告别 “听不懂”:搞懂 LLM 领域专业术语(下篇)
这篇技术文章系统解析了大语言模型(LLM)领域的高级核心概念。内容涵盖参数高效微调(PEFT)、人类反馈强化学习(RLHF)等训练优化技术,混合专家模型(MoE)等架构创新,量化与推测解码等推理优化方法,以及多模态学习、评估基准和安全对齐等扩展领域。文章通过对比表格、流程图和分类说明等方式,深入浅出地介绍了这些前沿技术的原理、优势和应用场景,为读者构建了完整的LLM知识框架。这些术语不仅代表了当前
引言:深入LLM技术核心
在掌握了LLM领域的基础术语后,我们需要进一步理解那些构成现代大模型技术骨架的高级概念。从参数高效微调到多模态学习,从推理优化到安全对齐,这些术语代表了LLM技术发展的最前沿。本文将系统解析这些关键术语,帮助读者构建完整的LLM知识体系。
高级训练与优化术语
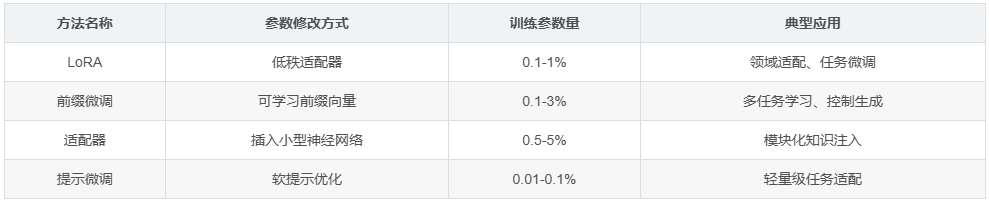
参数高效微调(Parameter-Efficient Fine-Tuning)
PEFT是一类旨在通过只训练少量参数来实现模型适配的技术,大幅降低计算和存储成本。
主要PEFT方法对比:
| 方法名称 | 参数修改方式 | 训练参数量 | 典型应用 |
|---|---|---|---|
| LoRA | 低秩适配器 | 0.1-1% | 领域适配、任务微调 |
| 前缀微调 | 可学习前缀向量 | 0.1-3% | 多任务学习、控制生成 |
| 适配器 | 插入小型神经网络 | 0.5-5% | 模块化知识注入 |
| 提示微调 | 软提示优化 | 0.01-0.1% | 轻量级任务适配 |
人类反馈强化学习(RLHF)
RLHF是通过人类偏好数据来对齐模型行为与人类价值观的三阶段训练流程。
三个阶段详解:
- 监督微调:使用高质量对话数据微调预训练模型
- 奖励模型训练:学习人类对回答质量的偏好评分
- 强化学习优化:使用PPO等算法最大化奖励模型评分
直接偏好优化(DPO)
DPO是RLHF的替代方案,通过闭式解直接优化偏好数据,避免了训练奖励模型的复杂性。
DPO优势:
- 训练更稳定,超参数更少
- 计算成本显著降低
- 避免了奖励黑客问题
模型架构进阶术语
混合专家模型(Mixture of Experts)
MoE架构通过稀疏激活实现模型规模的扩展,而不显著增加计算成本。
核心概念:
- 专家:专门化的前馈网络
- 门控网络:根据输入选择激活的专家
- 稀疏激活:每次推理只使用部分参数
代表性模型:
- Switch Transformer
- GLaM
- Mixtral 8x7B
注意力机制变体
分组查询注意力:
在键值对上进行分组,减少内存占用同时保持性能。
滑动窗口注意力:
只关注局部上下文,适合长序列处理。
多头潜在注意力:
在潜在空间中进行注意力计算,提升效率。
推理与部署术语
量化(Quantization)
量化是通过降低数值精度来减少模型大小和推理延迟的技术。
量化级别:
| 精度类型 | 比特数 | 内存节省 | 质量损失 | 使用场景 |
|---|---|---|---|---|
| FP16 | 16位 | 2倍 | 可忽略 | 标准推理 |
| INT8 | 8位 | 4倍 | 轻微 | 平衡部署 |
| INT4 | 4位 | 8倍 | 中等 | 资源受限 |
| 二值化 | 1位 | 32倍 | 显著 | 极端边缘 |
推测解码(Speculative Decoding)
推测解码使用小型草稿模型预先生成多个token,然后由大型模型并行验证,加速生成过程。
工作流程:
- 草稿模型快速生成候选序列
- 目标模型并行验证候选序列
- 接受验证通过的token前缀
- 重复过程直到生成完成
键值缓存(KV Cache)
在自回归生成过程中,将先前计算的键值对缓存起来,避免重复计算。
缓存优化策略:
- 分页注意力:高效管理可变长度序列
- 内存映射:优化GPU内存使用
- 缓存压缩:减少缓存内存占用
多模态与扩展术语
视觉语言模型(Vision-Language Models)
VLM能够同时处理视觉和语言信息,实现跨模态理解。
典型架构模式:
代表性模型:
- GPT-4V
- LLaVA
- BLIP-2
检索增强生成(Retrieval-Augmented Generation)
RAG通过检索外部知识库来增强模型的生成能力,解决知识截止和幻觉问题。
RAG工作流程:
- 问题编码和检索
- 相关文档获取
- 上下文增强提示构建
- 基于增强上下文的生成
评估与分析术语
基准测试套件
