AAAI 2026 Oral | 机器人也能“看人学活”?一次示范就能学会新任务!
复旦大学团队提出Human2Robot框架,通过精准同步的人机视频数据集H&R(2600段VR操控视频)和条件视频生成方法,实现了机器人从人类示范中学习细粒度动作。该方法采用视频预测模型提取隐式动力学表征,结合解耦动作解码器,在真实任务中展现出优异的单样本泛化能力,能够处理新位置、新物体甚至全新任务类别。实验表明,该框架在已见任务上成功率领先基线10-20%,并能有效适应六类泛化场景,突破
本文的作者来自复旦大学。第一作者谢思程是来自复旦大学的博士生,研究方向聚焦于模仿学习、遥操作和 3d 重建。通讯作者为复旦大学吴祖煊教授。
从人类示范中蒸馏知识是让机器人学习和执行任务的一种极具潜力的方式。现有方法通常依赖粗对齐的视频对,因此往往只能学习到全局或任务级别的特征。结果是,它们常常忽略复杂操作和泛化到新任务所需的细粒度帧级动态信息。这一局限性源于数据集不足与其催生的方法之间的恶性循环。
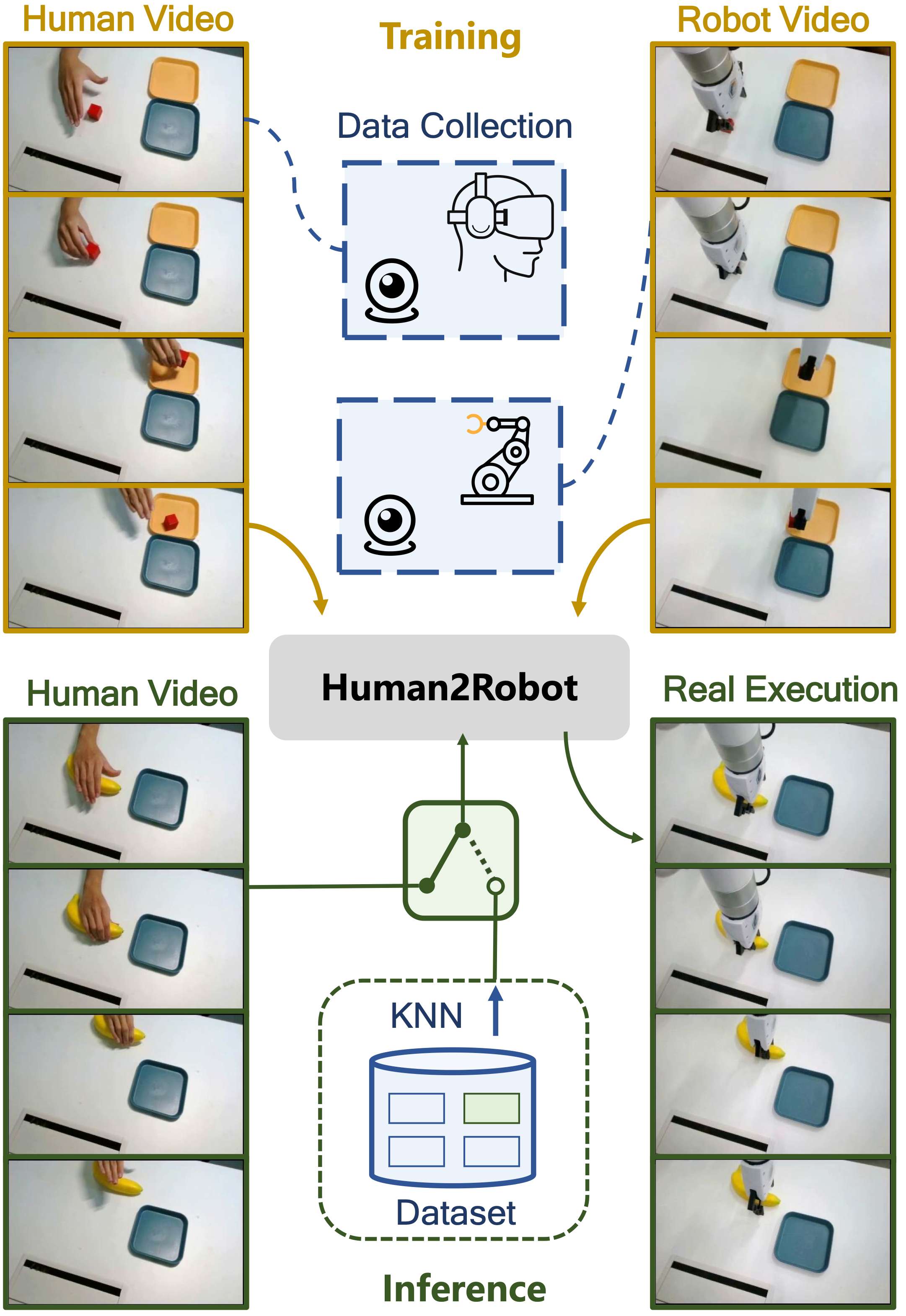
为打破这一循环,复旦大学和上海创智学院提出了一种范式转变:将细粒度的人机动作对齐视为一个条件视频生成问题。为此,他们首先引入 H&R —— 一个全新的第三人称数据集,包含 2,600 段通过 VR 远程操控系统采集的、精准同步的人类和机器人动作视频。随后,他们提出了 Human2Robot 框架,以充分利用这些数据。Human2Robot 通过视频预测模型(Video Prediction Model)在生成机器人视频的过程中,从人类输入中学习丰富而隐式的机器人动力学表征,进而指导一个解耦的动作解码器。
