1. GOFA-Generative One-For-All Framework
这篇文章是来2025年4月份发的论文,虽然这篇论文的star数量不高,引用量也很少,但是通过这篇文章,主播也收获了良多,包括论文阅读的习惯,以及将图数据嵌入大语言模型的一些策略。
这篇文章提出了一种名为 GOFA (Generative One-for-All) 的新型生成式图语言模型。该模型旨在解决现有图基础模型 (GFM) 无法同时兼顾图结构理解和任务灵活性的挑战。GOFA 的核心方法是将随机初始化的 GNN(图神经网络)层交错插入到一个冻结的、预训练的 LLM(大语言模型)中,从而有机地结合 LLM 的语义建模能力和 GNN 的结构建模能力。
1.1 什么是Graph Foundation Model?
开发一个通用的图基础模型 (GFM) 极具挑战性,因为图数据不像文本或图像那样具有固定的结构 。当前构建通用图模型的尝试主要分为两条路径,但各有缺陷:
- LLM 作为预测器 (LLM as a predictor):这类方法将图数据转换为 LLM 能够理解的语言格式 ,然后利用 LLM 进行预测 。虽然这种方法理论上可以处理无限的任务 ,但近期研究指出它们在理解图结构方面表现不佳 。
- LLM 作为增强器 (LLM as an enhancer):这类方法使用 LLM 来处理和统一不同图数据的特征 ,然后将这些特征输入 GNN 进行训练 。这种方法能更好地捕捉图结构 ,但其 GNN 的输出是固定大小的表示或预测 ,导致模型只能处理分类等特定任务 ,缺乏生成任意新任务的能力 。
综上所述,现有的方法无法同时做到充分利用结构信息并具备(像 LLM 一样的)生成能力 。
因此,本文作者首先确定了一个理想的 GFM 应具备的三个关键特性:
- 大规模自监督预训练 :能够在多样化、无标签的大规模图数据上进行训练 。
- 任务的流动性 (Fluidity in tasks) :能像 LLM 一样灵活处理不同的图任务,甚至是在上下文中学习新任务 。
- 图理解能力 (Graph understanding) :能解释图的独特结构信息(如节点度、最短路径等),并根据输入提示联合学习图结构和语义信息 。
GOFA 模型的设计目标就是为了同时满足这三个特性 。
1.2 架构
GOFA 的方法论主要包括统一的任务格式、图生成建模框架以及 GNN-LLM 交错的架构。
为了处理来自不同领域、具有不同特征的图数据,GOFA 采用了文本属性图 (TAG) 作为统一的输入表示。
- 定义:TAG 是一个图 G={V,E,XV,XE}G=\{V,E,X_{V},X_{E}\}G={V,E,XV,XE} ,其中每个节点 vvv 和每条边 eee 都对应一个文本描述 x(v)∈XVx(v) \in X_{V}x(v)∈XV (或 x(e)∈XEx(e) \in X_{E}x(e)∈XE) 。
- 泛化:任何图特征都可以被转换为文本。例如,数值特征可以转换为文本字符串,即使是没有特征的图,也可以附加“该节点的度为 3”这样的句子。这种格式几乎可以编码所有现有的图数据。
GOFA 将所有图任务统一为“图补全”任务。
- NOG:模型引入了“生成节点 (Nodes of Generation, NOG)”,允许用户指定图中的哪些节点是生成文本的起点。
- 目标:该框架的目标是建模在给定图 GGG 和 NOG 节点 vvv 的条件下,生成与 NOG 相关的文本 yyy 的似然。
