PikiwiDB(pika) 分布式集群架构解析
PikiwiDB(pika)3.5.X版本发布了分布式集群方案,基于codis+PikiwiDB(pika)-server实现,已经在360内部搜索团队线上使用,稳定性和性能都非常优秀。本文主要介绍分布式集群的架构和部署方案。
一、概述
PikiwiDB(pika)3.5.X版本发布了分布式集群方案,基于codis+PikiwiDB(pika)-server实现,已经在360内部搜索团队线上使用,稳定性和性能都非常优秀。本文主要介绍分布式集群的架构和部署方案。
二、分布式架构解析
pika分布式集群基于codis架构进行改造设计,架构图如下所示:
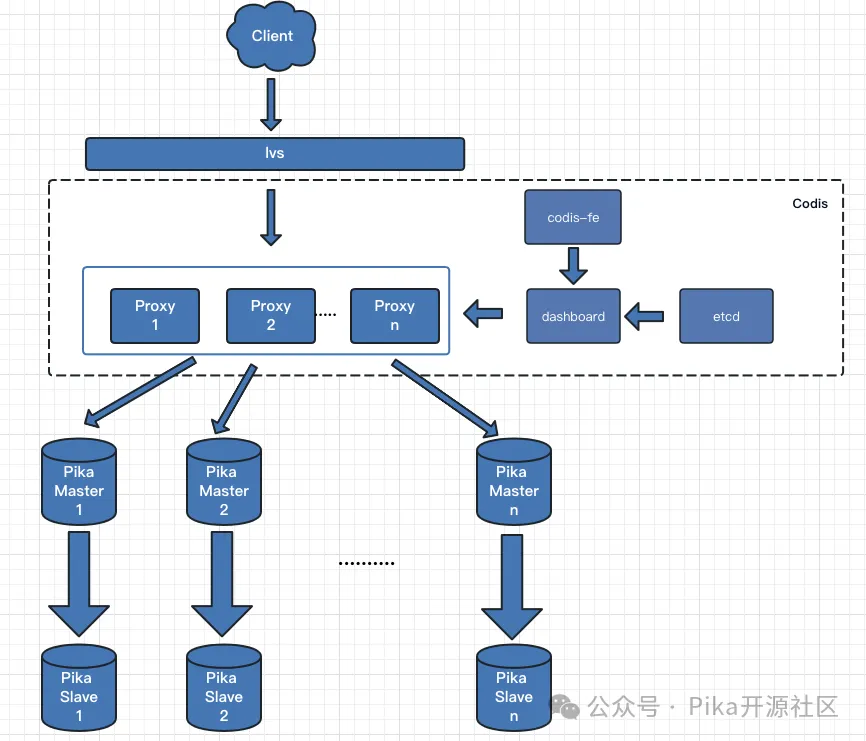
pika分布式集群主要 由以下这些组件组成:
Pika Server:PikiwiDB(pika)3.5.X, PikiwiDB(pika)4.0.x版本,与单机版模式及架构保持一致。
Codis Proxy:客户端直接连接 codis-proxy,codis-proxy 手动用户请求后,会通过计算 hash 值将请求转发到指定的 Pika Server 去执行。
对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例;
不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
Codis Dashboard:集群管理工具,支持 codis-proxy、pika-server 的添加、删除,以及据迁移等操作。在集群状态发生改变时,codis-dashboard 维护集群下所有 codis-proxy 的状态的一致性。
对于同一个业务集群而言,同一个时刻 codis-dashboard 只能有 0个或者1个;
所有对集群的修改都必须通过 codis-dashboard 完成。
Codis FE:集群管理界面。
多个集群实例共享可以共享同一个前端展示页面;
通过配置文件管理后端 codis-dashboard 列表,配置文件可自动更新。
Codis Etcd:
codis-etcd主要用于记录元数据信息,为保证高可用,建议etcd部署为3节点。
三、Sentinel主从切换
为了方便运维管理,本次版本支持sentinel自动主从切换,当集群主挂的时候会备升主,提供了主节点故障自愈的能力。
四、部署方式
机器配置可以根据自身情况选择:
搜索部门节点分配如下:
|
组件 |
节点个数(可以根据需求调整) |
实例规格(可以根据需求调整) |
|
pika server |
12主12从 |
每个实例:20核,32G内存,200G磁盘 |
|
Codis FE |
1个节点 |
1个节点 2核4G |
|
Codis Dashboard |
1个节点 |
1个节点 2核4G |
|
Codis Etcd |
3个节点 |
3个节点 2核4G |
|
Codis Proxy |
4个节点 |
4个节点 2核4G |
集群创建部署顺序:
- 启动 PikiwiDB(pika)
- 建立 PikiwiDB(pika) 主从关系
- 启动 codis etcd
- 启动 codis dashboard
- 启动 codis proxy
- 启动 codis fe
- 绑定 PikiwiDB(pika)+codis
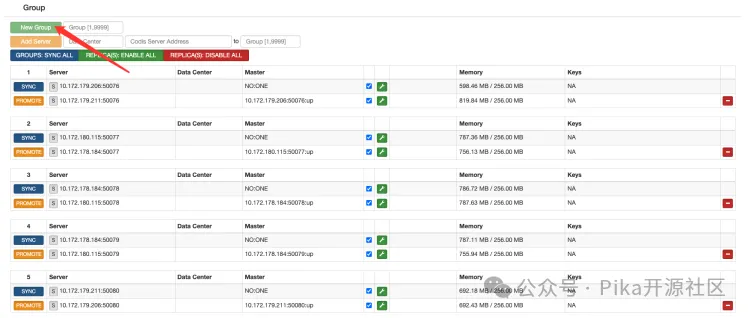
绑定 codis+PikiwiDB(pika) 需要在 dashboard 中进行操作,操作顺序如下:
1.添加 group (注意:PikiwiDB(pika) 1主一从为一个 group )
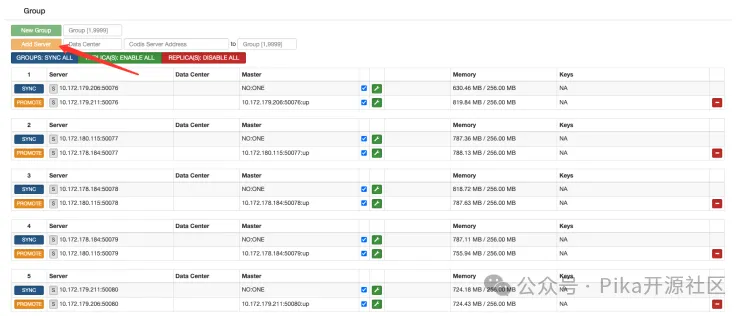
2.添加 PikiwiDB(pika)server
3.分配 slots :
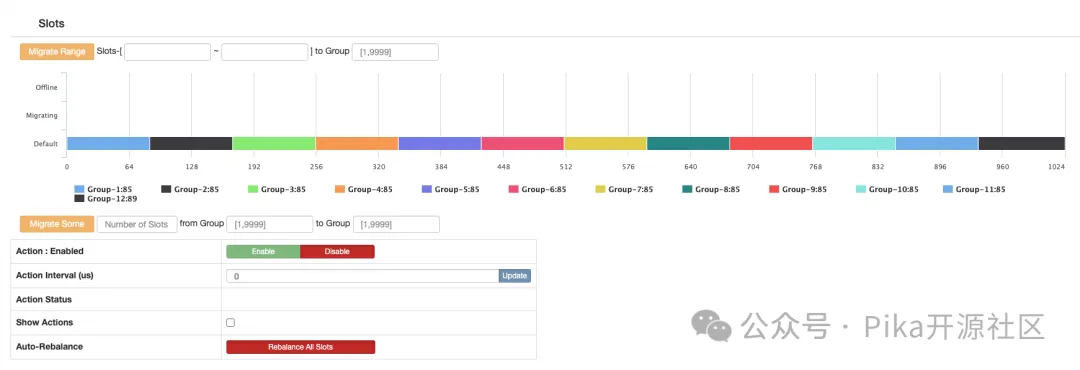
至此,PikiwiDB(pika) 和 codis 已经绑定完毕,我们可以用 proxy 的 vip vport 进行访问。
五、快速启动脚本
PikiwiDB(pika)-codis 源码(路径:) 中 admin 文件夹提供了一系列脚本以便快速启动、停止各个组件,提高运维效率。
启动codis-dashboard
使用 codis-dashboard-admin.sh 脚本启动 dashboard,并查看 dashboard 日志确认启动是否有异常。
|
|
快速启动集群元数据存储使用 filesystem,默认数据路径保存在 /tmp/codis,若启动失败,请检查当前用户是否对该路径拥有读写权限。
启动codis-proxy
使用 codis-proxy-admin.sh 脚本启动 codis-proxy,并查看 proxy 日志确认启动是否有异常。
|
|
启动codis-server
使用 codis-server-admin.sh 脚本启动 codis-server,并查看 redis 日志确认启动是否有异常。
|
|
redis.conf 配置中 pidfile、logfile 默认保存在 /tmp 目录,若启动失败,请检查当前用户是否有该目录的读写权限。
启动codis-fe
使用 codis-fe-admin.sh 脚本启动 codis-fe,并查看 fe 日志确认启动是否有异常。
六、Codis部分代码详细解析
1. Pika Server
codis架构中,pika server作为数据节点存储数据,处理codis proxy的读写请求,并根据slot迁移的命令进行数据迁移。
1.1 数据存储
在codis架构中,所有的数据按照分片进行存储。因此每个pika server只持有部分分片的数据。当前的pika实现中,相同类型的所有数据是写在同一个RocksDB实例中,引擎中数据本身并不携带slot信息。
