MCP 开发入门:从基础概念到 Server/Client 实战
最近,笔者接到了一些 MCP Server 开发相关的需求,虽然之前听说过也调用过 MCP 服务,但是真正去开发还是第一次,所以去 DeepLearning.AI 上好好学习了一下 Anthropic 官方开设的 MCP 课程(MCP: Build Rich-Context AI Apps with Anthropic),也看完了 MCP 的官方文档(版本 2025-06-18),感觉学到了很多,
本文作者为 360 奇舞团前端开发工程师
最近,笔者接到了一些 MCP Server 开发相关的需求,虽然之前听说过也调用过 MCP 服务,但是真正去开发还是第一次,所以去 DeepLearning.AI 上好好学习了一下 Anthropic 官方开设的 MCP 课程(MCP: Build Rich-Context AI Apps with Anthropic),也看完了 MCP 的官方文档(版本 2025-06-18),感觉学到了很多,故整理了这篇文章,希望能帮到对于 MCP 理解不清楚的开发同学。
另外,本文整理于 2025-7-28 日,本文中的内容和观点可能会过时,请各位注意甄别
Why MCP?
首先我们先要达成一个共识:「提供越优质的 Context,LLM 表现的就会越好」,通常这句话是没问题的,所以我们可以通过帮助 LLM 连接外部环境(如 Github、Notion),获取更高质量的 Context 来优化 LLM 输出的准确性。当然,连接外部环境也不仅仅意味着获取数据,也带给了 LLM 操作外部环境,向外部环境输出的能力。