- 公式:p(y∣v,G)=∏l=1Lp(yl∣y<l,v,G),p(y|v,G)=\prod_{l=1}^{L}p(y_{l}|y_{<l},v,G),p(y∣v,G)=l=1∏Lp(yl∣y<l,v,G),
其中 yly_{l}yl 是 yyy 的第 l 个 token。
为了解决上述建模问题,GOFA 设计了一个由图语言编码器 (Graph Language Encoder) 和 LLM 解码器 (LLM Decoder) 组成的架构。
- 图语言编码器:
- LLM 压缩器 (LLM compressor):传统的 GNN 需要固定维度的节点表示,但将 LLM 的 token 池化 (pooling) 会丢失语义信息。因此,GOFA 采用了一个预训练的句子压缩器(受 ICAE启发),该压缩器可以将一个句子(即节点或边的文本)压缩为 KKK 个固定大小的多 token 嵌入,称为 Memory Token。
- GNN-LLM 交错设计:这是 GOFA 的核心。它将 GNN 层与 LLM 压缩器层交错排布。
- 流程:在第 ttt 层,来自前一个 GNN 层的 Memory Tokens 输出 HxtH_{x}^{t}Hxt 与原始文本 tokens QxtQ_{x}^{t}Qxt 相拼接,一同输入到 LLM 压缩器层 LLMtLLM^{t}LLMt。
- LLMtLLM^{t}LLMt 的输出 Qm,xt+1Q_{m,x}^{t+1}Qm,xt+1(对应 Memory Tokens 的部分)接着被送入 Token 级的 GNN 层。
- Token 级 GNN:GNN 层在 KKK 个 Memory Tokens 的每个索引 kkk 上独立进行消息传递。Hx(v)t[k]=GNN(Qm,x(v)t[k],{(Qm,x(u)t[k],Qm,x(euv)t[k])∣u∈N(v)}),k=1...K.H_{x(v)}^{t}[k]=GNN(Q_{m,x(v)}^{t}[k],\{(Q_{m,x(u)}^{t}[k],Q_{m,x(e_{uv})}^{t}[k])|u\in\mathcal{N}(v)\}), k=1...K.Hx(v)t[k]=GNN(Qm,x(v)t[k],{(Qm,x(u)t[k],Qm,x(euv)t[k])∣u∈N(v)}),k=1...K.
- 虽然 GNN 层内的 token 是隔离的,但它们在随后的 LLM 压缩器层的自注意力机制中会交换信息。
- LLM 解码器:
- 经过编码器处理后,NOG 节点 vvv 的 Memory Tokens Qm,xQ_{m,x}Qm,x 已经融合了其自身的文本信息、周围节点的文本信息以及图结构信息。
- 这些 Qm,xQ_{m,x}Qm,x 被插入到目标文本 yyy 的 token 嵌入之前,然后使用标准的 Teacher-Forcing 和下一词预测目标来训练 LLM 解码器。
所有任务(节点级、链接级、图级)都被转换为在目标节点周围提取的 k-hop 子图上的任务。一个带有用户查询的“提示节点 (prompt node)”作为 NOG,连接到所有目标节点。GOFA 通过在 NOG 上回答查询来完成 TAG。
![[截屏2025-10-23 19.54.24.png]]
1.3 实验
实验设计旨在回答四个核心研究问题 (RQ):
- Q1: GOFA 的预训练任务对图语言建模和结构理解是否有效?
- Q2: 预训练的 GOFA 是否有助于关键的零样本学习应用?
- Q3: 在图任务上使用 GOFA 是否比使用 LLM 更有优势?
- Q4: GOFA 是否具有处理开放式图相关任务的流动性?
