Docker安装es、kibana并配置中文分词器
本文介绍了使用Docker部署Elasticsearch和Kibana 8.17.10的完整流程,包括:1)创建专用网络;2)拉取并运行ES容器;3)安装Kibana并连接ES;4)重点讲解如何安装IK中文分词器插件,详细说明ik_smart和ik_max_word两种分词模式的差异;5)提供优化IK分词器的方法,通过修改配置文件解决网络新词识别问题。部署完成后可通过9200和5601端口访问服务
一、 创建网络
创建虚拟网络,运行容器需要加入这个网络
docker network create es-net二、拉取 es安装 ES
docker pull elasticsearch:8.17.10三、运行 Docker 命令
切记版本号要对应❗❗❗
docker run -d --name es -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -e "discovery.type=single-node" -e "xpack.security.enabled=false" -v es-data:/usr/share/elasticsearch/data -v es-plugins:/usr/share/elasticsearch/plugins --privileged --network es-net -p 9200:9200 -p 9300:9300 elasticsearch:8.17.10测试,访问 http://ip:9200
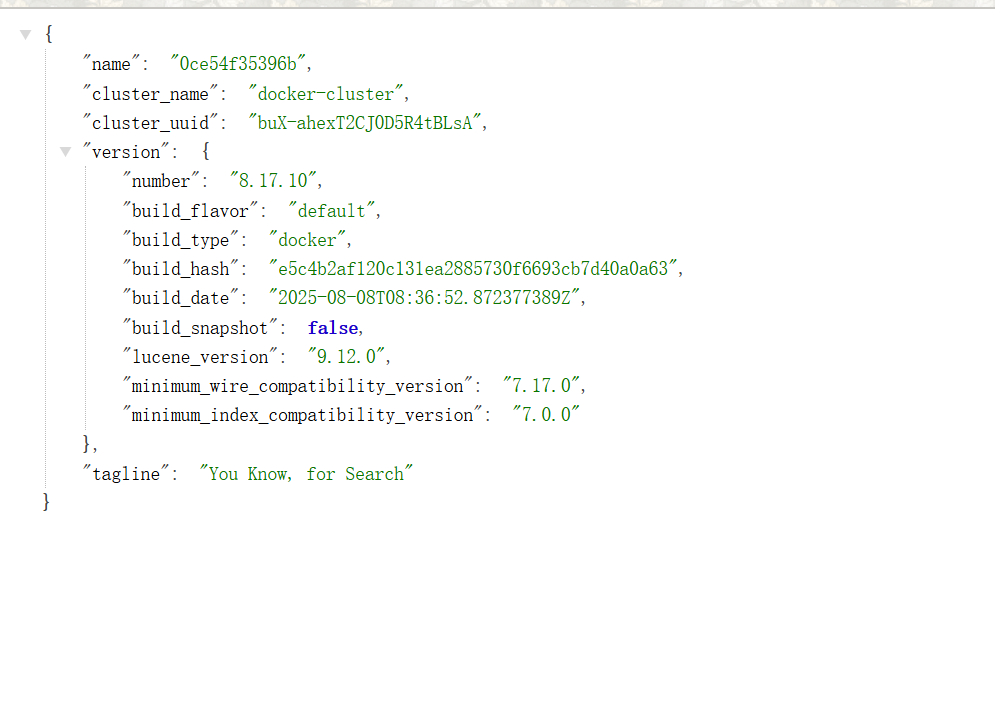
四、安装Kibana
docker pulll kibana:8.17.10五、运行 Kibana
切记版本号要对应❗❗❗
docker run -d --name kibana -e ELASTICSEARCH_HOSTS=http://es:9200 --network=es-net -p 5601:5601 kibana:8.17.10测试,http://ip:5601
到这里就可以正常使用了
扩展