MMLU:
大规模多任务语言理解,涵盖57个科目的学术考试题目。
HellaSwag:
常识推理基准,评估模型对日常情境的理解。
HumanEval:
代码生成能力评估,包含164个手写编程问题。
GSM8K:
小学数学应用题基准,测试多步推理能力。
模型能力矩阵
核心能力维度:
- 世界知识:事实性知识掌握程度
- 推理能力:逻辑推理和问题解决
- 指令遵循:理解和执行复杂指令
- 安全性:避免有害内容生成
- 鲁棒性:对输入变化的稳定性
安全与对齐术语
红队测试(Red Teaming)
通过系统性攻击来发现模型潜在风险和安全漏洞的方法。
测试类别:
- 越狱攻击:绕过安全限制
- 提示注入:操纵模型行为
- 隐私泄露:提取训练数据
- 偏见放大:放大社会偏见
宪法AI(Constitutional AI)
使用原则集(宪法)来指导模型自我改进和自对齐的方法。
核心思想:
模型根据宪法原则进行自我批评和改进,减少对人类反馈的依赖。
对抗性训练(Adversarial Training)
通过在训练中加入对抗样本来提升模型鲁棒性。
对抗样本类型:
- 语义保持的扰动
- 风格转换攻击
- 逻辑矛盾注入
- 上下文误导
前沿研究方向术语
推理时间干预(Inference-Time Intervention)
在推理过程中实时调整模型激活,引导生成方向。
干预策略:
- 方向性激活增强
- 概念神经元抑制
- 注意力重加权
- 梯度引导解码
思维树(Tree of Thoughts)
将推理过程建模为树形结构,通过搜索找到最优推理路径。
扩展自Chain-of-Thought:
- 并行探索多个推理路径
- 使用启发式评估中间状态
- 回溯和路径优化
程序辅助语言模型(Program-Aided Language Models)
让LLM生成程序代码而非直接答案,通过执行代码得到结果。
优势:
- 精确的计算能力
- 可验证的推理过程
- 复杂算法的可靠执行
工程与系统术语
模型并行(Model Parallelism)
将大型模型分布到多个设备上的技术。
并行策略:
- 张量并行:将单个算子分布到多个设备
- 流水线并行:按层分布模型
- 专家并行:在MoE模型中分布专家
服务系统架构
推理服务组件:
- 模型加载器:动态加载和卸载模型
- 请求调度器:管理并发请求
- 批处理引擎:合并请求提升吞吐量
- 内存管理器:优化GPU内存使用
持续学习(Continual Learning)
使模型能够持续学习新知识而不遗忘旧知识的技术。
持续学习挑战:
- 灾难性遗忘
- 知识冲突
- 存储增长
- 评估困难
开源生态术语
模型仓库(Model Hub)
集中存储和分享预训练模型的平台。
主要功能:
- 模型版本管理
- 推理API提供
- 社区贡献
- 许可证管理
开放权重(Open Weights)
发布模型权重但不一定包含训练代码和数据。
与开源的区别:
- 开放权重:可访问模型参数
- 完全开源:包含训练代码、数据和权重
经济与产业术语
推理成本(Inference Cost)
部署和运行LLM服务的经济成本计算。
成本构成:
- 硬件折旧
- 电力消耗
- 冷却系统
- 维护人力
令牌经济(Token Economics)
基于API调用次数或生成token数量的计费模式。
计费因素:
- 输入token数量
- 输出token数量
- 模型规模
- 服务质量要求
伦理与社会影响术语
价值对齐(Value Alignment)
确保AI系统目标与人类价值观一致的研究领域。
对齐挑战:
- 价值 specification问题
- 价值学习不确定性
- 价值冲突解决
- 跨文化价值差异
可解释AI(Explainable AI)
理解和解释模型决策过程的技术。
解释方法:
- 注意力可视化
- 特征重要性分析
- 概念激活向量
- 反事实解释
结语:构建完整的LLM知识图谱
通过上下两篇的术语解析,我们已经系统覆盖了LLM领域从基础到高级的关键概念。这些术语不仅是技术交流的工具,更是理解LLM技术发展脉络的路线图。
从Transformer架构到MoE扩展,从监督微调到RLHF对齐,从基准测试到红队评估,这些术语描绘了一个快速演进的技术生态。掌握这些概念,意味着我们能够:
- 理解技术原理:从数学基础到工程实现
- 跟踪研究进展:识别有前景的技术方向
- 参与专业讨论:与从业者有效交流想法
- 做出技术决策:基于深入理解选择合适方案

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)