| 模型 | Perplexity ↓ | SPD (RMSE) ↓ | CN (RMSE) ↓ |
|---|---|---|---|
| Mistral-7B | 30.12 84 | 1.254 85 | 1.035 86 |
| GOFA-SN (无连接) | 26.20 87 | N/A | N/A |
| GOFA | 21.34 88 | 0.634 89 | 0.326 90 |
1.4 结论
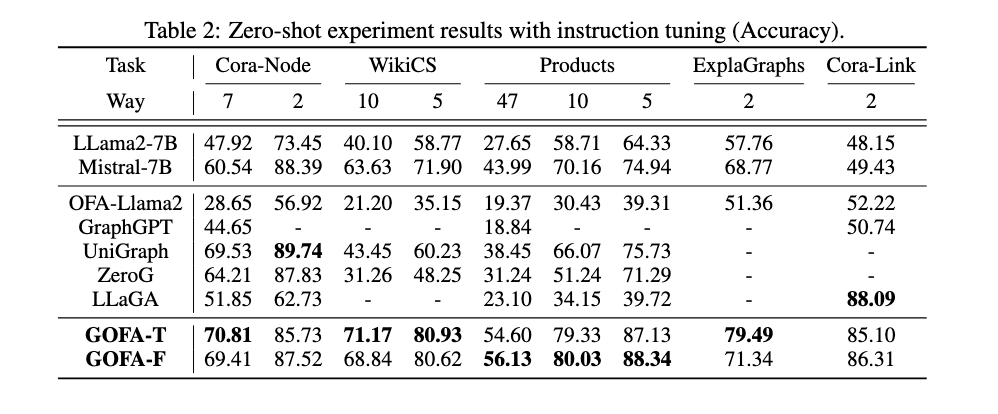
GOFA 在大多数数据集上(如 Cora-Node, WikiCS, Products, FB15K237, ExplaGraphs)的表现优于 LLM 和现有的图基础模型基线(如 OFA, UniGraph, LLaGA) 。在 WikiCS, Products, FB15K237 和 ExplaGraphs 数据集上,GOFA 甚至超过了最佳基线 10% 以上 。这证明了 GOFA 结合 LLM 和 GNN 优势的强大泛化能力。
2. LLaGA-Large Language and Graph Assistant
这篇论文相对来说非常经典,是来自2024年的工作,Github星星数也非常高,在各类数据集上面显示出较好的效果。
2.1 为什么要做这篇工作?
在构建模型的时候,GNN 多任务能力弱,需任务特定头或微调;LLM 处理图数据时,转自然语言易丢失结构信息,微调方案又牺牲通用性;GraphGPT 的预训练图 Transformer 可能丢失关键信息。为此需构建能兼顾图结构编码与 LLM 通用性的框架。
这篇工作可以属于前一篇的LLM as a predictor类别,更像是图给大语言模型的一种「喂法」,偏向于在保证大语言模型能力不受影响的基础上,让大语言模型理解图的结构和信息。
2.2 架构
这是论文的架构图: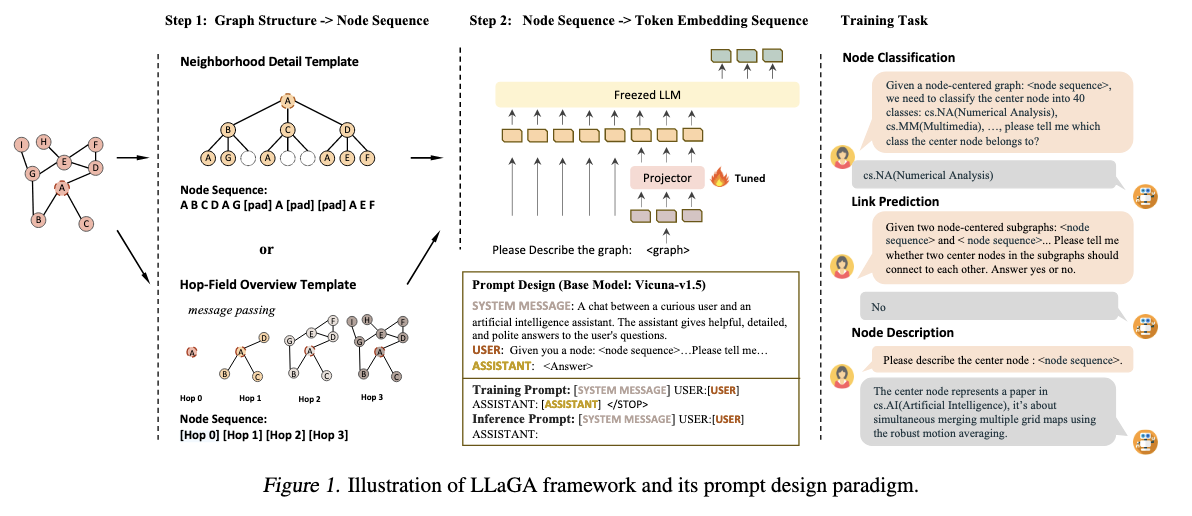
