为什么说:图智能=GNN+(LLM | 图提示)
摘要:随着AI技术的快速发展,大型语言模型(LLM)与图提示学习技术正成为图智能领域的新标杆,性能超越传统图神经网络(GNN)。港科大等研究机构在KDD2024上总结了LLM在图智能中的三大应用方式:1)作为GNN增强器,通过文本嵌入优化节点表示;2)作为预测器,直接处理图任务或结合GNN进行结构感知推理;3)通过嵌入空间对齐实现GNN与LLM的协同优化。此外,图提示学习技术借鉴自然语言处理思路,
图数据是一类典型的大数据,如引文网络、社交网络和生物数据等,图智能正迅速成为理解和挖掘图数据中复杂关联性的关键技术。
近年来,大型语言模型(LLM)与提示学习技术的突破显著推动了图智能领域的发展,其性能已超越传统的图神经网络(GNN)预训练方法,并树立了新的性能标杆。
港科大等单位的研究人员在KDD2024上的survey对LLM和图提示学习技术实现图智能的方法进行了总结,该survey的具体信息见后面留言部分,这里选择其中主要部分进行极简综述。
一、通过LLM对图预训练模型进行推理
根据LLM所发挥的作用,目前研究可以分为三大类型。在实际中,可以多种混合运用。
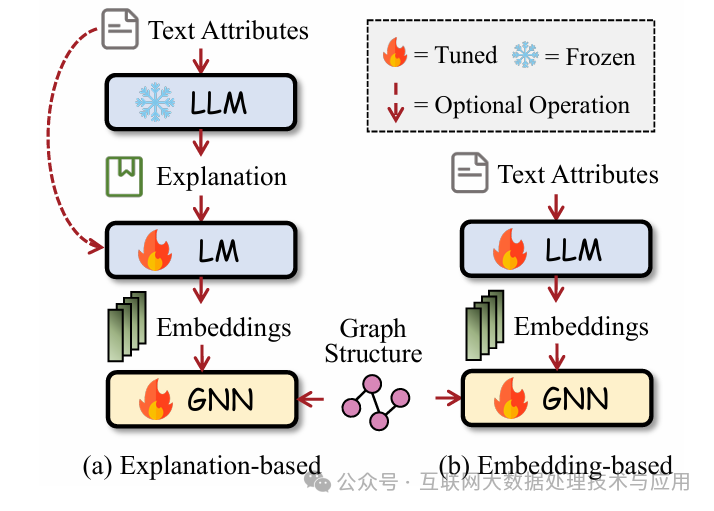
\1. LLM作为GNN的增强器
图的节点文本信息经过LLM编码后和图结构编码一起作为下游应用的输入,具体有两种形式。如图1所示,取决于是否用LLM来产生额外的文本,对于(a)类,LLM对节点的文本信息进行解释或提取生成了额外文本(伪标签、实体、解释文本等)。
另一类是基于嵌入的增强,通过LLM生成文本嵌入进而作为图节点的初始嵌入,再进行GNN的传播训练。从图中可见,LLM需要进行微调,目的是为了获得与下游任务更匹配的嵌入。因此,已有文献在这个问题上采取了很多不同做法,例如通过随机游走采样等策略提取图的路径,使用该路径上的节点文本对LLM进行微调,避免微调复杂度过高。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
\2. LLM作为预测器
使用LLM在同一个框架中对各类图任务进行预测,包括分类、推理。基于是否使用GNN为LLM提取图结构信息,各类框架可以分为两大类,如图2所示。(a)把图展平并用文本描述,从而让LLM直接处理。首先通过一个展平函数将图结构变换成节点或token的文本序列,然后对LLM的输出进行预测标签的检索,获得问题的答案。这种方法的关键在于展平函数的设计,有使用图语言的GraphML、使用图语法树的GraphText、直接对节点和边进行数字标识从而转换成序列等等。
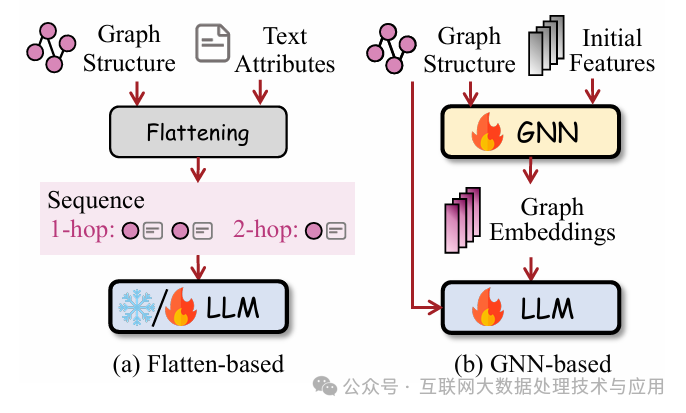
