小白程序员也能搞定的RAG:企业三大系统集成实战,附完整代码示例
RAG技术已从实验室走向企业核心基础设施,本文详细介绍了RAG与客服系统、知识库平台和BI工具的集成路径。从接口设计、数据同步、权限控制到工程实践,提供了一套可落地的技术方案,并强调了幂等性、超时控制与批量查询等关键非功能需求。通过将RAG深度集成到现有业务系统,企业可实现自然语言查询、知识库自动同步和BI语义化操作,构建统一语义接口层,让非技术人员也能安全高效地访问企业知识与数据。
在大模型时代,Retrieval-Augmented Generation(RAG)已不再只是实验室里的技术玩具,而是越来越多企业构建智能应用的核心基础设施。然而,如何将 RAG 无缝嵌入现有业务系统——如客服平台、企业知识库和商业智能(BI)工具——仍是许多架构师面临的现实挑战。
本文面向企业应用架构师,聚焦 RAG 与三大典型企业系统的集成路径:客服系统、知识库平台与 BI 工具。我们将从接口设计、数据同步、权限控制到工程实践,提供一套可落地的技术方案,并强调幂等性、超时控制与批量查询等关键非功能需求。
一、为什么 RAG 需要成为企业基础设施?
传统问答系统依赖规则或关键词匹配,难以应对复杂语义;而纯大模型又存在幻觉、成本高、无法访问私有数据等问题。RAG 通过“检索 + 生成”的混合架构,在保证回答准确性的同时,充分利用企业内部知识资产。
但若 RAG 只是一个孤立服务,其价值将大打折扣。只有将其深度集成到现有工作流中,才能真正赋能一线业务:
- 客服人员通过自然语言快速获取产品文档;
- 员工在 Confluence 中提问,直接获得上下文感知的答案;
- 业务分析师用口语化指令查询销售数据,无需写 SQL。
这正是本文要解决的问题:如何让 RAG 成为企业系统的“智能插件”?
二、客服系统集成:提供标准化问答接口
客服系统是 RAG 最直接的应用场景。用户咨询时,系统可自动调用 RAG 服务,返回基于最新知识库的精准答案。
接口设计建议
- 协议选择:推荐使用 RESTful API(便于前端调用)或 gRPC(高性能、强类型,适合内部微服务)。
- 端点示例(基于 FastAPI):
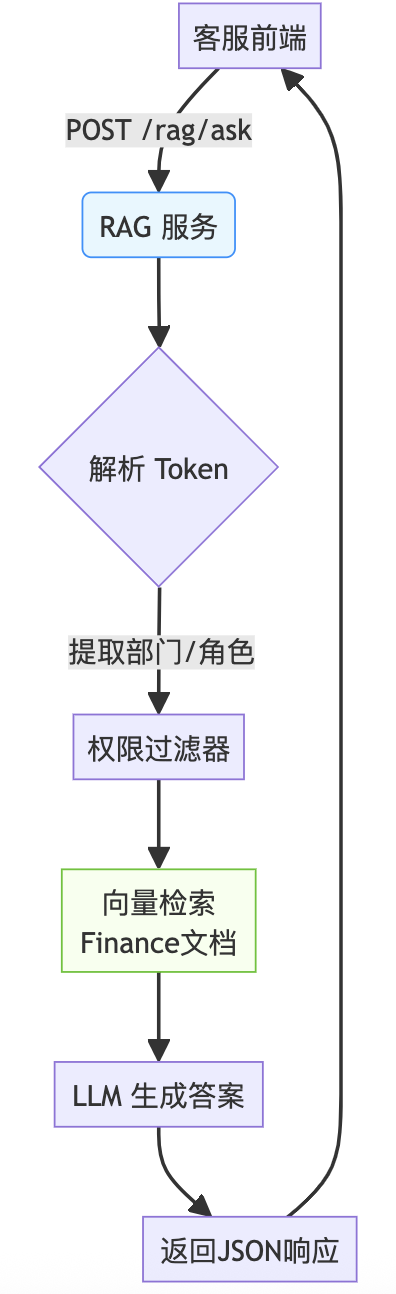
@app.post("/rag/ask")async def ask_rag(request: AskRequest, user_token: str = Header(...)): # 解析 token 获取用户角色/部门 # 执行带权限过滤的检索 # 返回结构化答案
- 关键字段:
query:用户问题(如“如何重置密码?”)user_id/token:用于权限透传context_hint(可选):指定知识库范围(如“仅限 HR 政策”)
工程保障
- 幂等性:相同 query + user 组合在短时间内应返回缓存结果,避免重复计算。
- 超时控制:建议设置 3–5 秒整体超时,防止阻塞客服主流程。
- 降级策略:RAG 服务不可用时,可回退至关键词搜索或提示“正在查询,请稍后”。
下图展示了客服系统与 RAG 的交互流程:
三、知识库对接:实现文档自动同步
RAG 的效果高度依赖底层知识库的时效性。若文档更新后未同步至向量库,将导致答案过时甚至错误。
主流平台集成方案
| 平台 | 同步机制 | 技术要点 |
| Confluence | Webhook + REST API | 监听 page.updated 事件,增量拉取内容并重新向量化 |
| Notion | Notion API + Database Polling | 使用官方 SDK 获取 blocks,注意速率限制 |
