即插即用系列 | CVPR 2025 MONA:多尺度方向感知适配器——仅需5%参数,性能超越全量微调 (5% > 100%)
本文提出了一种名为Mona的新型参数高效调优方法,首次在复杂视觉任务上超越全量微调性能。针对现有Adapter方法源于NLP领域、依赖线性层的局限,Mona创新性地引入"多认知视觉滤波器"(并行3×3/5×5/7×7深度卷积)替代线性层,并加入可学习缩放LayerNorm来调整特征分布。该方法仅需5%可训练参数,在COCO、ADE20K等任务上性能突破全量微调天花板。论文详细分
论文名称:5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks
论文原文 (Paper):https://arxiv.org/abs/2408.08345
官方代码 (Code):https://github.com/LeiyiHU/mona
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
** 本论文的完整复现代码(即插即用版)已更新至专栏**
即插即用系列(代码实践) | CVPR 2025 MONA:多尺度方向感知适配器——仅需5%参数,性能超越全量微调 (5% > 100%)
1. 核心思想
- 本文提出了一种名为 Mona(多认知视觉适配器) 的新型参数高效调优(Delta-tuning 或 PEFT)方法,其核心目标是打破全量微调(Full Fine-tuning)在视觉任务上的性能天花板。
- 论文的出发点是,现有的 Adapter(适配器)方法大多源自 NLP 领域,依赖“语言友好”的线性层,这不适合处理 2D 视觉信号。
- Mona 通过引入一个**“多认知视觉滤波器”(由并行的 3 × 3 , 5 × 5 , 7 × 7 3 \times 3, 5 \times 5, 7 \times 7 3×3,5×5,7×7 深度卷积构成)来替代线性层**,使其更擅长捕捉视觉特征。
- 同时,它在 Adapter 头部加入了一个可学习的缩放 LayerNorm,用于自适应地调整来自固定预训练骨干的特征分布。
- 最终,Mona-tuning 仅用不到 5% 的可训练参数,就在 COCO、ADE20K 等多个复杂的视觉识别任务上首次超越了全量微调的性能。
2. 背景与动机
-
[文本角度总结]
-
“预训练-微调”范式在 CV 领域取得了巨大成功。其中,全量微调(Full Fine-tuning)(即更新所有骨干网络参数)一直是实现最佳性能(SOTA)的黄金标准。
然而,随着模型越来越大,全量微调的存储和计算成本变得难以承受。因此,Delta-tuning(或 PEFT)方法应运而生。这类方法(如 LoRA、Adapter)只训练一小部分(<5%)的额外参数,在 NLP 和简单的 CV 分类任务上取得了接近全量微调的性能。
本文的核心动机(即“问题”):在复杂、密集的视觉识别任务(如 COCO 实例分割、ADE20K 语义分割)上,现有的 Delta-tuning 方法(如 LoRA, AdaptFormer)始终无法超越全量微调的性能上限。
论文作者认为,这种失败源于现有 Adapter 设计的两个根本缺陷:
- “语言友好”的过滤器: 现有的 Adapter 设计(如 AdaptFormer)几乎都是从 NLP 领域照搬过来的,它们依赖**线性层(Linear layers)**作为核心。但视觉信号是 2D 的,**卷积(Convolution)**才是处理视觉信号的“母语”。
- 单一认知尺度: 现有 Adapter 通常使用单一的线性层来压缩特征,缺乏多尺度认知(multi-cognitive perspectives)能力,而这在视觉任务中至关重要。
