【AI工具】用大模型生成脑图初试
试用了一下通过大模型生成脑图,非常简单
·
刚试用了一下通过大模型生成脑图,非常简单,记录一下
一、用大模型生成脑图文件
关键:存在markdown文件
举例:使用Deepseek,输入问题:“针对大模型的后训练,生成一个开发计划,用markdown格式表示”
然后大模型输出:
# 大模型后训练开发计划
## 1. 项目概述
**目标**:完成大模型领域适应、指令对齐和安全增强的后训练
**模型基线**:基于预训练模型(如LLaMA、GPT-3等)
**预期成果**:具备领域专业能力、可靠安全边界的高可用模型
## 2. 阶段规划
### 2.1 数据准备阶段(2-4周)
- **数据收集**
- 领域数据:专业文献/行业文档/领域问答对
- 指令数据:人工编写多轮对话样本
- 安全数据:对抗性提示词及标准响应
- **数据清洗**
- 去重去噪处理
- 质量标注(领域相关性/指令复杂度/安全等级)
- **数据增强**
- 文本扩写/回译增强
- 知识注入(知识图谱融合)
### 2.2 模型训练阶段(3-6周)
#### 2.2.1 领域适应训练
- 采用LoRA/Adapter微调
- 分层学习率设置
- 领域知识蒸馏
#### 2.2.2 指令微调
- 多任务联合训练
- 奖励模型构建(RHLF)
- 思维链(CoT)增强
#### 2.2.3 安全对齐
- 对抗训练框架搭建
- 红队测试机制
- 价值观对齐算法
### 2.3 评估验证阶段(2-3周)
#### 评估体系
```mermaid
graph TD
A[基础能力] --> B1(语言流畅度)
A --> B2(事实准确性)
C[领域能力] --> D1(专业术语)
C --> D2(推理深度)
D[安全性] --> E1(有害内容过滤)
D --> E2(价值观对齐)
然后将上面的输出拷贝,存成.md文件
用Xmind导入
导入结果如下: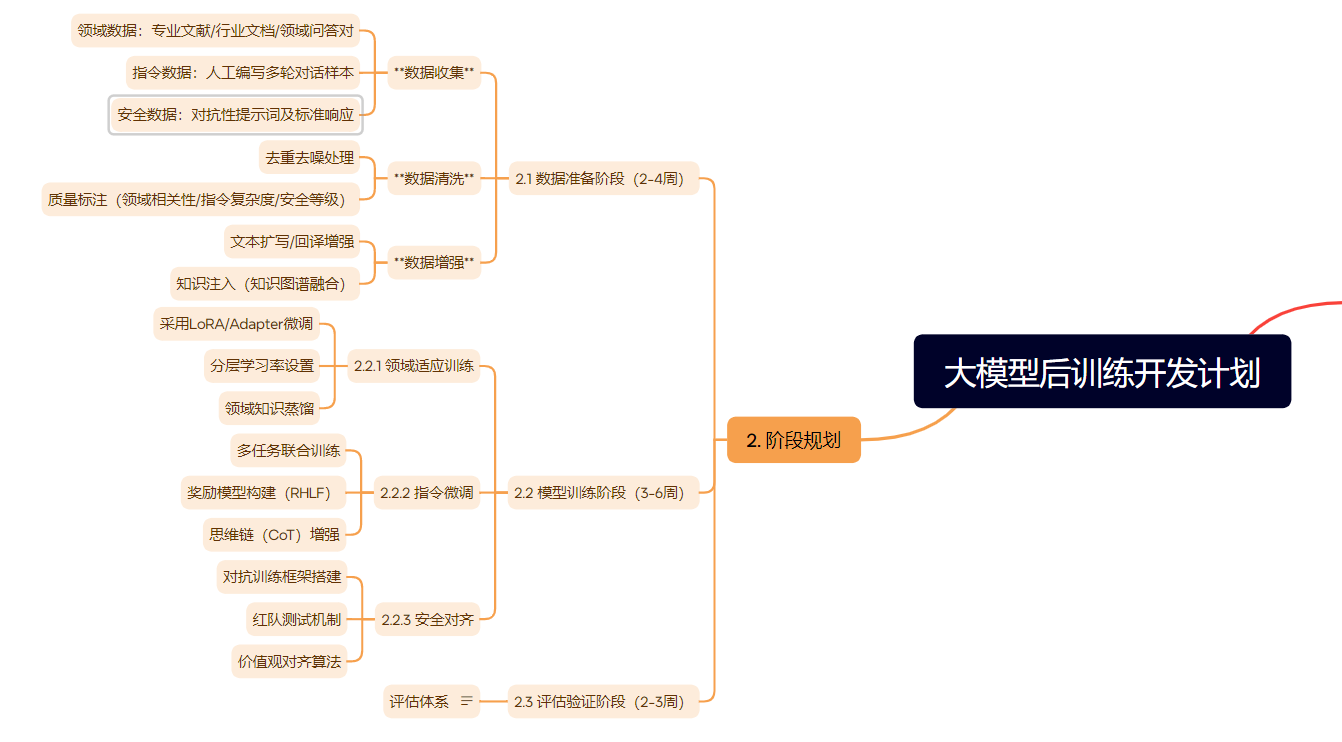
用了十分钟试用了一下,非常方便

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)