【Python语音识别系列】一文教你实现语音声道分离(案例+源码)
一文教你实现语音声道分离(案例+源码)
·
这是我的第418篇原创文章。
一、引言
在处理音频信号时,左右声道分离是一个非常常见的需求,尤其是在音频分析、声道处理和音频特效设计中。今天,我将分享如何使用 Python 的 Soundfile 库实现这一功能,通过几个步骤帮助大家理解整个过程。这一博文将集中在如何把立体声音频分离成左右声道,分析交互过程,并进行性能优化。
二、实现过程
2.1 分析原始音频文件
代码:
input_audio = AudioSegment.from("./test.ogg")
print(f"采样率:{input_audio.frame_rate}Hz")
print(f"声道数: {input_audio.channels}")
print(f"位深: {input_sample_width*8}位")
print(f"时长: {len(input_audio)}ms")结果:
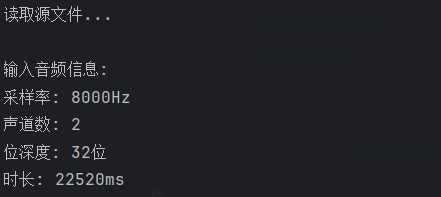
可见原始音频采样率为8k,双声道,位深度32,时长22520ms。
2.2 提取左声道
左声道:
channels = input_audio.split_to_mono()
channel_audio = channels[0]
channel_audio = channel_audio._spawn(channel_audio.raw_data, overides={"sample_width":2})"})
bytes_io = io.BytesIO()
channel_audio.export(
bytes_io,
format="wav",
parameters=["-ar", str(channel_audio.frame_rate), "-f", "s32le", "-ac": "1"]
)
left_bytes = bytes_io.getvalue()
with open("test_left.wav", "wb") as f:
f.write(left_bytes) 结果:
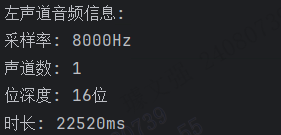
提取后的音频为单声道,位深度变为之前的一半,采样率和时长没有发生变化。
2.3 提取右声道
右声道:
channels = input_audio.split_to_mono()
channel_audio = channels[1]
channel_audio = channel_audio._spawn(channel_audio.raw_data, overides={"sample_width":2})"})
bytes_io = io.BytesIO()
channel_audio.export(
bytes_io,
format="wav",
parameters=["-ar", str(channel_audio.frame_rate), "-f", "s32le", "-ac": "1"]
)
right_bytes = bytes_io.getvalue()
with open("test_right.wav", "wb") as f:
f.write(right_bytes) 结果:
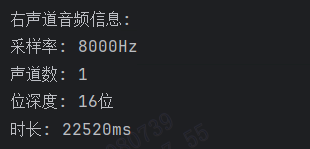
提取后的音频为单声道,位深度变为之前的一半,采样率和时长没有发生变化。
2.4 合并为双声道
左右声道合并为双声道:
left_audio = AudioSegment.from_wav("test_left.wav")
right_audio = AudioSegment.from_wav("test_right.wav")
merged = AudioSegment.from_mono_audiosegments(left_audio, right_audio)
merged.export("test_merged.wav", format="wav")结果:

作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)