| SharePoint | Microsoft Graph API + Change Log | 利用 delta query 获取变更项 |
自动化同步架构
建议采用 Airflow 或类似编排工具构建同步 DAG(Directed Acyclic Graph),实现:
- 监听变更事件(Webhook 触发或定时轮询);
- 提取文本内容(去除 HTML 标签、表格结构化);
- 分块与嵌入(使用 Sentence Transformers 等模型);
- 写入向量数据库(如 Qdrant、Milvus),支持版本快照以便回滚。
注意:不要在同步过程中直接删除旧向量。应采用“标记-清理”策略,确保服务期间数据一致性。
四、BI 场景集成:自然语言查数的新范式
BI 系统通常依赖固定报表或 SQL 查询,门槛高、灵活性差。RAG 可作为“语义层”,将自然语言转化为可执行的数据操作。
典型工作流
用户输入:“上季度华东区销售额是多少?”
- RAG 检索相关业务文档(如《销售指标定义》《区域划分规则》);
- 提取关键参数:时间=Q3 2025,区域=East China,指标=sales_amount;
- 调用 SQL Agent(或 NL2SQL 模块)生成安全 SQL;
- 执行查询并返回结果,附带数据来源说明。
安全与权限
- 权限透传至关重要:用户只能查询其权限范围内的数据(如销售员看不到财务成本)。
- 实现方式:在 RAG 请求头中携带 JWT Token,解析后传递给 SQL Agent 作为 WHERE 条件。
例如:
SELECT SUM(sales) FROM sales_table WHERE region = 'East China' AND quarter = 'Q3_2025' AND department_id IN (SELECT dept_id FROM user_dept WHERE user_id = 'U123')
此模式下,RAG 不仅提供答案,还充当语义解析器 + 权限网关,大幅提升 BI 系统的易用性与安全性。
五、关键技术保障:不止于功能实现
要让 RAG 在生产环境稳定运行,必须关注以下工程细节:
1. 接口幂等性
对相同输入(query + user context)应返回一致结果。可通过 Redis 缓存 key = hash(query + roles) 实现。
2. 超时与熔断
- 设置 端到端超时(如 4s),避免拖垮上游系统;
- 使用 circuit breaker(如 Hystrix 模式)在 RAG 服务异常时快速失败。
3. 批量查询支持
对于知识库预加载或离线分析场景,提供 /rag/batch_ask 接口,支持一次处理多个问题,提升吞吐。
4. 可观测性
- 记录每个请求的 trace_id、检索耗时、top-k 文档 ID;
- 监控缓存命中率、LLM 调用次数、错误率等核心指标。
六、结语:RAG 不是终点,而是智能入口
将 RAG 集成到客服、知识库与 BI 系统,本质上是在构建企业的统一语义接口层。它让非技术人员也能安全、高效地访问企业知识与数据。
但要注意:RAG 的价值不在于模型多大,而在于与业务系统的耦合深度。只有当它像数据库、消息队列一样,成为架构中的标准组件时,真正的智能才开始流动。
作为架构师,我们的任务不是追逐最新模型,而是设计可扩展、可维护、可信任的集成方案——这才是 RAG 落地的关键。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献365条内容
已为社区贡献365条内容

所有评论(0)