GraphLAMA复现
最近主播在学着做实验室图语言模型(GLM)的时候,读到了一篇非常亮眼的工作——。它巧妙地解决了当前图语言模型在"低资源场景"下适配难的问题,效果拔群,主播立马有了"复现一下"的想法。然而,主播看到原论文的实验环境(3块A800)时,再看看主播现在能用的…3090,不禁倒吸一口凉气。这篇博客,主播想和大家分享一下如何从理解 GraphLAMA 的原理,到最终在有限的硬件资源上成功跑通它的全过程。如果
在3090上复现GraphLAMA的踩坑与优化
最近主播在学着做实验室图语言模型(GLM)的时候,读到了一篇非常亮眼的工作——GraphLAMA。它巧妙地解决了当前图语言模型在"低资源场景"下适配难的问题,效果拔群,主播立马有了"复现一下"的想法。
然而,主播看到原论文的实验环境(3块A800)时,再看看主播现在能用的…3090,不禁倒吸一口凉气。这篇博客,主播想和大家分享一下如何从理解 GraphLAMA 的原理,到最终在有限的硬件资源上成功跑通它的全过程。
如果你也对 GraphLAMA 感兴趣,或者正在为如何训练大模型而烦恼,希望主播的经验能给你带来一些启发。
最终,主播把整个复现和适配的代码都开源了,欢迎大家 star 和交流:https://github.com/gdshjzm/GraphLAMA_ggl,这是北邮GAMMALAB的一个实验项目,网址在这里
GraphLAMA 原理趣谈:它解决了什么"痛点"?
在深入实践之前,我们先花点时间聊聊 GraphLAMA 到底有多酷。
目前的图语言模型(GLMs)主要有两种玩法:
- 上下文学习: 就像开卷考试,你把几个例子(包含图结构和文本)一股脑塞进提示词里,让大模型(LLM)照着学。缺点很明显:性能一般,而且例子一多,上下文窗口就爆了,推理又慢又贵
- 指令微调: 这就像是题海战术,用海量的标注数据去微调整个模型。效果是好,但标注数据的成本太高,在现实世界的很多场景里根本不现实
GraphLAMA 则提供了一种"中庸之道"。它的核心思想是:我只用极少量的数据,对模型里一小部分"图专属"的参数进行微调,既能达到好效果,又省钱省力。
这个过程分为"预训练-适应-推理"三步曲。
它的框架里有几个很有意思的设计:
- 图编码器 (GNN): 先用一个图神经网络(比如 GAT)把图的结构信息提取成特征向量 (embedding)。
- 跳数编码 (Hop Encoding): 为了让模型知道节点离目标节点有多远,它给不同"跳数"(距离)的邻居加上了位置编码,这能更好地保留子图结构信息。