真实世界实验表明,他们的方法不仅在已见任务上取得了优异性能,还能够实现对新的位置、物体、实例,甚至全新任务类别的一次性泛化(one-shot generalization),对于一个没见过的任务,只需要给一段人类完成任务的视频,即可让机器人完成这个任务。

- 论文标题:Human2Robot: Learning Robot Actions from Paired Human-Robot Videos
- 论文链接:https://arxiv.org/abs/2502.16587
- 代码链接:https://github.com/SII-dannyXSC/Human2Robot
任务概览
虽然现有模型在“见过的任务”上表现很好,但一旦面对人类展示的“从未见过的新任务”,就直接“懵了”。原因在于现在主流的方法,都依赖非常粗糙的人机视频对齐方式来学习:机器人只能大概知道“人在干什么”,却不知道人手到底怎么动。数据不够精细,模型自然学不到关键动作,它们只会抓一些模糊的“大概意思”。比如很多方法会把整段视频压缩成一个固定长度的向量,细节全没了。这使得模型无法理解动作之间的微小差别,也就无法学会真正的泛化能力。
我们提出了一个全新的想法:让机器人“看着人类做”,然后“脑补出自己应该怎么做”──直接生成一段对应的机器人操作视频。传统方法只会判断人类和机器人的动作大不相同,或只理解最终目标是什么,但不知道“这个动作到底是怎么一步步做出来的”。而我们的方法要求模型逐帧预测机器人下一步如何移动。这样,模型就会在生成过程中学会动作细节、理解操作逻辑,真正掌握“怎么做”,而不是只知道“做什么”。