codis在进行数据迁移时,支持key粒度的迁移和slot粒度的迁移。key粒度的迁移比较好理解,slot粒度的迁移,就需要在存储引擎中找到对应slot的存量数据。pika是通过为每个slot创建一个set类型的key,以此来记录每个slot中存储的key来实现的。由于该操作会引入额外的更新操作,对性能会有影响。因此pika中设置了slotmigrate_参数来表示是否要支持slot粒度迁移。如果不支持,就不需要更新slot set。
pika节点在收到proxy节点发来的请求之后,如果开启了slot_migrate,除了将用户数据写入RocksDB以外,还需要计算得出数据的slotID,将key和type追加到以对应slotID为key的set集合中。该步骤在pika_command层进行处理。以mset为例,写db成功之后会调用AddSlotKey将key记录到对应set中。
void MsetCmd::Do(std::shared_ptr<Slot> slot) {
storage::Status s = slot->db()->MSet(kvs_);
if (s.ok()) {
res_.SetRes(CmdRes::kOk);
std::vector<storage::KeyValue>::const_iterator it;
for (it = kvs_.begin(); it != kvs_.end(); it++) {
AddSlotKey("k", it->key, slot);
}
} else {
res_.SetRes(CmdRes::kErrOther, s.ToString());
}
}void AddSlotKey(const std::string& type, const std::string& key, const std::shared_ptr<Slot>& slot) {
if (g_pika_conf->slotmigrate() != true) {
return;
}
int slotID = GetSlotsID(key, &crc, &hastag);
std::string slot_key = GetSlotKey(slotID);
std::vector<std::string> members;
members.emplace_back(type + key);
s = slot->db()->SAdd(slot_key, members, &res);
if (!s.ok()) {
LOG(ERROR) << "sadd key[" << key << "] to slotKey[" << slot_key << "] failed, error: " << s.ToString();
return;
}
// codis hash tag模式
if (hastag) {
std::string tag_key = GetSlotsTagKey(crc);
s = slot->db()->SAdd(tag_key, members, &res);
if (!s.ok()) {
LOG(ERROR) << "sadd key[" << key << "] to tagKey[" << tag_key << "] failed, error: " << s.ToString();
return;
}
}
}1.2 Slot迁移
codis的架构中,slot迁移包括key粒度的迁移(通过命令slotsmgrtone, slotsmgrttagone)每次将一个key迁移到目的端。还有一种是分片粒度迁移。主要涉及的类包括PikaMigrate, PikaMigrateThread和PikaParseSendThread。首先介绍PikaMigrateThread类。
class PikaMigrateThread : public net::Thread {
public:
bool ReqMigrateBatch(const std::string &ip, int64_t port, int64_t time_out, int64_t slot_num, int64_t keys_num,
const std::shared_ptr<Slot>& slot);
int ReqMigrateOne(const std::string &key, const std::shared_ptr<Slot>& slot);
private:
void NotifyRequestMigrate(void);
void ReadSlotKeys(const std::string &slotKey, int64_t need_read_num, int64_t &real_read_num, int32_t *finish);
bool CreateParseSendThreads(int32_t dispatch_num);
void DestroyParseSendThreads(void);
void *ThreadMain() override;
int32_t workers_num_ = 0;
std::vector<PikaParseSendThread *> workers_;
std::deque<std::pair<const char, std::string>> mgrtone_queue_;
std::deque<std::pair<const char, std::string>> mgrtkeys_queue_;
std::map<std::pair<const char, std::string>, std::string> mgrtkeys_map_;PikaMigrateThread是Pika的后台迁移线程,负责收集待发送的key,创建迁移线程,管理迁移流程。PikaMigrateThread创建了若干个实际的迁移线程(即workers_),负责在后台进行数据迁移。