下面这个图可以清晰的看到,默认的分词器对于中文并不是很好:
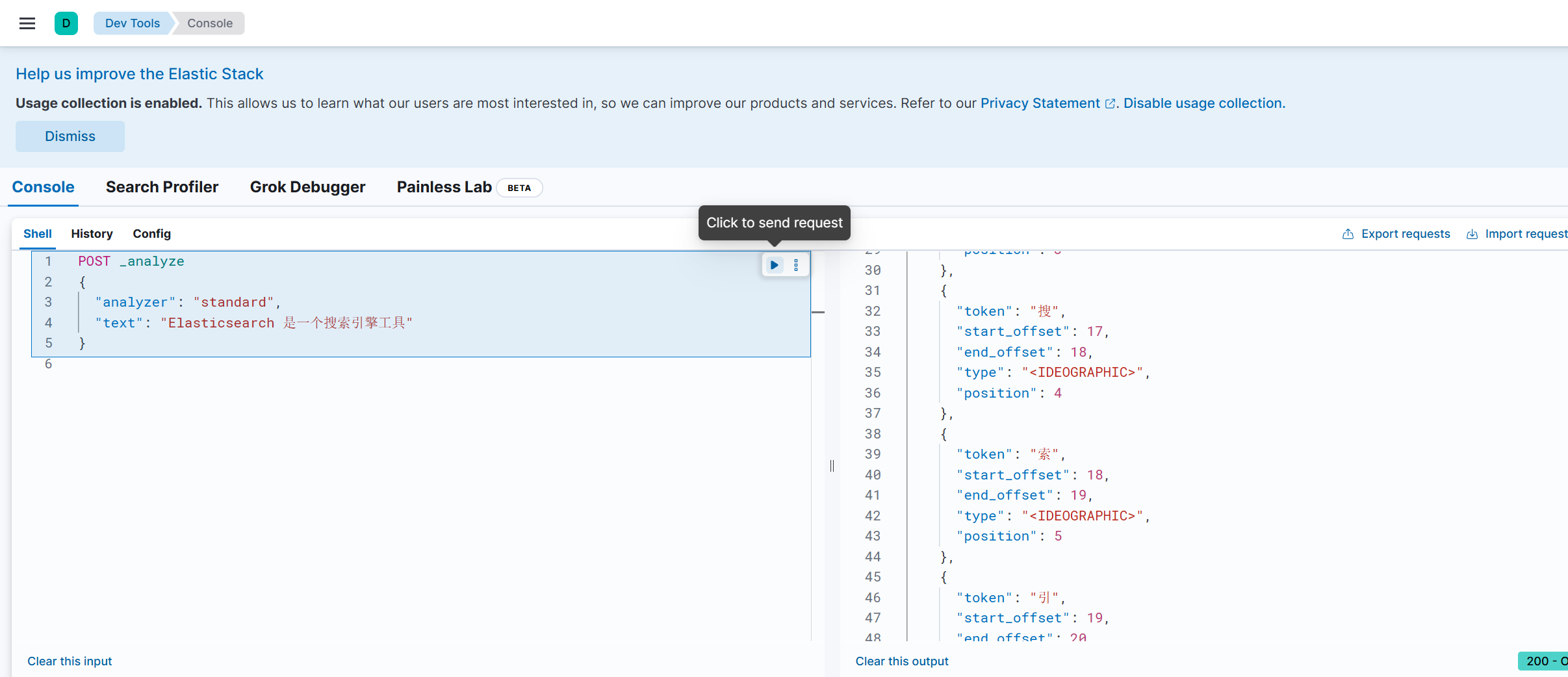
六、引入 IK 分词器
当需要处理中文分词时,一般都会使用 IK分词器。
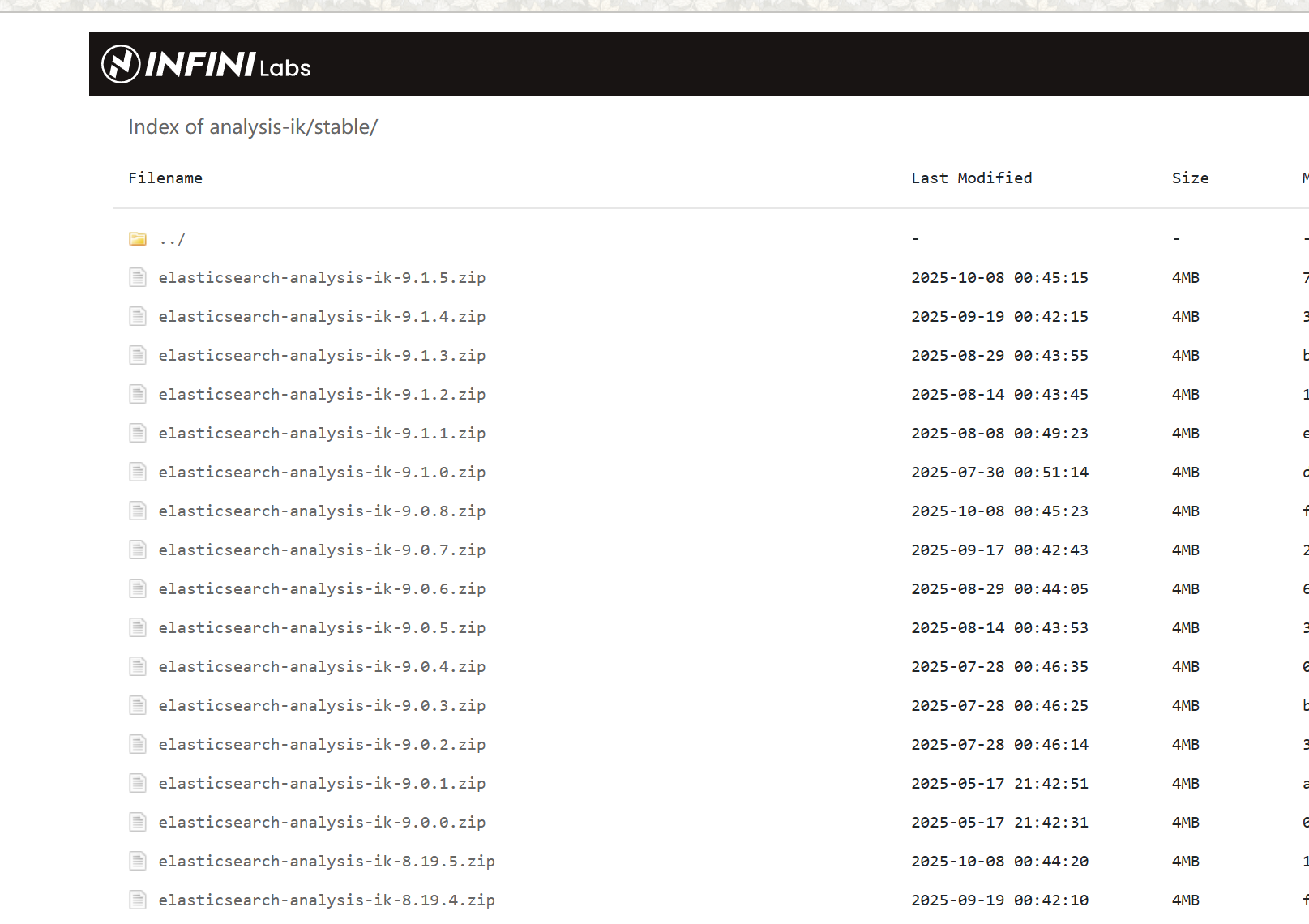
选择和自己版本对应的 ik 分词器
进入挂载目录将下载好的 zip 文件解压后放到挂在目录下,(我用的是 docker desktop)
docker cp D:\browserDownload\analysis-ik es:/usr/share/elasticsearch/plugins/IK 分词器有两种分词模式
ik-smark 模式
ik-smark 模式下 IK 分词器会进行最少拆分,保证整体性
POST _analyze
{
"analyzer": "ik_smart",
"text": "Elasticsearch 是一个搜索引擎工具。"
分词结果
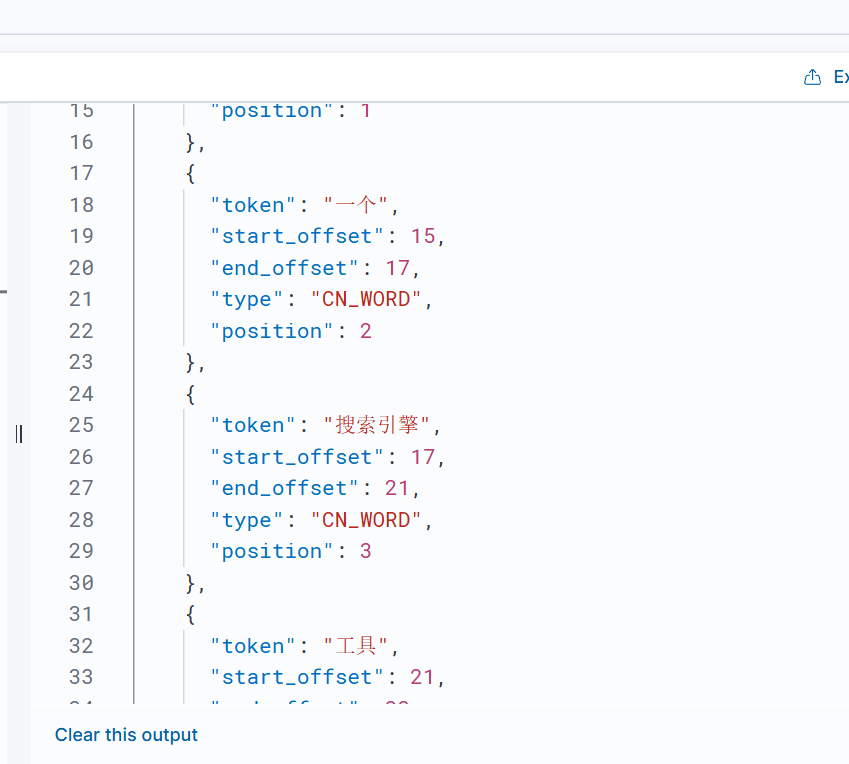
