吃透Python爬虫:巧用工具让效率飞起来,附网易云案例实操
新手通过视频学习Python爬虫常踩的三大坑:知识点零散、实操门槛高和学完无反馈。介绍了AI视频学习工具如何将45分钟视频内容自动整理为"环境准备-核心流程-反爬技巧-拓展应用&四大模块的思维导图,并实现知识点与视频时间戳精准关联。工具还提供AI智能出题、在线沙盒环境等功能,通过思维导图+实时练习+环境预装的闭环学习模式,帮助学习者快速掌握网易云音乐爬虫案例的核心技能,使学习效率提升5倍
一、纯看视频学爬虫,新手必踩的3个“坑”
网易云单首歌曲爬虫作为Python入门经典案例,涵盖了网络请求、数据解析、反爬基础等核心知识点,但纯靠视频学习,这些干货反而成了“拦路虎”:
- 知识点零散无体系:视频中老师边操作边讲解,从“pip install requests”的环境准备,跳到“构造headers绕过反爬”,再到“用JSON提取歌曲信息”,40分钟的内容没有清晰逻辑线,新手记完笔记却分不清“请求-解析-存储”的核心流程,更别提串联起“库调用-反爬策略-数据处理”的知识链。
- 实操门槛高到劝退:视频里的代码一闪而过,新手模仿时常漏写关键参数;本地配置环境时,要么遭遇“fake-useragent库安装失败”,要么因Python版本问题导致代码报错,等解决完环境问题,学习热情早已消磨殆尽。
- 学完就忘无反馈:视频结束后想检验学习成果,却不知道自己是否掌握“请求异常处理”“数据去重”等核心点;遇到“API接口失效”的突发情况,更是无从下手,只能再花半小时拖进度条找解决方案。
二、AI识别视频内容,知识点“秒变”逻辑链
AI视频学习助理能过滤视频中的冗余操作演示,提取核心知识点并按“学习逻辑”生成思维导图,将“网易云爬虫案例”拆解为“环境准备-核心流程-反爬技巧-拓展应用”四大模块,每个节点都关联视频时间戳,不用记笔记就能理清知识脉络。
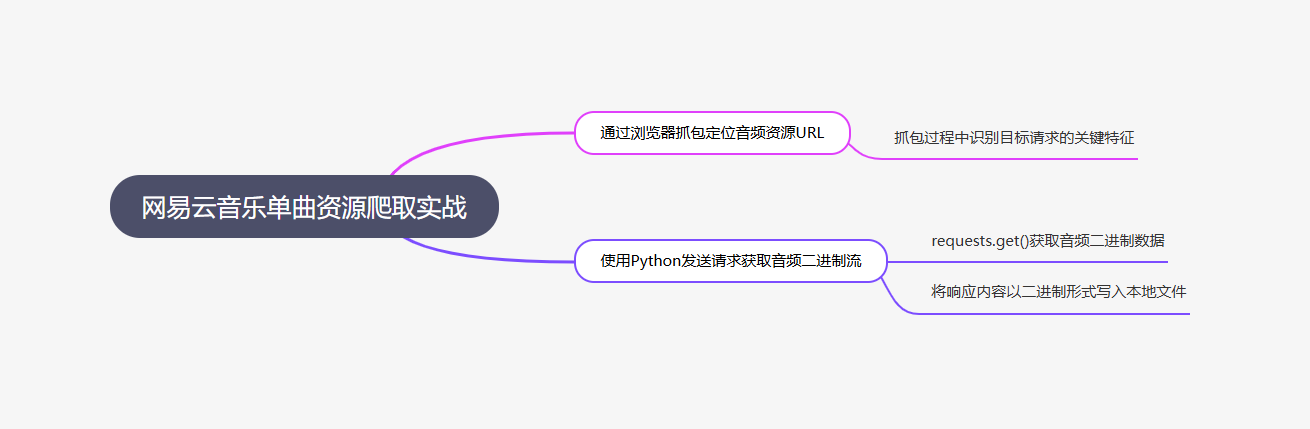
网易云单首歌曲爬虫知识点思维导图(工具自动生成)