待迁移的数据有两个来源,一个接收到是codis发来的异步迁移单个key的命令,将具体的key追加到mgrtone_queue_队列中,再由PikaMigrateThread线程消费mgrtone_queue_将数据追加到mgrtkeys_queue_中。另一个是遍历slotkey对应的set,将遍历到的key追加到mgrtkeys_queue_中。wokers_线程从mgrtkeys_queue_中消费出待迁移的key并进行发送。
PikaParseSendThread是迁移的worker线程,在一个while循环中消费mgrtkeys_queue_,将key发送到对应的接收端。MigrateOneKey会根据key类型的不同调用不同的处理函数构造网络请求包,比如string类型直接从引擎中读取value并发送,hash类型则需要将整个pkey下的所有field遍历出来并发送。当前的migrateOneKey的实现中查询两次RocksDB并发送两次请求包,一次是key-value本身,第二次是ttl。
void *PikaParseSendThread::ThreadMain() {
while (!should_exit_) {
//消费mgrtkeys_queue_
std::deque<std::pair<const char, std::string>> send_keys;
{
migrate_thread_->IncWorkingThreadNum();
for (int32_t i = 0; i < mgrtkeys_num_; ++i) {
if (migrate_thread_->mgrtkeys_queue_.empty()) {
break;
}
send_keys.emplace_back(migrate_thread_->mgrtkeys_queue_.front());
migrate_thread_->mgrtkeys_queue_.pop_front();
}
}
int64_t send_num = 0;
int64_t need_receive_num = 0;
int32_t migrate_keys_num = 0;
for (const auto& send_key : send_keys) {
// 发送单个key
if (0 > (send_num = MigrateOneKey(cli_, send_key.second, send_key.first, false))) {
LOG(WARNING) << "PikaParseSendThread::ThreadMain MigrateOneKey: " << send_key.second << " failed !!!";
migrate_thread_->OnTaskFailed();
migrate_thread_->DecWorkingThreadNum();
return nullptr;
} else {
need_receive_num += send_num;
++migrate_keys_num;
}
}
// 阻塞,等待收到need_receive_num个数据包
if (!CheckMigrateRecv(need_receive_num)) {
LOG(INFO) << "PikaMigrateThread::ThreadMain CheckMigrateRecv failed !!!";
migrate_thread_->OnTaskFailed();
migrate_thread_->DecWorkingThreadNum();
return nullptr;
} else {
DelKeysAndWriteBinlog(send_keys, slot_);
}
migrate_thread_->AddResponseNum(migrate_keys_num);
migrate_thread_->DecWorkingThreadNum();
}
return nullptr;
}
int PikaParseSendThread::MigrateOneKey(net::NetCli *cli, const std::string& key, const char key_type, bool async) {
int send_num;
switch (key_type) {
case 'k':
if (0 > (send_num = MigrateKv(cli_, key, slot_))) {
return -1;
}
break;
......
default:
return -1;
break;
}
return send_num;
}相对于PikaParseSendThread,PikaMigrateThread并不执行实际的数据迁移任务,而是用来进行迁移任务的管理。pika后台线程线程的执行是分批次进行,每一批次执行完成之后会挂起,需要被再次唤醒。PikaMigrateThread后台线程的主要代码执行流程如下:
LOG(INFO) << "PikaMigrateThread::ThreadMain Start";
// Create parse_send_threads
auto dispatch_num = static_cast<int32_t>(g_pika_conf->thread_migrate_keys_num());
if (!CreateParseSendThreads(dispatch_num)) {
LOG(INFO) << "PikaMigrateThread::ThreadMain CreateParseSendThreads failed !!!";
DestroyThread(true);
return nullptr;
}
