毕业设计:Python答题卡识别判分系统 +Django+OpenCV 计算机视觉实战(pyecharts可视化 源码+文档)✅
毕业设计:Python答题卡识别判分系统 +Django+OpenCV计算机视觉实战(pyecharts可视化 源码+文档)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Django框架、pyecharts可视化、OpenCV(计算机视觉)、matplotlib、MySQL数据库(数据存储)、HTML(前端界面)、拼图滑动验证码(安全验证)
- 核心功能:答题卡图像识别与自动判分、识别记录管理、得分数据可视化分析(得分分布、识别数量统计)、用户权限管理、后台系统运维
- 研究背景:传统纸质阅卷依赖人工或光标阅读机,存在显著痛点——人工阅卷效率低、易出错,光标阅读机购买与维护成本高,普通学校与个人难以负担;随着计算机视觉技术发展,亟需基于OpenCV的低成本答题卡识别方案,解决“阅卷效率低、成本高”的问题,满足教学场景中快速判分与数据统计需求。
- 研究意义:技术层面,整合OpenCV图像处理、DjangoWeb架构与pyecharts可视化,构建“识别-判分-分析-管理”完整技术闭环;用户层面,为教师/学校降低阅卷成本(无需采购专业设备),提升判分效率(秒级识别),支持得分数据可视化;行业层面,推动计算机视觉技术在教育场景落地,为“智慧阅卷”提供轻量化解决方案,具备实际应用与学习价值(如毕业设计、教学工具开发)。
2、项目界面
-
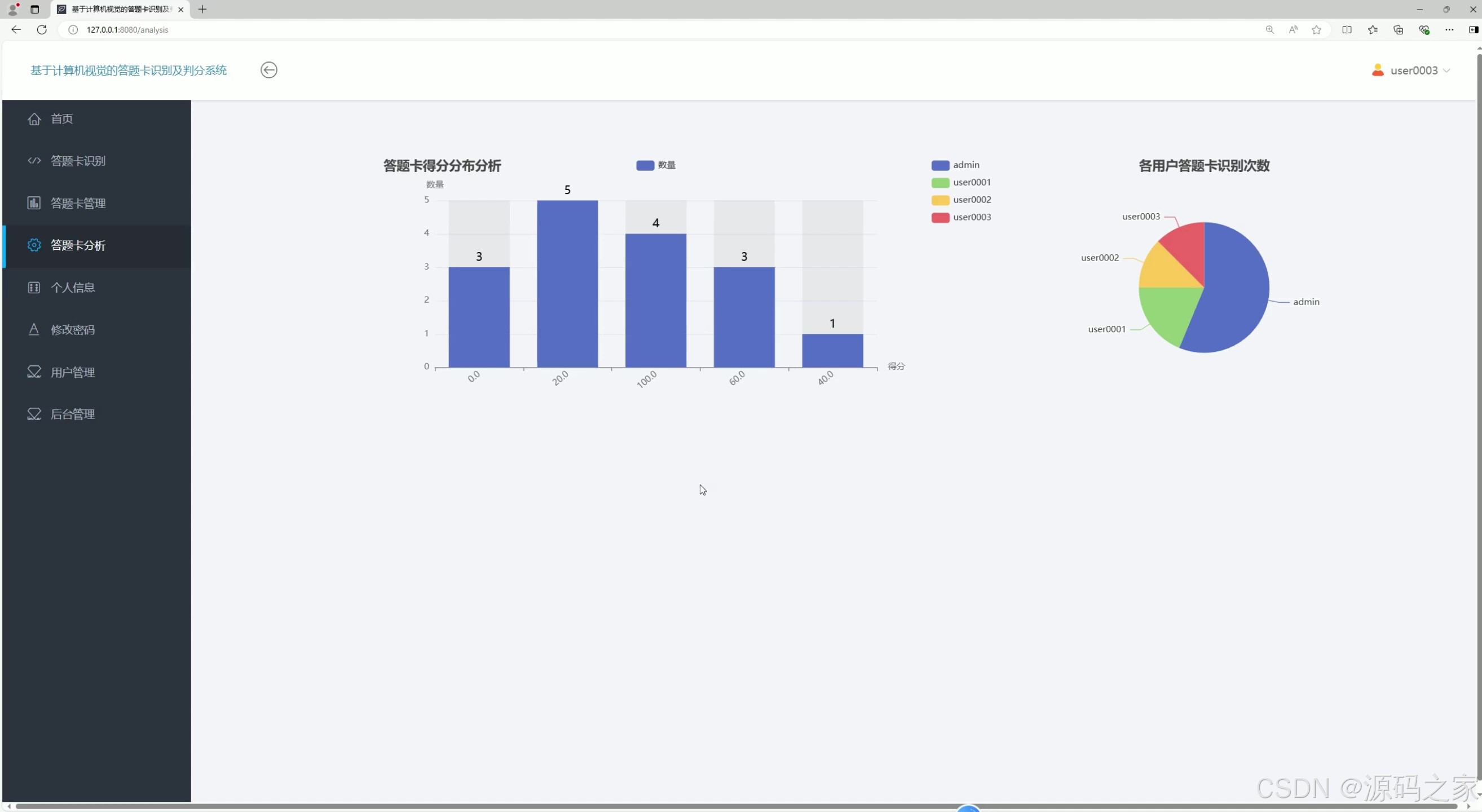
答题卡数据可视化分析
-
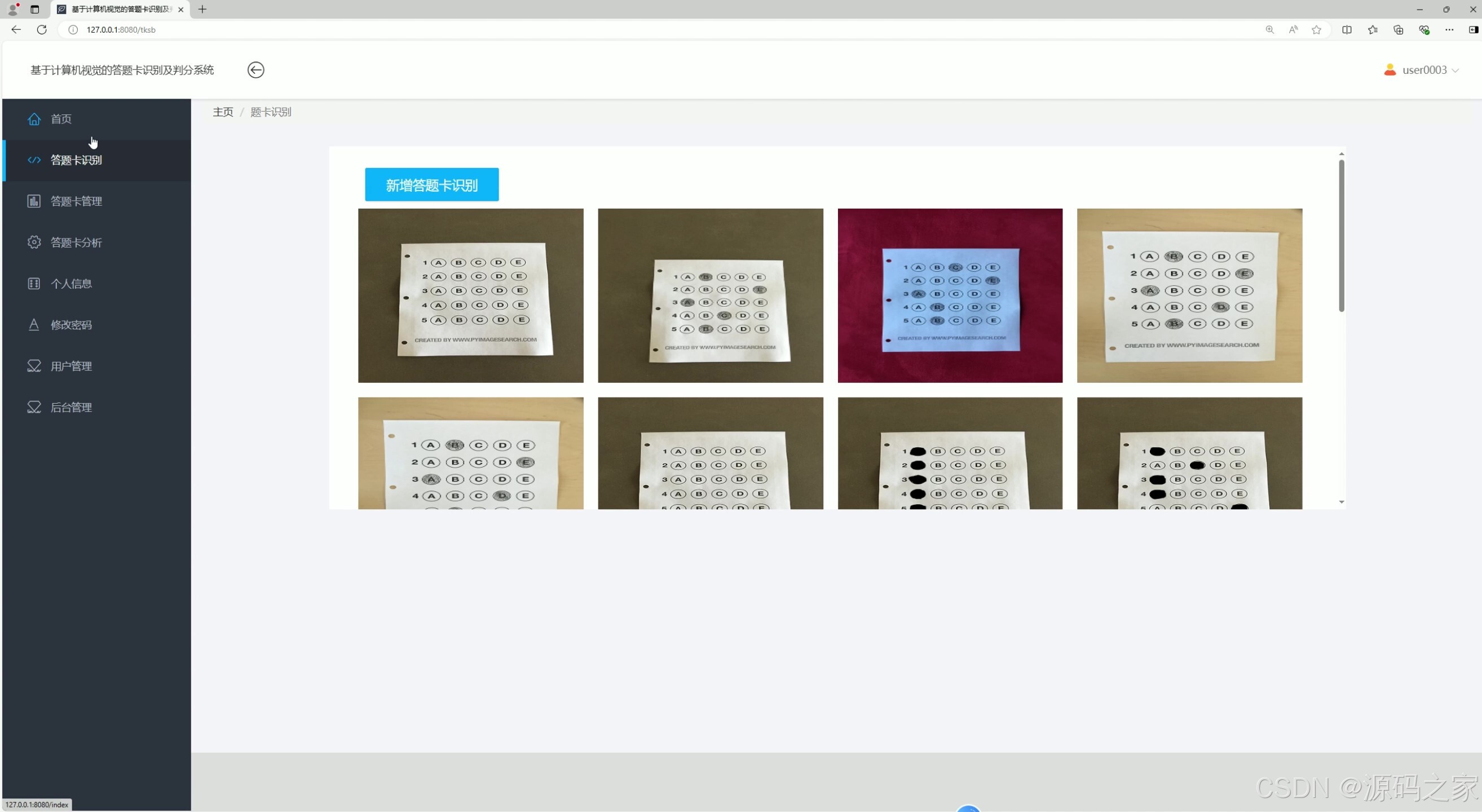
答题卡识别功能
-
上传图片进行识别
-
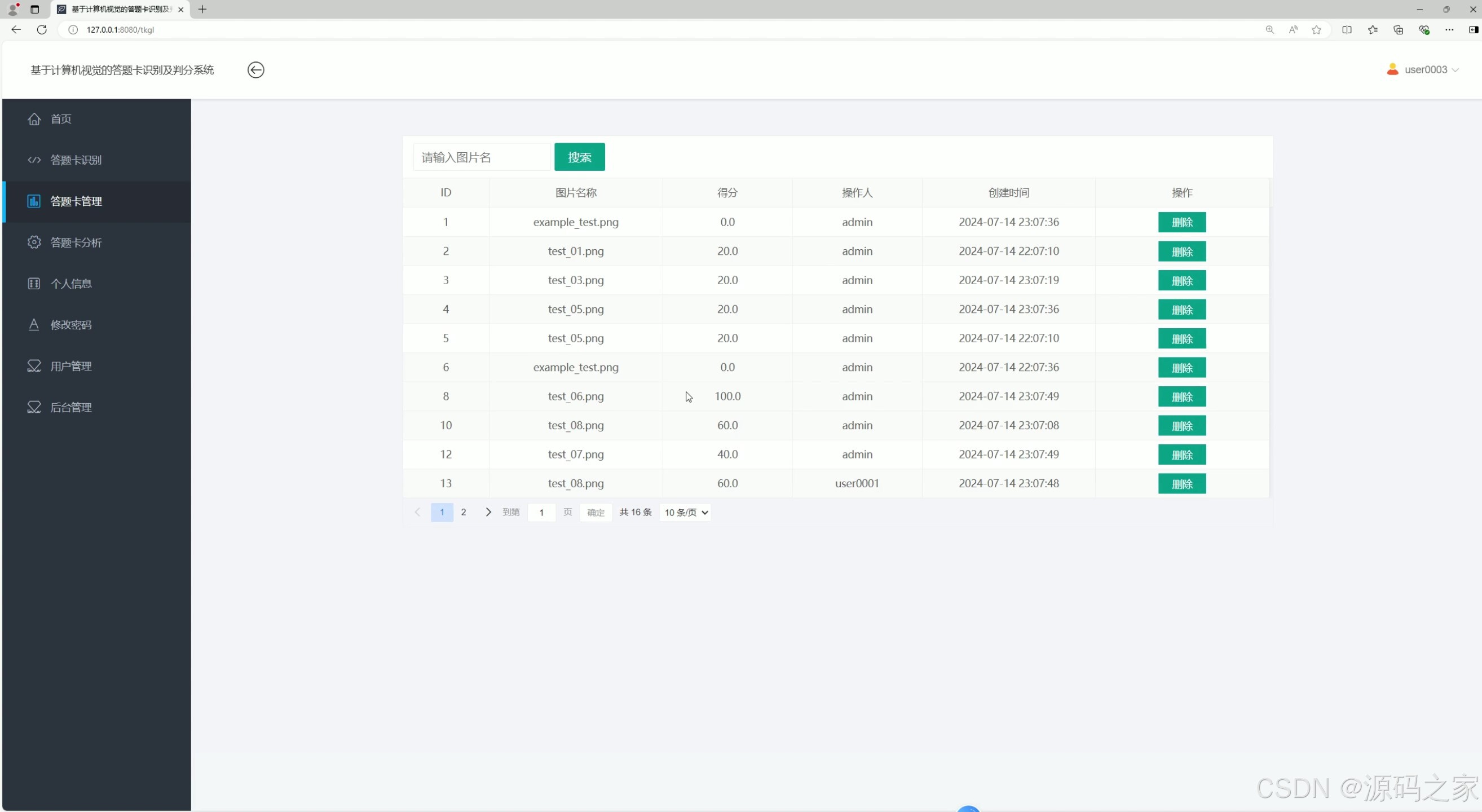
答题卡识别记录管理
-
后台管理
-
数据面板
-
注册登录
3、项目说明
本项目是基于Python+Django框架开发的答题卡识别及自动判分系统,核心集成OpenCV计算机视觉技术、pyecharts可视化工具与MySQL数据库,实现“答题卡上传-图像识别-自动判分-记录管理-数据分析”的全流程功能,旨在解决传统阅卷效率低、成本高的问题,适配普通学校与个人教学场景。
(1)核心技术与算法实现(OpenCV识别判分)
系统核心的答题卡识别与判分功能基于OpenCV构建,技术流程标准化:
- 图像预处理:用户上传答题卡图片后,OpenCV自动进行图像优化——灰度化(降低色彩干扰)、二值化(区分答题区域与背景,如黑色选项框与白色背景)、降噪处理(去除图片模糊或污渍导致的干扰像素);
- 关键区域定位:通过轮廓检测算法,识别答题卡的答题区域(如选择题选项框、题号位置)、准考证号区域,确保仅对有效区域进行识别,避免边缘无关内容干扰;
- 答案识别与比对:
- 识别:通过像素值分析,判断用户选择的选项(如黑色填充的选项框即为所选答案);
- 比对:系统预设标准答案(管理员在后台录入),将识别结果与标准答案逐题比对,自动计算得分(如100题满分,每题1分,错1题扣1分);
- 结果存储:识别结果(得分、答题情况、上传时间)与原图路径同步存入MySQL数据库,为后续管理与分析提供数据支撑。
(2)核心功能模块详解
① 用户认证与安全模块
- 注册登录:
- 功能:用户通过“注册登录界面”完成账号注册(填写姓名、密码、手机号)与登录,登录时需完成拼图滑动验证码验证,防止恶意登录与数据泄露;
- 权限划分:系统区分普通用户(如教师,仅可上传识别、查看个人记录)与管理员(可管理所有用户、录入标准答案、监控系统数据),保障数据安全。
- 个人中心:支持普通用户修改密码、维护个人信息,管理员可通过“用户管理界面”新增/修改/删除用户账号,分配操作权限。
② 答题卡识别与判分模块
- 上传识别:用户进入“上传图片进行识别”界面,支持单张/批量上传答题卡图片(格式如JPG、PNG),点击“开始识别”后,系统调用OpenCV接口完成自动判分,1-3秒内返回得分结果;
- 识别记录查看:“答题卡识别功能”界面展示个人所有识别记录,包含原图预览、得分、识别时间,支持按“识别时间”“得分区间”筛选,快速定位目标记录;
- 结果校验:若识别结果存在异议(如因图片模糊导致识别错误),用户可查看“答题详情”(逐题比对识别答案与标准答案),管理员可手动修正得分并重新存储。
③ 答题卡管理模块
- 记录管理:“答题卡识别记录管理”界面集中展示所有用户的识别记录(含图片名称、得分、操作人员、上传时间),支持:
- 搜索:按图片名称关键词查找特定记录;
- 删除:普通用户仅可删除个人记录,管理员可删除所有无效记录(如重复上传、识别失败的记录);
- 标准答案管理:管理员专属功能,通过后台录入不同试卷的标准答案(如“试卷A选择题标准答案:1.A、2.B、3.C…”),确保判分标准统一。
④ 数据可视化分析模块
- 数据面板:“数据面板”界面展示系统宏观数据,如总用户数、总识别次数、平均得分、今日新增识别量,帮助管理员快速把握系统运营状态;