- 双门控机制 (Gating Mechanism): 这是我觉得最巧妙的地方。它设计了两个"门"—— 任务相关门 (Task-Related Gate) 和 任务无关门 (Task-Invariant Gate)。前者根据你的具体任务(比如节点分类)来筛选有用的特征;后者则保留那些通用的、与任务无关的图结构特征。
- 投影器 (Projector): 最后,通过一个简单的线性层,把处理好的图特征"翻译"成 LLM 能听懂的语言(token),然后和文本信息一起喂给 LLM。
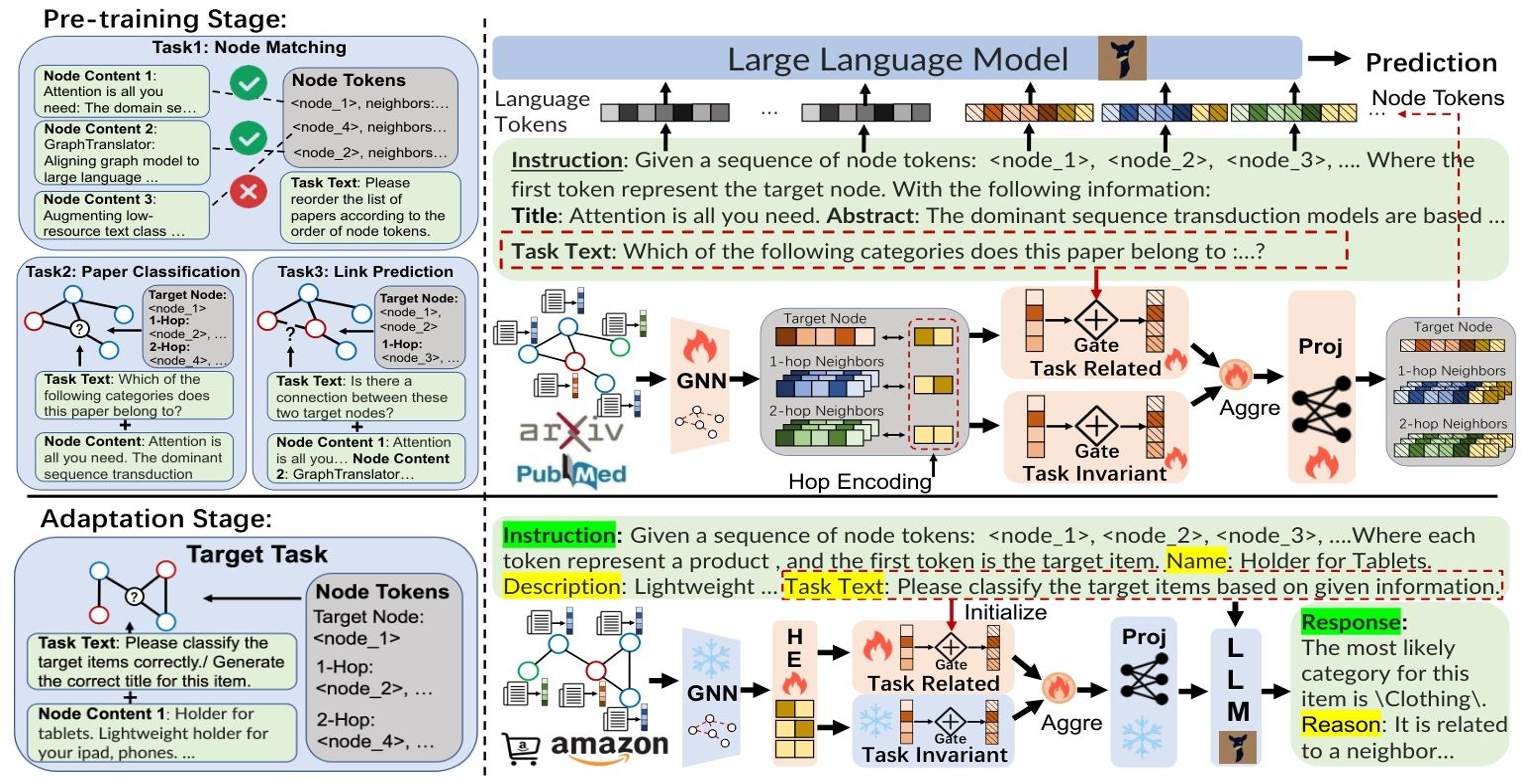
`在"适应"阶段,GraphLAMA 会冻结掉庞大的 LLM 和 GNN 主体,只去微调跳数编码、任务相关门等极少数参数。这使得整个微调过程的参数量极小,仅为 7B LLM 的万分之一,适配一个任务只需要 3MB 存储!
复现之旅:直面 7B 模型的显存挑战
理论搞清楚了,接下来就是动手环节。这也是整个过程中最"酸爽"的部分。
硬件鸿沟与显存"拦路虎"
原论文用的是 NVIDIA A800,而我这边主要是实验室的 NVIDIA 3090。一个 7B 的模型(Vicuna-7B),即使用半精度(FP16)加载,也需要大约 14GB 显存。但这仅仅是模型权重的静态占用。
在训练过程中,显存的消耗大头还包括:
- 梯度 (Gradients): 每个需要训练的参数都会产生一个梯度,FP16 下也需要 14GB。
- 优化器状态 (Optimizer State): 如果使用 Adam 这样的优化器,它会为每个参数保存动量和方差,这部分的显存消耗是参数量的两倍,也就是 28GB。
三者相加,FP16 训练至少需要 14 + 14 + 28 = 56GB 的显存。这对于单张 24GB 的 3090 来说,简直是天方夜谭。
我的显存优化"组合拳"
面对这个不可能完成的任务,我祭出了一套"极限优化"的组合拳,核心武器就是 DeepSpeed ZeRO-3。
- 精度转换 (FP16): 这是最基础的一步,直接将模型从 FP32 切换到 FP16,所有显存占用减半。
- CPU Offload (CPU 卸载): 这是 DeepSpeed ZeRO-3 的精髓。它允许你将不立即参与计算的参数、梯度和优化器状态从 GPU 显存中"卸载"到内存(CPU)里,在需要时再加载回来。
