AI工具革命:从代码生成到模型部署的全栈实践
本文系统介绍了现代AI工程实践中的三类核心工具:智能编码工具、数据标注工具和模型训练平台。智能编码工具(如GitHub Copilot)通过AI辅助显著提升开发效率;数据标注工具为AI模型提供高质量的"燃料",并逐步融入AI辅助标注技术;模型训练平台(如Google Vertex AI)实现了从数据准备到模型部署的全流程管理。这三类工具相互促进,共同构成了AI开发的完整生态系统
引言
人工智能正在重塑软件开发和数据科学的每一个环节。它不再仅仅是研究和实验的领域,而是已经演变为一系列强大的工程工具,渗透到从最初的代码编写到复杂的模型训练与部署的全流程。这些工具极大地提高了开发效率,降低了技术门槛,并正在成为现代技术人员“智械纪元”的标配。
本文将深入探讨三类核心的AI工具:
-
智能编码工具:以GitHub Copilot为代表,探讨AI如何辅助程序员进行代码编写、调试和解释。
-
数据标注工具:作为AI模型的“燃料”供应商,介绍其关键功能和在项目中的核心地位。
-
模型训练平台:如Google Vertex AI、Amazon SageMaker等,分析其如何简化和管理大规模的模型训练任务。
我们将通过理论结合实践的方式,辅以丰富的图表和代码,为您呈现一幅完整的AI工具应用图谱。
第一部分:智能编码工具 - GitHub Copilot 与 AI 编程助手
智能编码工具利用大型语言模型,将自然语言提示(Prompt)转化为代码建议,从而在集成开发环境(IDE)中为开发者提供实时的辅助。GitHub Copilot 是这一领域的先驱和领导者。
1.1 核心原理与工作流程
GitHub Copilot 基于OpenAI的Codex模型,该模型是在海量的公开源代码和自然语言文本上训练而成的。其工作流程可以概括为以下几个步骤:
flowchart TD
A[开发者编写代码或注释] --> B[IDE插件捕获上下文<br>代码、注释、文件名等]
B --> C[上下文信息发送至Copilot服务]
C --> D[Copilot服务调用AI模型<br>如GPT系列]
D --> E[模型生成代码建议]
E --> F[建议返回并显示在IDE中]
F --> G{开发者选择}
G -- 接受 --> H[代码插入编辑器]
G -- 拒绝/忽略 --> I[建议被丢弃]
H --> A
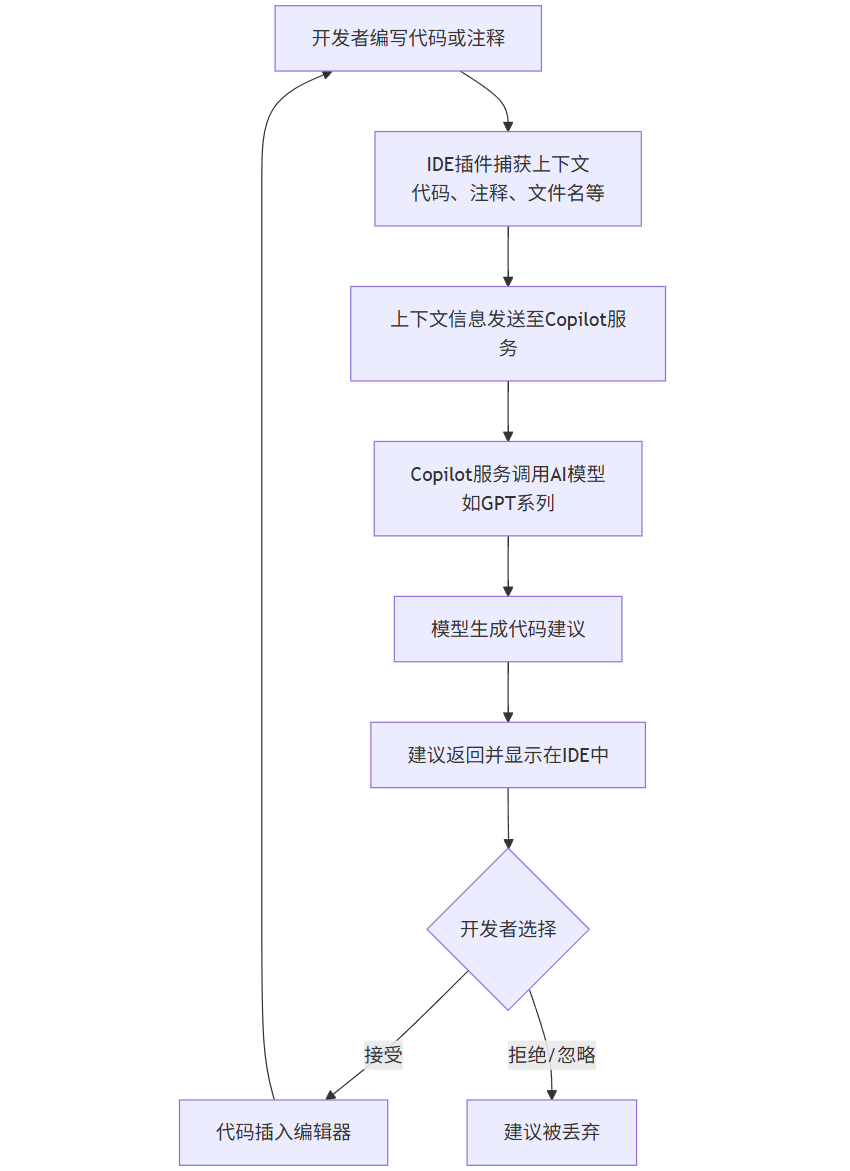
流程解读:
-
上下文捕获:当您输入代码或注释时,Copilot的IDE插件会持续分析当前的代码文件。它不仅仅看当前行,还会考虑您已经写好的函数、导入的库、文件名称以及相邻的代码块,以获取最丰富的上下文。
-
服务调用与模型推理:捕获的上下文被安全地发送到Copilot的后端服务。后端服务利用强大的LLM(如GPT-3.5/4系列专门为代码优化的版本)对上下文进行理解和推理。
-
代码生成与返回:模型根据上下文预测最可能的下文代码,生成一个或多个代码建议。
-
开发者决策:建议以灰色文本的形式显示在您的IDE中。您可以选择按
Tab键接受,按Esc键拒绝,或者查看其他备选建议。