- 可视化分析:“答题卡数据可视化分析”界面通过pyecharts生成多维度图表:
- 得分分布柱状图:展示不同得分区间的记录数量(如“80-90分区间有20条记录,90-100分区间有15条记录”);
- 识别趋势折线图:按日期展示每日识别次数变化(如“周一识别50次,周二识别30次”);
- 用户识别量排行:对比不同用户的累计识别次数,辅助管理员评估系统使用频率。
⑤ 后台管理模块(管理员专属)
- 系统监控:查看系统日志(如用户登录日志、识别失败日志),排查异常问题(如某时段识别失败率高,可能因图片格式不兼容);
- 数据维护:备份/恢复MySQL数据库,防止数据丢失;管理图片存储路径,定期清理无效图片文件,节省存储空间;
- 功能配置:调整识别参数(如OpenCV二值化阈值、识别精度),优化识别效果(如降低模糊图片的识别错误率)。
(3)系统价值与应用场景
- 目标用户:中小学教师(日常作业/小测验判分)、培训机构(模拟考试快速阅卷)、个人学习者(自测后自动核对答案);
- 核心价值:相比传统人工阅卷,效率提升80%以上;相比光标阅读机,零设备采购成本,普通学校与个人均可免费使用;
- 扩展性:支持后续新增“批量导出报表”功能(将得分数据导出为Excel)、“错题统计”功能(分析高频错题,辅助教学重点突破)。
4、核心代码
# 导入工具包
import numpy as np
import argparse
import imutils
import cv2
# 正确答案
ANSWER_KEY = {0: 0, 1: 0, 2: 0, 3: 0, 4: 0}
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype="float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype="float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
def sort_contours(cnts, method="left-to-right"):
reverse = False
i = 0
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i], reverse=reverse))
return cnts, boundingBoxes
def main(path):
# 预处理
image = cv2.imread(path)
contours_img = image.copy()