- 梯度累积 (Gradient Accumulation): 通过累积多个小批次的梯度,然后一次性更新模型。这相当于用时间换空间,可以显著降低单次迭代的显存峰值。
- 分布式训练: 我最终使用了两块 3090 进行分布式训练,进一步分摊了显存压力,也加速了训练进程。
我尝试了两种不同的 DeepSpeed 配置方案:
- 方案一:极致优化。将优化器和梯度全部卸载到 CPU。这种配置下,单卡显存占用可以被压到惊人的 7GB 左右。但缺点是 CPU 和 GPU 之间的数据交换会非常频繁,导致训练速度很慢,预计第一阶段要花 13-14 天。
- 方案二:均衡优化。只将优化器状态卸载到 CPU,梯度依然保留在 GPU 中。这种方案下单卡显存占用在 19-20GB 左右,正好在 3090 的承受范围内,而且速度快得多,预计 3-4 天就能完成。
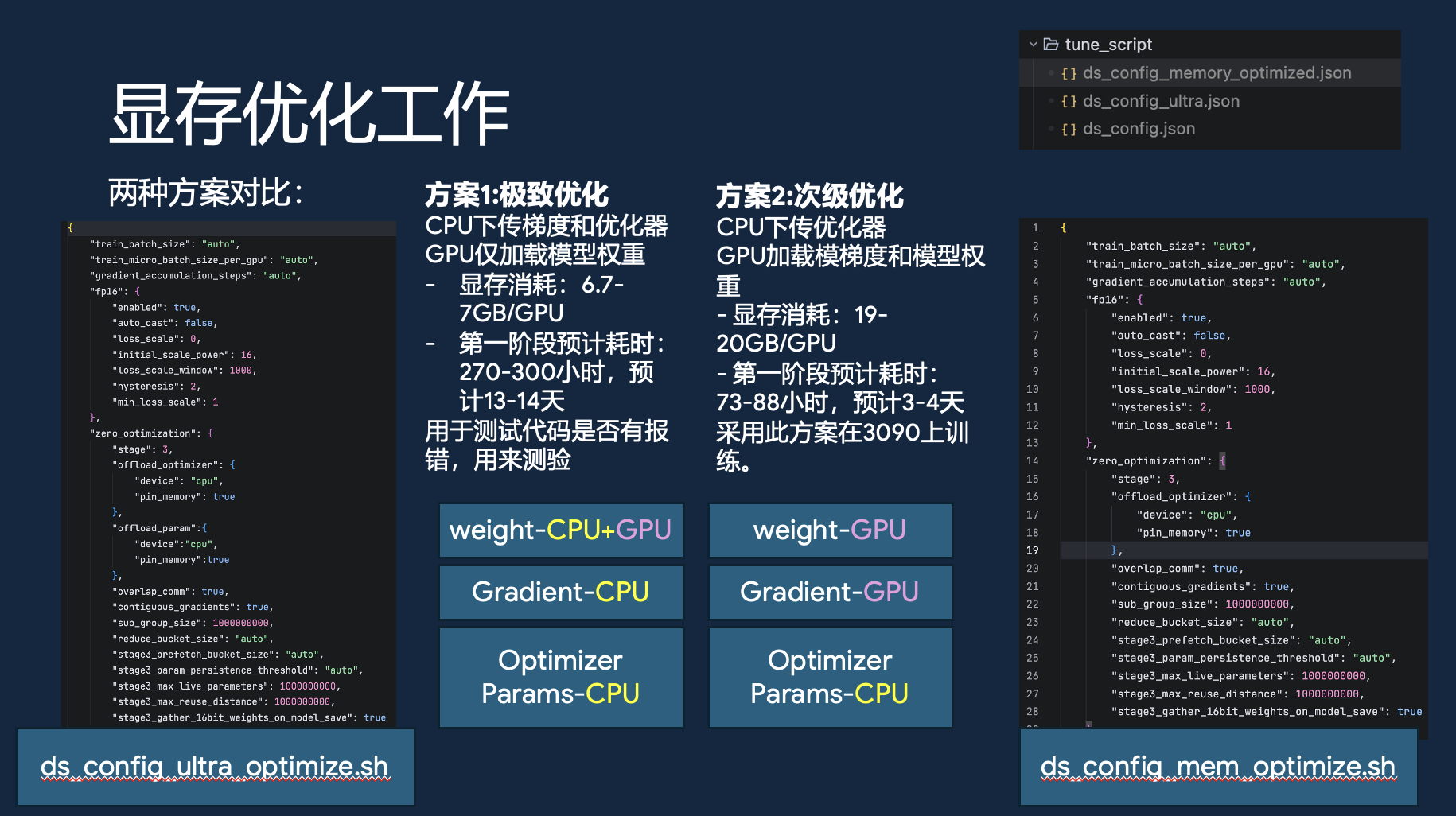
最终主播选择了方案二,这样时间耗得也不算久,内存也不算多,deepspeed还是挺强大。
代码适配:从 PyG 到 GammaGL
原项目的代码实现依赖 PyTorch Geometric (PyG)。为了更好地与实验室的技术栈对齐,主播进行了一项额外的改造工作:将所有的 PyG 代码替换为他们自行研发的GammaGL框架。
幸运的是,这两个框架的 API 接口高度相似,整个迁移过程比预想的要顺利。主要的不同点在于图对象的定义(PyG 的 Data vs GammaGL 的 Graph)和一些设备指定的方法上,但都很快解决了。
训练启动与未来展望
经过一番折腾,环境配置完毕,数据下载就绪,优化脚本也写好了。主播满怀期待地敲下了运行命令,看着日志滚动,GPU 占用率稳定在了 18642MB 左右,没有再报出可恶的 CUDA out of memory。那一刻,成就感满满!
目前,模型正在服务器上稳定地进行第一阶段的预训练。虽然最终的测试结果还需要几天时间才能出炉,但能够成功地在消费级显卡上驯服 7B 规模的图语言模型,本身就是一次巨大的成功。
再次附上我的项目地址,希望这份工作能帮助到社区里更多对 GLM 感兴趣的朋友们:
https://github.com/gdshjzm/GraphLAMA_ggl
感谢阅读,最后记得给主播一个赞和关注哦~各位家人们,实时分享优秀论文和技术栈,也欢迎在评论区交流讨论。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)