NeurIPS 2025 | 手持8张4090,怎么练大模型最划算?LLM炼丹哈佛给出终极配方
本文探讨了在计算资源受限(如仅有 8 张 RTX 4090)的真实环境下,如何科学地分配算力以训练出高性能的垂直领域语言模型。研究基于哈佛与斯坦福团队发表于 NeurIPS 2025 的EvoLM项目,通过对 100 多个 1B/4B 规模模型进行全生命周期(预训练 PT、持续预训练 CPT、监督微调 SFT、强化学习 RL)的穷举式实验,揭示了模型训练动力学的核心规律。文章否定了盲目追求大参数量
一、 总结

本文探讨了在计算资源受限(如仅有 8 张 RTX 4090)的真实环境下,如何科学地分配算力以训练出高性能的垂直领域语言模型。研究基于哈佛与斯坦福团队发表于 NeurIPS 2025 的 EvoLM 项目,通过对 100 多个 1B/4B 规模模型进行全生命周期(预训练 PT、持续预训练 CPT、监督微调 SFT、强化学习 RL)的穷举式实验,揭示了模型训练动力学的核心规律。文章否定了盲目追求大参数量或依赖大模型中间权重的做法,为“平民玩家”提供了一套包含数据配比、训练轮数及监控指标的标准化炼丹配方。
二、 摘要
哈佛与斯坦福大学的研究者通过从零训练 1B/4B 模型,系统性地分析了模型在不同训练阶段的性能演变。研究发现,模型的下游任务表现高度依赖于完整的学习率衰减(Learning Rate Decay),因此完整训练的小模型性能优于大模型的中间 Checkpoint。
- 预训练阶段:Token 数达到参数量的 80-160 倍时,通用能力进入平台期。
- 持续预训练 (CPT) 阶段:为缓解灾难性遗忘,必须混入约 16% 的通用回放数据,且收益在 30-40B Token 处趋于饱和。
- 后训练阶段:SFT 易导致过拟合,最佳轮数在 3 Epoch 左右;RL(如 PPO)虽能显著提升泛化能力(OOD),但更多是优化模型输出正确答案的概率而非增强基础逻辑。
- 评估指标:传统的困惑度(PPL)与解题能力呈零相关,而结果奖励模型(ORM)的分数则是更可靠的性能预测指标。
三、 观点
-
放弃大模型中间权重,坚持完整的小模型训练:
EvoLM 实验证明,由于学习率衰减轨迹的不同,同等 Token 量下,半路截取的 Checkpoint 性能显著逊于经过完整衰减训练的小模型。研究建议在算力有限时,优先选用 1B-3B 规模并跑完完整的 Scaling 曲线。- 参考公式: 预训练 Token 预算 T≈(80∼160)×ParametersT \approx (80 \sim 160) \times \text{Parameters}T≈(80∼160)×Parameters。
-
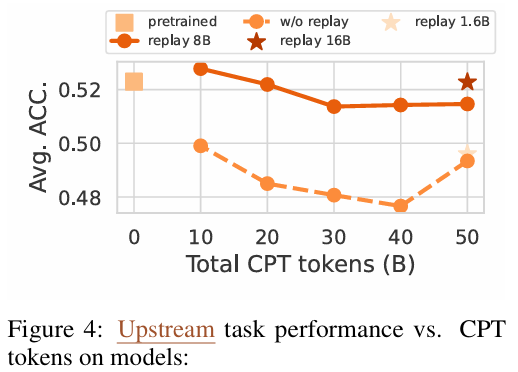
持续预训练 (CPT) 必须引入“数据回放”策略:
单纯灌输领域数据(如数学)会导致通用能力崩盘。实验表明,领域数据与通用数据应保持约 5:1 的比例。- 黄金配比公式: Total Data=Domain Data×84%+General Replay×16%\text{Total Data} = \text{Domain Data} \times 84\% + \text{General Replay} \times 16\%Total Data=Domain Data×84%+General Replay×16%。
- 图片来源: 论文 Figure 4 展示了加入 8B Replay 后对 Upstream 任务准确率的稳固作用。
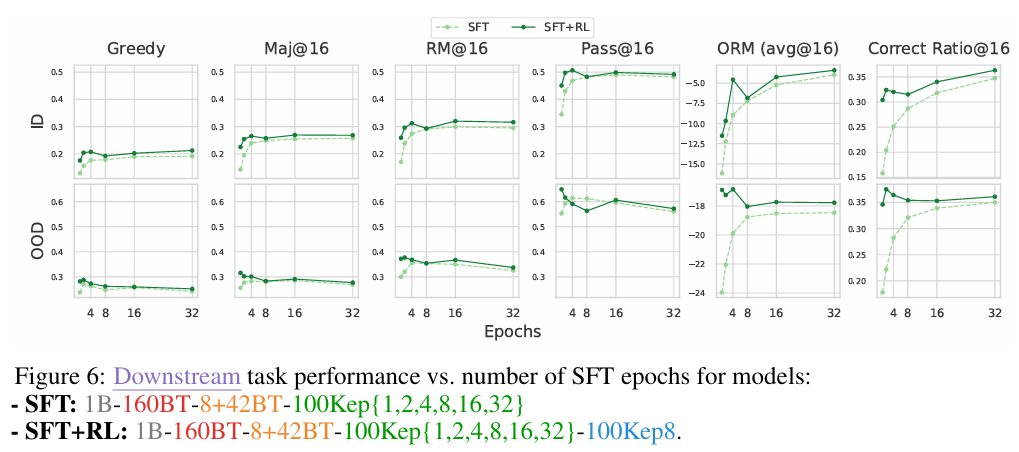
- SFT 的核心矛盾在于“记忆”与“泛化”的博弈:
SFT 轮数超过 4 轮后,域内(In-Domain)表现虽持续上升,但域外(Out-of-Domain)泛化能力会急剧下降。- 操作建议: 严控 SFT 在 2-4 个 Epoch 之间,为后续 RL 留出策略空间。
- 图片来源: 论文 Figure 6 显示 OOD 任务性能在 SFT 达到一定阈值后开始掉头向下。
-
RL 提升的是“自信”而非“逻辑”:
强化学习(RL)的主要作用是让模型学会从已有的知识库中更准确地采样(提高 Confidence),而非学会其原本不懂的新逻辑。- 分配策略: 追求垂直领域“专家”效应应重 SFT(90% 占比);追求通用逻辑泛化则应轻 SFT 重 RL(SFT 仅做对齐引导)。
-
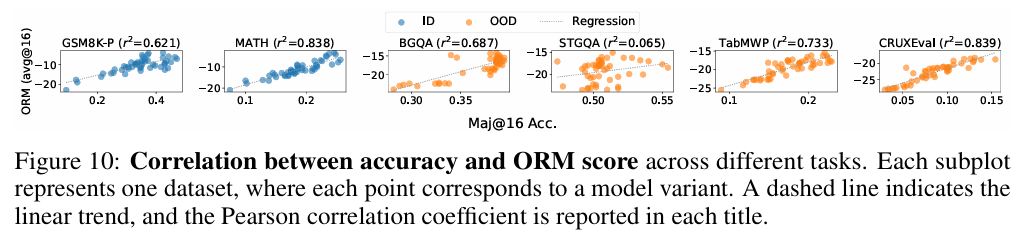
建立基于 ORM 的新型评估监控体系:
验证集损失(Validation Loss)和困惑度(PPL)在后训练阶段失效。- 核心发现: ORM(Outcome Reward Model)评分与模型最终准确率呈强正相关 (r2∈[0.62,0.84]r^2 \in [0.62, 0.84]r2∈[0.62,0.84])。
- 建议: 训练过程中应调用预训练好的 Reward Model 给模型生成的 Response 打分。
- 图片来源: 论文 Figure 10 详细刻画了 ORM Score 与 Maj@16 准确率的相关性。
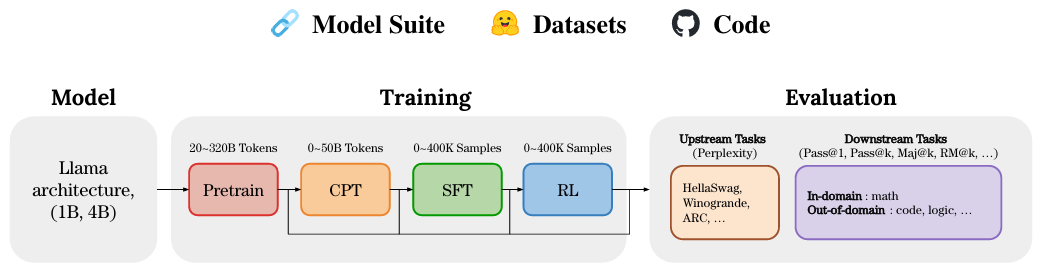
- 资源受限下的最优训练流水线 (Pipeline):
- 第一阶段 (PT):训练充分的 1B-3B 基座。
- 第二阶段 (CPT):30-40B Token 注入,混入 16% 通用回放。
- 第三阶段 (SFT):高质量数据跑 3 Epoch。
- 第四阶段 (RL):预算充足则上 RL,预算不足可舍弃,因为精调的 SFT 模型已具备极强竞争力。
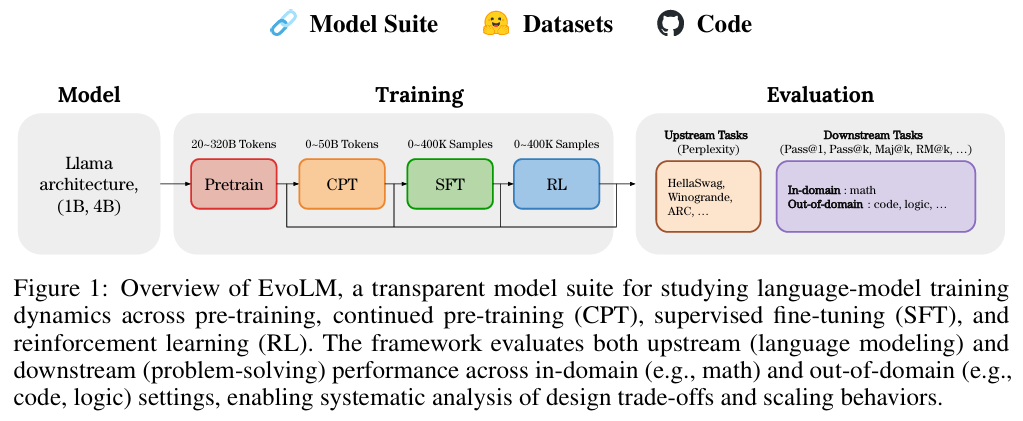
- 图片来源: 论文 Figure 1 展示了这一跨越四个阶段的全生命周期流水线。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)