AI 术语通俗词典:CLIP(对比语言–图像预训练)
CLIP 的核心思想:同时输入图像与对应的文本描述,通过对比学习,让模型学会把图像和文本映射到同一个语义空间,并尽可能让匹配的图文更接近,不匹配的则更远离。CLIP(对比语言–图像预训练)是一种通过对比学习连接图像与语言的预训练方法,同时也是 OpenAI 基于该方法训练出的代表性模型。在 Stable Diffusion、DALL·E 等模型中,CLIP 用来衡量生成图像与文本提示的匹配度,指导
在多模态人工智能的发展历程中,CLIP 是一个具有里程碑意义的成果。它不仅在研究领域掀起热潮,也在图像生成、搜索与标注等应用中发挥了巨大作用。
一、术语定义
CLIP 全称 Contrastive Language–Image Pre-training(对比语言–图像预训练)。
从学术角度看,CLIP 是一种预训练方法,通过语言与图像的对比学习来建立跨模态关联。
从应用角度看,CLIP 也是 OpenAI 基于该方法训练出的具体模型,因此人们常称之为“CLIP 模型”。
CLIP 的核心思想:同时输入图像与对应的文本描述,通过对比学习,让模型学会把图像和文本映射到同一个语义空间,并尽可能让匹配的图文更接近,不匹配的则更远离。
二、提出背景
在 CLIP 出现之前,图像识别任务通常依赖于:
单一任务训练:如专门训练一个分类模型识别“猫 vs 狗”。
大量标注数据:每个任务都需要人工打标签,成本极高。
CLIP 的突破点在于:
利用互联网上大规模图文配对数据(如网页上的图片和说明文字)。
通过对比学习,实现“一次训练,多任务适配”。
这意味着 CLIP 不必为每个任务单独训练,而是能直接迁移到下游应用。
三、工作原理
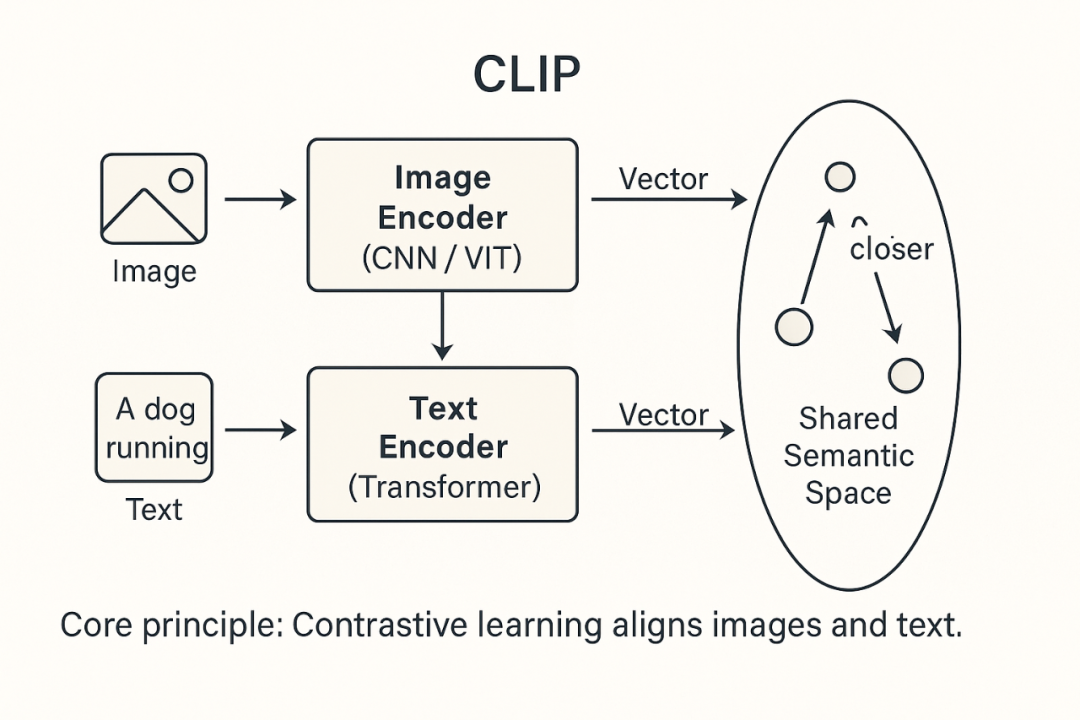
CLIP 的训练过程可以分为三个核心步骤:
1、输入数据
图像(Image)
文本(Text)
2、编码表示
图像编码器(通常基于 CNN 或 ViT)将图像转化为向量。
文本编码器(通常基于 Transformer)将文本转化为向量。
3、对比学习
将图像向量与文本向量投射到同一语义空间。
匹配的图文对 → 向量距离更近。
不匹配的图文对 → 向量距离更远。
训练目标:CLIP 通常采用对比损失(Contrastive Loss),其中最常见的是 InfoNCE 损失。它会最大化匹配图文对的相似度,同时最小化不匹配对的相似度。
最终,CLIP 学会了“图文对齐”的能力。
四、典型应用
1、零样本分类(Zero-shot Classification)
不需要额外训练,只需提供类别描述文字,就能对图像进行分类。
例:输入文字“狗”、“猫”,CLIP 就能判断一张照片更接近哪一类。
2、图像检索(Image Retrieval)
输入一句文字,如“在草地上奔跑的狗”,CLIP 可以从图片库中找到最符合的图像。
3、文本生成图像(Text-to-Image)
在 Stable Diffusion、DALL·E 等模型中,CLIP 用来衡量生成图像与文本提示的匹配度,指导优化结果。
提示:CLIP 在生成模型中通常作为判别器/评估器,而不是直接生成模块。
4、内容过滤与标注
用于自动识别图片内容,进行搜索引擎过滤或内容审核。
五、技术意义
1、多模态 AI 的基础
CLIP 让文本和图像在同一语义空间中建立联系,成为后续多模态模型(如文生图、图生文)的核心基石。
2、降低数据标注成本
不再需要逐任务标注,只需利用现成的图文数据。
3、推动下游应用普及
从搜索推荐到生成模型,CLIP 几乎无处不在。
六、挑战与问题
1、数据偏差
训练数据来自互联网,可能带有偏见或不准确信息。
2、语义理解的深度
CLIP 对表面语义的匹配很强,但在复杂逻辑推理和抽象概念理解上仍有限。
3、算力与规模依赖
训练 CLIP 需要大量算力和数据资源,中小团队难以复现。
📘 小结
CLIP(对比语言–图像预训练)是一种通过对比学习连接图像与语言的预训练方法,同时也是 OpenAI 基于该方法训练出的代表性模型。
本质:让图像与文本共享统一的语义空间。
能力:零样本分类、图像检索、文生图优化、内容理解与标注。
意义:奠定多模态 AI 的基础,成为生成模型和检索系统的关键组件。
可以说,没有 CLIP,就难以想象今天的文生图和多模态 AI 能如此快速发展。

“点赞有美意,赞赏是鼓励”

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)