但是,要教机器人学会每一个细微动作,必须有精准对齐的人类示范数据,但人工逐帧标注代价太大。所以我们选择了更聪明的方式 :用 VR 远程操控机器人,让机器人直接跟着人的手同步动作。通过改进坐标系匹配,我们让“人手怎么动,机器人就怎么动”变得丝滑顺畅。最终,我们收集了一个全新的大规模第三视角数据集 H&R: 2600 段人手与机械臂的完美同步视频, 4 类基础任务 + 6 类复杂长程任务。
技术方法
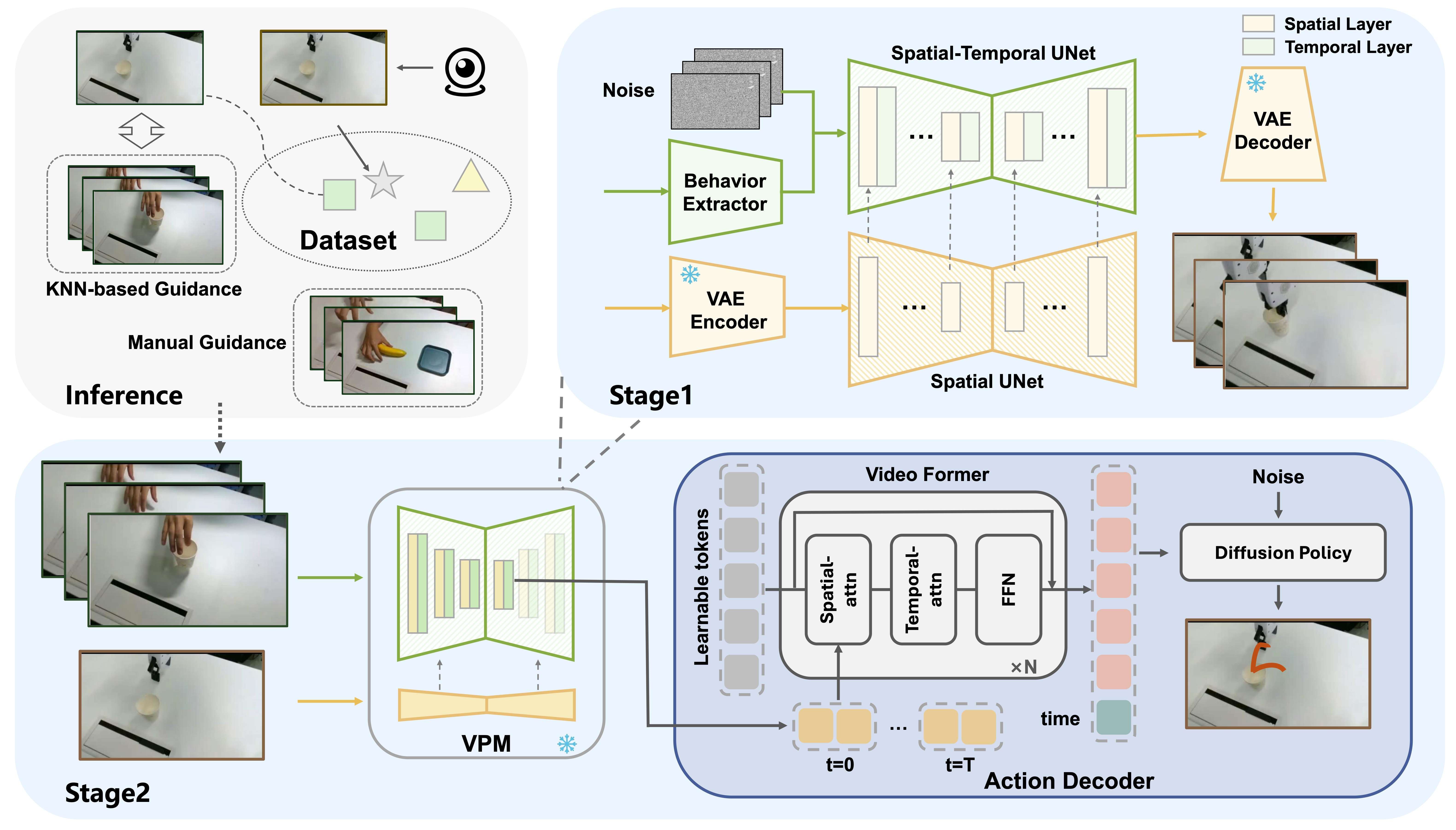
我们的方法:Human2Robot —— 让机器人“看人学动作”
我们提出了一个两阶段的方法,让机器人先学会脑补视频,再学会执行动作。
第一阶段:视频预测(VPM)
机器人看到人类在操作时,我们让模型直接生成一段机器人应该怎么动的视频。
- Spatial UNet:负责“看懂机器人”
捕捉机械臂形状、手部动作等关键信息 - Spatial-Temporal UNet:负责“理解动作连贯性”
学会逐帧预测动作的时间关系 - Behavior Extractor:负责“看懂人类”
提取人手的位置、速度、方向等运动线索
总结一下:
人怎么动 → 模型学动作规律 → 预测机器人下一步怎么动
我们先训练它学会生成单帧,然后再进阶训练整个视频,使它掌握完整的动作演化过程。
第二阶段:动作解码(Action Decoder)
虽然模型能生成视频,但视频渲染太慢,不适合实时机器人操作。于是我们在动作解码阶段只取一次去噪后的中间特征。这些特征已包含:
- 机械臂下一步的位置
- 动作趋势
- 物体相对关系
我们把 VPM 当作“视觉大脑”,冻结参数,然后训练一个动作解码器输出机器人到底怎么动(关节角/位姿)
KNN 推断:机器人自己认任务
执行任务时,模型无需你喂视频。它会:
- 观察环境首帧
