跨芯片统一优化,DLCompiler 与 DLBlas 驱动算子极致表现
9 月 10 日,上海人工智能实验室(上海 AI 实验室)DeepLink 团队开源扩展 Triton 的深度学习编译器,以及面向大模型训练与推理、异构硬件适配的高性能算子库。开发者无需手动调优,即可获得接近硬件峰值的性能。面向昇腾 DSA 架构,研究团队通过深度融合,在性能保持无损的同时,突破了跨代迁移难题。同时,研究团队与昇腾毕昇编译器团队、昇腾基础软件团队和昇腾特战队协同优化,基于 Asce
9 月 10 日,上海人工智能实验室(上海 AI 实验室)DeepLink 团队开源扩展 Triton 的深度学习编译器DLCompiler,以及面向大模型训练与推理、异构硬件适配的高性能算子库 DLBlas。开发者无需手动调优,即可获得接近硬件峰值的性能。面向昇腾 DSA 架构,研究团队通过扩展 DSL 深度融合,在性能保持无损的同时,突破了跨代迁移难题。同时,研究团队与昇腾毕昇编译器团队、昇腾基础软件团队和昇腾特战队协同优化,基于 AscendNPU IR 首次让 Triton OP 在昇腾芯片上实现极致性能优化,特定 Shape下 Cube 计算效率接近峰值,并在上海 AI 实验室多模态大模型训练中带来性能加速。
亮点速览:
-
跨架构 DSL 扩展:通过扩展 DSL,让 DSA 芯片(昇腾芯片)也能享受 GPU 级的编程体验和性能,成为 “跨架构 AI Kernel DSL” 。
-
智能自动优化:实现智能核间调度,充分释放多核算力;结合创新的访存合并优化,将离散访问自动重组为高速连续访问,大幅提升算子性能与带宽利用率。
-
大模型瓶颈算子极致优化:提供高效 Attention、GroupGemm、FuseMoe 等关键算子实现,性能在 NV H800 上可达理论峰值 80%+。GroupGemm、Matmul 在昇腾芯片的 Cube 计算效率可达 82%。
-
提供统一便捷的 MoE 接口:集成 DeepEP、DeepGemm 等算子,并根据 token 变化动态调整冗余专家分布解决 MoE 负载不均衡问题,并提供统一接口兼容不同推理框架。
当前仓库均已开源,欢迎拔冗试用。
DLCompiler Github: https://github.com/DeepLink-org/DLCompiler
DLBlas Github: https://github.com/DeepLink-org/DLBlas
DeepLink 官网:https://deeplink.org.cn/home