1.2 实战应用与代码示例
Copilot的能力远不止补全单个单词,它能在多种场景下大放异彩。
场景一:根据函数名和注释生成代码
假设您想写一个函数来计算斐波那契数列。您只需要给出函数名和一行清晰的注释。
python
# 编写一个函数来计算第n个斐波那契数
def fibonacci(n):
# Copilot 建议开始
if n <= 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
# Copilot 建议结束
场景二:生成样板代码和重复性代码
在编写Web应用时,经常需要创建类似的API路由或组件。
javascript
// 使用Express.js,为一个用户API生成路由
// GET /users - 获取所有用户
app.get('/users', (req, res) => {
// Copilot 可能会建议从数据库获取用户的代码
User.find({}, (err, users) => {
if (err) return res.status(500).send(err);
res.json(users);
});
});
// POST /users - 创建新用户
app.post('/users', (req, res) => {
// Copilot 可能会建议创建用户的代码
const newUser = new User(req.body);
newUser.save((err, user) => {
if (err) return res.status(500).send(err);
res.status(201).json(user);
});
});
场景三:单元测试生成
Copilot可以极大地加速测试代码的编写。
python
# 有一个函数用于计算圆的面积
import math
def calculate_area(radius):
if radius < 0:
raise ValueError("Radius cannot be negative")
return math.pi * radius ** 2
# 现在为这个函数写单元测试
def test_calculate_area():
# Copilot 建议开始
# 测试正常情况
assert abs(calculate_area(1) - math.pi) < 1e-6
assert abs(calculate_area(2) - 4 * math.pi) < 1e-6
# 测试边界条件
assert calculate_area(0) == 0
# 测试异常情况
try:
calculate_area(-1)
assert False, "Expected ValueError"
except ValueError:
pass
# Copilot 建议结束
场景四:代码解释与文档生成
如果您面对一段难以理解的遗留代码,可以让Copilot为您解释。
python
# 解释以下代码的功能:
def mysterious_func(lst):
return [x for x in lst if x % 2 == 0]
