VUE+SPRINGBOOT从0-1打造前后端-前后台系统-超拟人合成
本文介绍了一个基于WebSocket的拟真人语音合成前端实现方案,采用Vue.js框架结合ElementUI构建。系统提供15种发音人选择、2000字文本输入、背景音乐控制等功能,通过WebSocket与讯飞开放平台通信实现实时音频合成与播放。关键技术包括:发音人切换界面设计、文本输入处理、WebSocket连接与鉴权、实时音频流处理以及文件下载功能。特色功能支持多音字标注和自动中英文切换,具有响
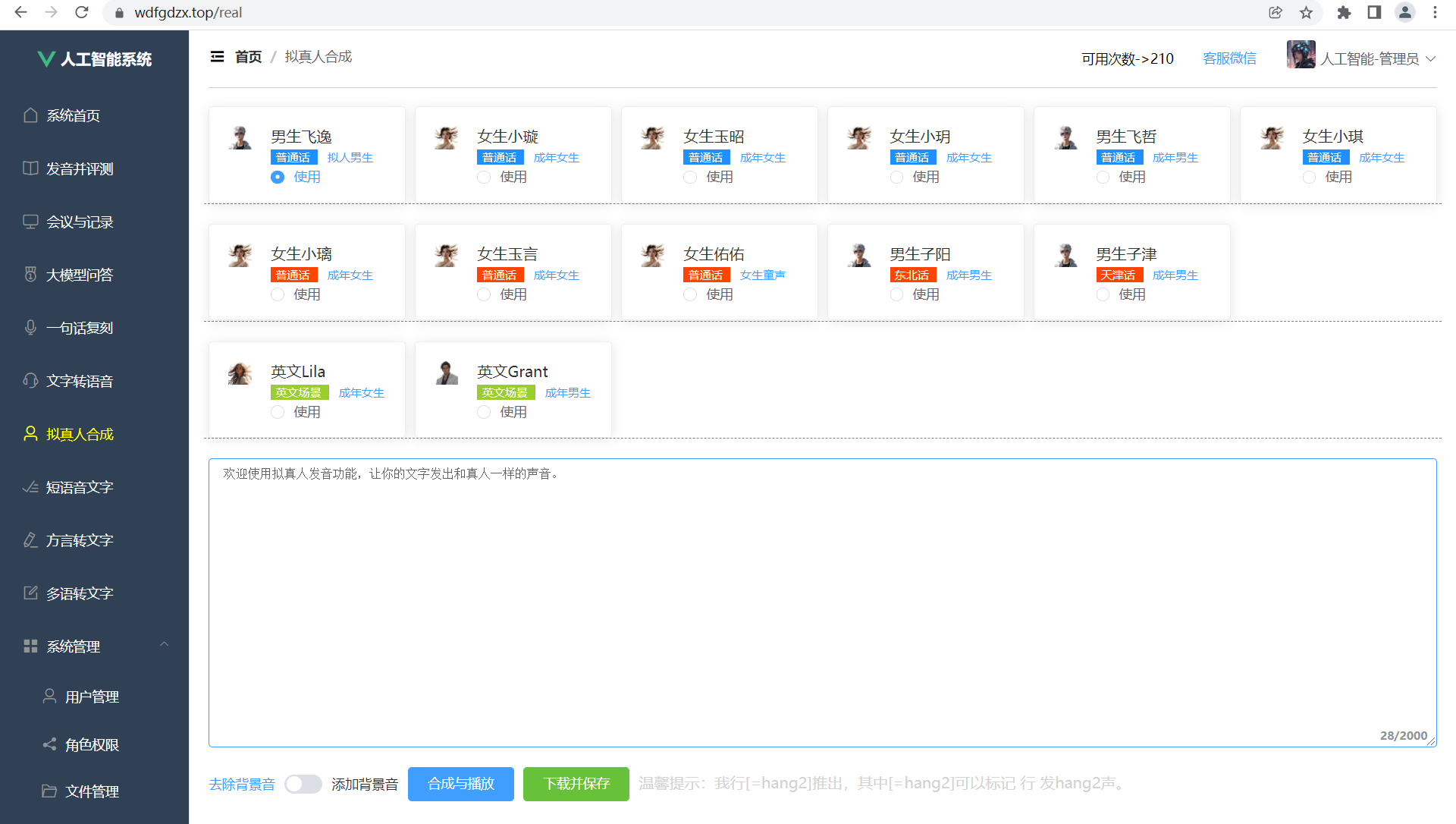
在当今数字化时代,语音合成技术(TTS, Text-To-Speech)已成为人机交互的重要组成部分。从最初的机械音到如今接近真人发音的拟真效果,TTS技术取得了长足进步。本文将详细解析一个基于WebSocket的拟真人语音合成前端实现方案,该方案支持多种发音人选择、背景音乐控制、实时播放和音频下载等功能。
一、项目概述
这个语音合成前端项目具有以下核心功能:
-
提供15种不同风格的发音人选择(包括男女声、儿童声、方言和英文发音人)
-
支持2000字以内的文本输入合成
-
可控制是否添加背景音乐
-
实时播放合成音频
-
下载保存合成的音频文件
-
支持多音字标注(如"我行[=hang2]推出")
项目采用Vue.js框架,结合Element UI组件库实现界面,通过WebSocket与讯飞开放平台的后端语音合成服务进行通信。
二、技术架构分析
2.1 前端技术栈
-
Vue.js:作为项目的前端框架,提供数据驱动和组件化开发能力
-
Element UI:提供美观的UI组件,如卡片、单选框、按钮、输入框等
-
WebSocket:实现与语音合成服务的实时双向通信
-
CryptoJS:用于WebSocket连接鉴权的加密处理
-
js-base64:处理文本的Base64编码
-
自定义音频播放器:处理音频流的接收和播放
2.2 核心业务流程
-
用户选择发音人和输入文本
-
前端通过WebSocket建立与服务端的连接
-
发送包含文本和参数的合成请求
-
接收服务端返回的音频数据流
-
实时播放音频或保存为文件
三、关键代码解析
3.1 发音人选择界面
项目使用Element UI的el-row和el-col布局组件创建了一个响应式的发音人选择面板。每种发音人用一个卡片(el-card)展示,包含:
-
头像图片(区分男女)
-
发音人名称和类型
-
语言/方言标签(不同颜色区分)
-
单选框选择
<el-row :gutter="10" style="border-bottom: 1px dashed grey">
<el-col :span="4">
<el-card style="height: 102px;">
<img src="../css_assets/9.png" style="width: 15%">
<div style="display: inline-block;vertical-align: top;margin-left: 20px;width: 120px;">
男生飞逸<br>
<span style="padding-left: 5px;padding-right: 5px;font-size: 12px;background-color: dodgerblue;color: white">
普通话
</span>
<span style="margin-left: 10px;font-size: 12px;color: #409EFF;">拟人男生</span>
<br>
<el-radio v-model="radio" label="x4_lingfeiyi_oral">使用</el-radio>
</div>
</el-card>
</el-col>
<!-- 更多发音人卡片 -->
</el-row>
3.2 文本输入区域
使用el-input的textarea类型实现文本输入,设置了最大长度限制和字数统计:
<el-input type="textarea" v-model="ttsText" rows="15"
style="font-family: 'Microsoft YaHei';font-size: medium;font-weight: bold"
:maxlength="2000" show-word-limit
placeholder="请输入不超过2000个汉字的文本进行合成">
</el-input>
3.3 控制按钮区域
提供三个主要操作控件:
-
背景音乐开关
-
合成与播放按钮
-
下载保存按钮
<el-switch
v-model="bgMusic"
active-text="添加背景音"
inactive-text="去除背景音">
</el-switch>
<el-button type="primary" size="medium" @click="clickReal" style="margin-left:10px;">合成与播放</el-button>