AscendNPU IR Gitee: https://gitee.com/ascend/ascendnpu-ir
通过 DSL 扩展能力边界,多款芯片上获最优性能表现
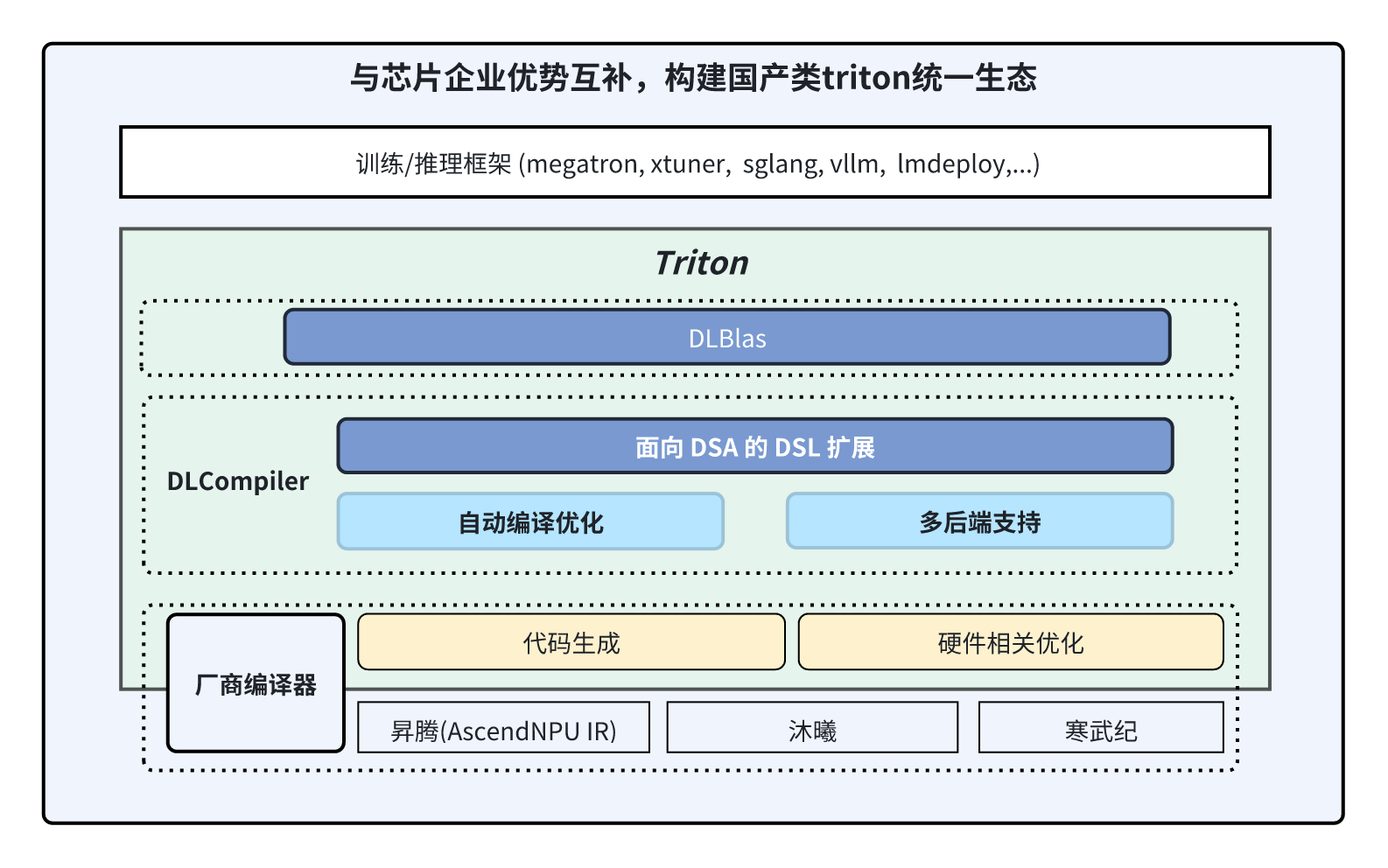
片上缓存分配(dl.alloc)
根据 DSA 硬件架构和内存排布要求,申请片上缓存大小并标定申请片上缓存层级(L0A, L0B,...),相比原生 Triton,可以让算子开发者更细粒度描述算子 tiling 和流水排布。
@triton.jit
def custom_func_kernel(x_ptr, output_ptr,
n_elements, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
# 申请片上SRAM UB的buffer
y = dl.alloc([BLOCK_SIZE], 1.68, dtype=tl.float32, layout=dl.ND, scope=dl.UB)
# 实现L1->UB数据搬移
tl.store(y, x)多处理单元流水抽象(dl.parallel)
针对 DSA 架构单个核内的 Tensor Core 计算单元和 Vector 计算单元算力不一致的问题,dl.parallel 可以更细粒度控制计算单元的并行。相比原生 Triton,算子开发者可以直接控制 Tensor Core 计算单元和 Vector 计算单元的并行行为。通过高效利用计算资源,获得更高的性能收益。
SUB_BLK_M: tl.constexpr = BLOCK_SIZE_M // 2
# 两个vector计算单元并行计算
for s in dl.parallel(0, 2, bind_sub_block=True):
left = s * SUB_BLK_M
right = (s + 1) * SUB_BLK_M
# 取slice切分local tensor
vec_sub_blk = accumulator[left:right, :]
if ACTIVATION == "leaky_relu_custom":
vec_sub_blk = leaky_relu_custom(vec_sub_blk)
c_sub_blk = vec_sub_blk.to(tl.float16)
# Write back the block of the output matrix C.灵活编译提示(dl.compile_hint)
给编译器特定提示以执行特定的编译行为。原生 Triton DSL 抽象度高,某些场景编译器无法知晓完整语义,扩展 dl.compile_hint 以提示编译器执行特定行为,可以获得更好的性能收益。