std::string slotKey = GetSlotKey(static_cast<int32_t>(slot_id_));
int32_t slot_size = 0;
slot_->db()->SCard(slotKey, &slot_size);
while (!should_exit_) {
// Waiting migrate task
{
std::unique_lock<std::mutex> lm(request_migrate_mutex_);
while (!request_migrate_) {
request_migrate_cond_.wait(lm);
}
// 每轮迁移对应一个task,执行完成之后需要被再次唤醒
request_migrate_ = false;
}
// read keys form slot and push to mgrtkeys_queue_
int64_t round_remained_keys = keys_num_;
int64_t real_read_num = 0;
int32_t is_finish = 0;
send_num_ = 0;
response_num_ = 0;
do {
std::unique_lock lq(mgrtkeys_queue_mutex_);
std::unique_lock lo(mgrtone_queue_mutex_);
std::unique_lock lm(mgrtkeys_map_mutex_);
// 查找待迁移的key,包括单key的迁移和slot迁移
if (!mgrtone_queue_.empty()) {
while (!mgrtone_queue_.empty()) {
mgrtkeys_queue_.push_front(mgrtone_queue_.front());
mgrtkeys_map_[mgrtone_queue_.front()] = INVALID_STR;
mgrtone_queue_.pop_front();
++send_num_;
}
} else {
int64_t need_read_num = (0 < round_remained_keys - dispatch_num) ? dispatch_num : round_remained_keys;
ReadSlotKeys(slotKey, need_read_num, real_read_num, &is_finish);
round_remained_keys -= need_read_num;
send_num_ += static_cast<int32_t>(real_read_num);
}
//唤醒worker线程
mgrtkeys_cond_.notify_all();
} while (0 < round_remained_keys && !is_finish);
LOG(INFO) << "PikaMigrateThread:: wait ParseSenderThread finish";
//阻塞等待worker线程执行完成
{
std::unique_lock lw(workers_mutex_);
while (!should_exit_ && is_task_success_ && send_num_ != response_num_) {
workers_cond_.wait(lw);
}
}
LOG(INFO) << "PikaMigrateThread::ThreadMain send_num:" << send_num_ << " response_num:" << response_num_;
if (should_exit_) {
LOG(INFO) << "PikaMigrateThread::ThreadMain :" << pthread_self() << " exit2 !!!";
DestroyThread(false);
return nullptr;
}
// check one round migrate task success
if (!is_task_success_) {
LOG(ERROR) << "PikaMigrateThread::ThreadMain one round migrate task failed !!!";
DestroyThread(true);
return nullptr;
} else {
moved_num_ += response_num_;
std::unique_lock lm(mgrtkeys_map_mutex_);
std::map<std::pair<const char, std::string>, std::string>().swap(mgrtkeys_map_);
}
// check slot migrate finish
int32_t slot_remained_keys = 0;
slot_->db()->SCard(slotKey, &slot_remained_keys);
if (0 == slot_remained_keys) {
LOG(INFO) << "PikaMigrateThread::ThreadMain slot_size:" << slot_size << " moved_num:" << moved_num_;
if (slot_size != moved_num_) {
LOG(ERROR) << "PikaMigrateThread::ThreadMain moved_num != slot_size !!!";
}
DestroyThread(true);
return nullptr;
}
}
return nullptr;
}2. codis
2.1 dashboard