<el-button type="success" size="medium" @click="clickWav">下载并保存</el-button>
3.4 发音人切换监听
使用Vue的watch功能监听发音人选择变化,当切换到英文发音人时自动切换示例文本:
watch: {
radio(newVal, oldVal) {
if (newVal == "x4_EnUs_Lila_emo" || newVal == "x4_EnUs_Grant_emo") {
this.ttsText = "Welcome to use the text-to-speech function...";
} else {
this.ttsText = "欢迎使用拟真人发音功能...";
}
}
}
四、WebSocket通信实现
4.1 建立WebSocket连接
doWsWork() {
let bgs = this.bgMusic ? 1 : 0;
const url = this.getWebSocketUrl(atob(this.user.apikey), atob(this.user.apisecret));
if ("WebSocket" in window) {
this.ttsWS = new WebSocket(url);
} else if ("MozWebSocket" in window) {
this.ttsWS = new MozWebSocket(url);
} else {
alert("浏览器不支持WebSocket");
return;
}
// 设置各种事件处理器
this.ttsWS.onopen = (e) => { /*...*/ };
this.ttsWS.onmessage = (e) => { /*...*/ };
this.ttsWS.onerror = (e) => { /*...*/ };
this.ttsWS.onclose = (e) => { /*...*/ };
}
4.2 鉴权URL生成
使用CryptoJS进行HMAC-SHA256加密生成鉴权参数:
getWebSocketUrl(apiKey, apiSecret) {
let url = "wss://cbm01.cn-huabei-1.xf-yun.com/v1/private/mcd9m97e6";
let host = location.host;
let date = new Date().toGMTString();
let algorithm = "hmac-sha256";
let headers = "host date request-line";
let signatureOrigin = `host: ${host}\ndate: ${date}\nGET /v1/private/mcd9m97e6 HTTP/1.1`;
let signatureSha = CryptoJS.HmacSHA256(signatureOrigin, apiSecret);
let signature = CryptoJS.enc.Base64.stringify(signatureSha);
let authorizationOrigin = `api_key="${apiKey}", algorithm="${algorithm}", headers="${headers}", signature="${signature}"`;
let authorization = btoa(authorizationOrigin);
url = `${url}?authorization=${authorization}&date=${date}&host=${host}`;
return url;
}
4.3 发送合成请求
连接建立后,发送包含文本和参数的JSON数据:
this.ttsWS.onopen = (e) => {
audioPlayer.start({
autoPlay: true,
sampleRate: 16000,
resumePlayDuration: 1000
});
let params = {
"header": {
"app_id": atob(this.user.appid),
"status": 2
},
"parameter": {
"oral": {
"spark_assist": 0
},
"tts": {
"vcn": this.radio,
"volume": 50,
"speed": 50,
"pitch": 50,
"bgs": bgs,
"reg": 0,
"rdn": 0,
"audio": {
"encoding": "raw",
"sample_rate": 16000,
"channels": 1,
"bit_depth": 16,
"frame_size": 0
}
}
},
"payload": {