目前,我们通过「Function Call」或者说「Tool Use」的方式来实现我们刚刚说的「连接外部环境」对吧。那么 MCP(Model Context Protocol)到底做了什么呢?其实 MCP 只是将这个「LLM 连接外部环境」的过程进行了标准化,就有点类似 Restful API 或者 LSP,它本身没有开发某种新的「Tool Use」实现,而是在包括「Tool Use」等一些逻辑的上层又进行了一些封装,直接调用「Tool Use」还是通过 MCP 调用「Tool Use」没有本质上的区别。所谓「任何可以使用 MCP 的场景,都可以选择不使用 MCP 」。
如果没有 MCP 或者某种标准,那么 LLM 和 外部环境的互动就会变得非常混乱,不同的 App 开发者需要为不同的 LLM 适配不同的外部数据消费策略和对接方式,而想要为 LLM 提供 Context 的 App (如 Github、Notion)也需要考虑针对不同的 LLM 做出相应的适配。这会造成大量的重复繁琐的适配工作,非常不利于整个社区的发展。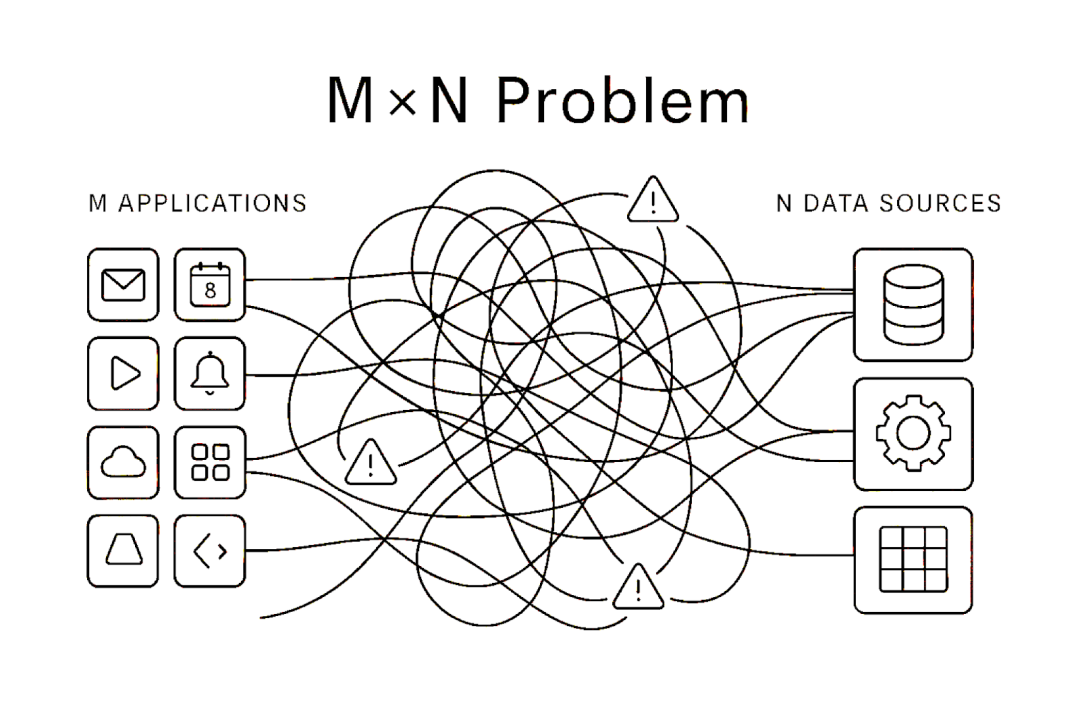
MCP 的存在,制定了标准,只要创建的 App 和 MCP Server 符合 MCP 标准,不同的 App 和 MCP Server 就可以自由交互,不需要再进行额外的适配。当 MCP 刚推出的时候,大家还在质疑,但随着 OpenAI、Google 几家大的 LLM 厂商公开宣布支持 MCP,目前 MCP 已然成为了「LLM 连接外部环境」的事实标准。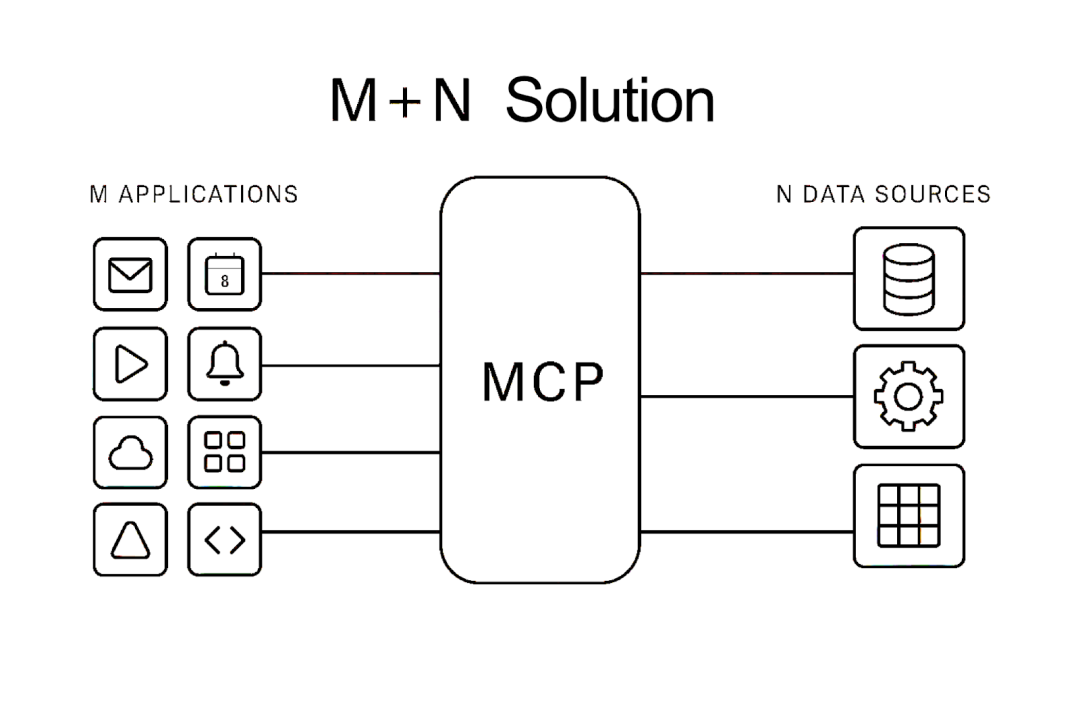
MCP 的架构与基础概念
MCP 采用了Client-Server(客户端-服务器)架构,有三个比较重要的组成部分: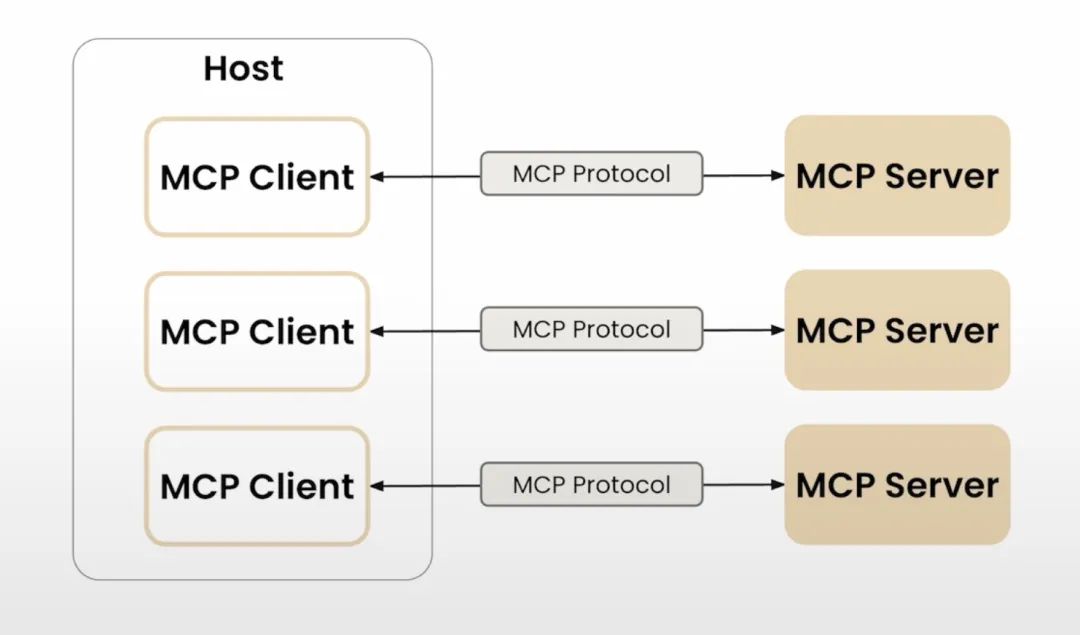
-