dashboard是codis架构中的中心管理节点,负责proxy节点,pika节点的管理,发起运维操作,检测节点状态以及进行failover。dashboard持有集群整体的信息,需要持久化的数据保存在etcd或zookeeper或者本地磁盘文件中。
2.1.1 关键类
Topom是dashboard中的一个关键类,记录了dashboard中所有信息。定义如下:
type Topom struct {
mu sync.Mutex
xauth string
model *models.Topom
//抽象出来的存储组件,可以是zk/etcd/fs
store *models.Store
//缓存结构,减少从store获取次数,当成员变量值有变更时,
//会调用相关接口清除cache,下次获取数据时会强制从store中load
cache struct {
hooks list.List
slots []*models.SlotMapping
group map[int]*models.Group
proxy map[string]*models.Proxy
sentinel *models.Sentinel
}
exit struct {
C chan struct{}
}
config *Config
online bool
closed bool
ladmin net.Listener
//slot迁移时使用
action struct {
redisp *redis.Pool
interval atomic2.Int64
disabled atomic2.Bool
progress struct {
status atomic.Value
}
executor atomic2.Int64
}
stats struct {
redisp *redis.Pool
servers map[string]*RedisStats
proxies map[string]*ProxyStats
}
ha struct {
redisp *redis.Pool
monitor *redis.CodisSentinel
masters map[int]string
}
}
context看起来是Topom的一个只读快照。
type context struct {
slots []*models.SlotMapping
group map[int]*models.Group
proxy map[string]*models.Proxy
sentinel *models.Sentinel
hosts struct {
sync.Mutex
m map[string]net.IP
}
method int
}
const (
ActionNothing = ""
ActionPending = "pending"
ActionPreparing = "preparing"
ActionPrepared = "prepared"
ActionMigrating = "migrating"
ActionFinished = "finished"
ActionSyncing = "syncing"
)Action状态在三个地方会用到,第一个是仅用于实现promot server,即提升group server为master,此时更新的是group.Action.State。
第二个是用于实现slot的迁移,第三个是用来实现group内pika节点的主从sync。
2.1.2 主要函数
dashboard在启动之后,其主要工作通过6个goroutine来实现。分别是:
1. CheckMastersAndSlavesState。
2. CheckPreOffineMastersState。
3. RefreshRedisStats。
4. RefreshProxyStats。
5. ProcessSlotAction。
6. ProcessSyncAction。2.1.2.1 CheckMastersAndSlavesState
主要工作:周期性检测pika节点状态,并根据状态统计对需要下线节点进行摘除。
第一阶段是检测pika节点的状态。首先是获取所有group的server信息,之后对每个server执行info replication命令,获取每个group的master和slave关系。这一阶段在
CodisSentinel.RefreshMastersAndSlavesClient函数中完成。
第二阶段根据统计结果更新每个group中的pika节点的状态。即遍历每个server的stat统计信息,如果某个pika server的error状态不为nil,而且该节点是对应group的master节点,需要更新该节点的状态。具体地,如果该节点之前的状态是GroupServerStateNormal,先将该节点标记为
GroupServerStateSubjectiveOffline,即主观下线。如果之前不是normal状态,则累加ReCallTimes,如果ReCallTimes大于等于设定的主观下线阈值,将节点状态更新为GroupServerStateOffline,并将该group记录到pending数据中,后续将对pending中记录的group进行failover操作。(其实在CheckMasterAndSlavesState中并不会走到第二个节点,因为filter函数会过滤掉master状态不是normal的节点,所以stat信息中不会包含非normal状态的master节点,这部分逻辑将会在2.1.2.2函数中进行)。接下来对每个节点更新state信息和offset信息。具体代码如下所示:
// It was the master node before, the master node hangs up, and it is currently the master node