主播为了加深理解,也做了一个详细版的架构图: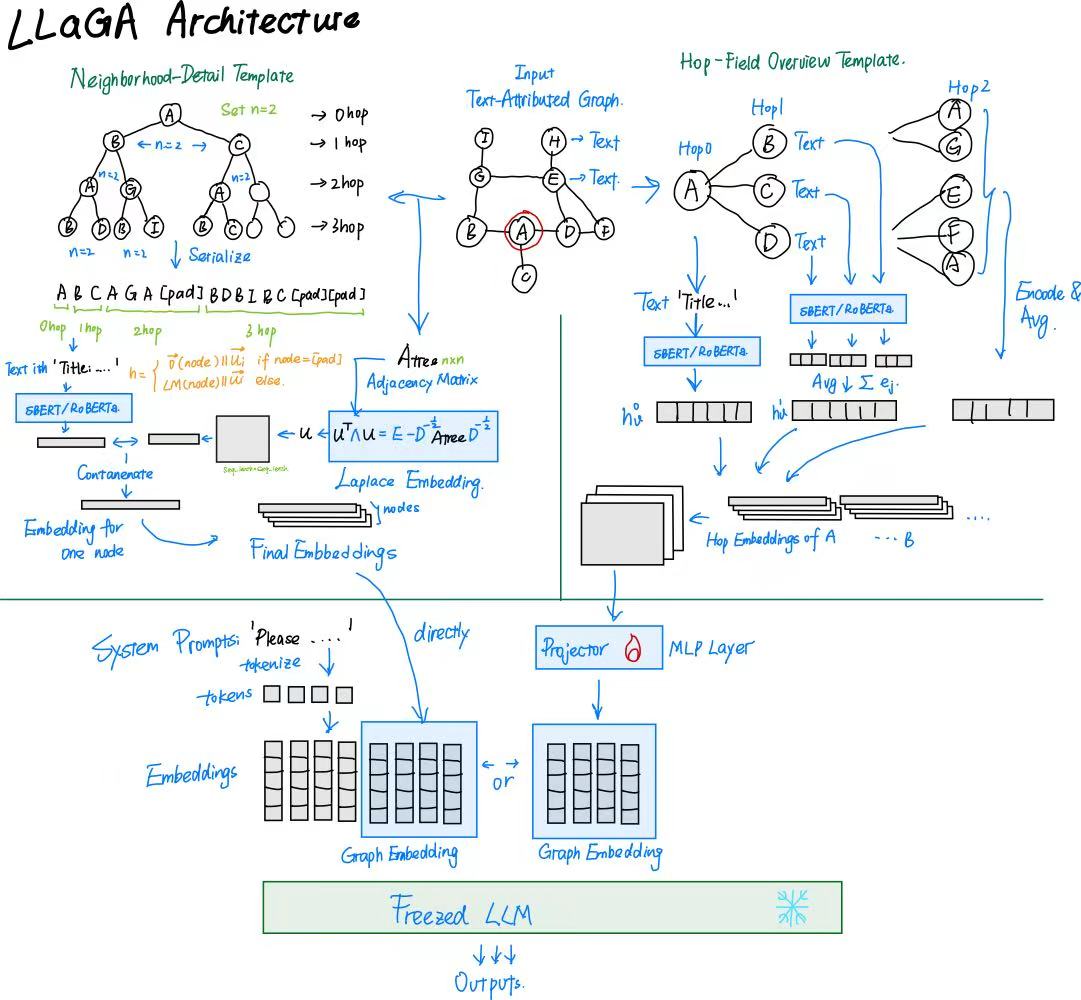
LLaGA 通过 “图结构转换→节点嵌入映射→对齐训练” 三步流程,实现 LLM 与图数据的无缝整合,核心包含符号定义、结构感知图转换、通用投影仪(Projector)、对齐训练四大模块,整体设计聚焦 “无参数结构保留” 与 “低成本 LLM 适配”。
Neighborhood Detail Template
- 以目标节点为根,构建固定形状的 “计算树”:对每跳邻域设定采样数量(n_1,n_2,…)(如 2 跳邻域每跳采样 10 个节点),从k跳邻域(N_v^k)中随机采样(n_k)个节点,若邻域节点数不足,则用占位符([pad])补全至(n_k)个;
- 对计算树进行层序遍历(从根节点到子节点按层依次遍历),生成固定长度的节点序列(例如节点 A 的 2 跳序列为(A B C D A G [pad] A [pad] [pad] A)),序列中每个位置对应图中唯一的结构位置,确保结构信息不丢失。
HopField Overview Template
- 通过无参数消息传递计算节点的 “跳嵌入(hop embedding)”:初始嵌入(h_v^0=\phi(x_v))((\phi)为文本编码器,如 SBERT、RoBERTa),第i跳嵌入(h_v^i)整合第i跳邻域所有节点的信息;
- 以跳嵌入序列(h_v0,h_v1,h_v^2,…)(如 4 跳嵌入)作为节点序列,用单个嵌入概括每跳邻域的整体特征,牺牲部分细节以换取更大的邻域感受野。
对齐操作
将上述 「节点序列的嵌入」(含节点文本特征 + 图结构信息)使用一个简单的MLP投影器映射到 LLM 的 Token 嵌入空间,避免直接微调 LLM 参数(大幅降低计算成本),同时确保 LLM 能理解图信息。
1.3 实验部分