MCP Server :提供 Tools / Resources / Prompts 不同类型的服务,负责响应 Client
-
MCP Client :与 MCP Server 进行一对一连接的连接器,负责所有和 Server 的通信
-
Host :顶层 AI 应用,控制并管理多个 MCP Client,可以收集 Client 中接收到的数据用于业务逻辑,或操作 Client 向 Server 发起请求
另外,MCP 是一个两层的架构,包含:
-
数据层(Data layer):定义了以 JSON-RPC 为基础的消息格式和语义,并划定了 MCP 的原语 和 生命周期逻辑。
-
传输层(Transport layer):定义了连接建立和消息传输的底层机制
数据层(Data layer)
MCP 原语(Primitive)
通常我们作为开发者,更多的是进行 MCP Server 的开发,所以有必要了解 MCP Server 的原语(即 MCP 能暴露的服务种类)。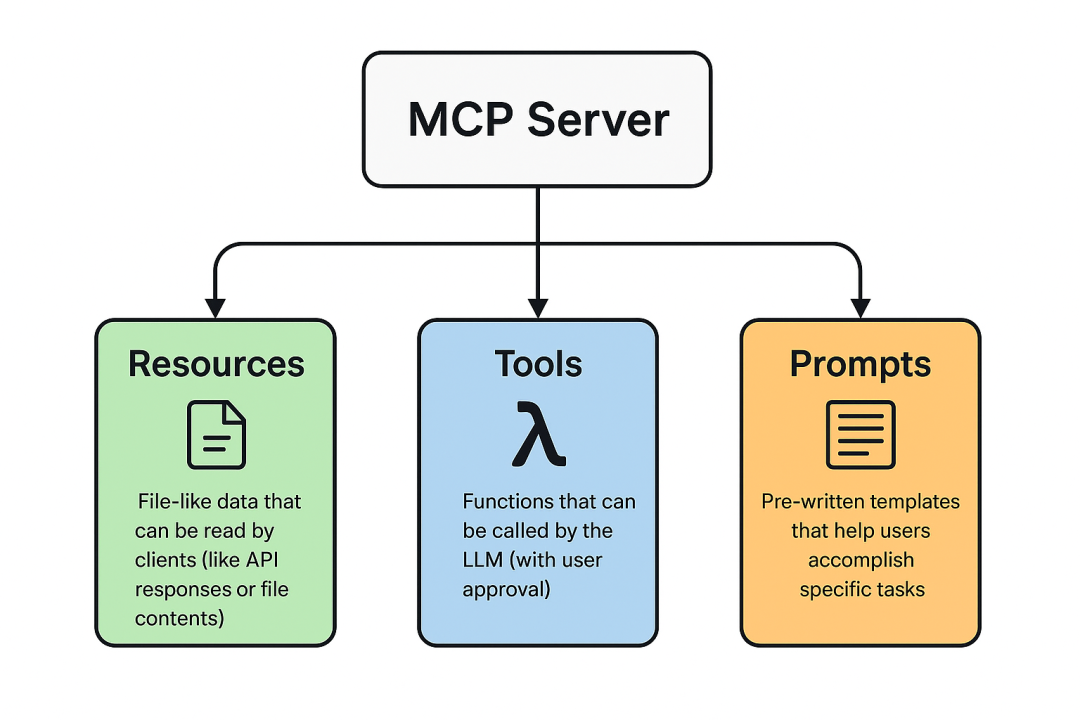 MCP Server 中有三大原语:
MCP Server 中有三大原语:
-
Tools :AI 应用可以调用的可执行函数,用于执行具体操作(如文件操作、API 调用、数据库查询)
-
Resources :为 AI 应用提供上下文信息的数据源(如文件内容、数据库记录、API 响应)
-
Prompts :帮助构建与语言模型交互的可复用模板(如系统提示词、Few-shot 示例)
但截止到目前(2025-7-27), 提供「Tools」的 MCP Server 占比要远远超越其他两种原语,甚至很多人并不知道 MCP 还能提供「Tools」之外的服务,所以这可能也是很多人会把「Tool Use」和「MCP Server」搞混,不知道其提供服务有什么差别的原因之一吧~ 因为看上去都是 LLM 在调用工具。