if state.Index == 0 && state.Err != nil && g.Servers[0].Addr == state.Addr {
if g.Servers[0].State == models.GroupServerStateNormal {
//主观下线
g.Servers[0].State = models.GroupServerStateSubjectiveOffline
} else {
// update retries
g.Servers[0].ReCallTimes++
// Retry more than config times, start election
if g.Servers[0].ReCallTimes >= s.Config().SentinelMasterDeadCheckTimes {
// Mark enters objective offline state
g.Servers[0].State = models.GroupServerStateOffline
g.Servers[0].ReplicaGroup = false
}
// Start the election master node
if g.Servers[0].State == models.GroupServerStateOffline {
pending = append(pending, g)
}
}
}
// Update the offset information of the state and role nodes
if val, ok := serversMap[state.Addr]; ok {
if state.Err != nil {
if val.State == models.GroupServerStateNormal {
val.State = models.GroupServerStateSubjectiveOffline
}
continue
}
val.State = models.GroupServerStateNormal
val.ReCallTimes = 0
val.Role = state.Replication.Role
if val.Role == "master" {
val.ReplyOffset = state.Replication.MasterReplOffset
} else {
val.ReplyOffset = state.Replication.SlaveReplOffset
}
}第三阶段进行failover。第二阶段中记录到pending中的group需要进行主从切换。首先从对应group中选新的master,挑选的原则是状态是normal且并且replyoffset最大。接下来对新master执行slaveof no one,对其他节点重新执行slaveof命令绑定到新master上。更新group统计信息,交换新老master在group.servers的位置,删除对应group的cache信息,标记group为OutOfSync = true,更新store中信息。
2.1.2.2 CheckPreOffineMastersState
整体执行逻辑类似于CheckMasterAndSlaveState,不同的是filter函数。2.1.2.1中检测状态时会忽略掉状态不是normal的master节点,当前函数逻辑互补,即只检测不是正常状态的master节点。猜测区分成两个函数处理的逻辑是为了使用不同的检测频率。
2.1.2.3 RefreshRedisStats
遍历所有的group以及每个group的server,向每个pika节点发info请求,获取统计信息。然后发送命令“config get maxmemory”,统计maxmemory。目前返回的是max-write-buffer-size,后期可以优化下。所有server的统计信息统计在map[string]*RedisStats,赋值给s.stats.severs。
2.1.2.4 RefreshProxyStats
类似于获取redis server节点的统计信息,同理,向所有的proxy发请求,获取统计信息,记录到Topom.stats.proxies中。初次之外,会扫一遍topom中记录的所有proxy,如果proxy的状态不是online,执行OnlineProxy对proxy进行上线操作。
2.1.2.5 ProcessSlotAction
功能:执行slots迁移相关的工作。具体执行流程类似于ProcessSyncAction。
第一步找到所有状态不是Nothing的slot,说明这些slots需要执行迁移动作,或者已经在执行迁移动作过程中。找到足够的slots之后,更新状态到Migrating,根据dashboard中设置的迁移函数,开始进行迁移。每迁移完成一个slots,执行一次resyncmappings操作,将slots新状态同步到proxy节点。在slot迁移完成之前,proxy收到业务的请求,需要先将对应的key迁移到destination,然后在执行读写操作。
2.1.2.6 ProcessSyncAction
功能:遍历所有的group和所有的节点,如果有group的Action成员变量不为空,找到Action.Index最小的,对其执行slaveof。主要函数分为
SyncActionPrepare,
newSyncActionExecutor,
SyncActionComplete。
SyncActionPrepare第一步遍历所有的group中的所有server,如果server.Action.State == models.ActionPending,并且server.Action.Index最小,记录对应的server addr。然后根据server addr找到所属的group,更新group.server.Action.Index为0,Action.State为ActionSyncing。