(b)基于GNN的预测,使用GNN对图结构进行编码,从而使得LLM具有图结构感知能力,这种情况一般需要对LLM进行微调以获得更规范化的输出格式。图中的初始特征为GNN的消息传播处理提供初始状态。这种方法的关键在于图结构编码和LLM获得上下文信息的融合。本号之前介绍的GraphGPT使用一个轻量级的投影器将编码后的图表示映射成图token,然后让LLM把这些token和文本对齐。
\3. GNN-LLM对齐
该方法通过在特定节点对齐二者的嵌入空间(Embedding Space),既保留了两种模型各自独特的优势,又实现了技术互补。对齐方法包括对称(a\b)和非对称(c\d),就看LLM和GNN是否被平等对待或是否并行工作的。其中(b)实际上是GLEM模型,它采用期望最大化(EM)框架,其编码器通过交互迭代生成伪标签,持续优化两个表征空间的特征对齐。这种动态协同机制使模型能够逐步收敛于更优的联合表征空间,特别适用于处理多模态数据融合场景。
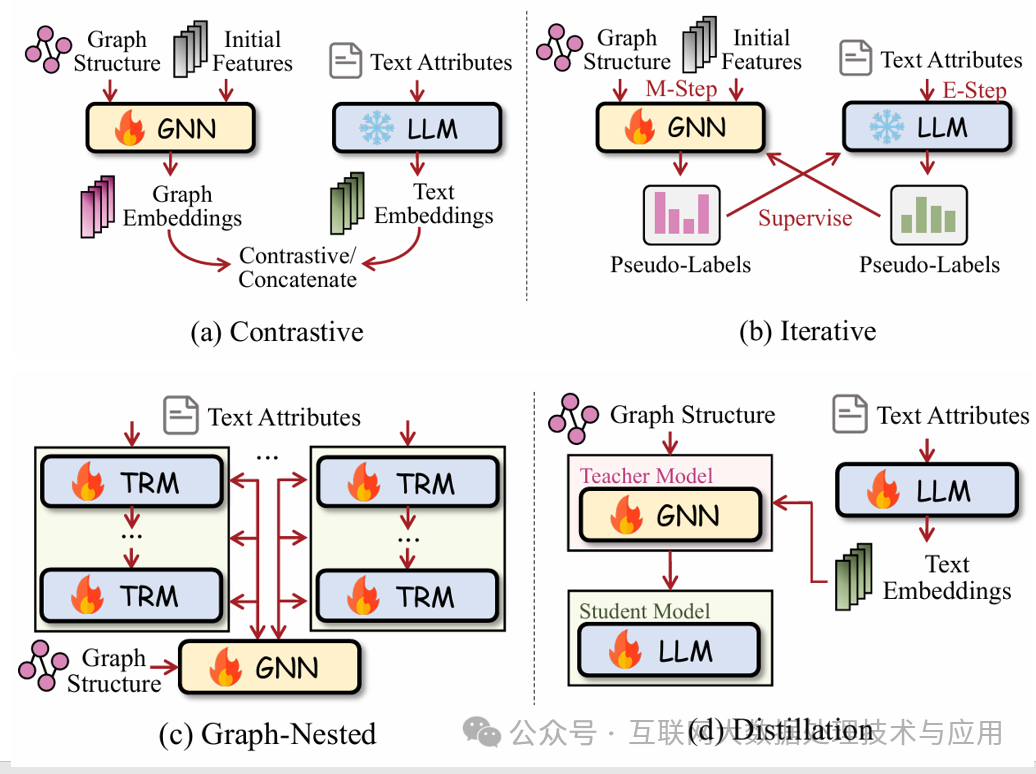
非对称对齐方法中,GNN和LLM的使用有先后顺序,但通常是使用GNN增强LLM。包括图内嵌Transformer架构(d)与图感知知识蒸馏策略(d)两类方法。
Graphformer是一种图内嵌Transformer架构,通过将图神经网络功能嵌入每个Transformer层,实现了非对称对齐机制。该架构的节点嵌入源自初始词级表征,具体取自[CLS]标记的向量。
技术实现包含三个关键步骤:首先聚合相关节点的表征向量,随后通过图Transformer进行加工处理,最终将输出结果与原始词嵌入融合,并传递至下一层Transformer。Patton[39]在此基础之上提出网络语境化掩码语言建模与掩码节点预测方法,该框架在分类、检索、重排序及链接预测等多类任务中均取得显著性能提升。
GRAD采用图感知知识蒸馏技术实现多模态对齐(图d)。该方法利用GNN作为教师模型生成软标签,用于训练LLM。由于LLM的参数共享机制,参数更新过程会同步优化GNN的文本编码能力。
通过多轮迭代优化,最终形成具备图结构感知能力的LLM,且在最终模型中移除了GNN组件,显著提升了推理阶段的可扩展性。
类似地,THLM[110]通过异构图神经网络为LLM赋予高级拓扑学习能力。该方法采用协同训练策略,同时训练LLM主模型和辅助GNN模块,具体通过上下文图预测任务和掩码语言建模任务实现知识融合。在完成协同训练后,移除辅助GNN组件,仅保留优化后的LLM进行特定下游任务的微调。
二、通过图提示学习技术对图预训练模型进行推理
这个方向的研究思路来源于自然语言预训练+提示学习,只是这里是图预训练模型。针对图的提示与自然语言任务的提示有很大不同,它没有直接可读的token,目前一般是按向量表示。相应地,图提示学习方法,通过在不同任务和领域中增强图的迁移能力,其目标就是要达到自然语言预训练模型的效果。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)