- 根据特征使用 knn找最像的训练任务
- 自动调用对应的人类示范来执行
机器人不仅会跟做,还会自己“判断是在做什么任务”。
实验
主要结果
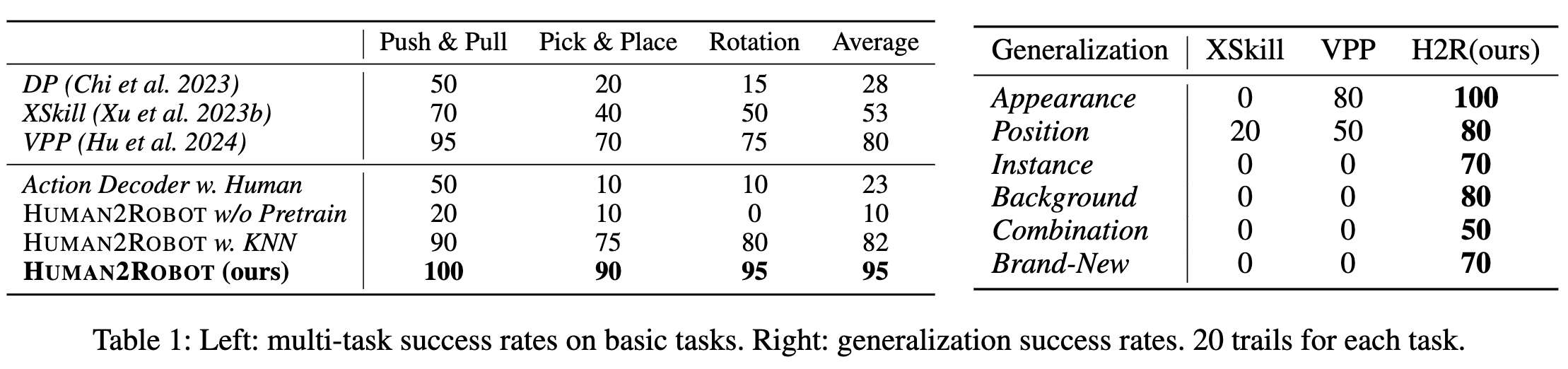
对比现有基线方法,在in domain的任务上,DP、XSkill和 VPP 等受限于信息有限的输入,导致性能波动较大,平均成功率比较低。而 Human2Robot 的依赖包含更多细节的人类视频条件,因此 Human2Robot 保持超过 10–20 个百分点的优势。总体而言,Human2Robot 在所有任务上均取得最高成功率,验证了基于人类视频条件与视频生成预训练相结合的有效性。
引入 KNN 的 Human2Robot 在所有任务上仍优于各基线方法,表明即使没有直接示范输入,KNN+Human2Robot 依旧能够保持较强的任务执行能力。相比完整版本的 Human2Robot,KNN 策略仅带来约 10–20% 的成功率下降,处于可接受范围内。整体来看,这些结果表明 Human2Robot 在已见任务中具有高效且可靠的性能。
预测表示的可视化

由于我们将视频预测模型重用于视觉编码器,并通过单次前向传播提取预测特征,因此我们进一步评估了这些特征的质量。如图所示,我们将真实未来帧与 1-step 预测结果和 30-step 去噪结果进行可视化对比。结果表明,仅经过一步去噪的预测已包含足够的动作信息,可有效支持后续的动作规划。此外,30-step 去噪结果与真实机器人视频高度一致,进一步验证了所提出 VPM 架构的有效性。
消融研究
VPM的有效性