newSyncActionExecutor(addr)找出对应group的master,返回的lambda处理逻辑是如果master为NO:ONE,执行slaveof no one。如果不是,对addr节点执行slaveof master
SyncActionComplete扫尾函数,更新cache,下发mappings到proxy节点。
2.1.2.7 resyncSlotMappings
函数签名:
func (s *Topom) resyncSlotMappings(ctx *context, slots ...*models.SlotMapping) error作用是将传入的models.SlotMapping中的slot转换成models.Slot,并下发给所有的proxy节点。
models.Slot定义:
type Slot struct {
Id int `json:"id"`
Locked bool `json:"locked,omitempty"`
BackendAddr string `json:"backend_addr,omitempty"`
BackendAddrGroupId int `json:"backend_addr_group_id,omitempty"`
//处于迁移状态的slot会设置这两个值.
//在proxy节点,如果客户端请求的key分配到了当前slot且这两个参数不为空,proxy需要先迁移对应的key到target节点(slotmgrtone)
MigrateFrom string `json:"migrate_from,omitempty"`
MigrateFromGroupId int `json:"migrate_from_group_id,omitempty"`
//proxy需要同步迁移一个key时使用的方法
ForwardMethod int `json:"forward_method,omitempty"`
//复制组,dc就近读
ReplicaGroups [][]string `json:"replica_groups,omitempty"`
}主要包括了两个函数,context.toSlot()和FilSlots()
context完成models.Mapping到models.Slot的转换,转换过程中相关key的赋值情况:
Locked: 如果slot的状态是prepared,返回true。如果不是preapred状态,检查group lock状态。
BackendAddr:
BackendAddrGroupId
MigrateFrom
MigrateFromGroupId2.1.3 主要流程
slot rebalance
slot rebalance形参中有一个confirm参数,如果为false,表明只是生成一个slot rebalance的迁移计划,并不会真正执行,如果为true,表明生成了迁移计划之后就更新对应slot的状态。
关键的几个变量:
- assigned : map[int]int //key: groupId, value: 不需要迁移的slots个数
- pendings : map[int][]int //key: groupId, value: 等待迁出的待分配的slots个数,即pendings中记录的[]slot记录的slot当前属于key对应的groupId,可以迁出,但还没有找到目的端。
- moveout:map[int]int //key: groupId, value: 对应groupId中,要迁出的slots的数量。如果为正值,说明对应的groupId需要往外迁移,如果为负值,说明需要其他的group向它迁移数据。
- docking: 需要进行迁移的slots,其中包括了offline slots,还有需要进行迁移的slots
slot_rebalance整体的执行逻辑包括:
1. topom加锁,生成一个新的context。
2. 遍历ctx.slots,如果某个slot的Action.State不为“”,说明该slot属于已经迁移的slot,那么对应的嵌入端的group的assigned值++。
3. 遍历ctx.slots,如果某个slot的Action.State为"",并且groupId不为0, 如果该group的slot个数小于平均值,那么该group的assigned值++。否则,该group就需要迁出一些slots,所以pendings中记录该group和slotid
4. 构造一棵红黑树,排序依据是groupsize,将所有的groupId存到rbtree中。作用是尽量slots分片尽量均匀地分配给所有的slots,所以需要按照节点持有的分片数进行排序。
5. 遍历所有的slots,如果某个slot的groupId为0,即为offline slot(最开始,集群中的slots没有分配给任何节点,就是offline slot),则groupsize最小的group的moveout值--。(通过rbtree找到最小size的group,moveout值负数,表示需要迁入slot)。
6. 从rbtree中找到groupsize最大的group,再找到groupsize最小的group,如果他们size相差大于1,那么最大size的group的moveout++,最小的moveout--。(其实就是在做slots均衡,削峰填谷)
7. 根据第8步中已经计算出的moveout值,遍历moveout,如果值大于0,表明需要迁出,那么从pending中截取指定长度的slots,追加到docking中。
8. 遍历groupids和docking,将docking中记录的slots的目的端记录为需要迁入的group,生成了一个迁移plan,key位slotid,value为targetGroupId。
