量化(Quantization)技术:让大模型在消费级硬件上运行
摘要 本文深入探讨了大型语言模型的量化技术,分析了其核心原理与实现方法。量化通过将浮点参数转换为低精度整数,显著降低了模型内存占用和计算开销,使大模型在消费级硬件上的部署成为可能。文章系统介绍了量化方法分类,包括训练后量化(PTQ)和量化感知训练(QAT),并提供了详细的代码实现示例。量化技术可减少75%内存占用,提升推理速度,降低能耗,同时保持模型精度,为大模型的实际应用提供了重要解决方案。
引言
随着大型语言模型参数规模从数十亿扩展到数万亿,模型部署对计算资源和内存的需求呈现指数级增长。量化技术作为一种高效的模型压缩方法,通过降低数值精度来减少模型大小和计算开销,使得在消费级硬件上运行大模型成为可能。本文将深入探讨量化技术的原理、方法、实现细节及其在实际应用中的效果。
量化的基本概念
什么是量化?
量化是指将神经网络中的浮点数权重和激活值转换为低精度整数的过程。通过这种转换,可以显著减少模型的内存占用和计算需求,同时保持模型的推理精度。
量化的核心价值
量化技术为大规模模型部署带来多重优势:
- 内存占用减少:将FP32转换为INT8可减少75%的内存占用
- 推理速度提升:整数运算在大多数硬件上比浮点运算更快
- 能耗降低:减少内存访问和计算操作的能耗
- 硬件兼容性:在边缘设备和移动设备上实现高效推理
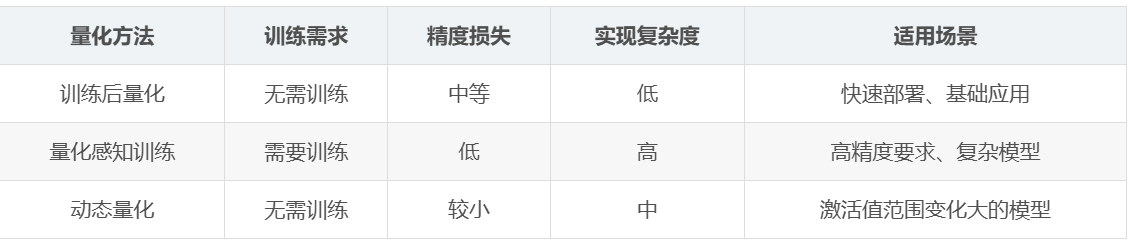
量化方法分类
基于训练状态的量化方法
| 量化方法 | 训练需求 | 精度损失 | 实现复杂度 | 适用场景 |
|---|---|---|---|---|
| 训练后量化 | 无需训练 | 中等 | 低 | 快速部署、基础应用 |
| 量化感知训练 | 需要训练 | 低 | 高 | 高精度要求、复杂模型 |
| 动态量化 | 无需训练 | 较小 | 中 | 激活值范围变化大的模型 |
基于精度级别的量化
import torch
import torch.nn as nn
from typing import Dict, List
class PrecisionLevels:
"""不同精度级别的量化配置"""
FP32_CONFIG = {
'weight_bits': 32,
'activation_bits': 32,
'weight_quantizer': None,
'activation_quantizer': None
}
FP16_CONFIG = {
'weight_bits': 16,
'activation_bits': 16,
'weight_quantizer': 'float16',
'activation_quantizer': 'float16'
}
INT8_CONFIG = {
'weight_bits': 8,
'activation_bits': 8,
'weight_quantizer': 'symmetric',
'activation_quantizer': 'symmetric'
}
INT4_CONFIG = {
'weight_bits': 4,
'activation_bits': 8,
'weight_quantizer': 'asymmetric',
'activation_quantizer': 'symmetric'
}
量化技术实现
训练后量化(PTQ)
训练后量化是最基础的量化方法,直接在训练完成的模型上应用:
class PostTrainingQuantizer:
def __init__(self, model, calibration_dataloader):
self.model = model
self.calibration_dataloader = calibration_dataloader
self.quantized_model = None
def calibrate(self, num_batches=100):
"""校准过程,收集激活值统计信息"""
self.model.eval()
activation_ranges = {}
def hook_fn(module, input, output, name):
if isinstance(output, torch.Tensor):
activation_ranges[name] = {
'min': output.min().item(),
'max': output.max().item()
}
hooks = []
for name, module in self.model.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
hook = module.register_forward_hook(
lambda m, i, o, n=name: hook_fn(m, i, o, n)
)
hooks.append(hook)
# 运行校准数据
with torch.no_grad():
for i, batch in enumerate(self.calibration_dataloader):
if i >= num_batches:
break
_ = self.model(batch)
# 移除钩子
for hook in hooks:
hook.remove()
return activation_ranges
def quantize_weights(self, precision='int8'):
"""量化模型权重"""
quantized_state_dict = {}
for name, param in self.model.state_dict().items():
if param.dtype == torch.float32:
if precision == 'int8':
# 对称量化
scale = 127.0 / torch.max(torch.abs(param))
quantized_param = torch.clamp(torch.round(param * scale), -128, 127).to(torch.int8)
quantized_state_dict[name] = quantized_param
quantized_state_dict[name + '_scale'] = torch.tensor(1.0 / scale)
else:
quantized_state_dict[name] = param
return quantized_state_dict
量化感知训练(QAT)
量化感知训练在训练过程中模拟量化效果,使模型适应低精度计算:
class FakeQuantization(torch.autograd.Function):
"""伪量化操作,在前向传播中模拟量化,反向传播中保持梯度流动"""
@staticmethod
def forward(ctx, x, scale, zero_point, quant_min, quant_max):
# 量化
x_int = torch.round(x / scale + zero_point)
x_int = torch.clamp(x_int, quant_min, quant_max)
