一文带大家了解DeepSeek选择 SwiGLU 作为前馈神经网络激活函数的原因
SwiGLU是DeepSeek、LLaMA等大模型采用的前馈网络激活函数,它结合Swish激活和门控机制,相比ReLU/GELU具有显著优势。SwiGLU通过双路径交互(Swish分支和门控分支相乘)实现精细特征调节,避免了ReLU的神经元死亡问题,训练更稳定。其门控机制类似注意力,能在特征维度动态调节重要性,提升模型表达能力。实验证明SwiGLU在语言建模任务上表现更优,特别适合配合RMSNor
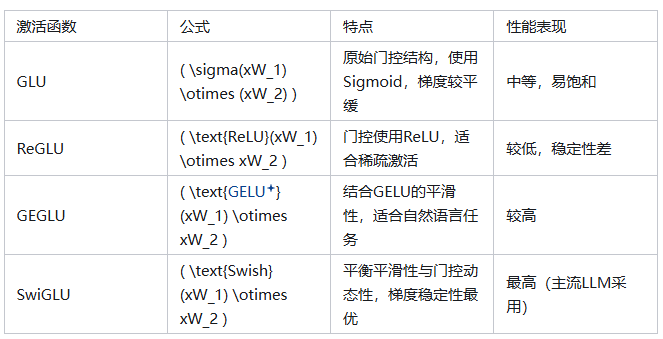
DeepSeek(以及 LLaMA、Mistral 等现代大模型)之所以选择 SwiGLU 作为前馈神经网络(FFN)的激活函数,是因为它在表达能力、训练稳定性和推理性能上,显著优于传统的 ReLU 或 GELU。
一、SwiGLU 是什么?名字怎么来的?
- GLU = Gated Linear Unit(门控线性单元)
→ 引入一个“门”来控制信息是否通过。 - Swish = 一种比 ReLU 更平滑的激活函数:
Swish(x)=x⋅σ(x),其中 σ 是 sigmoid。 - SwiGLU = 把 GLU 中的激活函数换成 Swish!
所以,SwiGLU = Swish + Gating(门控)。
二、SwiGLU 是怎么工作的?(通俗版)
想象你是一个内容审核员,要决定一条消息是否值得转发:
-
第一眼判断(Swish 分支):
你快速扫一眼内容,觉得“好像还行”,但不确定,于是给出一个 0.7 的兴趣分(这个分数是平滑的,不是非黑即白)。 -
第二眼判断(门控分支):
你再看一眼来源是否可信,给出一个 0.9 的可信度分。 -
最终决定:
把两个分数相乘:0.7×0.9=0.63,作为最终转发强度。
这就是 SwiGLU 的核心思想:
不是简单地“开/关”,而是用两个信号相乘,做更精细的“加权通过”。
三、数学公式(技术版)
对于输入向量 x∈Rd,SwiGLU 定义为:
SwiGLU(x)=Swish(W1x+b1)⊗(W3x+b3)
然后通常还会接一个输出投影:
Output=W2⋅SwiGLU(x)
其中:
- W1,W3∈Rdff×d:两个不同的线性变换;
- Swish(z)=z⋅σ(z),σ(z)=1+e−z1;
- ⊗ 表示逐元素相乘(Hadamard product);
- W2 把结果映射回原维度。
注意:DeepSeek 和 LLaMA 通常不使用偏置项(bias=False),以减少参数并配合 RMSNorm。
四、为什么 SwiGLU 比 ReLU/GELU 更好?
| 特性 | ReLU | GELU | SwiGLU |
|---|---|---|---|
| 非线性能力 | 弱(硬截断) | 中等(平滑) | 强(门控+平滑) |
| 梯度稳定性 | 有“死亡神经元”问题 | 较好 | 非常好(无硬截断) |
| 表达能力 | 单一路径 | 单一路径 | 双路径交互(门控机制) |
| 实测效果 | 基准 | 提升 | 显著提升(尤其在大模型中) |
关键优势:
门控机制(Gating)
- 允许模型动态调节每个特征的重要性;
- 类似“注意力”,但作用在特征维度而非 token 维度。
平滑梯度
- Swish 在负值区域也有小梯度,避免 ReLU 的“神经元死亡”问题;
- 训练更稳定,收敛更快。
更强的表示能力
- 实验证明:相同参数量下,SwiGLU 模型性能明显优于 ReLU/GELU;
- 这就是为什么 LLaMA、DeepSeek、Mistral 等都采用它。
论文支持:
Google 在 2020 年的《GLU Variants Improve Transformer》中证明:GLU 变体(尤其是 SwiGLU)在语言建模任务上 consistently better。
五、DeepSeek 为什么特别适合用 SwiGLU?
-
参数效率高
DeepSeek 70B 虽然参数多,但通过 MoE + SwiGLU,在激活参数少的情况下仍保持高性能。 -
与 RMSNorm 配合好
DeepSeek 使用 RMSNorm(而非 LayerNorm),不使用 bias,而 SwiGLU 天然适合无 bias 设计。 -
推理速度与精度平衡
SwiGLU 虽比 ReLU 稍慢,但在 A100/H100 等 GPU 上优化良好,且精度提升远大于计算开销。
六、举个代码例子(PyTorch)
1import torch
2import torch.nn as nn
3
4class SwiGLU(nn.Module):
5 def __init__(self, in_features, out_features, bias=False):
6 super().__init__()
7 self.w1 = nn.Linear(in_features, out_features, bias=bias)
8 self.w2 = nn.Linear(out_features, in_features, bias=bias) # 输出投影
9 self.w3 = nn.Linear(in_features, out_features, bias=bias)
10
11 def forward(self, x):
12 swish = self.w1(x).sigmoid() * self.w1(x) # Swish(W1x)
13 gate = self.w3(x) # W3x
14 return self.w2(swish * gate) # 输出在 DeepSeek 中,out_features 通常设为 int(2/3 * 4 * d_model),这是经验最优值(来自 LLaMA)。
总结
DeepSeek 用 SwiGLU,是因为它像一个“智能阀门”:不仅能判断信息是否有用,还能精细调节用多少——这让大模型学得更快、记得更牢、答得更准。
它代表了现代大模型在激活函数设计上的重要进化:从“开关”到“调光旋钮”,再到“智能门控”。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)