for k in tl.range(0, tl.cdiv(K, BLOCK_K)):
a_ptrs = a_ptrs_base + k * BLOCK_K
b_ptrs = b_ptrs_base + k * BLOCK_K
a = tl.load(a_ptrs,
mask=msk_m[:, None] and (offs_k[None, :] < K - k * BLOCK_K),
other=0.0)
# 提供类似pragma指导编译器优化
tl.compile_hint(a, "dot_pad_only_k")
b = tl.load(b_ptrs,
mask=msk_n[:, None] and (offs_k[None, :] < K - k * BLOCK_K),
other=0.0)
tl.compile_hint(b, "dot_pad_only_k")
accumulator = tl.dot(a, b.T, acc=accumulator)细粒度缓存切分(dl.extract_slice)
支持对 SharedMemory、UB、L1 等缓存层级中的 localTensor 取 slice。可以与 dl.parallel 配合,细粒度控制计算资源,也可以配合访存,将非连续访存替换成连续大块访存,然后在 LocalMemory 中使用 slice 能切分后分别进行计算。
@triton.jit
def triton_kernel(x_ptr, y_ptr, output_ptr, POS: tl.constexpr, N: tl.constexpr, BLOCK_SIZE_N: tl.constexpr):
pid = tl.program_id(axis=0)
start = pid * N
offsets = tl.arange(0, BLOCK_SIZE_N)
mask = offsets < N
x = tl.load(x_ptr + start + offsets, mask=mask)
y = tl.load(y_ptr + start + offsets, mask=mask)
# 片上缓存切分
out_left = x[:POS] + y[:POS]
out_right = x[POS:] - y[POS:]
out_left_offsets = tl.arange(0, POS)
tl.store(output_ptr + start + out_left_offsets, out_left)