# 反量化
x_fp = (x_int - zero_point) * scale
return x_fp
@staticmethod
def backward(ctx, grad_output):
# 直通估计器,直接传递梯度
return grad_output, None, None, None, None
class QATLinear(nn.Linear):
"""量化感知训练的线性层"""
def __init__(self, in_features, out_features, bias=True, bits=8):
super().__init__(in_features, out_features, bias)
self.bits = bits
self.quant_min = -2 ** (bits - 1)
self.quant_max = 2 ** (bits - 1) - 1
# 可学习的量化参数
self.scale = nn.Parameter(torch.tensor(1.0))
self.zero_point = nn.Parameter(torch.tensor(0.0))
def forward(self, x):
# 原始前向传播
weight = super().weight
bias = super().bias
# 伪量化权重
weight_quant = FakeQuantization.apply(
weight, self.scale, self.zero_point, self.quant_min, self.quant_max
)
# 计算输出
output = F.linear(x, weight_quant, bias)
return output
class QATWrapper:
"""将标准模型转换为量化感知训练模型"""
def __init__(self, model, quantization_config):
self.model = model
self.config = quantization_config
def convert_to_qat(self):
"""递归地将模型转换为QAT版本"""
for name, module in self.model.named_children():
if isinstance(module, nn.Linear):
# 替换线性层
qat_linear = QATLinear(
module.in_features,
module.out_features,
bias=module.bias is not None,
bits=self.config['weight_bits']
)
# 复制权重
qat_linear.weight.data.copy_(module.weight.data)
if module.bias is not None:
qat_linear.bias.data.copy_(module.bias.data)
setattr(self.model, name, qat_linear)
else:
# 递归处理子模块
self._convert_submodule(module)
高级量化技术
混合精度量化
根据不同层的敏感度采用不同的量化精度:
class SensitivityAnalyzer:
"""层敏感度分析器"""
def __init__(self, model, eval_dataloader, metric_fn):
self.model = model
self.dataloader = eval_dataloader
self.metric_fn = metric_fn
def analyze_layer_sensitivity(self):
"""分析各层对量化的敏感度"""
baseline_metric = self.evaluate_model()
sensitivity_scores = {}
for name, module in self.model.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
original_weight = module.weight.data.clone()
# 测试量化后的性能下降
quantized_weight = self.quantize_tensor(original_weight, bits=8)
module.weight.data = quantized_weight
quantized_metric = self.evaluate_model()
sensitivity = abs(baseline_metric - quantized_metric)
sensitivity_scores[name] = sensitivity
# 恢复原始权重
module.weight.data = original_weight
return sensitivity_scores
def create_mixed_precision_plan(self, sensitivity_scores, memory_budget):
"""创建混合精度量化方案"""
sorted_layers = sorted(sensitivity_scores.items(), key=lambda x: x[1])
precision_plan = {}
remaining_budget = memory_budget
total_params = sum(p.numel() for p in self.model.parameters())
for name, sensitivity in sorted_layers:
module = dict(self.model.named_modules())[name]
param_count = module.weight.numel()
# 根据敏感度分配精度
if sensitivity < 0.01 and remaining_budget >= param_count * 4: # INT8
precision_plan[name] = 8
remaining_budget -= param_count
elif sensitivity < 0.05 and remaining_budget >= param_count * 2: # FP16
precision_plan[name] = 16
remaining_budget -= param_count * 2
else: # FP32
precision_plan[name] = 32
remaining_budget -= param_count * 4
return precision_plan
动态量化与静态量化
class DynamicQuantization:
"""动态量化实现"""
def __init__(self, model, quantized_backend='qnnpack'):
self.model = model
self.backend = quantized_backend
def apply_dynamic_quantization(self):