- 输入分布失配: Delta-tuning 会“冻结”骨干网络。当新任务的数据分布与预训练任务不同时,固定的骨干网络会输出“有偏”的特征分布,而 Adapter 无法调整这一点。
-
动机图解分析(Figure 1):
- 图表 A (Figure 1):揭示“性能瓶颈”问题
- “看图说话”: 这张图(ADE20K mIoU vs. COCO mAP)是本文最核心的动机和成果展示。
- 分析:
- 性能天花板(The Ceiling): 蓝色的虚线代表了**全量微调(Full Fine-tuning)**的性能(51.18 mIoU, 52.4 mAP)。这是现有技术的天花板。
- 现有 Delta-tuning 的失败: 几乎所有其他的 Delta-tuning 方法(LoRA, Adapter, AdaptFormer 等,显示为各种彩色图标)都聚集在虚线的左下方。这意味着它们在两个任务上的表现均弱于全量微调。
- 本文的解决方案: 只有
Mona (ours)(红色五角星)唯一地出现在虚线的右上方(51.36 mIoU, 53.4 mAP)。
- 结论: Figure 1 极其清晰地传达了本文的核心论点:1) 现有的 Delta-tuning(PEFT)方法在复杂视觉任务上存在性能瓶颈,无法击败全量微调。2) 本文提出的 Mona 成功地打破了这一瓶颈,证明了“微调少量参数”可以比“微调全部参数”做得更好。
- 图表 A (Figure 1):揭示“性能瓶颈”问题
3. 主要贡献点
- 首次在复杂视觉任务上超越全量微调: 本文是第一个在多个复杂的视觉识别任务(包括 COCO 实例分割、ADE20K 语义分割、DOTA 旋转框检测等)上,性能全面超越全量微调的 Delta-tuning(PEFT)方法。
- 提出 Mona(多认知视觉适配器): 提出了一个专为视觉任务设计的 Adapter 结构。它抛弃了 NLP 中常用的线性层,转而使用“视觉友好”的滤波器。
- 引入多认知视觉滤波器(Multi-Cognitive Visual Filters):
- 这是 Mona 的核心。在 Adapter 的降维投影(Down Projection)之后,Mona 并行使用了三个不同尺度的深度可分离卷积(DWConv)(核大小为 3 × 3 , 5 × 5 , 7 × 7 3 \times 3, 5 \times 5, 7 \times 7 3×3,5×5,7×7)。
- 这使得 Adapter 能够从多个认知尺度(类比人眼)来处理视觉特征,而不是像传统 Adapter 那样只有一个“单一认知”(线性层)。
- 设计可缩放的 LayerNorm(Scaled LayerNorm):
- 为了解决 Adapter 输入特征的分布偏移问题,Mona 在 Adapter 的最前端加入了一个
LayerNorm层。 - 关键在于,这个
LayerNorm的输出和原始输入 x 0 x_0 x0 是通过两个可学习的标量 s 1 s_1 s1 和 s 2 s_2 s2 来加权的( x n o r m = s 1 ⋅ L N ( x 0 ) + s 2 ⋅ x 0 x_{norm} = s_1 \cdot LN(x_0) + s_2 \cdot x_0 xnorm=s1⋅LN(x0)+s2⋅x0)。这使得 Mona 能够自适应地调整输入特征的分布,决定是更多地使用归一化后的特征还是原始特征。
- 为了解决 Adapter 输入特征的分布偏移问题,Mona 在 Adapter 的最前端加入了一个
4. 方法细节
-
整体网络架构(Figure 2 左侧):
- 模型名称: Mona-tuning (应用于 Swin-Transformer)
- 数据流:
- 该图展示了 Mona 如何作为一个**“插件”**集成到标准的 Swin-Transformer 块中。
- 一个标准的 Swin 块由