9. 如果confirm为true,更新slot的Action.State为ActionPending,Action.Index为一个单调递增的counter值,targeId为plans中记录的groupId。执行storeUpdateSlotMapping,更新store,清除cache。processslotaction函数会执行从plan中恢复中所有需要执行迁移的slots。
2.1.4 主要接口
类定义
type Group struct {
Id int json:"id"
Servers []*GroupServer json:"servers"
Promoting struct {
Index int json:"index,omitempty"
State string json:"state,omitempty"
} json:"promoting"
OutOfSync bool json:"out_of_sync"
}相关api
创建group
"/api/topom/group/create/{xauth}/{gid}"
topom_group.go
执行完成之后,如果store选择的是文件系统,会在prodct_name目录下创建一个group目录,group目录中新建“group-{gid}”,目录中初始内容:
{
"id": 1,
"servers": [],
"promoting": {},
"out_of_sync": false
}添加server
"/api/topom/group/add/{xauth}/{gid}/{addr}/{dc}"
topom_group.go:GroupAddServer
newcontext -> getGroup() -> group g如果group的Promoting.state不是ActionNothing, 返回error
如果ctx.sentinel.servers不为空,标记sentinel.OutOfSync为true,执行storeUpdateSentinel
将新server追加到group的server中,保存到store.group-{gid}文件内容变为:
{
"id": 1,
"servers": [
{
"server": "10.224.129.40:9271",
"datacenter": "",
"action": {},
"role": "",
"reply_offset": 0,
"state": 0,
"recall_times": 0,
"replica_group": false
}
],
"promoting": {},
"out_of_sync": false
}主从同步
"/api/topom/group/action/create/{token}/10.224.129.40:9261"
首先是状态判断,如果group.Promoting.State不是nothing,返回error。如果对应server的Action.State == models.ActionPending,返回error,表明该server已经有action存在。
设置server.Action.Index,设置Action.State ==models.ActionPending
实际执行主从同步的步骤,是通过dashboard的后台goroutine执行ProcessSyncAction完成。
{
"id": 1,
"servers": [
{
"server": "10.224.129.40:9271",
"datacenter": "",
"action": {},
"role": "master",
"reply_offset": 0,
"state": 0,
"recall_times": 0,
"replica_group": false
},
{
"server": "10.224.129.40:9261",
"datacenter": "",
"action": {
"state": "synced"
},
"role": "master",
"reply_offset": 0,
"state": 0,
"recall_times": 0,
"replica_group": false
}
],
"promoting": {},
"out_of_sync": false
}rebalance
"/api/topom/slots/rebalance/95b62887719520f17e312eaa76d28f2b/0"
topom_api.go:SlotsRebalance
topom_slots.go:SlotRebalance
同步完成plan的更新,将plan中的每个slot保存到store中,状态为pending。
接下来processSlotAction协程每秒被调度执行一次,首先遍历所有的slots,找到Action.State不是nothing状态的slot,更新状态从ActionPending -> ActionPreparing -> ActionPrepared -> ActionMigrating。每次更新时需要同步更新store,以及使cache失效。之后开始执行迁移操作,根据config中的配置,选择执行SLOTSMGRTTAGSLOT或者是SLOTSMGRTTAGSLOT_ASYNC. slotsmigrtagslot命令会返回对应slotkey中还剩余的key个数。dashboard收到之后就可以判断是否这个codis已经迁移完成,如果已经迁移完成,执行slotActionComplete,更新slotAction的状态以及resyncSlotMapings通知proxy。
如果没有全部迁移完,sleep指定的slot_action_interval之后重视。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)