## 网易云单首歌曲爬虫核心(视频45:10-58:30)
### 1. 环境准备(45:10-47:20)
- 必备库:requests(发送网络请求)、json(解析数据)、fake-useragent(生成随机请求头)
- 安装命令:pip install requests fake-useragent
- 版本兼容:Python 3.8+避免库冲突
### 2. 爬虫核心流程(47:21-53:40)
- 步骤1:分析接口——F12抓包获取歌曲信息API(例:https://music.163.com/api/song/detail)
- 步骤2:构造请求——添加headers模拟浏览器访问(User-Agent必带)
- 步骤3:发送请求——requests.get()方法,设置timeout防卡死
- 步骤4:解析数据——response.json()提取歌曲名、歌手、时长等字段
- 步骤5:数据存储——字典转CSV或TXT文件
### 3. 反爬基础技巧(53:41-56:10)
- 随机User-Agent:避免单一标识被封IP
- 请求间隔:time.sleep(1-3)降低访问频率
- 异常处理:try-except捕获请求失败问题
### 4. 问题排查(56:11-58:30)
- 接口403:检查headers是否完整
- 数据为空:确认API参数中songId是否正确
- 编码乱码:response.encoding = 'utf-8'设置编码之前我花20分钟记的混乱笔记,工具10秒就整理成逻辑清晰的框架。点击“请求构造”节点,还能直接跳转到视频48:15的实操演示片段,不用再拖进度条大海捞针,复习效率直接提升5倍。
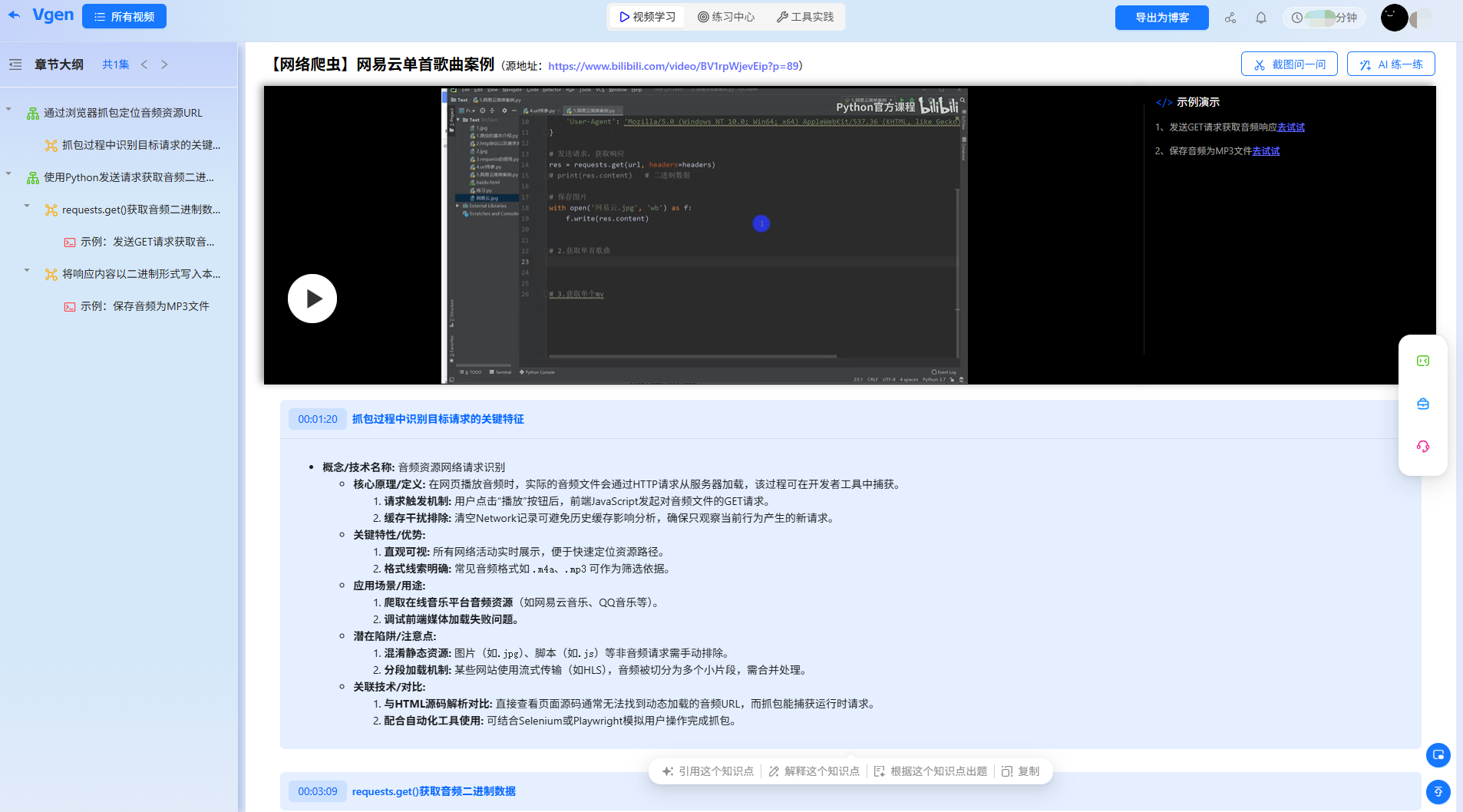
三、AI智能出题,边学边测筑牢核心考点
爬虫学习的核心是“练”而非“看”,工具的AI出题功能完全贴合视频知识点,从基础概念到实操纠错层层递进,像专属老师随时抽考,帮我把“薄弱点”变成“得分点”。
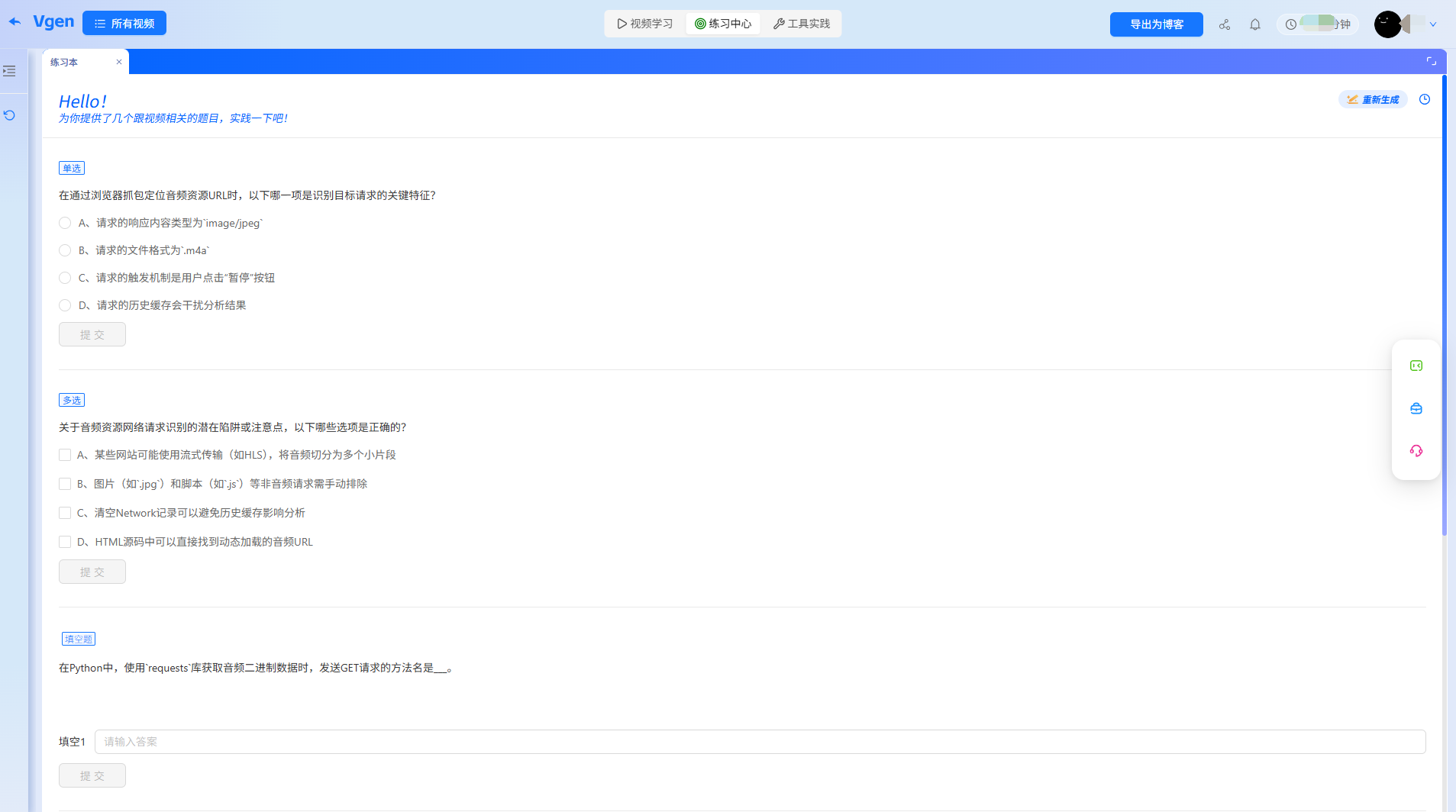
针对性考题(工具基于视频内容生成)