LayerNorm→ \rightarrow →W/SW-MSA(窗口/移位窗口多头自注意力)和一个LayerNorm→ \rightarrow →2x Feed-Forward Layer(MLP)组成,两者都有残差连接。 - Mona-tuning 的策略是冻结 Swin 块中的所有原始参数(MSA 和 MLP)。
- 然后,串行地在
W/SW-MSA模块之后插入一个Mona Layer,并在2x Feed-Forward Layer之后再插入一个Mona Layer。 - 在训练期间,只有
Mona Layer的参数被更新。
- 设计目的: 这种串行插入(而非并行)的方式(类似于 Adapter)允许 Mona 模块在不干扰预训练知识流(残差连接)的情况下,对 MSA 和 MLP 输出的特征进行**“二次精炼”**(refinement)。
-
核心创新模块详解(Figure 2 右侧):
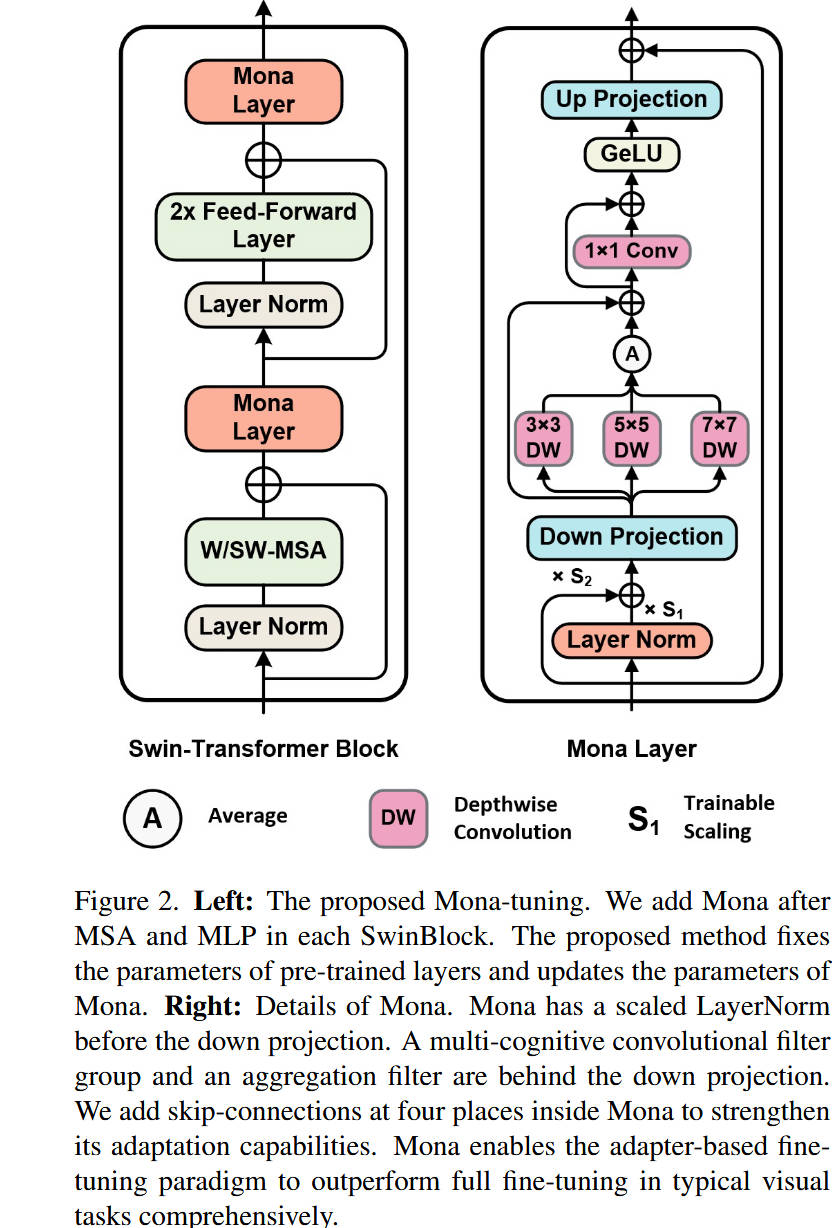
- 对于 模块 A:Mona Layer
- 理念: 这是本文的核心创新。它是一个专为视觉信号设计的高效适配器(Adapter)。
- 内部结构: 具有“瓶颈”(Bottleneck)结构的 Adapter,但内部完全由视觉友好的算子构成。
- 数据流:
- 输入优化(Scaled LayerNorm): 输入特征 x 0 x_0 x0 首先进入可缩放的 LayerNorm(
Layer Norm× s 1 \times s_1 ×s1+× s 2 \times s_2 ×s2),得到 x n o r m x_{norm} xnorm。这一步是可学习的,用于调整输入分布。 - 下采样(Down Projection): x n o r m x_{norm} xnorm 经过一个
Down Projection(线性层),将通道数 m m m 压缩到 n n n(例如 n = 64 n=64 n=64),以减少计算量。 - 多认知视觉滤波器(Multi-Cognitive Filters): 这是核心中的核心。下采样后的特征被并行送入三个不同的**深度可分离卷积(DWConv)**分支,核大小分别为 3 × 3 , 5 × 5 , 7 × 7 3 \times 3, 5 \times 5, 7 \times 7 3×3,5×5,7×7。
- 聚合(Aggregation): 三个 DWConv 分支的输出特征被求平均(Average, ‘A’ 符号),然后送入一个
1x1 Conv层进行特征融合。 - 非线性与上采样: 融合后的特征经过
GeLU激活函数,最后通过Up Projection(线性层)将通道数从 n n n 恢复回 m m m。 - 残差连接: 最终的输出与最原始的输入 x 0 x_0 x0(来自 Swin 块)进行逐元素相加( ⊕ \oplus ⊕)。
- (注意: 图中还显示了
Down Projection→ \rightarrow →DW和DW→ \rightarrow →1x1 Conv之间存在两个内部跳跃连接,以增强信息流。)
- 输入优化(Scaled LayerNorm): 输入特征 x 0 x_0 x0 首先进入可缩放的 LayerNorm(
- 设计目的: 传统 Adapter 在“下采样”和“上采样”之间是一个简单的
GeLU→ \rightarrow →Linear。Mona 用一个强大的多尺度卷积模块( 3 × 3 , 5 × 5 , 7 × 7 3 \times 3, 5 \times 5, 7 \times 7 3×3,5×5,7×7 DWConv + 1x1 Conv)替换了它,使得 Adapter 具备了处理 2D 视觉信号和多尺度认知的能力。
- 对于 模块 A:Mona Layer
-
理念与机制总结:
- 为什么 Mona 优于全量微调?