本文后续不会再介绍「Resources」和「Prompts」相关的信息,因为真就太小众了,大家感兴趣可以自行了解一下。
除了常见的 Server 侧的原语,MCP Client 也有几种原语暴露给 Server,为 Server 提供一些和客户端用户交互的能力,如:
-
Sampling : Server 可以向 Client 发起 LLM 调用请求,使得 Server 无需直接接入或付费调用 LLM
-
Roots :Client 向 Server 生命可访问的文件系统范围
-
Elicitation : Server 向 Client 发起请求用户填写结构化信息,使得用户可以直接为 Server 提供详细信息
生命周期
MCP 的通信生命周期有以下几个流程,这里简要讲解一下: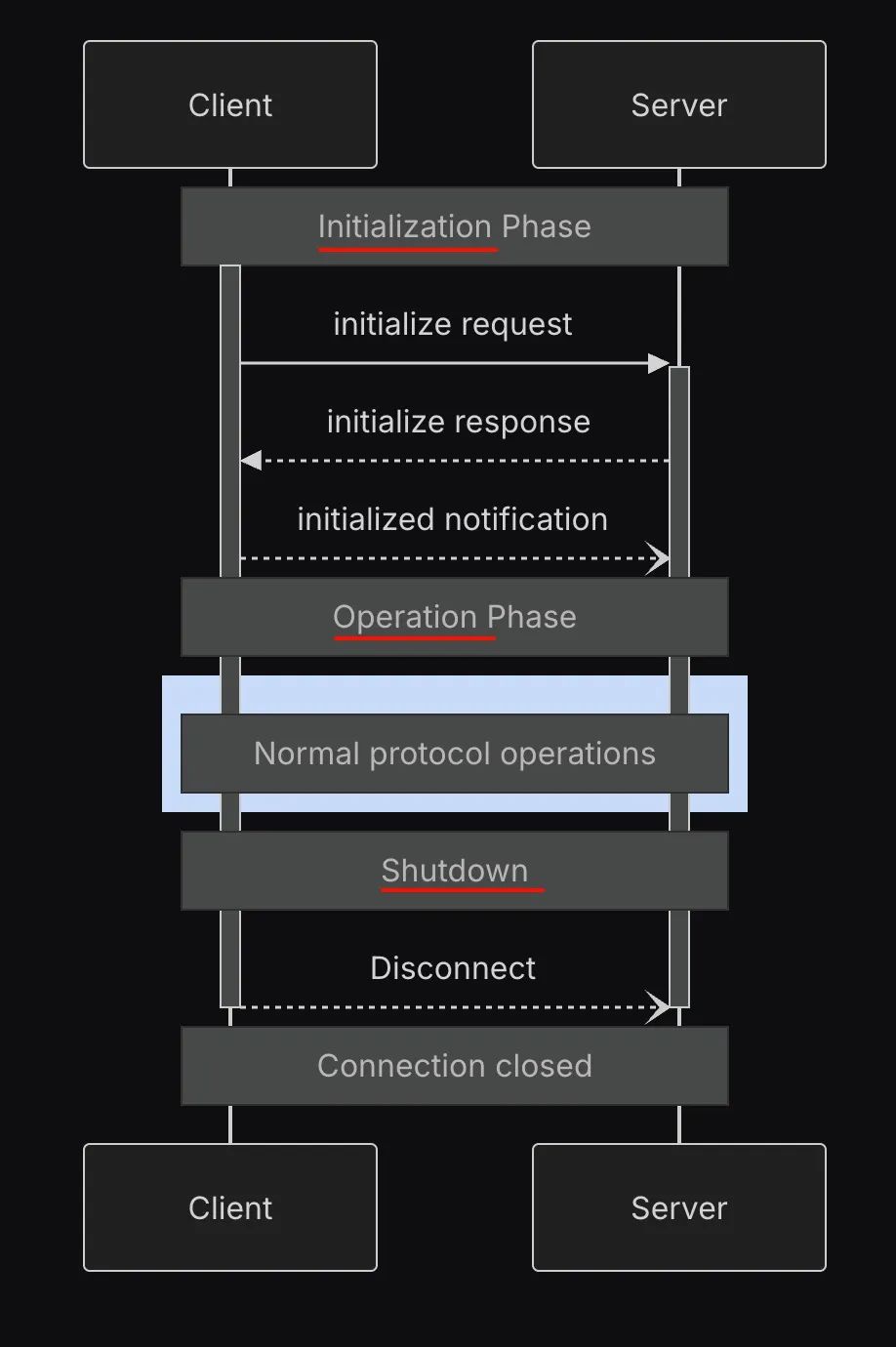
-
初始化(Initialization):Client 和 Server 进行握手和协议协商,完成初始化,并进行能力协商(capability negotiation),双方交换自己支持的原语和能力,建立通信能力边界
-
运行(Operation):双方基于已确定的能力边界进行 JSON-RPC 通信,可以基于场景选择不同的传输模式
-
终止(Shutdown):基于不同的传输模式来断开连接
传输层(Transport layer)
对于 Client 和 Server 的数据传输,官方提供了几种标准传输模式(当然,如果业务有需求也可以自定义传输模式,只要符合官方提供的 JSON-RPC 标准):
-
本地:stdio
-
远程:
-
-
Streamable HTTP
-
HTTP + SSE(现已不推荐使用)
-
在 stdio 传输模式下,Host 直接以子进程形式启动 MCP Server,通过标准输入(stdin)发送 JSON‑RPC 请求,从标准输出(stdout)接收响应,无需网络层。适用于那些需要操纵用户本地机器的场景,比如连接用户本地的数据库、访问本地文件或者为用户本地创建文件等操作。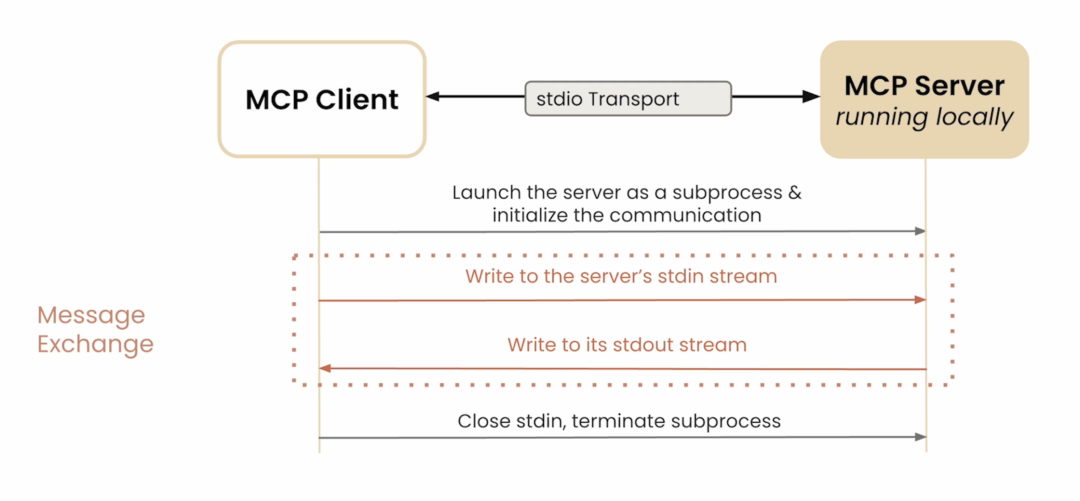
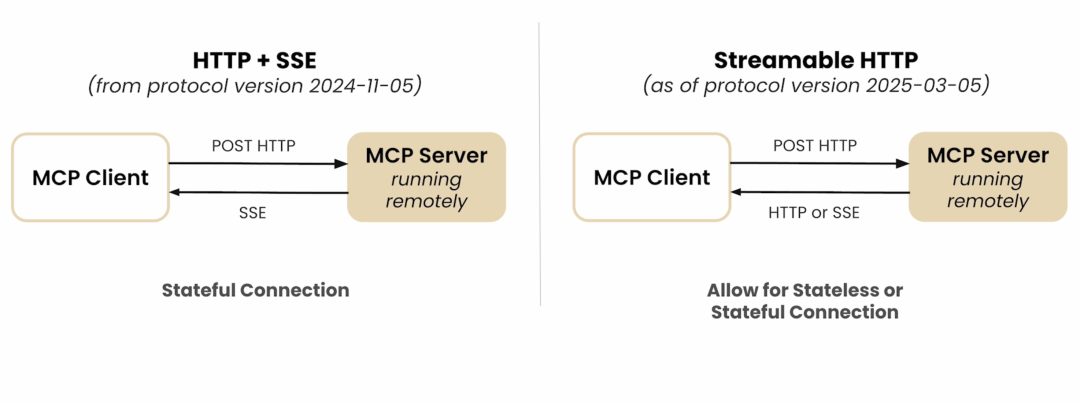
目前,Streamable HTTP 是标准指定的远程 MCP 实现方式,它是为了解决 HTTP + SSE 的弊端而提出的。
在 HTTP + SSE 传输模式下,Client 和 Server 建立长连接,Server 可以通过 SSE(Server‑Sent Events)向 Client 推送消息。虽说整个流程非常简单,但是 HTTP + SSE 问题在于,这种传输模式依赖长连接,是 stateful 的,这非常不利于扩展。另外,其实很多场景没有必要做 stateful,比如某些场景下 MCP Server 就是被调用一次就结束,那维持长连接就会显得非常鸡肋,完全是在浪费资源。所以可以 stateful、可以 stateless 的 Streamable HTTP 就被提出了。
Streamable HTTP 同时支持 stateful + stateless,可以直接用普通 HTTP(POST / GET)做无状态请求,请求响应后立即断开,适合无状态场景。也能按需升级为 SSE(流式),在确实需要实时推送时再开启长连接。这适应更多云端和弹性部署场景,所以它将逐步取代原来的 HTTP + SSE。
开发 MCP Server
我们可以使用 MCP 的 Python SDK 简单创建一个 Stateless 的 Streamable HTTP MCP Server,我创建了一个用来查询 Github 相关信息的 MCP Server,包含两个 Tool:
-
get_github_user_info:查询某个 Github 用户信息 -
get_github_repo_issues:查询某个 repo issue 信息
from mcp.server.fastmcp import FastMCP
import httpx
mcp = FastMCP("StatelessServer", stateless_http=True)
@mcp.tool()
def get_github_user_info(username: str = "SuperTapir"):
"""Get information about a GitHub user."""
url = f"https://api.github.com/users/{username}"
response = httpx.get(url)
json = response.json()
result = {
"name": json["name"],
"bio": json["bio"],
"location": json["location"],
}
return result
@mcp.tool()
def get_github_repo_issues(owner: str = "SuperTapir", repo: str = "Blog"):
"""Get issues for a GitHub repository."""
