11.18 脚本 termux自动化合并txt等文件
功能,自动化合并文件,当然执行这个文件也被自动化。
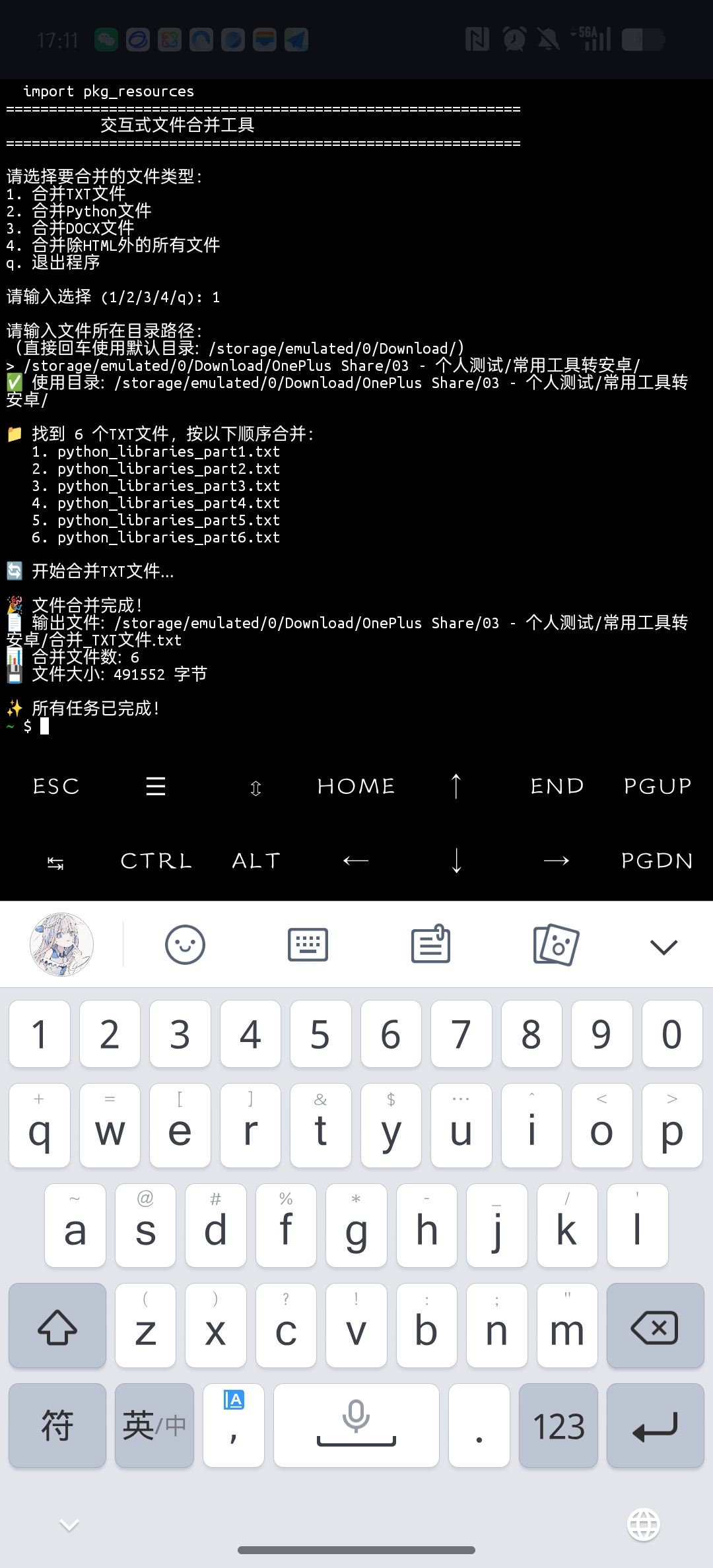
先py,再直接文件路径

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
文件名: interactive_file_merger.py
作者: 脚本助手
功能: 交互式文件合并工具
创建时间: 2025年11月
描述: 支持合并TXT、Python、DOCX文件,以及除HTML外的所有文件
"""
import os
import re
import sys
from pathlib import Path
from datetime import datetime
# 尝试导入Word处理库
try:
from docx import Document
from docxcompose.composer import Composer
from docx.shared import Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH
DOCX_AVAILABLE = True
except ImportError:
DOCX_AVAILABLE = False
class InteractiveFileMerger:
"""交互式文件合并器"""
def __init__(self):
self.directory = ""
self.output_file = ""
def display_menu(self):
"""显示主菜单"""
print("=" * 60)
print(" 交互式文件合并工具")
print("=" * 60)
print("\n请选择要合并的文件类型:")
print("1. 合并TXT文件")
print("2. 合并Python文件")
print("3. 合并DOCX文件")
print("4. 合并除HTML外的所有文件")
print("q. 退出程序")
def get_user_choice(self):
"""获取用户选择"""
self.display_menu()
while True:
choice = input("\n请输入选择 (1/2/3/4/q): ").strip()
if choice.lower() == 'q':
return None
if choice in ['1', '2', '3', '4']:
if choice == '3' and not DOCX_AVAILABLE:
print("❌ DOCX合并功能不可用,请先安装库:")
print(" pip install python-docx docxcompose")
continue
return choice
print("❌ 无效选择,请重新输入!")