# 在注释中向Copilot提问:What does this function do?
# Copilot 生成的解释:
# This function takes a list of numbers and returns a new list
# containing only the even numbers from the original list.
1.3 高级Prompt技巧与示例
要最大化利用Copilot,需要掌握“与AI对话”的艺术。以下是几种有效的Prompt模式:
1. 清晰描述意图
-
弱Prompt:
// sort the list -
强Prompt:
// 使用快速排序算法对整数列表进行升序排序
2. 提供输入输出示例(Few-Shot Learning)
python
# 将英文月份名转换为数字
# Example: "January" -> 1, "February" -> 2
def month_name_to_number(month_name):
months = {
"January": 1, "February": 2, "March": 3, "April": 4,
"May": 5, "June": 6, "July": 7, "August": 8,
"September": 9, "October": 10, "November": 11, "December": 12
}
return months.get(month_name, None)
3. 设定约束和条件
python
# 写一个SQL查询,获取2023年每个部门销售额前3的员工。 # 只使用窗口函数,不要使用子查询。
4. 链式思考(Step-by-Step)
python
# 实现一个函数,验证一个字符串是否是有效的括号对。
# 思路:
# 1. 使用一个栈来跟踪开括号。
# 2. 遍历字符串中的每个字符。
# 3. 如果遇到开括号('(', '[', '{'),将其压入栈。
# 4. 如果遇到闭括号,检查栈顶元素是否与之匹配。如果匹配则弹出,否则返回False。
# 5. 最后,如果栈为空,返回True,否则返回False。
def is_valid_parentheses(s):
stack = []
mapping = {')': '(', ']': '[', '}': '{'}
for char in s:
if char in mapping.values():
stack.append(char)
elif char in mapping.keys():
if not stack or stack[-1] != mapping[char]:
return False
stack.pop()
return not stack
1.4 优势、局限与最佳实践
优势:
-
效率提升:自动化样板代码和常见模式,让开发者专注于核心逻辑。
-
学习助手:帮助学习新语言、新框架的语法和最佳实践。
-
减少错误:提供经过验证的代码模式,减少拼写和语法错误。
-
促进探索:快速生成不同解决方案的原型,便于比较和选择。
局限与风险:
-
代码质量:可能生成看似正确但实则低效或有细微错误的代码。
-
安全性:可能建议包含已知安全漏洞的代码模式(如SQL注入风险)。
-
版权与许可:生成的代码可能与训练数据中的开源代码相似,引发许可问题。
-
依赖性:过度依赖可能导致开发者技能退化。
最佳实践:
-
充当代码审查员:永远不要盲目接受建议。将Copilot视为一个初级合伙人,您是其导师和审查者。
-
编写清晰的Prompt:意图越明确,生成的代码质量越高。
-
结合测试:为Copilot生成的代码编写全面的单元测试至关重要。
-
了解上下文限制:Copilot的上下文窗口有限,对于非常大型的文件,其建议可能不够准确。
-
保护敏感信息:避免在代码中泄露API密钥、密码等,因为它们会被发送到远程服务。
第二部分:数据标注工具 - AI模型的“燃料”工厂
高质量的标注数据是监督学习模型的基石。数据标注工具提供了一个高效的平台,用于对原始数据(如图像、文本、音频)进行标记和分类,从而创建训练数据集。
2.1 数据标注的核心流程
一个典型的数据标注项目管理流程涉及多个角色和阶段。
flowchart LR