"text": {
"encoding": "utf8",
"compress": "raw",
"format": "plain",
"status": 2,
"seq": 0,
"text": this.encodeText(text, tte),
}
}
}
this.ttsWS.send(JSON.stringify(params));
};
4.4 处理音频数据
接收服务端返回的音频数据并播放:
this.ttsWS.onmessage = (e) => {
let jsonData = JSON.parse(e.data);
if (jsonData.header.code !== 0) {
console.error(jsonData);
return;
}
if (typeof jsonData.payload !== 'undefined' && jsonData.payload.audio.audio) {
audioPlayer.postMessage({
type: "base64",
data: jsonData.payload.audio.audio,
isLastData: jsonData.header.status === 2,
});
}
if (jsonData.header.code === 0 && jsonData.header.status === 2) {
this.ttsWS.close();
}
};
五、音频处理实现
5.1 音频播放器初始化
使用自定义的AudioPlayer处理音频流:
const audioPlayer = new AudioPlayer("../../player");
5.2 播放音频数据
javascript
复制
下载
audioPlayer.start({
autoPlay: true,
sampleRate: 16000,
resumePlayDuration: 1000
});
// 接收到音频数据后
audioPlayer.postMessage({
type: "base64",
data: jsonData.payload.audio.audio,
isLastData: jsonData.header.status === 2,
});
5.3 下载音频文件
将合成的音频保存为WAV文件:
clickWav() {
const blob = audioPlayer.getAudioDataBlob("wav")
if (!blob) return;
let defaultName = new Date().getTime();
let node = document.createElement("a");
node.href = window.URL.createObjectURL(blob);
node.download = `${defaultName}.wav`;
node.click();
node.remove();
}
六、特色功能实现
6.1 多音字标注
系统支持通过[=拼音]的方式标注多音字,例如:
我行[=hang2]推出
实现这一功能需要服务端支持,前端只需按格式输入文本即可。
6.2 背景音乐控制
通过bgs参数控制是否添加背景音乐:
let bgs = this.bgMusic ? 1 : 0;
6.3 中英文自动切换
当用户选择英文发音人时,自动切换示例文本为英文:
watch: {
radio(newVal, oldVal) {
if (newVal == "x4_EnUs_Lila_emo" || newVal == "x4_EnUs_Grant_emo") {
this.ttsText = "Welcome to use the text-to-speech function...";
} else {
this.ttsText = "欢迎使用拟真人发音功能...";
}
}
}
七、性能优化与注意事项
-
WebSocket连接管理:确保及时关闭不再使用的连接,避免资源泄漏
-
音频数据处理:使用流式处理,减少内存占用
-
错误处理:对各种网络错误和服务端错误进行适当处理
-
用户引导:通过UI提示引导用户正确使用多音字标注等功能
-
响应式设计:确保在不同屏幕尺寸下都能良好显示
八、总结
本文详细分析了一个基于WebSocket的拟真人语音合成前端实现方案。该方案具有以下优点:
-
实时性强:通过WebSocket实现低延迟的语音合成
-
功能丰富:支持多种发音人、背景音乐、多音字标注等
-
用户体验好:提供实时播放和下载保存两种使用方式
-
扩展性强:架构设计便于添加新的发音人或功能
这种实现方式不仅适用于在线语音合成场景,其技术思路也可以应用于其他实时音频处理场景,如语音识别、实时翻译等。随着Web技术的不断发展,基于Web的实时音频处理能力将会越来越强大,为人机交互带来更多可能性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)