def get_directory(self):
"""获取用户输入的目录路径"""
default_dir = "/storage/emulated/0/Download/"
print(f"\n请输入文件所在目录路径:")
print(f"(直接回车使用默认目录: {default_dir})")
while True:
user_input = input("> ").strip()
if not user_input:
self.directory = default_dir
else:
self.directory = user_input
if os.path.exists(self.directory):
print(f"✅ 使用目录: {self.directory}")
return True
else:
print(f"❌ 目录不存在: {self.directory}")
print("请重新输入或按 Ctrl+C 退出")
def get_files_by_type(self, merge_type):
"""根据合并类型获取文件列表"""
files = []
output_name = ""
merge_type_name = ""
if merge_type == "1": # TXT文件
pattern = "*.txt"
files = list(Path(self.directory).glob(pattern))
output_name = "合并_TXT文件.txt"
merge_type_name = "TXT文件"
elif merge_type == "2": # Python文件
pattern = "*.py"
files = list(Path(self.directory).glob(pattern))
output_name = "合并_Python文件.txt"
merge_type_name = "Python文件"
elif merge_type == "3": # DOCX文件
pattern = "*.docx"
files = list(Path(self.directory).glob(pattern))
output_name = "合并_DOCX文件.docx"
merge_type_name = "DOCX文件"
elif merge_type == "4": # 除HTML外的所有文件
all_files = list(Path(self.directory).glob("*"))
files = [f for f in all_files
if f.is_file()
and f.suffix.lower() not in ['.html', '.htm']
and f.name != output_name]
output_name = "合并_除HTML外所有文件.txt"
merge_type_name = "除HTML外的所有文件"
# 排除输出文件
files = [f for f in files if f.name != output_name]
# 自然排序
files.sort(key=lambda x: self.natural_sort_key(x.name))
return files, output_name, merge_type_name
def natural_sort_key(self, filename):
"""自然排序函数"""
return [int(text) if text.isdigit() else text.lower()
for text in re.split(r'(\d+)', filename)]
def merge_text_files(self, files, output_path, merge_type_name):
"""合并文本文件(TXT、Python、其他)"""
try:
with open(output_path, 'w', encoding='utf-8') as outfile:
# 写入文件大纲
outfile.write("===== 文件大纲 =====\n")
outfile.write(f"合并时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
outfile.write(f"合并类型: {merge_type_name}\n")
outfile.write(f"文件数量: {len(files)}\n")
outfile.write(f"目录路径: {self.directory}\n")
outfile.write("=========================\n\n")
# 列出所有文件
for i, file_path in enumerate(files, 1):
outfile.write(f"{i:2d}. {file_path.name}\n")
outfile.write("\n===== 文件内容 =====\n\n")
# 写入每个文件的内容
for file_path in files:
outfile.write(f"--- {file_path.name} ⬇️⬇️⬇️⬇️⬇️ ---\n")
try:
file_size = file_path.stat().st_size
mod_time = datetime.fromtimestamp(file_path.stat().st_mtime).strftime('%Y-%m-%d %H:%M:%S')
outfile.write(f"文件大小: {file_size} 字节\n")
outfile.write(f"修改时间: {mod_time}\n")
outfile.write("-------------------------\n")
# 读取文件内容
try:
with open(file_path, 'r', encoding='utf-8') as infile:
content = infile.read()
outfile.write(content)
except UnicodeDecodeError:
try:
with open(file_path, 'r', encoding='gbk') as infile:
content = infile.read()
outfile.write(content)
except:
outfile.write("【无法读取文件内容:编码问题】\n")
except Exception as e:
outfile.write(f"【读取文件出错: {str(e)}】\n")