A[项目管理员<br>定义任务] --> B[上传原始数据]
B --> C[设置标注规范<br>与指南]
C --> D[标注员<br>执行标注]
D --> E[质检员<br>审核质量]
E -- 不通过 --> D
E -- 通过 --> F[导出标注数据集]
F --> G[模型训练]
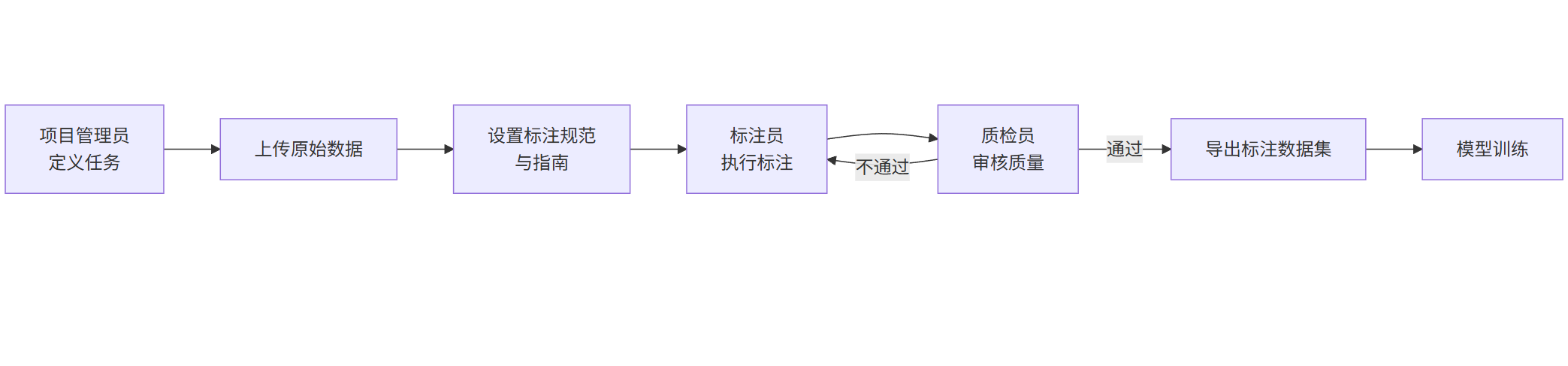
流程解读:
-
项目初始化:项目管理员定义任务目标(如目标检测、图像分类、文本命名实体识别等),并上传原始数据集。
-
制定规范:创建详细的标注指南,明确标注规则、标签定义和边界情况处理方法。这是保证数据质量的关键。
-
标注执行:标注员根据指南,使用工具提供的界面(如画框、划线、分类)对数据进行处理。
-
质量检查:质检员(可以是管理员或资深标注员)对已标注的数据进行抽样或全量检查,确保符合规范。不合格的样本将被发回重标。
-
数据集导出:标注完成后,数据可以导出为常见的格式(如COCO、Pascal VOC、JSON等),用于后续的模型训练。
2.2 主流标注类型与工具示例
1. 图像标注
-
边界框:用于目标检测,标记物体在图像中的位置。
-
工具界面描述:工具左侧是图像列表,中间是主画布。右侧是标签列表(如“人”、“车”、“狗”)。标注员在目标物体上拖动鼠标绘制矩形框,然后选择对应标签。
-
导出数据格式(JSON示例):
json
{ "image": "image_001.jpg", "width": 1920, "height": 1080, "annotations": [ { "label": "person", "bbox": [x, y, width, height], // [100, 200, 50, 150] "confidence": 1.0 }, { "label": "car", "bbox": [500, 300, 120, 80], "confidence": 1.0 } ] }
-
-
多边形分割:用于图像分割,精确勾勒物体的轮廓。
-
语义分割:为图像中的每一个像素分配一个类别标签。
2. 文本标注
-
命名实体识别:标识文本中的实体,如人名、地点、组织。
-
文本示例:
[PER 约翰]在[ORG 苹果公司]工作,该公司总部位于[LOC 加利福尼亚州]的[LOC 库比蒂诺]。
-
-
文本分类:为整个文档或段落分配一个类别标签(如情感分析:正面/负面/中性)。
-
关系抽取:识别实体之间的关系。
3. 音频与视频标注
-
语音转文本:将语音内容转录为文字。
-
事件标注:在视频的时间线上标记特定事件发生的时间点。
2.3 自动化与AI辅助标注
现代数据标注平台越来越多地集成AI模型来提升标注效率,这被称为“人机回环”模式。
原理:
-
先用一小部分人工标注的数据训练一个初始模型(预标注模型)。
-
用这个模型对未标注的数据进行预测,生成初步的标注结果。
-
标注员只需对模型的预测结果进行修正和确认,而不是从零开始。
-
修正后的高质量数据再用于重新训练和优化模型,形成闭环。
代码示例:使用预训练模型进行辅助标注(伪代码)
假设我们使用一个开源的图像检测模型YOLO来辅助标注。
python
# 伪代码:AI辅助标注流程
from yolov5 import YOLOv5Model # 假设的YOLO库
class AIAssistedLabeling:
def __init__(self, model_path):
self.model = YOLOv5Model.load(model_path)
def pre_annotate(self, image_path):
"""使用模型对图像进行预标注"""
# 模型推理
predictions = self.model.predict(image_path)
# 将预测结果转换为标注工具的格式
annotations = []
for pred in predictions:
annotation = {
'label': pred['class_name'],
'bbox': [pred['x'], pred['y'], pred['width'], pred['height']],
'confidence': pred['confidence']
}