ik-max-word 模式
ik-max-word模式会将文本以最细粒度进行穷尽切分,分成尽可能多的词语。
POST _analyze
{
"analyzer": "ik_max_word",
"text": "Elasticsearch 是一个搜索引擎工具。"
}分词结果:

优化 IK 分词
其实 IK 分词器到这里还有一点点的小问题,就是目前的 IK 分词器无法正确的划分网络名词,所以这个时候就需要我们手动去设置,在 IK 分词器目录中的config目录中的IkAnalyzer.cfg.xml中
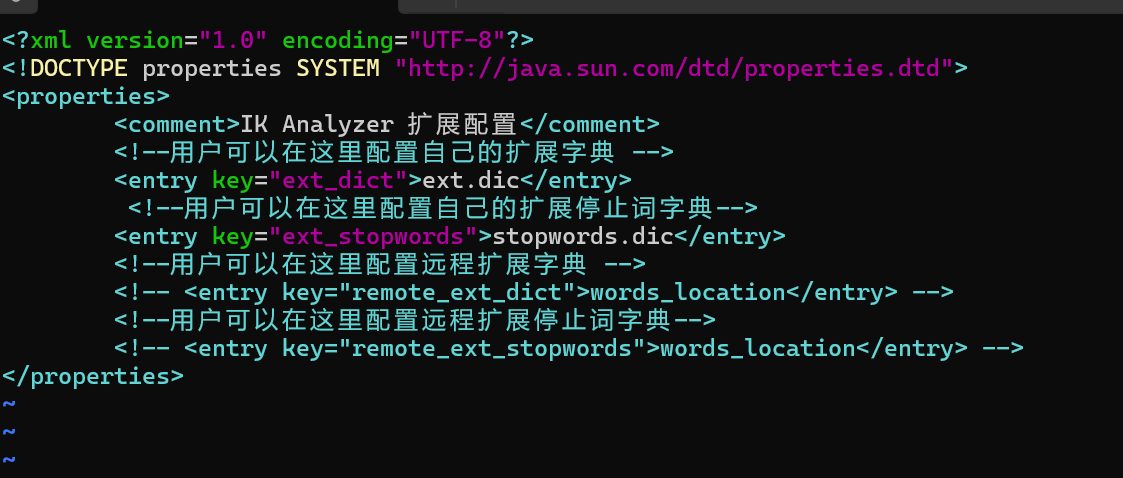
ext.dic 内容如下:

stopwords.dic内容如下:

保存退出,重启 es
验证:
POST _analyze
{
"analyzer": "ik_smart",
"text": "小孩哥觉得我city不city呀"
}结果:


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)