由于 H&R 数据集中包含人类与机器人动作的配对视频,我们首先测试了直接从人类视频预测机器人动作的方式(Action Decoder w. Human)。具体而言,我们使用人类视频 o 0 : T h o_{0:T}^h o0:Th 作为条件输入,预测机器人动作 a 0 : T a_{0:T} a0:T。然而,该方法在实验中表现不佳:动作执行抖动明显,对抓取等关键行为不敏感,平均成功率仅为 23%。这说明仅依靠人类视频推断机器人动作映射较为困难,而 Human2Robot 通过视频生成过程学习到更可靠的人机动作对应,为后续动作解码器提供了有效运动先验。
生成预训练的有效性
为验证视频生成预训练的必要性,我们设计了 Human2Robot w/o Pretraining,将 VPM 初始化为未训练状态并冻结,仅训练动作解码器。结果显示该方法几乎无法完成任务,最简单的推拉任务成功率仅为 20%,抓取放置任务仅为 10%。我们认为,直接使用 Stable Diffusion 初始化无法提取任务相关特征,反而引入额外噪声,影响策略性能。相比之下,完整的 Human2Robot 显著优于该变体,证明视频预训练对于建立动作先验至关重要。
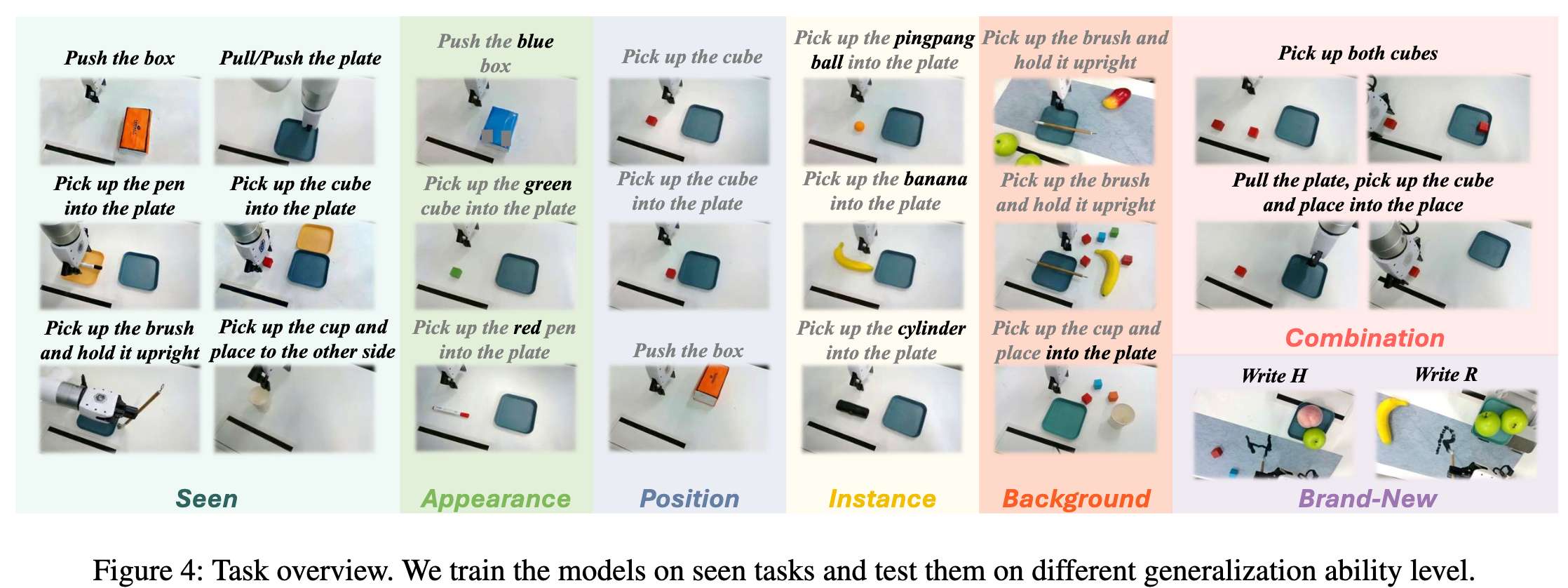
泛化性效果
在六类泛化设置中,Human2Robot(ours) 在位置、外观、实例与背景变化下均保持领先,并能完成组合任务与全新任务,而 XSkill 与 VPP 在后两者上均失败。我们认为优势来自:
(1) H&R 提供的人机配对数据建立了明确动作对应关系;
(2) 视频条件提供细粒度动态信息,使策略具备跨任务泛化能力。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)