annotations.append(annotation)
return annotations
# 在标注工具中集成
labeling_tool = DataLabelingTool()
ai_helper = AIAssistedLabeling('yolov5s.pt')
for image in unlabeled_images:
# 获取AI预标注结果
pre_annotations = ai_helper.pre_annotate(image.path)
# 在UI中显示给标注员,标注员进行修正
labeling_tool.show_suggestions(image, pre_annotations)
# 标注员修正后,保存最终结果
final_annotations = labeling_tool.get_corrected_annotations()
save_to_dataset(image, final_annotations)
2.4 数据标注项目的管理要点
-
标注指南:必须清晰、无歧义,并包含大量正例和反例。
-
质量度量:使用一致率来衡量不同标注员对同一样本标注结果的一致性。一致性低通常意味着指南不清晰。
-
迭代优化:数据标注是一个迭代过程。在训练模型后,可能会发现模型在特定类别上表现不佳,这就需要回头补充或修正该类别的数据。
第三部分:模型训练平台 - 规模化机器学习的心脏
模型训练平台(MLOps平台)为数据科学家和工程师提供了端到端的机器学习生命周期管理能力,涵盖了从数据准备、模型训练、评估到部署和监控的全过程。
3.1 平台核心架构与工作流
以AWS SageMaker为例,一个典型的平台化训练流程如下:
flowchart TB
A[数据准备与特征存储] --> B[选择与配置算法]
B --> C[进行模型训练<br>超参数调优]
C --> D[模型评估与验证]
D -- 不通过 --> B
D -- 通过 --> E[模型注册与版本管理]
E --> F[模型部署至端点]
F --> G[监控与推理服务]
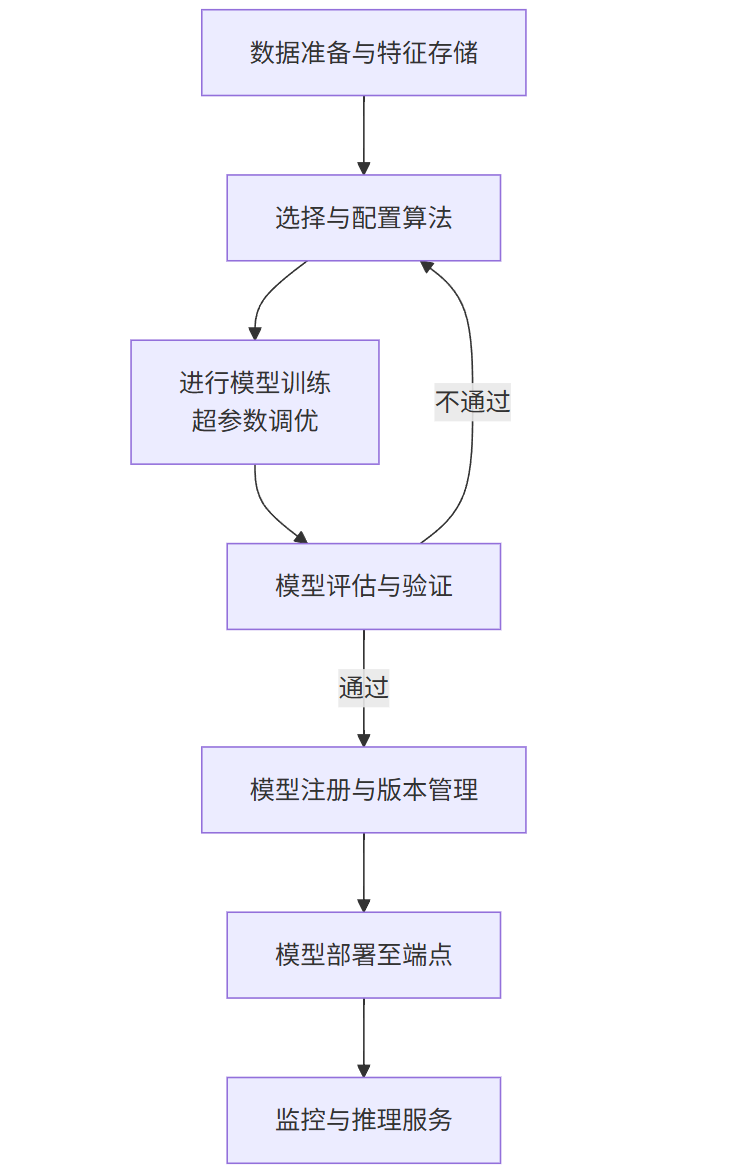
核心组件解读:
-
数据处理与管理:平台提供Notebook实例、数据处理作业和特征存储,用于数据探索、清洗和生成可复用的特征。
-
算法与框架:内置了大量优化的算法(XGBoost, BlazingText等),并支持自带算法和自定义容器,兼容TensorFlow, PyTorch等主流框架。
-
训练与调优:通过配置计算资源(GPU/CPU实例),以分布式的方式运行训练作业。集成自动超参数调优,寻找最优的模型参数组合。
-
模型管理:训练好的模型被注册到模型库中,带有版本、元数据和沿袭信息,实现模型的可追溯性。
-
部署与推理:一键将模型部署为可扩展的RESTful API端点,支持实时推理和批量推理。
-
监控与治理:监控端点的性能、延迟和资源利用率,并记录推理日志,用于模型漂移检测和审计。
3.2 代码实战:在云平台上训练一个文本分类模型
我们将以Google Cloud Vertex AI为例,展示一个完整的文本分类模型训练和部署流程。
步骤一:准备和上传数据
假设我们有一个CSV文件 news_classification.csv,包含 article_text 和 category 两列。
python
# 在Vertex AI Workbench Notebook中
import pandas as pd
from sklearn.model_selection import train_test_split
from google.cloud import aiplatform
# 加载数据
df = pd.read_csv('news_classification.csv')
train_df, eval_df = train_test_split(df, test_size=0.2, random_state=42)
# 上传到Google Cloud Storage
train_df.to_csv('gs://my-bucket/data/train.csv', index=False)
eval_df.to_csv('gs://my-bucket/data/eval.csv', index=False)