out_right_offsets = POS + out_left_offsets
tl.store(output_ptr + start + out_right_offsets, out_right, mask=out_right_offsets < N)屏蔽硬件细节,编译优化释放芯片算力
核内调度
原生 Triton 中,Program ID 表示一个 block 内启动的线程数。在 DSA 架构下,DLCompiler 将其和任务类型对齐,通过自动分离代码映射到 Tensor Core,Vector Core 资源,在考虑 Tensor Core 与 Vector Core 负载均衡且保障 Tensor Core 与 Vector Core 流水并行前提下,用满核资源。
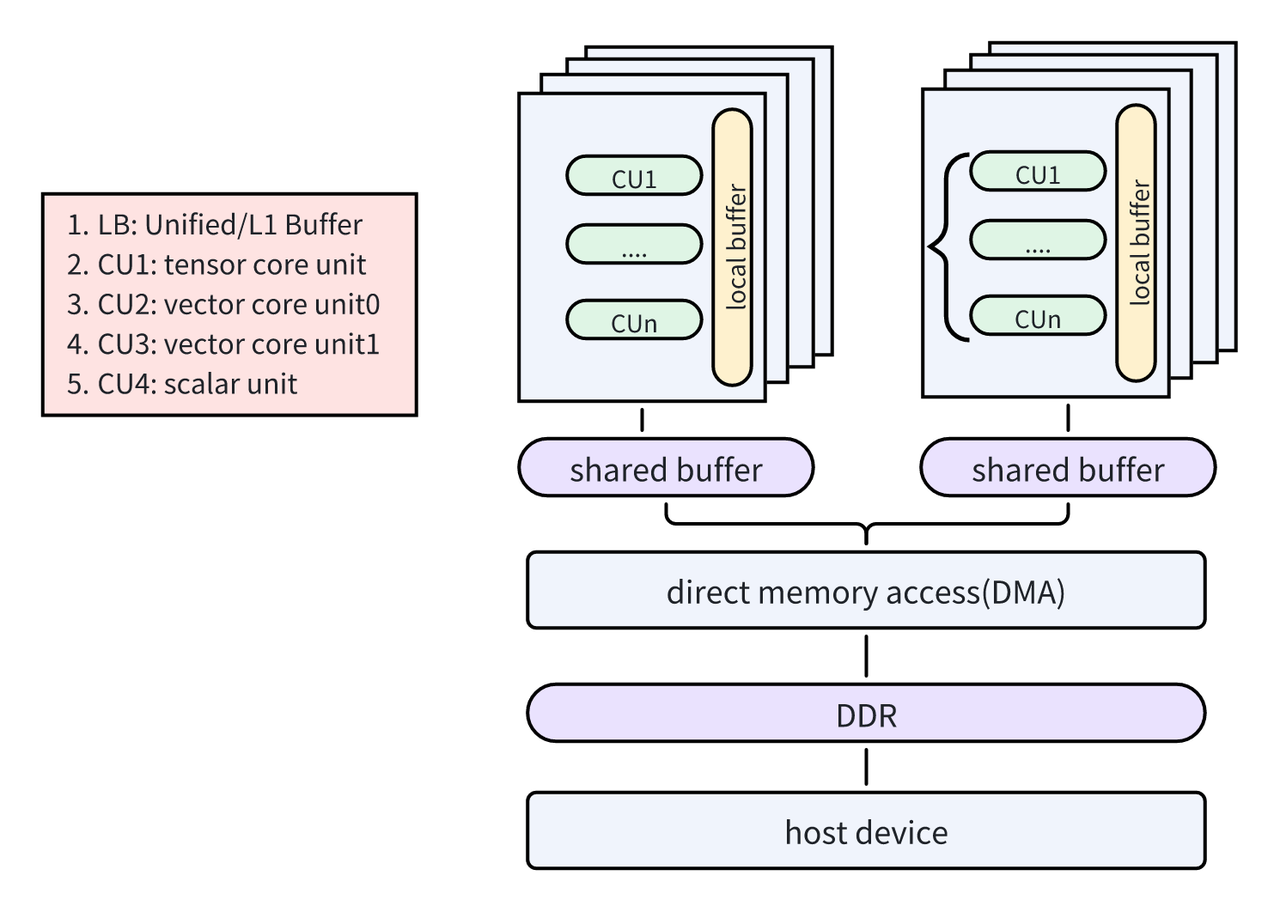
存合并访
原生 Triton 中主要面向 GPU 场景,将 Gemm/Attention 连续访存模式做到极致,对于 stride 不等于 1 或者非连续内存访问,基本就直接生成 scalar load 或 warp 内分散访问。这对于 DSA 架构采用 SIMD 指令,性能将会损失很厉害。DLCompiler 通过把 innermost loop 对齐到 memory-contigous dimension,同时通过自动插入 tile copy 将非连续块转换为 scratchedpad, 再由 compute core 从 scratchedpad 进行消费。
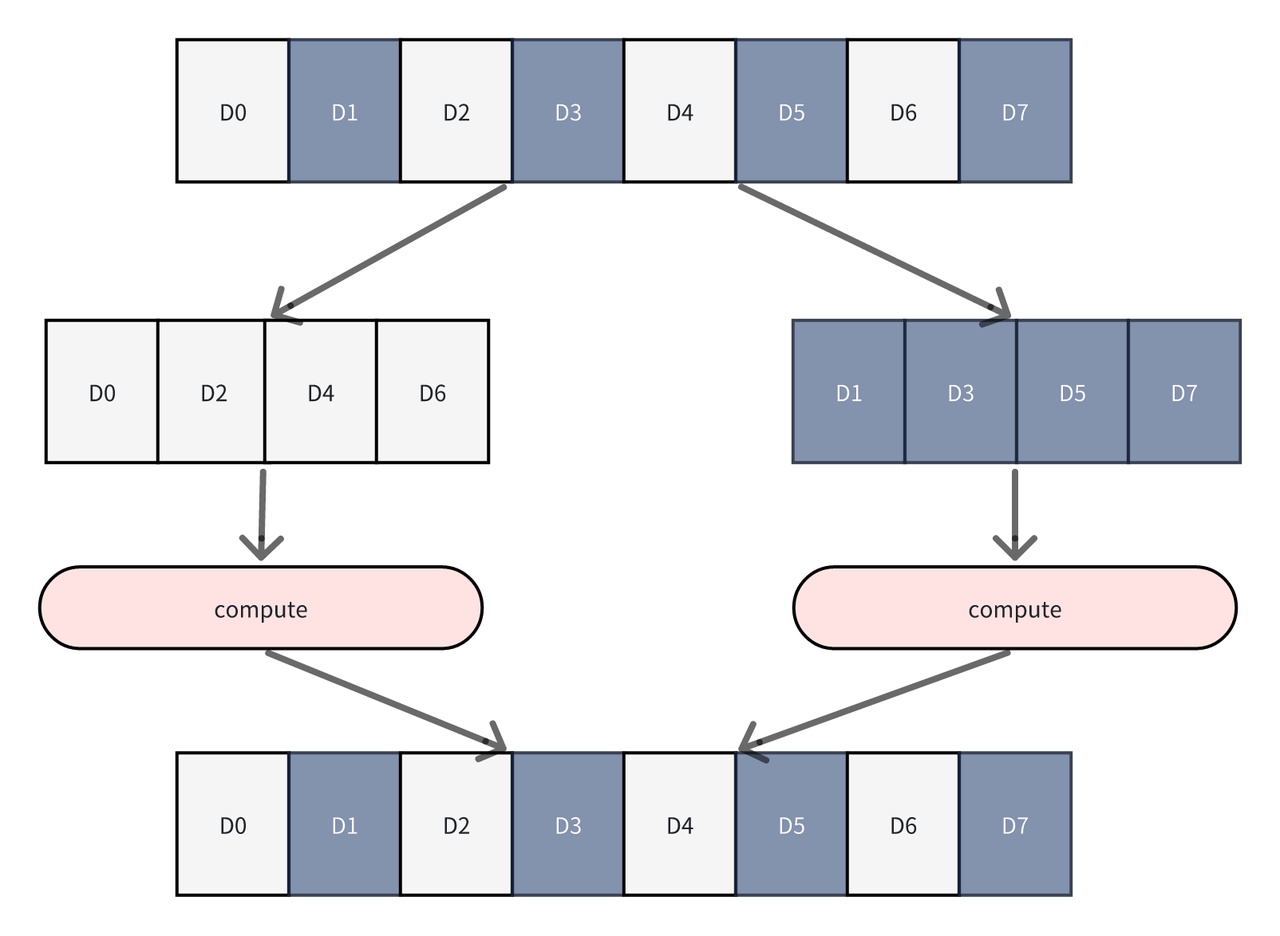
破解 DSA 芯片优化难点,极致性能最佳实践
优化 L2 缓存
针对 Matmul、Grouped_Matmul 等矩阵乘算子,传统水平分核实现方式是优先完成结果矩阵的一行基本块计算,之后再计算下一行,以此类推。
当参与计算的张量 shape 比较大时使用传统水平分核方式会有如下问题:
-
同一时间多个计算核心都需要访问同一块左矩阵内存,产生 Bank 冲突,导致硬件访问效率降低。
-
当完成一整行分块矩阵乘运算时,已经将所有右矩阵数据全部使用上,右矩阵较大时会超过 L2 缓存的容量上限,此后每行运算都会产生缓存未命中,导致 L2 缓存命中率较低,影响算子执行效率。
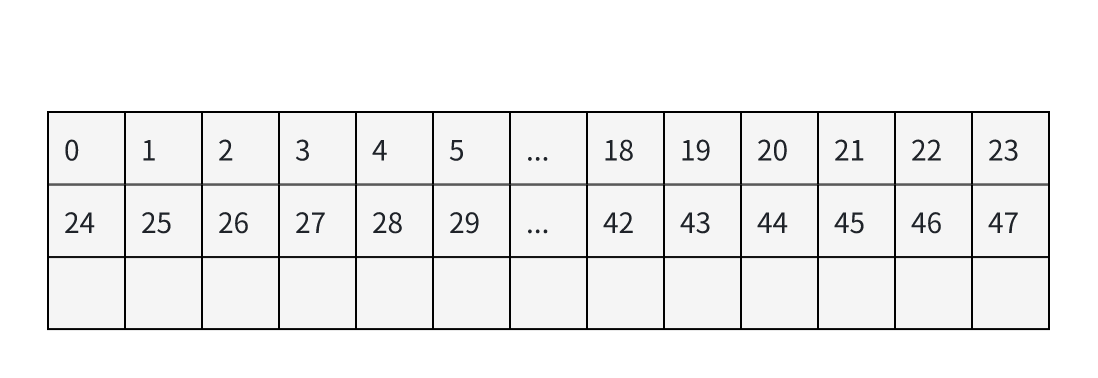
使用对角线分核计算可以很大程度优化上面两点,此处以使用 8 * 8 对角线分核为例(可以 Autotune)。8 * 8 对角线分核方式中,每 8 * 8 分格内任务块编号如下:
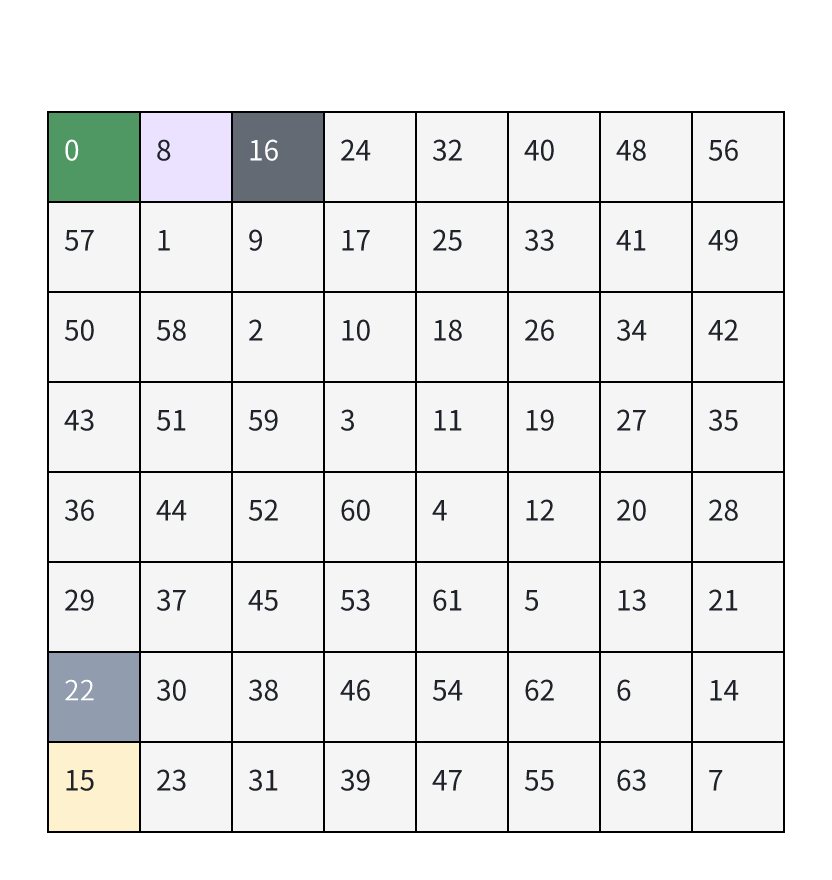
在昇腾 Atlas A2 训练/推理系列产品中,以24个计算核并行执行任务为例进行分析。水平分核时,同一时间所有的核都在使用同一块左矩阵,导致理论访问 bank 冲突高达 24,降低了左矩阵搬运效率。而 8*8 对角线分核分核的任务块内,行方向同一时刻只有 3 个核(0, 8, 16)在读左矩阵,列方向同一时刻也只有 3 个核(0, 22, 15)在读右矩阵,明显减小了 Bank 冲突。
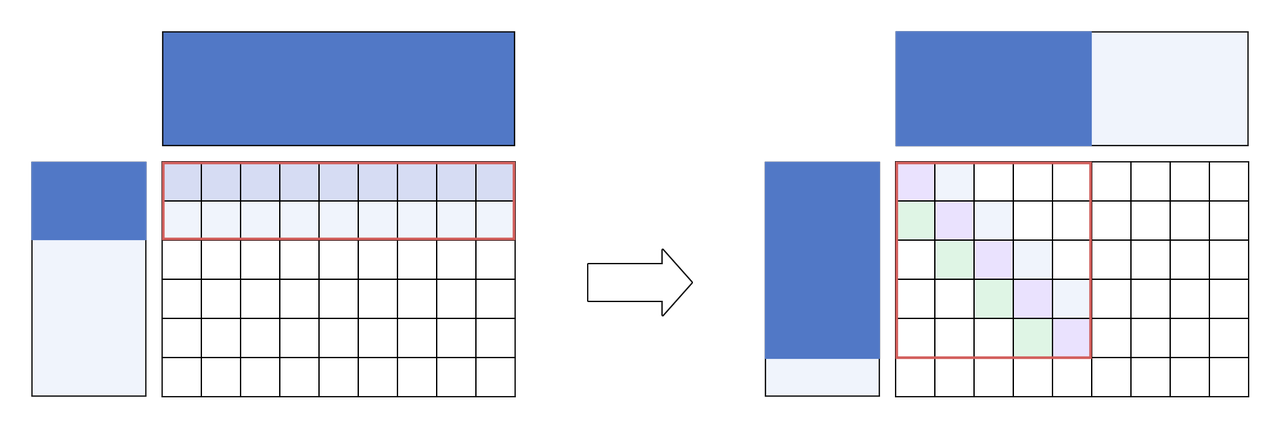
L2 缓存是所有计算核心共享的,所以理论上应尽可能使用 L2 缓存中的数据计算按计算。水平分核计算一行就需要使用到整个右矩阵。而对角线分核使用整个右矩阵理论可以执行 8 行数据的计算,数据局部性更优,对于 L2 缓存利用率较高。当 L2 缓存不足以放下整个右矩阵时,水平分核存在更加频繁的 L2 缓存换入换出。对角线分核作为 Swizzle 分核的变种,在 DSA 架构芯片上可以获得更高的性能收益。
高效访存
增加访存连续性:DLCompiler 支持通过 load/store 原语使用地址偏移和 mask 实现灵活访存,但是连续大段访存时 IO 利用率更高。例如当读写二维 Tensor 的一个 Block 时,对低维的读写是连续的,对高维的读写是间断的,所以 Autotune 时,适当增加低维 BlockSize 可以增加访存连续性,性能更好。
使用块指针访存:块指针从语义上可以明确数据的排布形式,在 DSL 里直接提供了访存的 shape、stride、offset、order 等信息,比使用 load/store 原语更有利于编译优化,生成更优的访存指令。
使用编译器提示:访存时在 DSL 中增加 max_constancy、max_contiguous、multiple_of 三种编译器提示原语可以辅助编译器进行地址连续性分析,更有助于生成高效访存指令。
大段读取、切片计算:连续大段访存时 IO 利用率更高。某些场景中(例如数据不连续或者计算逻辑需要多次读取小数据),可以一次性读取大段数据,然后使用 DLCompiler 扩展的 slice 原语,在片上对大段数据取切片后分别计算,可以达到更高性能。
组合数据、大段写出:为了更好利用设备带宽。某些场景中,也可以使用 DLCompiler 扩展的 slice 原语,在片上将数据组合起来再整体写到 GlobalMemory,可以达到更高性能。
大模型瓶颈算子极致优化