- Mona vs. 线性 Adapter (如 AdaptFormer): 线性 Adapter 使用“语言友好”的线性层,无法有效处理 2D 视觉信号。Mona 使用**“视觉友好”的 DWConv 滤波器**( 3 × 3 , 5 × 5 , 7 × 7 3 \times 3, 5 \times 5, 7 \times 7 3×3,5×5,7×7),能更好地捕捉局部模式和多尺度信息。
- Mona vs. 全量微调 (Full FT): 全量微调会更新所有预训练参数,这可能会破坏(catastrophic forgetting)大型预训练模型(如 Swin-L)学到的宝贵知识。Mona-tuning 冻结了所有预训练参数,只训练(<5%)Mona 插件。Mona 模块通过其 Scaled LayerNorm 自适应地调整输入,并通过其多认知滤波器提取新任务所需的“增量特征(delta)”。
- 结论: Mona-tuning 能够更好地**“保留”预训练模型的泛化能力,同时“适应”**新任务的特定需求,从而实现了超越全量微调的性能。
- 为什么 Mona 优于全量微调?
-
图解总结:
- Figure 1 提出了问题:所有现有的 Delta-tuning 方法(LoRA, Adapter…)在复杂的视觉任务上都弱于全量微调(蓝色虚线),存在性能天花板。
- Figure 2(右侧) 提出了解决方案:
Mona Layer。它通过两个关键创新解决了传统 Adapter 的缺陷:- Scaled LayerNorm:解决了“输入分布失配”问题。
- Multi-Cognitive Filters( 3 × 3 , 5 × 5 , 7 × 7 3 \times 3, 5 \times 5, 7 \times 7 3×3,5×5,7×7 DWConv):解决了 Adapter“水土不服”(即语言友好的线性层无法处理视觉信号)的问题。
- Figure 2(左侧) 展示了部署方式:将
Mona Layer作为插件串行插入到冻结的Swin-Transformer Block中(MSA 之后和 FFN 之后)。 - Figure 1(Mona ★) 展示了最终结果:这种“视觉友好”的 Adapter 设计(Mona)成功突破了性能天花板,在 mIoU 和 mAP 上均超越了全量微调。
5. 即插即用模块的作用
-
本文的核心创新
Mona Layer是一个专为 Transformer 架构(特别是 Swin Transformer)设计的**即插即用(Plug-and-play)的适配器(Adapter)**模块。 -
适用场景 1:替代全量微调(Full Fine-tuning)
- 应用: 当你需要将一个大型预训练视觉 Transformer(如 Swin-B, Swin-L)迁移到新的下游任务时(无论是分类、检测还是分割)。
- 方法: 冻结整个预训练骨干网络,然后在每个 Transformer 块的 MSA 和 MLP 之后串行插入一个
Mona Layer(如图 Figure 2 左侧所示)。 - 优势:
- 性能更优: 如 Table 1, 2, 4 所示,Mona-tuning 在 COCO, ADE20K, DOTA 等任务上全面超越了全量微调的性能(例如,COCO mAP 高出 1%)。
- 极高的参数效率: 只需训练骨干网络参数量的不到 5%(例如,在 Swin-L 上仅为 2.56%)。
- 极低的存储成本: 对于 K 个任务,全量微调需要存储 K 个完整的骨干网络副本。Mona-tuning 只需存储 1 个骨干网络副本和 K 个极小(例如 5.08M)的 Mona 插件。
-
适用场景 2:替代其他 Delta-tuning/PEFT 方法(如 LoRA, AdaptFormer)
- 应用: 在任何需要进行参数高效微调的视觉任务中。
- 优势:
Mona是为视觉信号专门设计的。与 LoRA 或 AdaptFormer 等“语言友好”的线性适配器相比,Mona 的多尺度卷积核设计使其能更有效地从预训练模型中提取和迁移视觉知识,从而在所有视觉任务上都取得了比它们更高的性能。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)