# print(contours_img)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blurred, 75, 200)
# 轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[0]
# print(contours_img)
cv2.drawContours(contours_img, cnts, -1, (0, 0, 255), 3)
# cv2.drawContours(contours_img,cnts.reshape(-1,1,2),-1,(0,0,255),3)
# cv_show('contours_img', contours_img)
docCnt = None
# 确保检测到了
if len(cnts) > 0:
# 根据轮廓大小进行排序
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# 遍历每一个轮廓
for c in cnts:
# 近似
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 准备做透视变换
if len(approx) == 4:
docCnt = approx
break
# 执行透视变换
warped = four_point_transform(gray, docCnt.reshape(4, 2))
# cv_show('warped', warped)
# Otsu's 阈值处理
thresh = cv2.threshold(warped, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
# cv_show('thresh', thresh)
thresh_Contours = thresh.copy()
# 找到每一个圆圈轮廓
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[0]
cv2.drawContours(thresh_Contours, cnts, -1, (0, 0, 255), 3)
# cv_show('thresh_Contours', thresh_Contours)
questionCnts = []
# 遍历
for c in cnts:
# 计算比例和大小
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# 根据实际情况指定标准
if w >= 20 and h >= 20 and ar >= 0.9 and ar <= 1.1:
questionCnts.append(c)
# 按照从上到下进行排序
questionCnts = sort_contours(questionCnts,
method="top-to-bottom")[0]
correct = 0
# 每排有5个选项
for (q, i) in enumerate(np.arange(0, len(questionCnts), 5)):
# 排序
cnts = sort_contours(questionCnts[i:i + 5])[0]
bubbled = None
# 遍历每一个结果
for (j, c) in enumerate(cnts):
# 使用mask来判断结果
mask = np.zeros(thresh.shape, dtype="uint8")
cv2.drawContours(mask, [c], -1, 255, -1) # -1表示填充
# cv_show('mask', mask)
# 通过计算非零点数量来算是否选择这个答案
mask = cv2.bitwise_and(thresh, thresh, mask=mask)
total = cv2.countNonZero(mask)
# 通过阈值判断
if bubbled is None or total > bubbled[0]:
bubbled = (total, j)
# 对比正确答案
color = (0, 0, 255)
k = ANSWER_KEY[q]
# 判断正确
if k == bubbled[1]:
color = (0, 255, 0)
correct += 1
# 绘图
cv2.drawContours(warped, [cnts[k]], -1, color, 3)
score = (correct / 5.0) * 100
print("--------------------------------------------")
print("答题卡得分为: {:.2f}分".format(score))
print("正确率: {:.2f}%".format(score))
return score
if __name__ == '__main__':
main()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)