Group Gemm:零同步冗余,实现 MoE 训推的端到端性能突破
目前 Triton 和 cuBLAS 实现的 Gemm 操作都需要在主机端明确大小,在计算过程中需要进行 CPU-GPU 同步,带来了显著的性能开销。
为了能够在 GPU 内核内部动态确定组边界,同时确保连续内存布局下的正确计算,避免数据重叠错误,研究团队基于 Triton 的 Gemm 实现进行开发,并进行了性能优化,最终Triton kernel 在 M_grouped_gemm 上部分超过 cuBLAS,最高达到 1.1x,在 K_grouped_gemm 均超过 cuBLAS,最高达到 1.27x。
研究团队使用以下方法进行性能优化:
1. 持久化内核:CTA 持久驻留在 SM 上,动态处理多个工作单元。
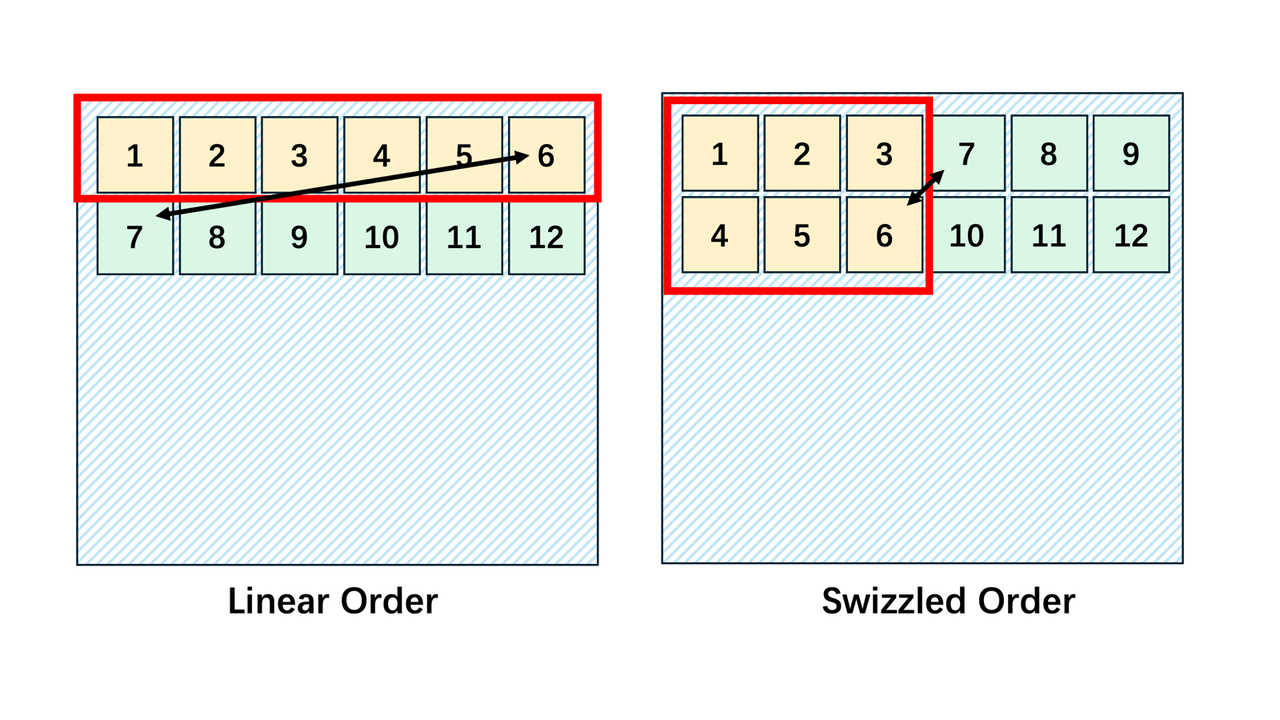
2. L2 缓存优化——Thread block swizzling:采用瓦片交错的方式,重新排列线程块的二维网格位置(pid_m 和 pid_n),使相邻程序处理的数据在物理存储上更接近,从而显著提高 L2 缓存命中率。
3. 增大算数强度:使用 Triton 的 Autotune 功能尝试 64、128、256 等不同尺寸的组合,自动优化提高算术强度。
4. 分组偏移预计算:提前使用预计算 kernel 计算分组偏移并存储到全局内存,减少线程块频繁查询自己所属的分组。
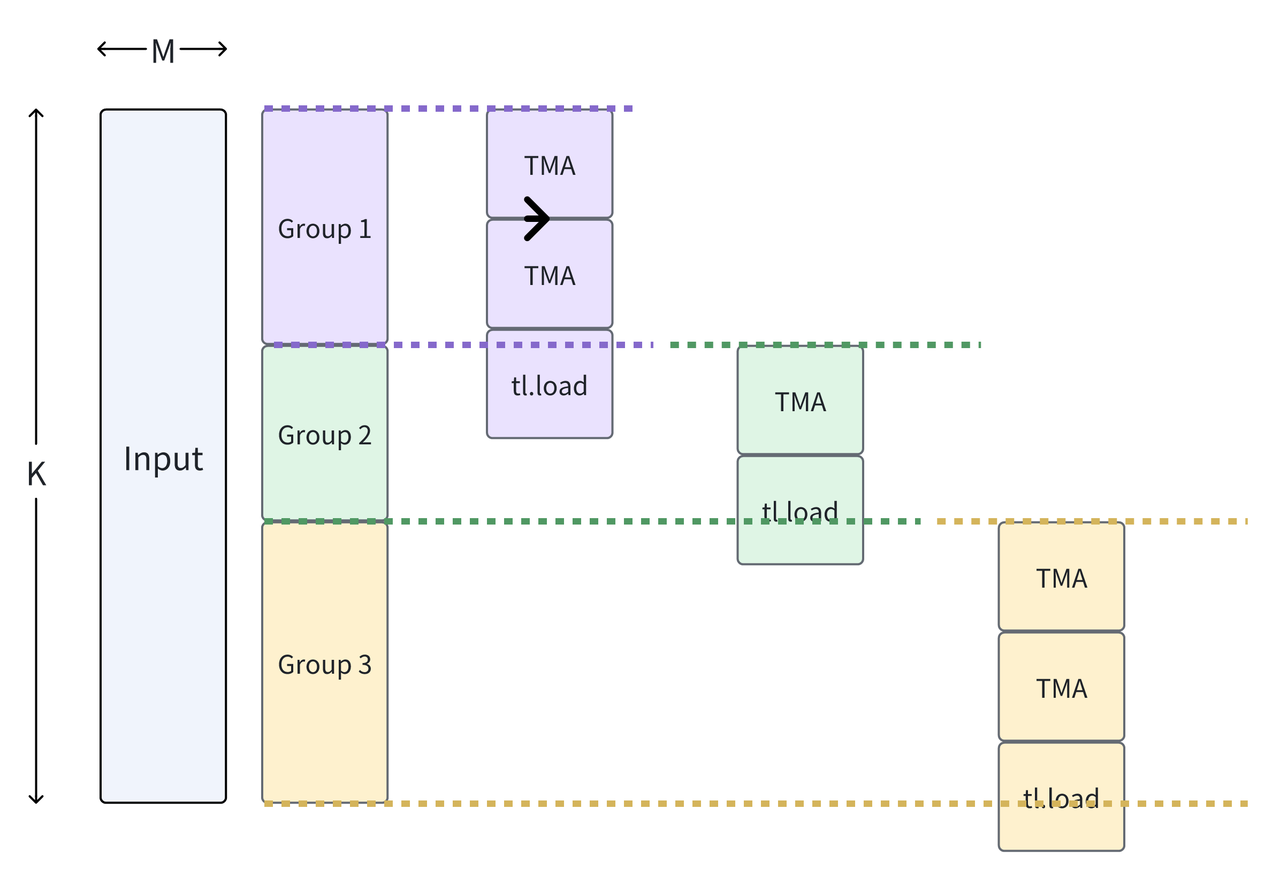
5. TMA - tl.load 混合加载: 采用 TMA 异步加载对齐的 block,tl.load 配合精确的 mask 机制处理最后的边界数据。
Attention : 非 2 次幂实现最佳性能
目前 Triton 的 Flash Attention 实现在 A100 卡上有两个问题:1. 精度损失严重;2. 运行时间是 PyTorch 原生实现的 2.2 倍。 因此研究团队基于 Triton 的实现分成精度和速度两个部分进行性能优化,最终 Triton kernel 在 Bfloat16 精度运行时,相比 Torch,dim=96 时可以达到 1.028,dim=64 时最高可以达到 1.108。
-
在精度方面:针对 Triton3.0 以下版本 bug 情况进行数据读取时强制同步,Triton3.0 以上版本不需要将中间结果存在全局内存中。
-
速度方面:
(1)Triton autotune:使用 Triton 的 autotune 功能尝试 64、128、256 等不同尺寸的组合,寻找适合的配置参数。