except Exception as e:
outfile.write(f"【获取文件信息出错: {str(e)}】\n")
outfile.write("\n")
return True
except Exception as e:
print(f"❌ 合并文本文件时出错: {e}")
return False
def merge_docx_files(self, files, output_path):
"""合并DOCX文件"""
if not DOCX_AVAILABLE:
print("❌ DOCX文档合并功能不可用,请安装:pip install python-docx docxcompose")
return False
try:
# 创建主文档
master_doc = Document()
composer = Composer(master_doc)
# 创建目录文档
toc_doc = Document()
# 添加目录标题
title_paragraph = toc_doc.add_paragraph()
title_run = title_paragraph.add_run("===== 大纲 =====")
title_run.bold = True
title_run.font.size = Pt(18)
title_paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
toc_doc.add_paragraph() # 空行
# 添加目录内容
for i, file_path in enumerate(files, 1):
clean_name = file_path.stem
para = toc_doc.add_paragraph(f"{i:2d}. {clean_name}", style='ListNumber')
# 合并目录页
composer.append(toc_doc)
# 合并所有文档内容
for i, file_path in enumerate(files, 1):
try:
clean_name = file_path.stem
print(f"正在处理: {file_path.name}")
# 添加分隔符
separator_doc = Document()
self.add_file_separator(separator_doc, clean_name)
composer.append(separator_doc)
# 合并原文档
source_doc = Document(str(file_path))
composer.append(source_doc)
print(f"✅ 已添加: {file_path.name}")
except Exception as e:
print(f"❌ 处理文件 {file_path.name} 时出错: {e}")
continue
# 保存文档
composer.save(output_path)
return True
except Exception as e:
print(f"❌ 合并DOCX文档时出错: {e}")
return False
def add_file_separator(self, doc, filename):
"""为DOCX文档添加文件分隔符"""
doc.add_page_break()
title_paragraph = doc.add_paragraph()
title_run = title_paragraph.add_run(f"--- {filename} ⬇️⬇️⬇️⬇️⬇️ ---")
title_run.bold = True
title_run.font.size = Pt(14)
title_paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
doc.add_paragraph()
def run_merge(self, choice):
"""执行合并操作"""
# 获取文件列表
files, output_name, merge_type_name = self.get_files_by_type(choice)
if not files:
print("❌ 未找到任何符合条件的文件!")
return False
print(f"\n📁 找到 {len(files)} 个{merge_type_name},按以下顺序合并:")
for i, f in enumerate(files, 1):
print(f" {i:2d}. {f.name}")
# 设置输出文件路径
self.output_file = os.path.join(self.directory, output_name)
# 根据选择执行不同的合并
if choice == "3": # DOCX文件
print(f"\n🔄 开始合并DOCX文件...")
success = self.merge_docx_files(files, self.output_file)
else: # 文本文件
print(f"\n🔄 开始合并{merge_type_name}...")
success = self.merge_text_files(files, self.output_file, merge_type_name)
# 显示结果
if success:
output_size = os.path.getsize(self.output_file)
print(f"\n🎉 文件合并完成!")
print(f"📄 输出文件: {self.output_file}")
print(f"📊 合并文件数: {len(files)}")
print(f"💾 文件大小: {output_size} 字节")
return True
else:
print("❌ 合并失败!")
return False
def main():
"""主函数"""
merger = InteractiveFileMerger()
# 获取用户选择
choice = merger.get_user_choice()
if choice is None:
print("👋 程序已退出")
return
# 获取目录路径
if not merger.get_directory():
return
# 执行合并
merger.run_merge(choice)
print("\n✨ 所有任务已完成!")
if __name__ == "__main__":
main()

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)