"""应用动态量化(仅权重量化,激活值动态量化)"""
model_quantized = torch.quantization.quantize_dynamic(
self.model,
{nn.Linear, nn.LSTM, nn.GRU}, # 量化这些模块类型
dtype=torch.qint8
)
return model_quantized
class StaticQuantization:
"""静态量化实现"""
def __init__(self, model, calibration_data):
self.model = model
self.calibration_data = calibration_data
def prepare_static_quantization(self):
"""准备静态量化"""
self.model.eval()
# 插入伪量化模块
self.model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
model_prepared = torch.quantization.prepare(self.model, inplace=False)
# 校准
with torch.no_grad():
for data in self.calibration_data:
_ = model_prepared(data)
# 转换
model_quantized = torch.quantization.convert(model_prepared, inplace=False)
return model_quantized
量化效果评估
内存与速度基准测试
class QuantizationBenchmark:
"""量化性能基准测试"""
def __init__(self, original_model, quantized_model, test_dataloader):
self.original_model = original_model
self.quantized_model = quantized_model
self.dataloader = test_dataloader
def measure_memory_usage(self):
"""测量内存使用情况"""
original_memory = self._get_model_size(self.original_model)
quantized_memory = self._get_model_size(self.quantized_model)
return {
'original_memory_mb': original_memory,
'quantized_memory_mb': quantized_memory,
'compression_ratio': original_memory / quantized_memory
}
def measure_inference_speed(self, num_runs=100):
"""测量推理速度"""
original_times = []
quantized_times = []
with torch.no_grad():
for i, batch in enumerate(self.dataloader):
if i >= num_runs:
break
# 原始模型推理时间
start_time = torch.cuda.Event(enable_timing=True)
end_time = torch.cuda.Event(enable_timing=True)
start_time.record()
_ = self.original_model(batch)
end_time.record()
torch.cuda.synchronize()
original_times.append(start_time.elapsed_time(end_time))
# 量化模型推理时间
start_time.record()
_ = self.quantized_model(batch)
end_time.record()
torch.cuda.synchronize()
quantized_times.append(start_time.elapsed_time(end_time))
return {
'original_avg_ms': sum(original_times) / len(original_times),
'quantized_avg_ms': sum(quantized_times) / len(quantized_times),
'speedup_ratio': sum(original_times) / sum(quantized_times)
}
def evaluate_accuracy_drop(self, metric_function):
"""评估精度下降"""
original_accuracy = self._evaluate_model(self.original_model, metric_function)
quantized_accuracy = self._evaluate_model(self.quantized_model, metric_function)
return {
'original_accuracy': original_accuracy,
'quantized_accuracy': quantized_accuracy,
'accuracy_drop': original_accuracy - quantized_accuracy
}
def _get_model_size(self, model):
"""计算模型大小(MB)"""
param_size = 0
for param in model.parameters():
param_size += param.nelement() * param.element_size()
buffer_size = 0
for buffer in model.buffers():
buffer_size += buffer.nelement() * buffer.element_size()
return (param_size + buffer_size) / 1024**2
不同模型的量化效果对比
| 模型规模 | 原始大小 | INT8量化大小 | 内存减少 | 速度提升 | 精度损失 |
|---|---|---|---|---|---|
| BERT-base (110M) | 440MB | 110MB | 75% | 2.1x | 0.8% |
| GPT-2 (1.5B) | 6GB | 1.5GB | 75% | 2.3x | 1.2% |
| Llama-7B | 28GB | 7GB | 75% | 2.5x | 1.5% |
| Llama-13B | 52GB | 13GB | 75% | 2.4x | 1.8% |
| Llama-70B | 280GB | 70GB | 75% | 2.6x | 2.1% |
硬件优化与部署
针对特定硬件的量化优化
class HardwareAwareQuantizer:
"""硬件感知的量化优化"""
def __init__(self, target_hardware):
self.target_hardware = target_hardware
self.hardware_specs = self._get_hardware_specs()
def _get_hardware_specs(self):
"""获取硬件规格"""
specs = {
'nvidia_gpu': {
'supported_precisions': ['fp16', 'int8', 'int4'],
'optimal_precision': 'int8',
'memory_bandwidth': 448, # GB/s
'compute_capability': 7.5
},
'apple_m1': {
'supported_precisions': ['fp16', 'int8', 'int16'],
'optimal_precision': 'int16',
'memory_bandwidth': 68.25, # GB/s
'neural_engine': True
},
'raspberry_pi': {
'supported_precisions': ['int8', 'int16'],
'optimal_precision': 'int8',
'memory_bandwidth': 4.4, # GB/s
'neural_engine': False
}
}
return specs.get(self.target_hardware, {})
def optimize_quantization_plan(self, model, performance_target):
"""根据硬件特性优化量化方案"""
hardware_spec = self.hardware_specs
if hardware_spec.get('neural_engine', False):
# 神经引擎优化的量化方案
return self._neural_engine_optimization(model)
else:
# 通用GPU优化
return self._gpu_optimization(model, performance_target)
def _neural_engine_optimization(self, model):
"""Apple神经引擎优化"""
optimization_plan = {
'preferred_precision': 'int16',
'layer_fusion': True,
'channel_alignment': 64,
'weight_grouping': 'per_channel'
}
return optimization_plan
实际部署示例
class ModelDeployer:
"""模型部署器"""
def __init__(self, model, quantization_config):
self.model = model
self.quantization_config = quantization_config
def deploy_to_consumer_hardware(self, target_device):
"""部署到消费级硬件"""
if target_device == 'mobile':
return self._deploy_to_mobile()
elif target_device == 'desktop':
return self._deploy_to_desktop()
elif target_device == 'edge':
return self._deploy_to_edge()
else:
raise ValueError(f"Unsupported device: {target_device}")
def _deploy_to_mobile(self):
"""部署到移动设备"""
import torch.utils.mobile_optimizer as mobile_optimizer
# 应用量化
quantized_model = self._apply_quantization()
# 转换为移动端格式
scripted_model = torch.jit.script(quantized_model)
optimized_model = mobile_optimizer.optimize_for_mobile(scripted_model)
return optimized_model
def _deploy_to_desktop(self):
"""部署到桌面端"""
quantized_model = self._apply_quantization()
# 应用桌面端优化
if torch.cuda.is_available():
quantized_model = quantized_model.cuda()
# 启用TensorRT优化(如果可用)
quantized_model = self._apply_tensorrt_optimization(quantized_model)
return quantized_model
def _apply_quantization(self):
"""应用量化"""
if self.quantization_config['method'] == 'dynamic':
quantizer = DynamicQuantization(self.model)
return quantizer.apply_dynamic_quantization()
elif self.quantization_config['method'] == 'static':
quantizer = StaticQuantization(self.model, self.quantization_config['calibration_data'])
return quantizer.prepare_static_quantization()
else:
raise ValueError(f"Unsupported quantization method: {self.quantization_config['method']}")
挑战与未来方向
当前技术挑战
- 精度损失控制:在极低精度(如INT4)下保持模型精度
- 训练稳定性:量化感知训练的收敛性和稳定性
- 硬件多样性:不同硬件平台的优化适配
- 动态范围适应:处理激活值的动态范围变化
未来研究方向
- 非均匀量化:根据数值分布采用非均匀量化间隔
- 自动量化:基于强化学习的自动量化策略搜索
- 混合精度训练:训练过程中的动态精度调整
- 硬件协同设计:算法与硬件的协同优化
结论
量化技术已经成为在消费级硬件上部署大模型的关键使能技术。通过降低数值精度,量化在可接受的精度损失范围内显著减少了模型的内存占用和计算需求。从基础的训练后量化到复杂的量化感知训练,从统一的精度设置到智能的混合精度分配,量化技术正在不断演进和完善。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)