train_data_uri = 'gs://my-bucket/data/train.csv'
eval_data_uri = 'gs://my-bucket/data/eval.csv'
步骤二:创建自定义训练脚本(TensorFlow)
这是模型训练的核心逻辑,需要打包到容器中。
python
# task.py
import tensorflow as tf
from tensorflow.keras.layers import TextVectorization, Embedding, Dense, GlobalAveragePooling1D
import argparse
import os
def create_model(vocab_size, embedding_dim, sequence_length, num_classes):
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(sequence_length,), dtype=tf.int64),
Embedding(vocab_size, embedding_dim),
GlobalAveragePooling1D(),
Dense(64, activation='relu'),
Dense(num_classes, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
return model
def preprocess_data(texts, labels, vectorizer, max_length):
"""预处理文本数据"""
texts_vectorized = vectorizer(texts)
# 填充或截断到固定长度
texts_padded = tf.keras.preprocessing.sequence.pad_sequences(texts_vectorized, maxlen=max_length, padding='post', truncating='post')
return texts_padded, labels
def main(args):
# 加载数据
train_df = tf.data.experimental.make_csv_dataset(
args.train_data_uri,
batch_size=1024,
label_name='category'
).unbatch()
eval_df = tf.data.experimental.make_csv_dataset(
args.eval_data_uri,
batch_size=1024,
label_name='category'
).unbatch()
# 准备文本向量化层
vectorizer = TextVectorization(
max_tokens=args.vocab_size,
output_sequence_length=args.sequence_length
)
# 适配训练文本数据
train_texts = train_df.map(lambda x, y: x['article_text'])
vectorizer.adapt(train_texts)
# 预处理数据集
train_data = train_df.map(lambda x, y: (vectorizer(x['article_text']), y))
eval_data = eval_df.map(lambda x, y: (vectorizer(x['article_text']), y))
# 创建模型
model = create_model(
vocab_size=args.vocab_size,
embedding_dim=args.embedding_dim,
sequence_length=args.sequence_length,
num_classes=args.num_classes
)
# 设置回调
callbacks = [
tf.keras.callbacks.ModelCheckpoint(
filepath=os.path.join(args.model_dir, 'checkpoint'),
