【AI论文】实时交互式视频生成的自回归对抗后训练
摘要:本研究提出自回归对抗后训练(AAPT)方法,将预训练视频扩散模型转化为实时交互式视频生成器。通过架构转换(采用因果注意力)和对抗训练策略,模型可实现24fps实时生成(736x416分辨率单H100,或1280x720分辨率8xH100),最长支持1分钟视频生成。实验显示其性能优于现有方法,但存在快速动作处理、长程记忆等局限。未来将优化架构、物理一致性和人类偏好对齐,扩展实时交互应用场景。论
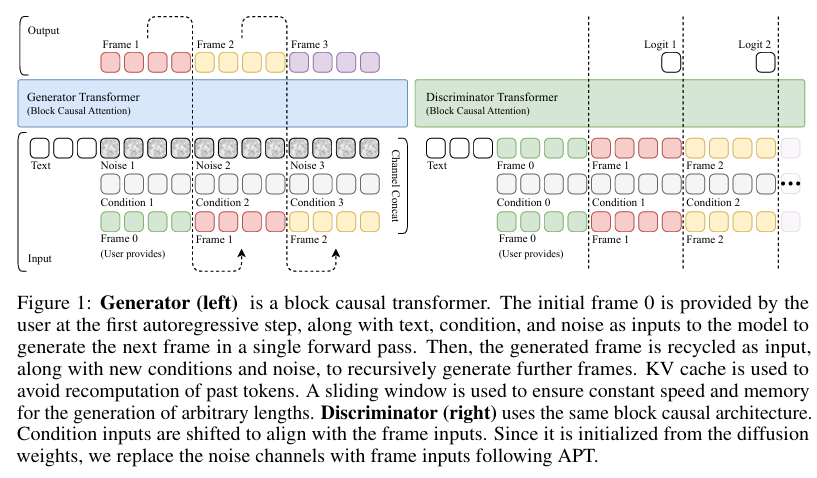
摘要:现有的大规模视频生成模型计算量很大,阻碍了其在实时和交互式应用中的采用。 在这项工作中,我们提出了自回归对抗后训练(AAPT),将预先训练的潜在视频扩散模型转化为实时、交互式的视频生成器。 我们的模型通过一次神经函数评估(1NFE)来自动生成一个潜在框架。 该模型可以实时将结果流式传输给用户,并接收交互式响应作为控件,以生成下一个潜在帧。 与现有方法不同,我们的方法探索了对抗训练作为自回归生成的有效范例。 这不仅使我们能够设计一个在充分利用KV缓存的同时更高效的一步生成架构,而且能够以一种学生强制的方式训练模型,这被证明在长时间视频生成过程中有效地减少了错误积累。 我们的实验证明,我们的8B模型在单个H100上以736x416分辨率或8xH100上以1280x720分辨率实现实时、24fps、长达一分钟(1440帧)的流媒体视频生成。 访问我们的研究网站Seaweed APT2。Huggingface链接:Paper page,论文链接:2506.09350
研究背景和目的
研究背景:
近年来,随着深度学习技术的快速发展,视频生成领域取得了显著进展,特别是在基于基础模型(Foundation Models)的视频生成方面。这些模型能够支持多种强大的应用,如文本到视频的生成、图像到视频的合成,以及基于多模态信号的可控视频创作。然而,尽管这些模型在离线视频合成方面表现出色,但在实时和交互式视频生成应用中,其计算需求过高,导致难以广泛应用。
现有的视频生成模型,尤其是基于扩散模型(Diffusion Models)的方法,虽然能够生成高质量的视频,但其迭代生成过程缓慢且计算成本高昂。例如,生成几秒钟的高分辨率视频可能需要数分钟时间。为了减少推理成本,研究者们提出了多种方法,如更高效的公式、采样器、架构、缓存和蒸馏等。然而,这些方法在实时性和交互性方面仍存在不足。
与此同时,基于 token 的自回归生成方法(如大型语言模型 LLMs)提供了一种替代方案。这些模型通过将视频生成视为下一个 token 的预测任务,可以有效地利用 KV 缓存来提高生成效率。然而,逐 token 解码的方式限制了并行性,使得难以满足实时需求。
研究目的:
本研究旨在解决实时交互式视频生成中的三个核心挑战:(1)实现实时视频生成吞吐量;(2)保持交互信号的低延迟;(3)支持长时间因果断视频生成。为此,研究者们探索了对抗训练(Adversarial Training)作为一种新的范式,并提出了自回归对抗后训练(Autoregressive Adversarial Post-Training, AAPT)方法,以将预训练的视频扩散变压器转化为高效的自回归生成器。