- 基础题(对应视频48:30):以下构造请求头的代码正确的是?(答案:B) A. headers = {'user-agent': 'Chrome/118.0.0.0'}
- B. from fake_useragent import UserAgent; headers = {'User-Agent': UserAgent().random}
- C. headers = {User-Agent: 'Mozilla/5.0'}
- 实操改错题(对应视频51:20):以下代码尝试获取歌曲信息,却返回空数据,请指出错误:
import requestsurl = "https://music.163.com/api/song/detail"params = {"ids": "123456"} # 假设歌曲ID为123456response = requests.get(url, params=params)data = response.json()print(data["song"]["name"])工具提示:错误1:缺少请求头,被网易云服务器识别为爬虫拒绝返回数据,需添加headers;错误2:JSON数据结构错误,歌曲信息存储在"data"→"songs"列表中,应改为data["data"]["songs"][0]["name"](关联视频50:40-51:10)。 - 拓展题(对应视频57:30):基于视频案例,编写代码实现“输入歌曲ID,保存歌曲名、歌手到CSV文件”,并添加请求超时处理。
每道题都标注对应视频片段,错题会自动存入“爬虫错题本”,我通过集中练习,很快就掌握了“请求头构造”“JSON解析”等易混点,比单纯回看视频高效太多。
四、在线沙盒环境,学完即练零门槛
爬虫学习的核心是“动手实操”,但本地环境配置往往让新手望而却步。工具自带的Python在线沙盒环境,预装了requests、fake-useragent等视频中所有必备库,不用手动安装,复制代码就能运行,还支持实时修改和报错提示,让我专注于“代码逻辑”而非“环境调试”。
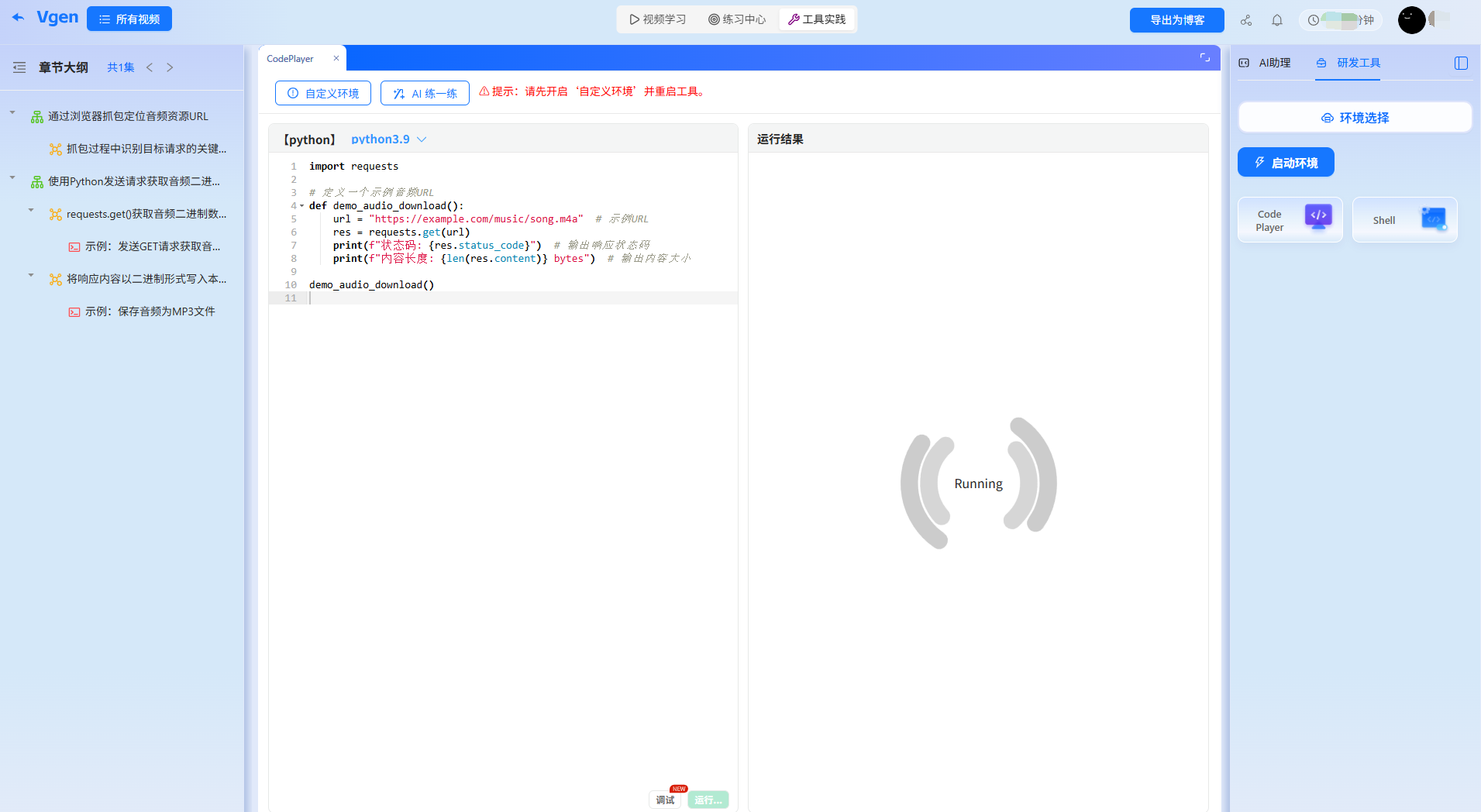
沙盒环境实操案例(视频核心代码优化版)
import requests