save_best_only=True
),
tf.keras.callbacks.EarlyStopping(patience=3)
]
# 训练模型
history = model.fit(
train_data.batch(args.batch_size),
epochs=args.epochs,
validation_data=eval_data.batch(args.batch_size),
callbacks=callbacks
)
# 保存最终模型
model.save(os.path.join(args.model_dir, 'saved_model'))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--train-data-uri', type=str)
parser.add_argument('--eval-data-uri', type=str)
parser.add_argument('--model-dir', type=str)
parser.add_argument('--vocab-size', type=int, default=10000)
parser.add_argument('--embedding-dim', type=int, default=128)
parser.add_argument('--sequence-length', type=int, default=500)
parser.add_argument('--num-classes', type=int, default=5)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--epochs', type=int, default=10)
args = parser.parse_args()
main(args)
步骤三:使用Vertex AI SDK提交训练作业
python
# submit_job.py
from google.cloud import aiplatform
# 初始化Vertex AI
aiplatform.init(project="my-project", location="us-central1", staging_bucket="gs://my-bucket")
# 配置训练任务
job = aiplatform.CustomTrainingJob(
display_name="news-classification-custom",
script_path="task.py", # 上一步的脚本
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-gpu.2-12:latest", # TensorFlow基础镜像
requirements=[], # 如有额外依赖,在此列出
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-12:latest"
)
# 运行训练任务
model = job.run(
model_display_name="news-classification-model",
args=[
'--train-data-uri=gs://my-bucket/data/train.csv',
'--eval-data-uri=gs://my-bucket/data/eval.csv',
'--vocab-size=10000',
'--epochs=10'
],
replica_count=1,
machine_type="n1-standard-4",
accelerator_type="NVIDIA_TESLA_T4", # 使用GPU加速
accelerator_count=1
)
print(f"训练完成后模型将存储在: {model.resource_name}")
步骤四:部署模型并在线预测
训练完成后,可以在UI或通过代码部署模型。
python
# deploy_and_predict.py
from google.cloud import aiplatform