url = f"https://api.github.com/repos/{owner}/{repo}/issues"
response = httpx.get(url)
issues = response.json()
return [
{
"title": issue["title"],
"labels": [lbl["name"] for lbl in issue.get("labels", [])],
"created_at": issue["created_at"],
}
for issue in issues
]
if __name__ == "__main__":
mcp.run(transport="streamable-http")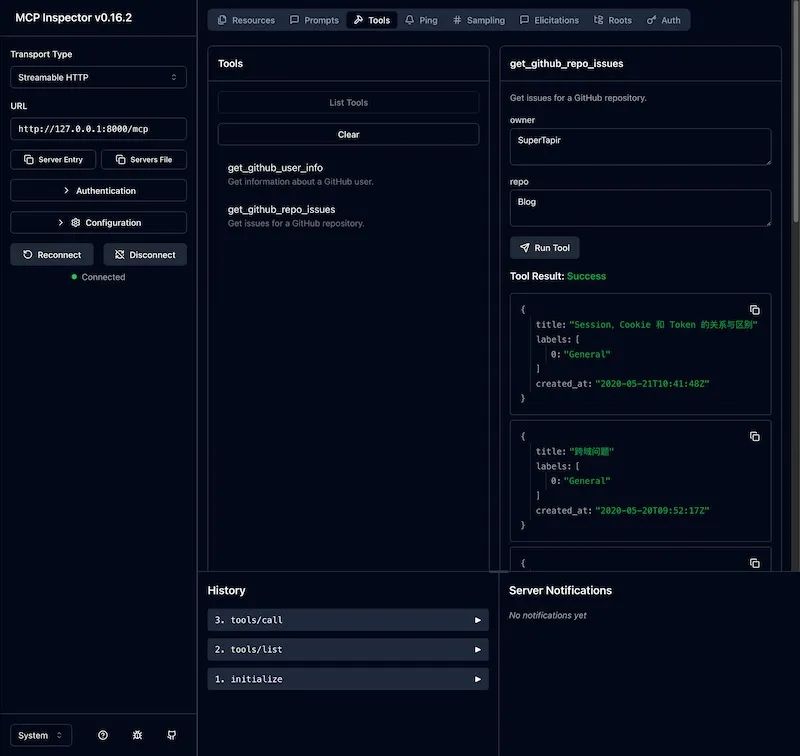
通过 @modelcontextprotocol/inspector 我们可以方便的调试 MCP Server,可以看到和我们的预期是一致的。
我们使用 MCP SDK 提供的 FastMCP 来实现 MCP Server 非常的简单,只需要使用 @mcp.tool() 来声明我们的 Tool,再 run 一下就完事了,这是因为 FastMCP 为我们封装了大量的细节,如果我们有更定制化的需求,比如定制 tools/list 的返回值,动态生成工具列表,那就必须使用 MCP SDK 提供的「Low Level」 API 了,接下来我们将刚刚的 Server 改得更复杂一些:
import json
import logging
import contextlib
from collections.abc import AsyncIterator
import mcp.types as types
from mcp.server.lowlevel import Server
from mcp.server.streamable_http_manager import StreamableHTTPSessionManager
from starlette.applications import Starlette
from starlette.routing import Mount
from starlette.types import Receive, Scope, Send
import httpx
logger = logging.getLogger(__name__)
app = Server("My GitHub MCP")
@app.list_tools()
asyncdef list_tools() -> list[types.Tool]:
return [
types.Tool(
name="tapir.github/get_user_info",
description="Get information about a GitHub user.",
inputSchema={
"type": "object",
"required": ["username"],
"properties": {
"username": {"type": "string", "default": "SuperTapir"},
},
},
),
types.Tool(
name="tapir.github/get_repo_issues",
description="Get issues for a GitHub repository.",
inputSchema={
"type": "object",
"required": ["owner", "repo"],
"properties": {
"owner": {"type": "string", "default": "SuperTapir"},
"repo": {"type": "string", "default": "Blog"},
},
},
),
]
@app.call_tool()
asyncdef call_tool(tool_name: str, tool_input: dict) -> list[types.ContentBlock]:
"""Call a tool."""
if tool_name == "tapir.github/get_user_info":
url = f"https://api.github.com/users/{tool_input['username']}"
response = httpx.get(url)
user_info = response.json()
result = {
"name": user_info["name"],
"bio": user_info["bio"],
"location": user_info["location"],
}
return [
types.TextContent(
type="text",
text=json.dumps(result)
)
]
elif tool_name == "tapir.github/get_repo_issues":
url = f"https://api.github.com/repos/{tool_input['owner']}/{tool_input['repo']}/issues"
response = httpx.get(url)
issues = response.json()
result = [
{
"title": issue["title"],
"labels": [lbl["name"] for lbl in issue.get("labels", [])],
"created_at": issue["created_at"],
}
for issue in issues
]
return [
types.TextContent(
type="text",
text=json.dumps(result)
)
]
return []
session_manager = StreamableHTTPSessionManager(
app=app,
event_store=None,
stateless=True,
)
asyncdef handle_streamable_http(
scope: Scope, receive: Receive, send: Send
) -> None:
await session_manager.handle_request(scope, receive, send)
@contextlib.asynccontextmanager
asyncdef lifespan(app: Starlette) -> AsyncIterator[None]:
"""Context manager for session manager."""
asyncwith session_manager.run():
logger.info(
"Application started with StreamableHTTP session manager!")
try:
yield
finally:
logger.info("Application shutting down...")