研究方法
方法概述:
本研究提出了 AAPT 方法,通过以下步骤将预训练的潜在视频扩散模型转化为实时、交互式的视频生成器:
-
架构转换:将双向扩散变压器(DiT)架构转换为因果自回归架构,通过用块因果注意力(Block Causal Attention)替换全注意力机制,使模型能够基于之前的生成结果递归地生成下一个潜在帧。
-
训练过程:
- 扩散适应:使用教师强制(Teacher-Forcing)训练方式,对预训练权重进行微调,以适应新的因果架构。
- 一致性蒸馏:在对抗训练之前应用一致性蒸馏,以加速收敛。
- 对抗训练:扩展对抗训练到自回归设置,改进鉴别器设计、训练策略和损失目标。采用学生强制(Student-Forcing)方式,在训练过程中使用实际生成的结果作为下一个自回归步骤的输入,以减少长时间视频生成中的错误积累。
-
长视频训练:提出了一种长视频训练技术,通过让生成器生成长视频并分解为短片段供鉴别器评估,从而绕过数据和 GPU 内存的限制。
研究结果
实验结果:
-
速度与效率:实验表明,80 亿参数的模型在单个 H100 GPU 上以 736x416 分辨率实现实时 24fps 视频生成,或在 8xH100 GPU 上以 1280x720 分辨率生成长达一分钟(1440 帧)的视频。相比之下,其他先进模型如 CausVid 在相同硬件配置下只能达到较低的分辨率和帧率。
-
生成质量:在 VBench-I2V 基准测试中,AAPT 模型在 120 帧和 1440 帧视频生成任务上均表现出色,与现有最先进方法相比具有竞争力。特别是在长时间视频生成中,AAPT 模型显著优于基于扩散的方法,如 SkyReel-V2 和 MAGI-1。
-
交互式应用:在姿态条件虚拟人生成和相机控制世界探索两个交互式应用中,AAPT 模型展示了其实时交互生成能力,用户可以通过提供初始帧和交互式输入来控制视频生成过程。
研究局限
局限性:
-
快速变化动作:AAPT 模型在处理快速变化动作时可能遇到困难,因为单次网络前向评估(1NFE)模型在生成立即出现的场景和对象时能力有限。
-
长距离记忆:由于使用滑动窗口注意力机制,模型在长距离记忆方面存在局限性。
-
物理一致性:模型有时会违反物理规律,生成不符合现实世界的视频内容。
-
人类偏好对齐:当前模型未经人类偏好对齐训练,这可能限制其性能表现。未来研究可以探索结合人类反馈来改进模型。
未来研究方向
未来研究方向:
-
改进模型架构:探索更高效的架构设计,以更好地处理快速变化动作和长距离记忆问题。
-
增强物理一致性:开发新的方法来确保生成的视频内容符合物理规律,提高视频的真实感。
-
人类偏好对齐:研究如何将人类偏好纳入模型训练过程中,以提高生成视频的质量和用户满意度。
-
扩展应用场景:将 AAPT 方法应用于更多实时交互式视频生成场景中,如虚拟现实、增强现实和游戏开发等领域。
-
优化训练技术:进一步优化长视频训练技术,减少训练时间和计算资源消耗,提高模型的可扩展性和实用性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)