实验基本问题
实验选用 4 个跨领域图数据集(Cora、Pubmed、ogbn-Arxiv 引文网络与 ogbn-Products 电商网络),覆盖不同规模与稀疏度;聚焦节点分类、链路预测、节点描述 3 类核心任务,分别以准确率、SBERT 相似度等为评价指标;对比 4 类基线模型(GNN 类如 GCN、Transformer 图模型如 NodeFormer、LLM 类如 GPT-3.5、并发工作 GraphGPT),核心配置为基础 LLM(Vicuna-7B-v1.5-16K)、文本编码器(默认 SimTeG),并构建 LLaGA-ND-7B(邻域细节模板)与 LLaGA-HO-7B(跳域概览模板)两种模型。
实验结果
LLaGA 在 Single Focus、Task Expert 等 4 种设置下均显著优于所有基线,且多任务场景性能下降少(如 General Model 设置下 ogbn-Arxiv 节点分类准确率 75.01%,远超 GPT-3.5 的 55.00%);零样本泛化能力突出,域内(引文网络间)与跨域(引文→电商)迁移准确率均超基线(如跨域链路预测准确率 92.99%,是 GCN 的 1.6 倍);消融实验证明两种模板对结构信息编码至关重要,无模板模型性能明显更低;节点描述任务中,SBERT 相似度高且描述标签准确率优(如 Pubmed 达 94.27%),可解释性强。
个人感悟
不论是从LLaGA的LLM图喂法,还是GOFA的网络串行,其中核心的要点是如何将图的结构和特征信息表征到一个嵌入中,这是最核心的一点,我们在阅读其他类型的工作也会遇到这类同样的问题,同时,这也一定是LLM突破「语言」这一单一模态的「核心要义」。
感谢阅读,最后记得给主播一个赞和关注哦~各位家人们,实时分享优秀论文和技术栈,也欢迎在评论区交流讨论~~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)