def main():
starlette_app = Starlette(
debug=True,
routes=[
Mount("/mcp", app=handle_streamable_http),
],
lifespan=lifespan,
)
import uvicorn
uvicorn.run(starlette_app, host="127.0.0.1", port=8001)
if __name__ == "__main__":
main()在这个用例中,我们利用 MCP SDK 提供的 Low Level API,先创建了一个 Server,并定义了它的 tools/list 和 tools/call 行为,使得我们可以动态的生成 Tool 列表了,并且因为不是像之前一样通过装饰器来创建 Tool,所以更加灵活,比如我们可以将工具名按照官方推荐的方式加上命名空间,就像这样 tapir.github/get_user_info 。另外,我们也可以更灵活的调整生命周期和服务的挂载点相关逻辑。
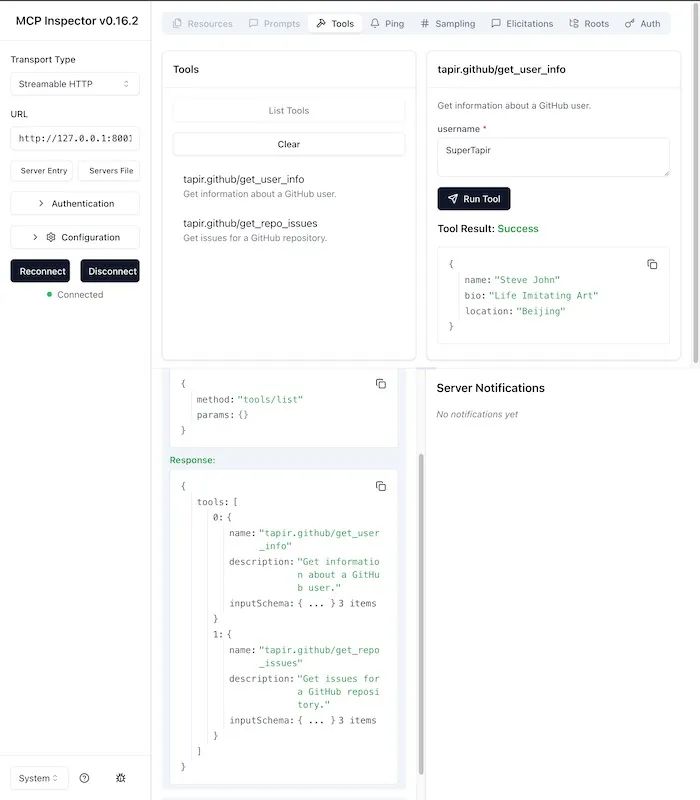
通过 @modelcontextprotocol/inspector 可以看到也是一切正常。
开发 MCP Client
虽说我们作为 MCP 的开发者,通常不太用开发 MCP Client,但是了解 MCP Client 能更好的让我们理解 MCP 整体的过程,所以这里我们来开发一个 MCP Client :
import asyncio
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
asyncdef main():
# 连接我们本地的 Streamable HTTP MCP 服务
asyncwith streamablehttp_client("http://localhost:8001/mcp") as (
read_stream,
write_stream,
_,
):
asyncwith ClientSession(read_stream, write_stream) as session:
# 初始化 session
await session.initialize()
# 列出可用的工具
tools = await session.list_tools()
print(f"Available tools: {[tool.name for tool in tools.tools]}")
# 调用一个工具,这里直接调用 tapir.github/get_user_info
result = await session.call_tool("tapir.github/get_user_info", {"username": "SuperTapir"})
print(f"Result: {result}")
if __name__ == "__main__":
asyncio.run(main())总结
感谢你看到这里,MCP 目前已然成为了 LLM 连接外部世界的事实标准,理解和学习开发 MCP Server 非常有价值。本文从 MCP 开发的动机开始聊起,之后讲解了 MCP 的核心概念,最终进行了 Server 和 Client 的代码实践,希望这个过程能帮你打通从理论到实践的路径。
当然,受篇幅所限,本文主要聚焦于最常见的 Tools 原语和无状态的 Streamable HTTP Server。MCP 还有如 Resources 和 Prompts 等原语、有状态(Stateful)服务的实现、以及更丰富的 Client 能力(如 Elicitation)、Auth 相关、通知机制等诸多内容没有深入探讨。如果大家对这些高级主题感兴趣,请务必查阅 MCP 的官方文档,获取最全面、最准确的信息。
大家都开发过 MCP 吗,有没有什么小技巧可以分享?欢迎在评论区留言交流!
-END -
如果您关注前端+AI 相关领域可以扫码进群交流

添加小编微信进群😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)