# 获取已训练的模型
model = aiplatform.Model(model_name="projects/my-project/locations/us-central1/models/MODEL_ID")
# 部署到端点
endpoint = model.deploy(
deployed_model_display_name="news-classification-endpoint",
machine_type="n1-standard-2",
min_replica_count=1,
max_replica_count=3 # 自动缩放
)
# 进行在线预测
instances = [
{"article_text": "The stock market reached a new all-time high today after the central bank announced new economic policies."},
{"article_text": "The local football team won the national championship in a stunning victory last night."}
]
prediction = endpoint.predict(instances=instances)
print(prediction.predictions) # 输出预测的类别概率
3.3 核心优势与选型考量
平台的核心优势:
-
可扩展性:轻松利用数百个GPU进行分布式训练,处理TB级数据。
-
可复现性:通过容器化和版本控制,确保任何实验都可以被精确复现。
-
自动化:自动化训练、调参和部署流程,实现MLOps。
-
成本优化:按需使用资源,支持竞价实例,并提供成本管理工具。
-
生产就绪:内置了高可用、自动缩放、监控和安全的部署方案。
选型考量因素:
-
云服务商锁定:AWS SageMaker, GCP Vertex AI, Azure Machine Learning各有优劣,需考虑与现有云环境的整合。
-
成本模型:比较计算资源、存储和API调用的定价。
-
对开源的支持:是否支持原生PyTorch, TensorFlow, Scikit-learn,以及自定义容器的灵活性。
-
特性成熟度:不同平台在特征工程、模型监控、工作流编排等方面的能力有差异。
-
学习曲线:平台的抽象程度和易用性。
总结与展望
我们系统地探讨了现代AI工程实践中三类不可或缺的工具。
-
智能编码工具(如GitHub Copilot) 作为开发者的“副驾驶”,正在从根本上改变我们编写软件的方式,将我们从重复性劳动中解放出来,激发创造力。
-
数据标注工具 是连接现实世界与AI模型的桥梁。随着AI辅助标注的成熟,数据标注的效率和质量正在不断提升,解决了AI项目中最耗时、最昂贵的瓶颈问题。
-
模型训练平台(MLOps平台) 则将机器学习从散乱的手工作坊模式,升级为标准化、自动化、规模化的工业化生产流水线。它确保了从实验到生产之路的顺畅、可靠和高效。
这三类工具共同构成了一个紧密协作的生态系统:Copilot帮助开发者更快地构建数据标注流水线和模型训练脚本;数据标注工具为模型平台提供高质量的燃料;而模型平台训练出的强大模型,又可以反过来赋能数据标注工具和未来的AI编程助手,使其更加智能。
未来展望:
-
深度融合:我们将会看到这些工具之间更深的集成。例如,在IDE中直接调用模型平台的API进行实验,或者在标注工具中直接使用平台上最新训练的模型进行预标注。
-
代理(Agent)的崛起:未来的AI工具将不再是简单的助手,而是能够自主完成复杂任务的“代理”。例如,一个AI代理可以理解“优化网站登录转化率”这样的高级目标,然后自动进行数据收集、特征工程、模型训练、A/B测试部署和效果分析。
-
低代码/无代码AI:这些平台正使得AI能力民主化,让非专家用户也能通过图形化界面构建和部署AI解决方案。
-
负责任AI的集成:公平性、可解释性、透明度和隐私保护将不再是事后考虑,而是作为核心功能被内置到这些工具和平台中。
AI工具的革命才刚刚开始。拥抱这些工具,深入理解其原理并掌握其应用,将是所有技术人员在智能化浪潮中保持竞争力的关键。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)