import json
import csv
from fake_useragent import UserAgent
import time
def get_song_info(song_id):
# 1. 构造请求(视频48:20核心知识点)
url = "https://music.163.com/api/song/detail"
headers = {
"User-Agent": UserAgent().random,
"Referer": "https://music.163.com/" # 补充视频未提的反爬细节
}
params = {"ids": song_id}
try:
# 2. 发送请求并处理异常(视频55:40知识点)
response = requests.get(
url,
headers=headers,
params=params,
timeout=10 # 防止程序卡死
)
response.raise_for_status() # 检测请求是否成功
response.encoding = "utf-8"
# 3. 解析数据(视频50:10核心逻辑)
data = response.json()
song = data["data"]["songs"][0]
song_info = {
"歌曲ID": song_id,
"歌曲名": song["name"],
"歌手": song["ar"][0]["name"],
"时长(秒)": song["dt"] // 1000
}
return song_info
except requests.exceptions.RequestException as e:
print(f"请求失败:{e}")
return None
# 4. 数据存储(视频56:20拓展)
def save_to_csv(song_info, filename="网易云歌曲信息.csv"):
if not song_info:
return
# 检查文件是否存在,不存在则写入表头
with open(filename, "a", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=song_info.keys())
# 获取文件当前位置,为0说明是新文件
if f.tell() == 0:
writer.writeheader()
writer.writerow(song_info)
# 主程序
if __name__ == "__main__":
song_id = input("请输入网易云歌曲ID:")
info = get_song_info(song_id)
if info:
save_to_csv(info)
print(f"成功保存:{info['歌曲名']} - {info['歌手']}")
time.sleep(2) # 遵守爬虫礼仪,设置请求间隔沙盒环境优势体现
- 零配置启动:无需本地装Python和库,打开工具直接运行代码,解决新手“环境配置半小时,写代码5分钟”的困境。
- 实时反馈纠错:若漏写“import csv”,沙盒会立即标红提示“模块未导入”,并关联视频56:00的“数据存储”知识点。
- 互动性强:支持手动输入歌曲ID测试,运行结果实时显示,我通过修改song_id参数,成功爬取了3首不同歌曲的信息,成就感直接拉满。
五、总结:Python爬虫入门,工具比“刷遍视频”更重要
回头看网易云爬虫案例的学习过程,我深刻体会到:748集的海量视频只是“资源库”,而视频解析工具才是“导航仪”。纯看视频时,我花一下午都在“记笔记-调环境-找错误”中循环,却没吃透核心逻辑;用工具后,1小时就完成了“思维导图理框架-AI出题补漏洞-沙盒实操练代码”的闭环学习,不仅掌握了视频里的知识点,还能独立添加“CSV存储”“异常处理”等拓展功能。
对于Python零基础学习者来说,像网易云爬虫这样的实操案例是入门关键,好的工具能少走99%的弯路,借助AI工具把复杂的爬虫知识变得清晰易懂,让学习效率翻倍的同时,还能培养“边学边练”的编程思维——这才是Python从新手到大神的正确打开方式。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)