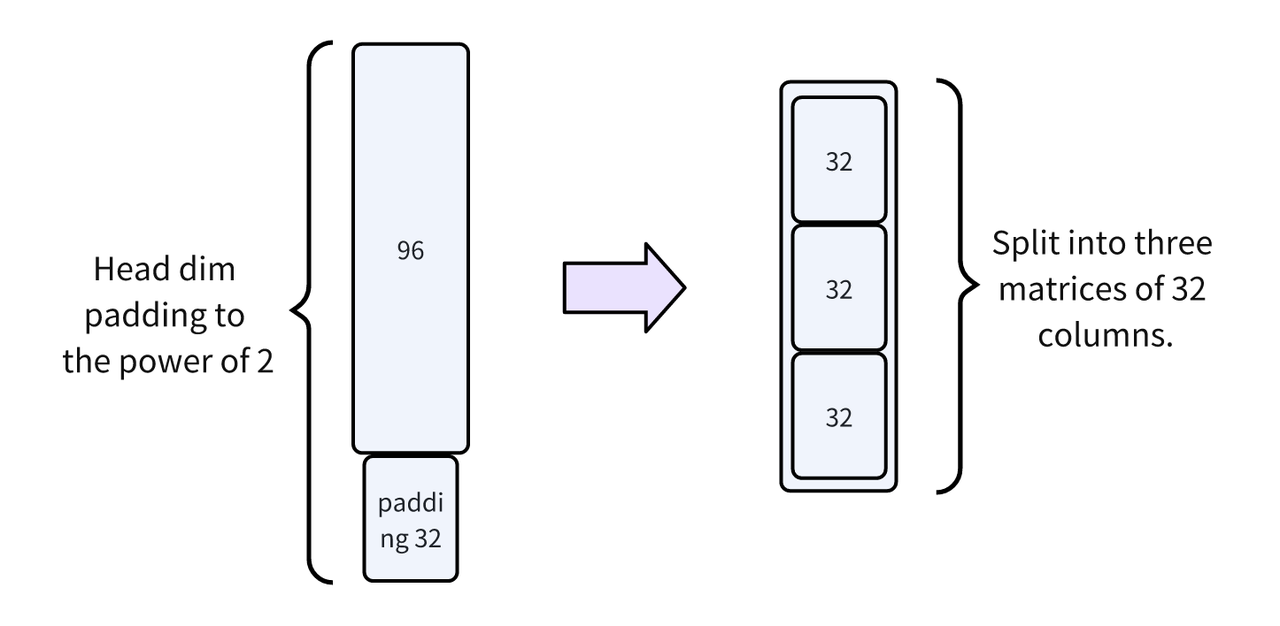
(2)手动管理 BLOCK_HEADDIM2:使用 3 个 32 列的矩阵进行 load 和计算替换 Triton 原始方式(将 head dim padding 到 2 的幂次方)。
(3)L2 cache 优化: 交换 seq_k 和 head 的 grid 序号,提高缓存命中率。
Fused_allgather_grop_loss 融合算子
虽然计算和通信在逻辑上是两种可独立使用的资源,但由于 NCCL 的 send/recv 内核会通过 SM 利用 NVLink 传输数据,这一过程会带来额外的开销,从而降低整体速度。此外,若采用双向同步机制,发送方和接收方均会被阻塞,进一步影响通信性能。Fused_allgather_group_loss 通过利用 CUDA 的 P2P(点对点)通信机制有效避免了上述问题。该方法通过自定义的 wait_signal 机制实现自旋等待,并确保仅由第一个线程(flat_tid=0)执行等待操作。一旦当前线程块的数据到达,计算即可立即启动,从而显著提升了通信与计算的重叠效率。
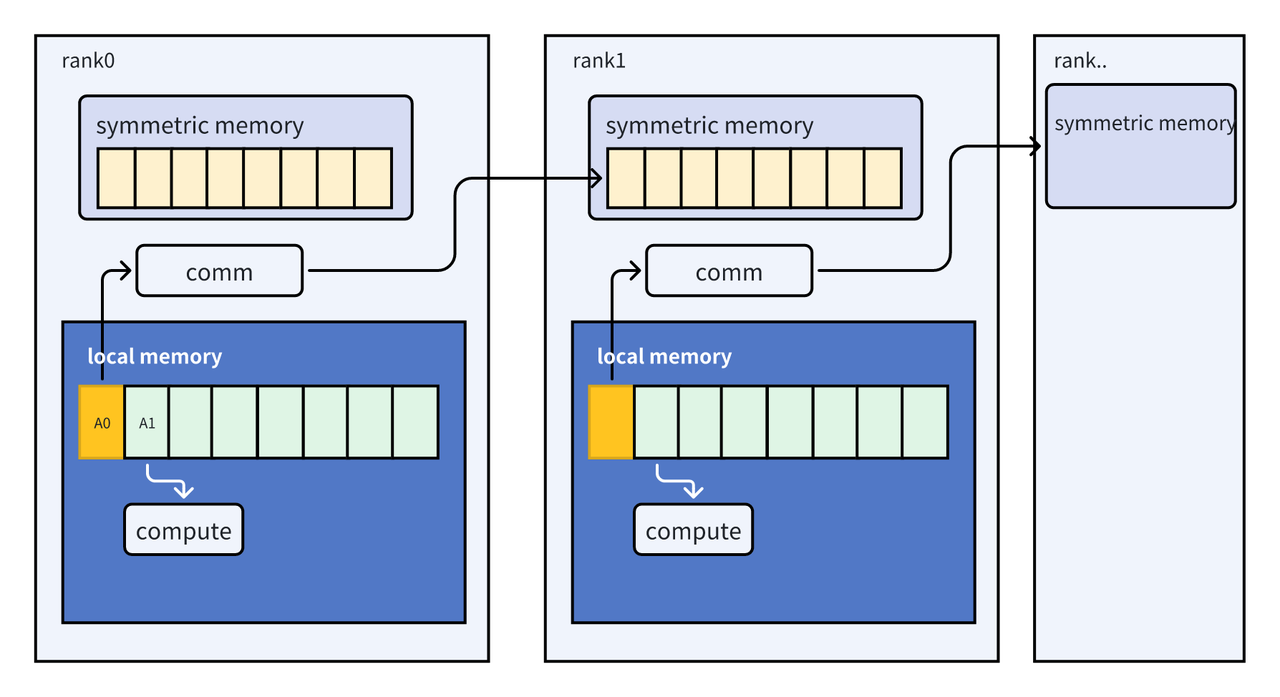
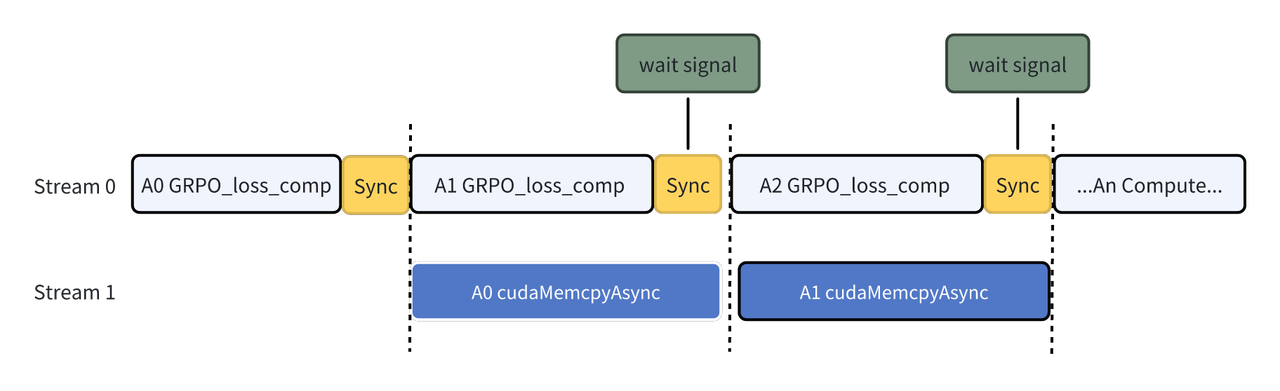
通过在设备组之间对称分配的缓冲区,并利用虚拟内存/多播寻址机制,为每个 GPU 提供对其对等设备上所有对应缓冲区的访问权限。输入数据按照 rank 总数进行分块,每个 rank 负责处理其中一块(共有 world_size 个 rank),并借助一个 progress 数组来跟踪各个分块的完成状态。在当前 rank 中,首先完成本地内存(local memory)上分块 A0 的计算。随后,在开始处理下一个分块 A1 的计算的同时,通过通信操作将 A0 的计算结果传输至其他 rank 的对称内存(symmetric memory)中。通过 wait_signal 和 cudaMemcpyAsync 最终实现 symmetric memory 远程数据传输和本地 local memory 计算的 overlap。
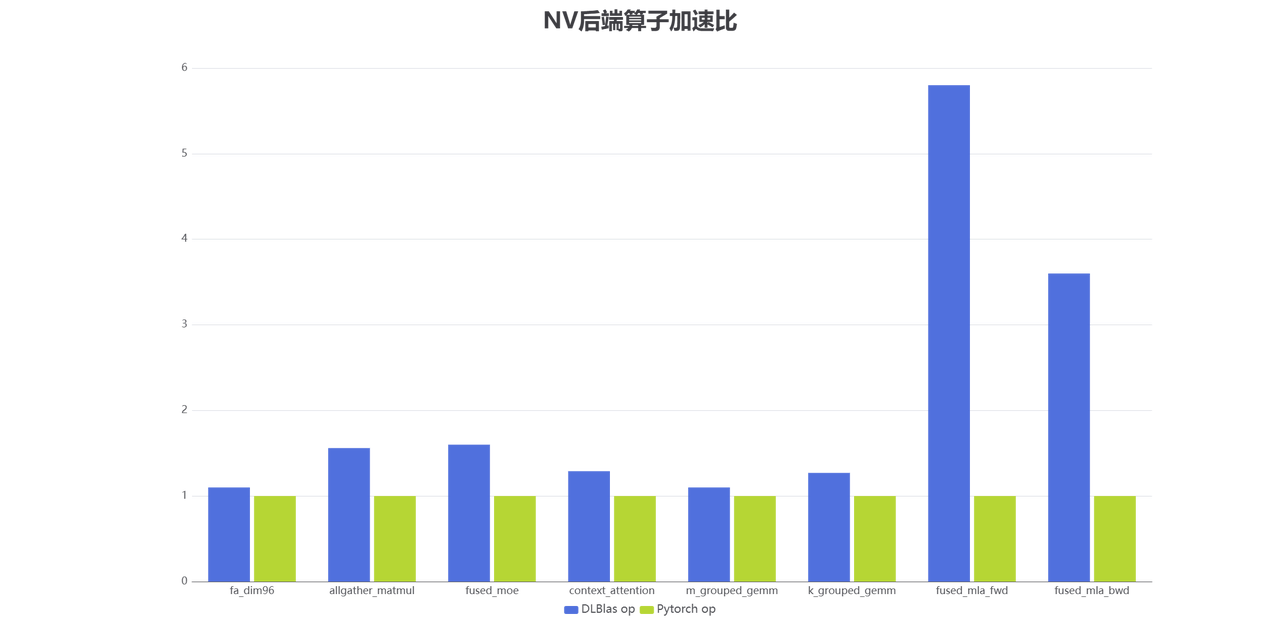
大模型主流算子在 DLBlas 中优化情况一览
在大模型训练与推理中,针对计算瓶颈的关键算子在 NVIDIA 与昇腾两大硬件平台上均已实现显著的性能加速。通过深入优化算子实现、充分利用硬件特性,并结合软件协同设计,两类平台在以下方面取得突出进展:
-
在 NVIDIA 的 H800/A100:借助新一代硬件架构(如 Hopper)所引入的张量内存加速器(TMA, Tensor Memory Accelerator) 和异步数据拷贝(Async Copy) 等特性,通过内核融合、精细调度与混合精度策略,在 Gemm、Attention、LayerNorm 等瓶颈算子实现相比通用实现 1.2 倍至 5 倍的加速效果,尤其在 FP8 大矩阵运算和长序列注意力机制中表现优异。
-
在昇腾平台:针对昇腾芯片,通过扩展领域专用语言(DSL)并与昇腾毕昇编译器团队开展深度融合与协同优化,实现了关键算子的高效部署与性能提升。相比社区通用实现,优化后的算子性能提升达 1.2 至 1.9 倍。此外,针对部分社区现有算子在昇腾特定张量加速器(DSA)架构上支持不足的情况,完成了功能适配与基本通路验证,确保了其可在昇腾平台上正常运行。相关优化算子已在DLBlas仓库中集成发布。
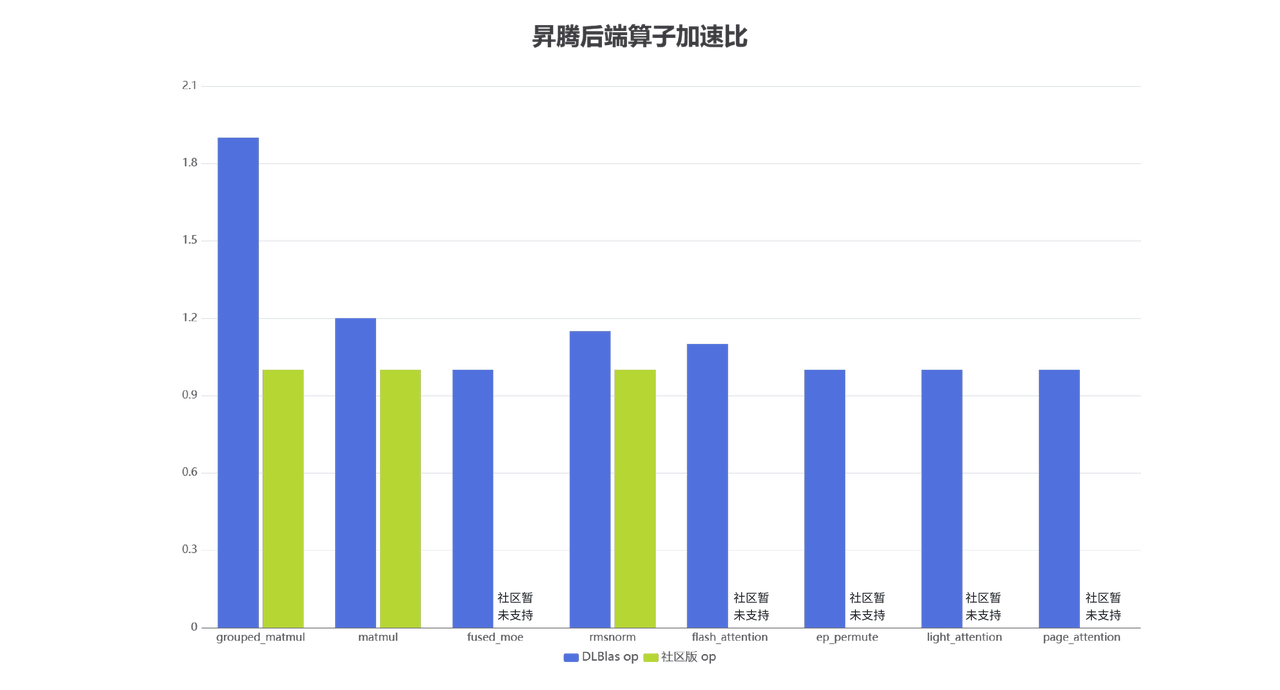
MoE 模型终极适配与生态融合
DLBlas 为 MoE 系列模型提供统一接口层,支持 SGLang、LMDeploy、VLLM 等推理框架的即插即用,集成 DeepEP,DeepGemm 等接口,并针对 MoE 中的大 EP 场景优化实现 two batch overlap 和融合算子 fusedMoE,并根据 token 动态选择 expert 均衡计算负载实现以缓解木桶效应。此外,针对 FlashAttention 的精度与效率问题,通过 Triton Autotune 参数优化与 L2 cache 策略调整,在保持精度的同时实现最高 1.108 倍加速。
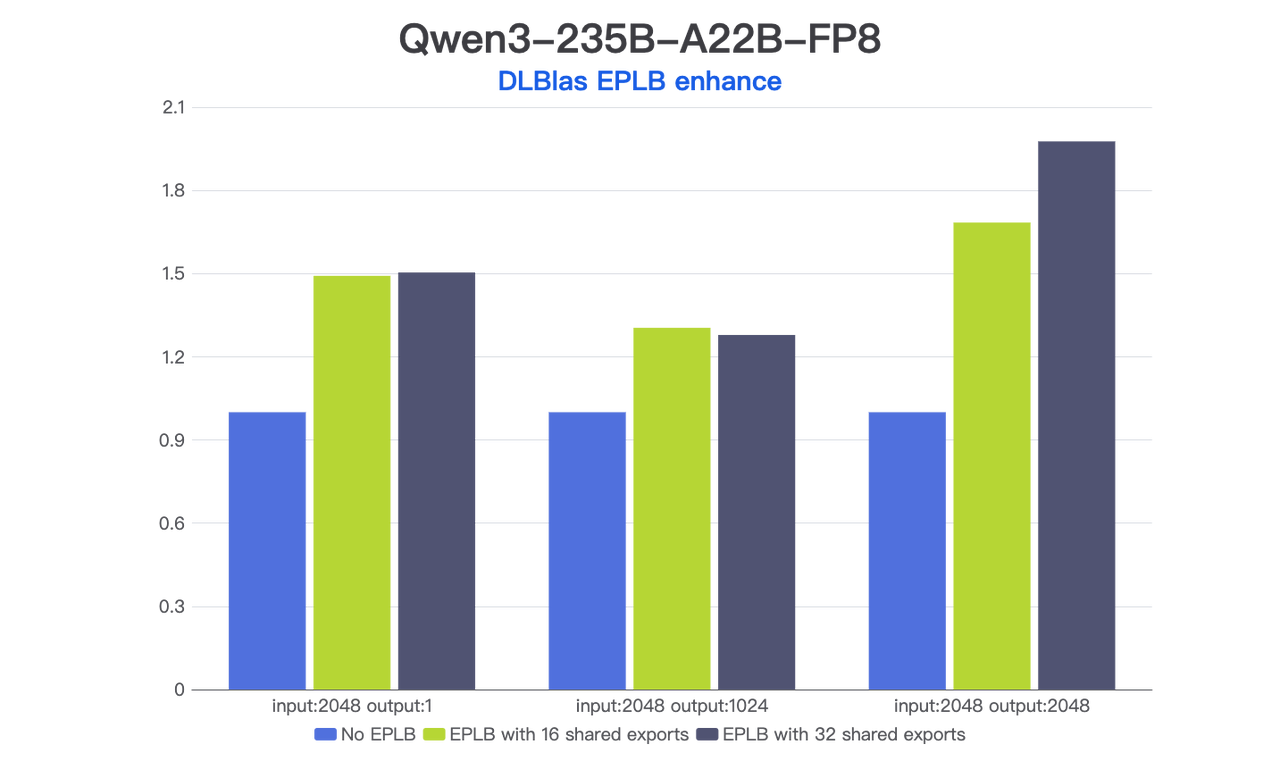
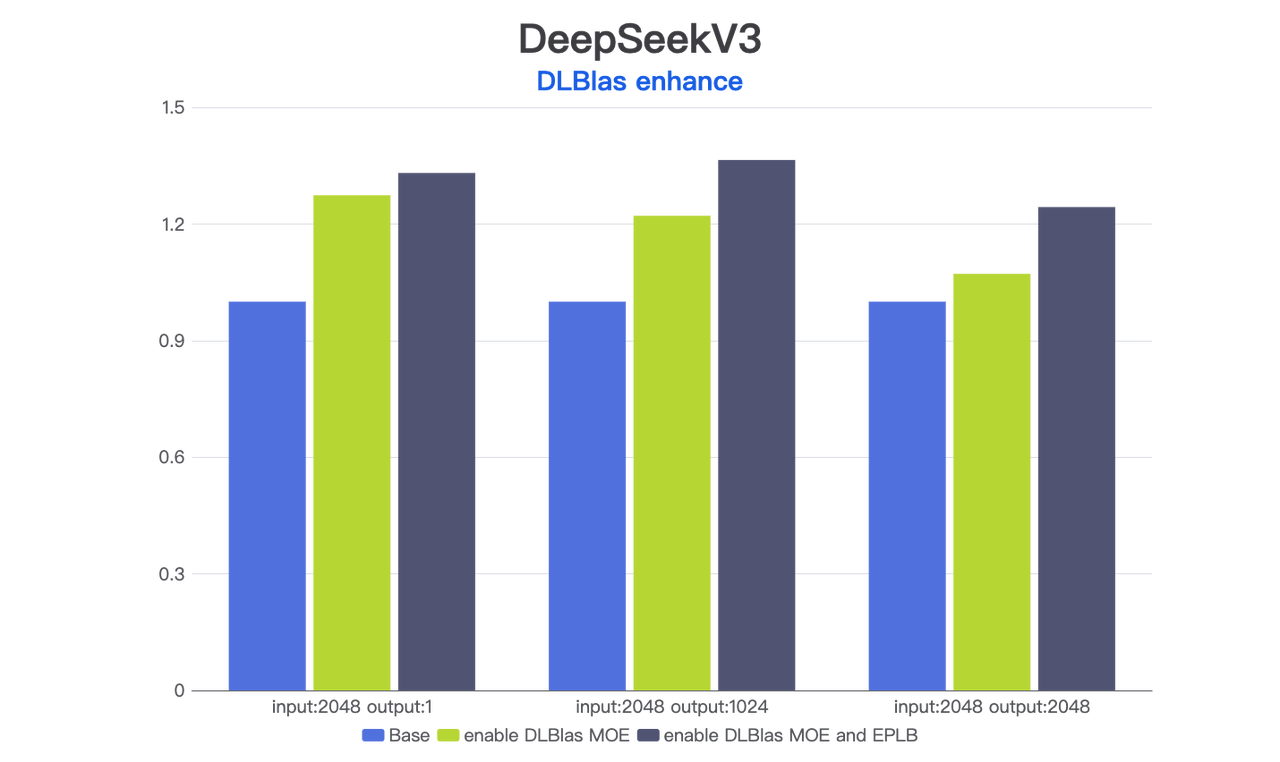
DLBlas 在 Qwen3、DeepSeekV3 等模型中助力开源框架提升性能:
DeepLink 聚焦多元芯片生态建设,深耕编译优化等核心技术,全力推进国产 AI 工具链研发与安全高效的方案落地。针对国产芯片特性优化算子性能、构建统一计算通信中间表达,打造兼容主流框架的开发环境,降低开发者国产芯片迁移门槛,不断提高国产芯片的易用性和端到端性能。同时通过构建多场景支撑平台和垂域标杆应用,为科研和产业界提供更为强大的支持,推动 AI 全行业自主可控、可持续发展。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)